Algorithmes pour les réseaux ad hoc
Depuis le milieu des années 1990, deux révolutions transforment le monde des télécommunications : l’explosion d’Internet d’une part et la généralisation des communications mobiles sans-fil d’autre part. L’Internet tend depuis une dizaine d’années à absorber tous les types de réseaux, pour les fondre progressivement en un seul réseau de plus d’un milliard d’utilisateurs. Les frontières de l’Internet se sont étendues tout dernièrement aux réseaux sans-fil, qui ont eux aussi récemment connu une croissance phénoménale (on compte ainsi plus d’un milliard d’utilisateurs de téléphones cellulaires sur la planète). La convergence semble maintenant inéluctable entre les technologies Internet et les technologies sans-fil : la perspective est celle d’un réseau ambiant omniprésent, qui déplacera à chaque instant et en temps réel des quantités considérables d’information multimédia, que les éléments du réseau et les destinataires soient fixes ou mobiles.
Des réseaux mobiles d’un nouveau genre
Au cœur de cette convergence technologique, des réseaux mobiles d’un nouveau genre se développent : les réseaux ad hoc. Ces derniers incarnent d’une certaine manière la synthèse de l’Internet et des communications mobiles sans-fil. Leur principe de fonctionnement est le suivant : chaque terminal utilisateur peut être utilisé comme relais intermédiaire pour acheminer le trafic entre d’autres terminaux utilisateurs. En d’autres termes, les réseaux ad hoc abolissent la différence traditionnelle (fondement des réseaux téléphoniques et de l’Internet) entre d’une part les terminaux qui utilisent le réseau, et d’autre part les machines de l’infrastructure (les routeurs), dédiées à la formation et à la maintenance du réseau, et à l’acheminement du trafic utilisateurs. Dans les réseaux ad hoc, il n’y a qu’un seul type de machine, qui à la fois utilise et forme le réseau, tandis que le medium radio est utilisé pour acheminer à la fois le trafic utile – les informations que veulent transmettre les utilisateurs – et le trafic de contrôle – les informations que doivent échanger les éléments du réseau pour découvrir et maintenir à jour les routes à travers le réseau, tâche que l’on appelle le routage.
Les propriétés des réseaux ad hoc en font des solutions pratiques pour étendre l’accès aux bornes d’une infrastructure fixe (téléphonie sans-fil, Wifi etc.), en dépassant la portée radio de ces bornes grâce au relais ad hoc que les utilisateurs peuvent se fournir les uns aux autres pour accéder indirectement à l’infrastructure. Cependant, l’aspect le plus novateur des réseaux ad hoc est de pouvoir fournir une couverture réseau mobile de manière automatique et autonome, et ce même sans accès à une infrastructure préexistante, toujours grâce au relais ad hoc que les utilisateurs peuvent se fournir les uns aux autres.
Afin d’être en mesure d’acheminer le trafic de données requis par ces utilisateurs, les réseaux ad hoc utilisent des algorithmes pour construire des routes entre paires d’utilisateurs à travers des utilisateurs tiers, en formant des relais intermédiaires. Cette tâche, qu’on appelle le routage, est généralement accomplie au moyen d’un trafic de données supplémentaire au trafic des utilisateurs : le trafic de contrôle, qui véhicule les informations nécessaires au bon fonctionnement du routage. Ici, il sera donc essentiellement question de routage et de trafic de contrôle.
Contraintes du routage dans les réseaux ad hoc
L’accomplissement de la tâche de routage, inhérente à tout réseau, est compliquée dans les réseaux ad hoc par l’utilisation de communications par radio : la radio est en effet le medium le plus hostile à la propagation de l’information, du fait notamment des interférences entre utilisateurs et de la complexité du traitement du signal. D’autre part, le routage ad hoc est aussi compliqué par la mobilité des éléments susceptibles d’acheminer le trafic (c’est-à-dire les utilisateurs eux-mêmes). N’ayant pas été prévus pour ces dernières complications, les algorithmes de routage classiques ne peuvent donc pas être utilisés tels quels. Ils doivent être optimisés (si ce n’est entièrement revus) pour être efficaces dans les réseaux ad hoc : s’adapter aux communications radio en réduisant au maximum le trafic de contrôle nécessaire au bon fonctionnement du réseau, et en même temps rester en mesure de suivre dynamiquement la mobilité des éléments du réseau. Ce sont ces contraintes qui sont au fondement des algorithmes de routage ad hoc.
Principe du routage
Dans les réseaux traditionnels, par exemple dans l’Internet, le routage de base est généralement accompli à l’aide d’un algorithme simple : l’algorithme d’état des liens. Chaque routeur échange des messages de contrôle avec ses voisins. Sont appelés voisins deux routeurs soit directement connectés par un câble (dans le cas d’un réseau filaire), soit réciproquement à portée radio l’un de l’autre (dans le cas d’un réseau sans-fil). De manière schématique, dans ces deux cas, deux routeurs voisins seront représentés liés par un trait. Notons que les voisins d’un routeur peuvent changer au cours du temps : un routeur voisin peut par exemple cesser de fonctionner, ou un câble peut être débranché. Dans le cas d’un réseau radio, un routeur voisin pourrait aussi se mouvoir et se trouver tout à coup hors de portée radio.
Plus précisément, avec l’algorithme d’état des liens, un routeur émet deux types de messages de contrôle :
- d’une part, des messages à portée locale, qu’il échange périodiquement avec les routeurs voisins seulement, lui permettant de découvrir et de suivre l’évolution de ses liens avec ces derniers ;
- d’autre part, des messages à portée globale, qu’il envoie périodiquement à tous les routeurs du réseau (et non seulement à ses voisins), décrivant l’état de ses liens avec ses routeurs voisins du moment.

Le routeur A envoie deux types de messages : à portée locale d’une part, à portée globale d’autre part.
De cette manière, chaque routeur se trouve à tout moment en possession de l’état actuel des liens de tous les routeurs du réseau avec leurs voisins. En agrégeant ces informations, chaque routeur peut constituer une carte routière complète et actualisée du réseau, et ainsi déterminer les chemins utilisables entre différents points du réseau.
L’algorithme d’état des liens est en général utilisé en collaboration avec des mécanismes hiérarchiques, afin de gérer efficacement des réseaux de grande taille (comme l’Internet par exemple). Le réseau est ainsi divisé en zones indépendantes, reliées entre elles par des passerelles. L’algorithme d’état des liens est utilisé pour le routage à l’intérieur de chaque zone, et le « super réseau » formé des liens entre les passerelles des différentes zones est utilisé pour le routage d’une zone à une autre. Ce « super réseau » peut d’ailleurs, lui aussi, faire usage de l’algorithme d’état des liens (mais il peut aussi utiliser un autre algorithme de routage). De même, cette hiérarchie peut comporter plusieurs niveaux d’imbrication, sur un principe similaire.
Ce principe de réseau hiérarchique permet de cloisonner une partie du trafic de contrôle à l’intérieur des zones. Ainsi, ces dernières peuvent évoluer relativement indépendamment les unes des autres. Les passerelles de différentes zones peuvent se contenter d’échanger entre elles des condensés d’information de routage à propos de leurs zones respectives, qui s’avèrent pertinents au niveau interzones.
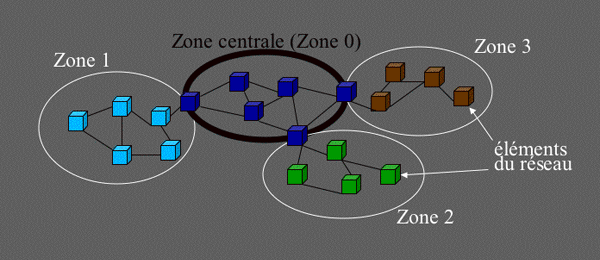
Principe d’un réseau hiérarchique.
Notons une différence fondamentale entre les réseaux filaires et les réseaux sans-fil ad hoc : une diffusion par radio couvre naturellement tout élément venant à se trouver à portée d’antenne, alors qu’une diffusion filaire est plus limitée, n’atteignant que le ou les routeurs connectés à un même câble. Alors que l’ensemble des éléments connectés à un même câble est relativement stable (et donc une unité sur laquelle il est facile de bâtir), l’ensemble des éléments couverts par une portée radio est a contrario relativement instable, en raison des aléas des transmissions radio et de la mobilité éventuelle des éléments.
Afin d’adapter les principes du routage classique aux réseaux ad hoc, des algorithmes qui optimisent ou refondent ces bases ont été mis au point.
Réduction du nombre de transmissions d’information de routage
Un algorithme de routage s’appuie généralement sur un mécanisme permettant à un élément du réseau d’envoyer la même information à tous les autres éléments du réseau. Ce mécanisme de diffusion est par exemple utilisé pour envoyer un message de portée globale dans l’algorithme d’état des liens. C’est la diffusion de tels messages à portée globale qui constitue généralement la grande majorité du trafic de contrôle.
Dans les réseaux filaires, le mécanisme qui assure la diffusion d’un message à travers tout le réseau est simple : à partir de la source du message, tous les éléments du réseau répètent le message quand ils le reçoivent pour la première fois. De cette manière, de proche en proche, tout élément du réseau est assuré de recevoir le message, au moins une fois. Néanmoins, cette méthode génère de nombreuses retransmissions superflues : par exemple, un élément du réseau qui possède de nombreux voisins peut recevoir ce message autant de fois qu’il a de voisins (alors qu’a priori il suffirait qu’il le reçoive une seule fois pour être au courant). Dans les réseaux ad hoc, il s’agit donc d’optimiser le mécanisme utilisé pour réaliser les diffusions, et de maîtriser le nombre de retransmissions redondantes, afin de préserver au maximum la bande passante radio et de limiter les interférences entre voisins.
Pour cela, des techniques spéciales identifient parmi les éléments du réseau les relais qui suffisent à ce qu’une diffusion soit complète. Il existe essentiellement deux types de techniques pour ce faire. La première organise la sélection d’un relais par ses voisins directs, alors que la seconde organise l’autoproclamation de certains éléments du réseau en tant que relais.
Sélection de relais
L’algorithme de sélection se base généralement sur une règle simple (appelée règle du multipoint) : chaque nœud sélectionne comme relais un sous-ensemble de ses voisins directs qui couvre l’ensemble de ses voisins à deux sauts. De cette manière, une information diffusée par un nœud est relayée de proche en proche par les relais, sélectionnés saut par saut, et tout le réseau finit par être couvert avec un nombre de retransmissions réduit. Une particularité de cette technique est que suivant la source de la diffusion, les relais de cette diffusion ne seront pas forcément les mêmes, puisque chaque nœud sélectionne ses relais comme bon lui semble, tant que la règle du multipoint est respectée. Ceci aboutit à une distribution des rôles de relais et du trafic de diffusion.

Le routeur A choisit B et C comme relais. Ainsi, B et C sont seuls à retransmettre les données, au lieu de B, C, D, E, F et G.
Autoproclamation
La règle sur laquelle se base l’algorithme d’autoproclamation (appelée règle du dominant) est plus complexe. Elle utilise l’identité de chaque élément du réseau, par exemple l’adresse IP. Un nœud s’autoproclame relais si le sous-ensemble de ses voisins directs ayant une identité lexicographiquement plus grande que la sienne ne couvre pas tout son voisinage direct. De manière similaire à la technique de sélection, une information diffusée par un nœud est relayée de proche en proche par les relais autoproclamés, et tout le réseau finit par être couvert avec un nombre de retransmissions réduit. Cependant, contrairement à la technique de sélection, avec la technique d’autoproclamation les relais d’une diffusion seront toujours les mêmes quelle que soit la source de cette diffusion. Ceci aboutit à une concentration des rôles de relais et du trafic de diffusion.
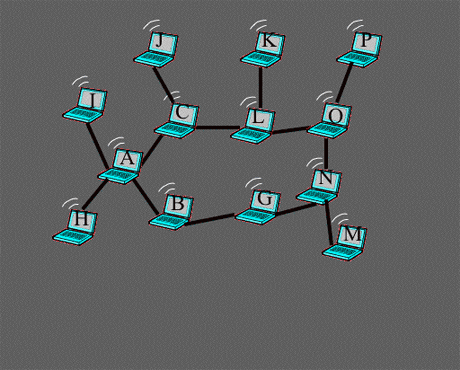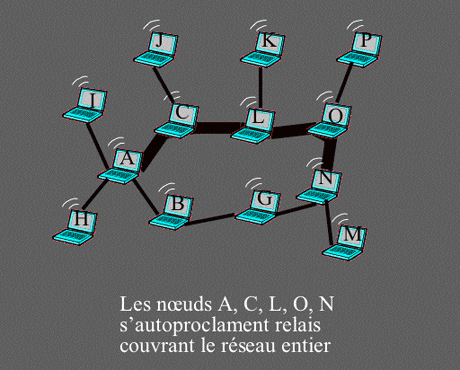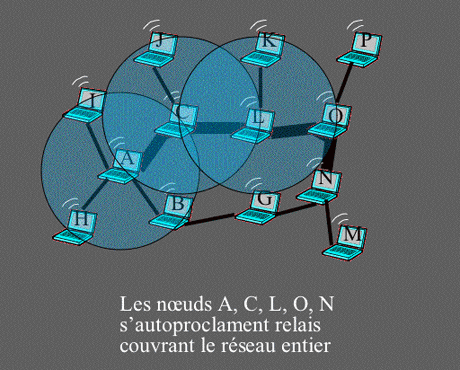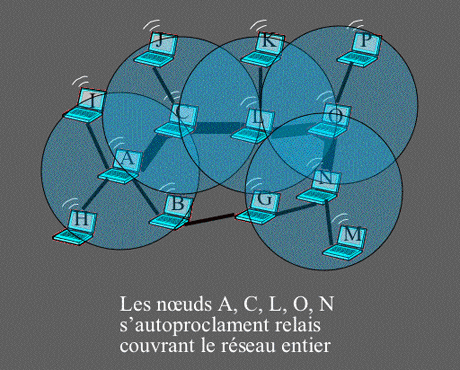
Exemple d’autoproclamation.
Les relais autoproclamés couvent le réseau entier.
Le protocole OLSR est un exemple de protocole de routage ad hoc qui utilise certaines de ces techniques de réduction du nombre de transmissions d’information de routage.
Réduction de la quantité d’information de routage à transmettre
Indépendamment de la réduction du nombre de transmissions, l’autre pan de la réduction du trafic de contrôle dans les réseaux ad hoc est l’optimisation de la taille de l’information à transmettre, et plus précisément la taille des messages à portée globale. Afin de réduire cette taille, plusieurs méthodes sont utilisées. On distingue des méthodes appelées proactives et d’autres réactives.
Méthodes proactives
Un type de méthodes (appelées proactives), identifie en temps réel un sous-ensemble des liens entre les éléments du réseau qui soit suffisant pour que toute paire d’éléments du réseau soit connectée à chaque instant (éventuellement à travers plusieurs liens consécutifs). Les messages à portée globale ne doivent alors contenir que l’information sur les liens appartenant à ce sous-ensemble, au lieu de toute l’information sur tous les liens, ce qui constitue une économie certaine.
Afin d’identifier de manière distribuée le sous-ensemble de liens essentiels pour que chaque paire d’éléments du réseau soit connectée, les algorithmes de sélection ou d’autoproclamation de relais sont réutilisés. Avec un algorithme d’autoproclamation, il est par exemple suffisant que chaque nœud relais envoie périodiquement un message à portée globale contenant l’information à propos de tous ses liens avec tous ses voisins pour qu’il soit garanti que chaque nœud du réseau possède assez d’information pour trouver un chemin jusqu’à tout autre élément dans le réseau.
Cependant, il est à noter que l’utilisation d’un algorithme d’autoproclamation dans ce contexte peut artificiellement allonger les chemins utilisés à travers le réseau. En effet, le fait que l’existence de certains liens ne soit pas connue peut créer des situations au cours desquelles les chemins les plus courts ne sont pas connus, et donc pas utilisés. Afin de remédier à cette carence, on peut utiliser l’algorithme de sélection (à la place de l’autoproclamation). Il est en effet suffisant que chaque nœud du réseau envoie périodiquement un message à portée globale contenant l’information à propos de ses liens avec ses voisins l’ayant sélectionné comme relais pour que qu’il soit garanti que chaque nœud du réseau possède d’assez d’information pour trouver le chemin le plus court jusqu’à tout autre élément dans le réseau. Cette garantie supplémentaire est au prix d’un peu plus d’information de routage à transmettre dans certains cas.
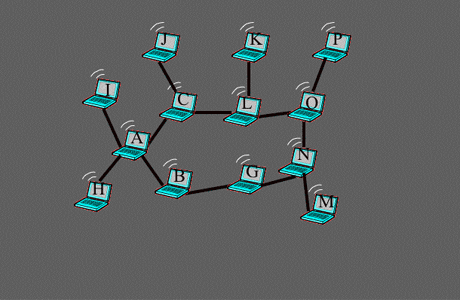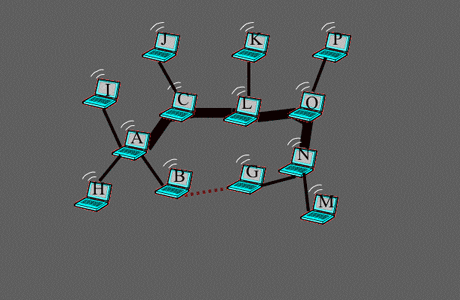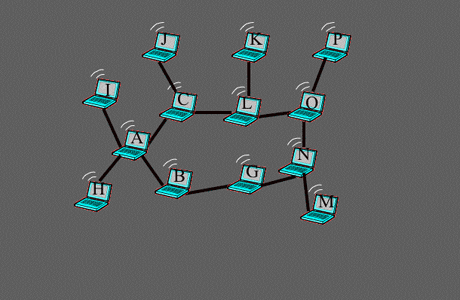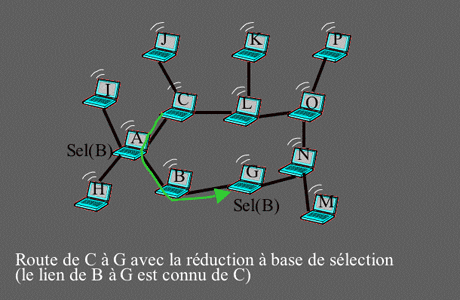
Exemple où l’algorithme de sélection est plus efficace que celui d’autoproclamation.
La route optimale de C à G n’est pas utilisée avec l’algorithme d’autoproclamation, car dans ce cas, le lien de B à G est inconnu de C.
Méthodes réactives
Un autre type de méthodes (appelées réactives), se fonde sur une économie plus poussée, et identifie en temps réel un sous-ensemble de liens suffisant pour acheminer le trafic utilisateur du moment. Seuls ces liens font l’objet d’information de routage. Pour cela, les messages à portée globale ne sont plus envoyés périodiquement, mais seulement à la demande, lorsque du trafic utilisateur doit être acheminé vers une destination vers laquelle un chemin n’est pas connu à ce moment-là.
Dans ce cas, un message à portée globale est diffusé dans tout le réseau, en tant que requête pour établir un tel chemin. La destination (ou un nœud connaissant un chemin vers la destination) recevra alors cette requête diffusée, et pourra y répondre pour établir un chemin, envoyant une réponse rebroussant le chemin pris depuis la source de la requête. La connaissance de ce chemin sera maintenue dans le réseau tant que le trafic utilisateur l’empruntera, puis disparaîtra une fois redevenue inutile.
Ce type de méthode réduit de manière drastique la quantité d’information de routage à transmettre, si un nombre réduit de chemins sont utilisés à travers le réseau, et que les nœuds ne sont pas trop mobiles (par exemple un réseau de capteurs quasi-fixes, rassemblant de l’information à transmettre vers une passerelle de sortie). Il est à noter cependant que les méthodes réactives sont susceptibles de ne pas gérer correctement un trafic utilisateur empruntant des routes trop différentes et trop changeantes.
Le protocole AODV est un exemple de protocole de routage ad hoc qui utilise certaines de ces techniques de réduction de la quantité d’information de routage.
Cloisonnement dynamique du trafic de contrôle
De par leur caractéristique statique, les mécanismes classiques de hiérarchie divisant un grand réseau en zones pseudo-indépendantes ne sont pas adaptés dans un contexte mobile ad hoc. Cependant, comme tous les réseaux, un réseau mobile ad hoc a besoin de mécanismes permettant de cloisonner le trafic de contrôle de certaines zones, afin de pouvoir gérer des topologies de grande taille. La principale difficulté pour ce faire est la dynamique de ces mécanismes de partition, qui doivent établir des zones appropriées en temps réel, et non de manière prédéterminée.
Un des algorithmes utilisables pour le partitionnement dynamique se fonde sur la formation automatisée d’arbres qui se partagent les éléments du réseau. Ces arbres se font et se défont suivant le mouvement des éléments, à partir d’une loi simple : chaque nœud du réseau choisit comme parent son voisin qui possède le plus de voisins. Un nœud étant maximum local est alors son propre parent, c’est-à-dire la racine de l’arbre auquel il appartient. Par ce mécanisme, les autres nœuds s’associent dynamiquement via leur parent à un arbre du réseau. Le réseau dans son ensemble peut dès lors être considéré comme une forêt d’arbres interconnectés, qui définissent dynamiquement une partition du réseau. Cette partition peut alors être utilisée pour cloisonner le trafic de contrôle dans les zones définies, et faciliter l’utilisation de mécanismes de routage hiérarchiques. Cependant, il est à noter qu’une trop grande mobilité des nœuds pourrait fragiliser le routage hiérarchique avec les zones définies par le biais de cet algorithme, les arbres se faisant et se défaisant trop vite.

Formation d’arbres qui se partagent les éléments du réseau.
Chaque nœud du réseau choisit comme parent son voisin qui possède le plus de voisins.
Un autre algorithme utilisé pour cloisonner le trafic de contrôle se fonde sur un principe de perméabilité progressive des messages de contrôle : on reçoit de moins en moins souvent de messages de contrôle générés par un certain nœud au fur et à mesure que l’on s’éloigne de ce nœud. En effet, pour trouver sa route vers une destination très éloignée, on a juste besoin d’une simple direction au début, mais d’informations de plus en plus précises et actuelles au fur et à mesure que l’on s’approche de cette destination. Cette propriété est obtenue à partir d’une loi simple appliquée par chaque nœud du réseau : chaque nœud varie périodiquement la portée de ses messages de contrôle, couvrant plus souvent les éléments du réseau qui sont proches de lui, et moins souvent les nœuds qui sont loin de lui. Cette variation de portée peut se faire de manière assez fine pour que la charge du réseau due au trafic de contrôle reste bornée quel que soit le nombre de nœuds dans le réseau, ce qui permet d’envisager de gérer un réseau ad hoc de très grande taille (théoriquement infinie). Cependant, de manière pratique, on ne peut pas attendre indéfiniment de recevoir les informations nécessaires à propos de nœuds trop éloignés. Avec cet algorithme, on peut donc gérer des topologies mobiles ad hoc très grandes, mais pas de taille infinie.

Variation de la portée des messages de contrôle.
Chaque nœud couvre plus souvent les éléments du réseau qui sont proches de lui, et moins souvent les nœuds éloignés.
Topologie mobiles ad hoc à l’échelle d’Internet
Il est probable que dans un futur pas si lointain, l’Internet s’étendra au delà de l’infrastructure fixe et de sa proximité radio directe, au travers de topologies mobiles ad hoc de tailles variables, incluant divers appareils allant des « smartphones » aux appareils ménagers communicants, et des véhicules de transports aux poussières intelligentes.
Une condition sine qua non pour en arriver à ce point est de trouver la bonne alchimie entre différents algorithmes pour gérer efficacement les grandes topologies mobile ad hoc. Certaines briques évoquées plus haut seront sûrement utilisées, ainsi que d’autres, à venir.
Une de ces briques devra être consacrée à la sécurité sur ces nouveaux moyens de communications. D’une part, l’utilisation de transmissions radio est bien sûr un facteur de danger accru comparé aux transmissions filaires (les écoutes intempestives sont plus faciles, etc.). Ce type de problème est traité par la recherche depuis un certain temps, notamment dans le domaine de la cryptographie. Mais d’autre part, de nouveaux types de problèmes de sécurité sont à considérer. En effet, comme les utilisateurs fournissent eux-mêmes une partie de l’information servant à former le réseau, il faut assurer lors d’une transmission non seulement que l’information reçue est bien conforme à l’information émise, mais aussi que l’information émise est en fait valable. Il s’agit donc de développer des mécanismes pour repérer, identifier, localiser puis isoler les éléments perturbateurs d’un réseau ad hoc, et ce de manière distribuée… une tâche pour le moins ardue.
Par ailleurs, certains problèmes jusqu’ici annexes à ceux rencontrés normalement dans le cadre des réseaux de communications vont devoir être considérés intégralement. Par exemple, le partage des ressources de chacun en énergie (fournies par les batteries de portables) sera central : un utilisateur qui relaie de l’information qui ne lui est pas directement destinée dépense de l’énergie pour la collectivité. Il s’agira donc de trouver un bon équilibre entre l’énergie dépensée pour soi d’une part, et pour les autres d’autre part. Ainsi, toute une gamme de problèmes d’ordre social va devoir être gérée.
Les pistes à emprunter afin de résoudre ces problèmes restent à découvrir. Cependant, des progrès certains ont déjà été réalisés en parallèle dans des domaines jusqu’ici distincts des réseaux ad hoc, comme par exemple les réseaux de pair à pair. Les problèmes qu’ils traitent sont en fait très similaires, à savoir : la formation et la maintenance décentralisées de réseaux de communications. Quelques pistes peuvent donc être à explorer en combinant certaines solutions utilisées dans ces deux domaines.
Newsletter
Le responsable de ce traitement est Inria. En saisissant votre adresse mail, vous consentez à recevoir chaque mois une sélection d'articles et à ce que vos données soient collectées et stockées comme décrit dans notre politique de confidentialité
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
