Gérard Huet, d’une frontière à l’autre
« Le savoir [dans la civilisation indienne], c'est avant tout la parole sonore. L'écrit ne donne accès au savoir que s'il donne accès à la connaissance des sons. » (Charles Malamoud)
Tabler sur l’ordinateur pour aider à la lecture du sanskrit relève de la gageure. Seule la passion de la culture indienne, alliée à celle de l’informatique théorique, pouvait inciter Gérard Huet à en fomenter le projet.

Le sanskrit s’écrit en effet comme il se prononce. Pas d’alphabet, mais des caractères qui transcrivent visuellement une cinquantaine de sons, les phonèmes. Il suffit de connaître ces signes pour lire le texte. Mais avant de pénétrer dans l’univers du sens, il faudra au lecteur de longues années d’étude de cette langue multimillénaire. Un peu comme une partition musicale, l’écrit sanskrit se déroule de manière continue, sans espace ni ponctuation, ou presque. Il en fallait plus pour décourager Gérard Huet.
Entre ciel et terre
Ce directeur de recherche de l’INRIA est de ceux qu’enthousiasme la mise en question des idées reçues. L’une des vertus premières, selon lui, d’un vrai scientifique. Mais la bonne question, celle qui ouvrira la voie à une véritable découverte, ne vient pas toujours de celui qui voue sa vie à la même spécialité. Elle surgit parfois de la bouche de l’« étranger », celui qui a su, à un moment donné, faire ses valises et passer une frontière entre disciplines. « De nombreux problèmes ont des solutions simples auxquelles personne n’a encore pensé. Il suffit quelquefois d’un regard neuf pour les découvrir », indique Gérard Huet.
A priori, rien ne le prédestine à travailler sur le sanskrit, du moins à l’écoute de ce qu’il livre de son jardin secret. En 1966, il intègre Sup-Aéro où il poursuit ses études d’ingénieur et obtient sa licence de pilote d’avion. Il n’abandonnera jamais sa passion du pilotage. Mais professionnellement, il se détourne déjà de la ligne de plus grande pente, et se lance dans l’informatique. Il jette son dévolu sur cette discipline alors naissante, l’aéronautique devient un souvenir. Il entre à l’IRIA (ancêtre de l’INRIA) en 1972, après un PhD aux États-Unis. Outre-Atlantique, c’est l’ébullition autour des problèmes d’intelligence artificielle qui l’avait attiré. Son séjour sera marqué par l’invention d’un algorithme permettant la démonstration automatique de théorèmes, toujours utilisé à ce jour et qui porte son nom.
Escale dans les langages de programmation
Au début des années soixante-dix, les espoirs mis dans la démonstration automatique excitent les esprits. À l’IRIA, à Rocquencourt (Ile-de-France), se monte une équipe d’informatique théorique très dynamique. « Le bâtiment 8 était un environnement particulièrement stimulant, avec des locomotives telles que Gilles Kahn, Jean Vuillemin, Philippe Flajolet, Jean-Jacques Lévy et beaucoup d’autres », se souvient Gérard Huet.

Le bâtiment 8 était un environnement particulièrement stimulant, avec des locomotives comme Gilles Kahn [légionnaire Qui peu le plus], Jean Vuillemin [Cosmique honoraire], Philippe Flajolet [Algorithmix], Jean-Jacques Lévy [Paralytix] et beaucoup d’autres, se souvient Gérard Huet [Camélix] (d’après l’affiche originale réalisée par Philippe Jacquet, chercheur à l’INRIA).
Le modèle pour ces jeunes chercheurs : le groupe d’intelligence artificielle de l’Université d’Edimbourg, avec notamment Rod Burstall, Robin Milner et Gordon Plotkin. L’équipe française va se distinguer pour ses avancées dans la sémantique des langages de programmation et la logique computationnelle.
Nous sommes au début des années quatre-vingts quand naît le langage Caml, dont Gérard Huet est l’initiateur. Ce langage est de la famille du langage ML (Meta-Language), inventé par les collègues d’outre-Manche. « Caml et Coq sont allés de pair », précise Gérard Huet. C’est en effet encore à lui, avec Thierry Coquand, l’un de ses brillants élèves, que la communauté informatique doit le calcul des constructions, et les premières versions du système Coq d’aide à la preuve qui en est issu.
À n’en pas douter, ce rappel de quelques grandes étapes de l’itinéraire scientifique de Gérard Huet parlera plus à l’initié qu’au profane. Reste que pour ce dernier, il évoquera la diversité des thèmes abordés par ce chercheur, et plus généralement la diversité des sujets qui s’offrent à un scientifique un tant soit peu curieux, en Sciences de l’information et de la communication.
De 1970 à 1976, Gérard Huet travaille sur l’unification dans le lambda-calcul typé et d’autres langages logiques, thème sur lequel il passera sa thèse. Dès 1972, il fait partie des chercheurs de l’institut qui s’appelle alors IRIA (l’ancêtre de l’INRIA), et qui prend une dynamique nouvelle sous la houlette du professeur Jacques-Louis Lions. De 1973 à 1978, avec Gilles Kahn notamment, il conçoit et réalise l’éditeur structuré Mentor. Il s’engage ensuite dans des recherches sur la démonstration automatique en logique équationnelle et sur la réécriture algébrique, jusqu’en 1983. Il profite de son année sabbatique au Stanford Research Institute (États-Unis), en 1980, pour mettre au point, avec Jean-Marie Hullot, le système de preuves KB, en VLISP.
De retour à l’INRIA, c’est entre 1982 et 1989 qu’il participe au développement du langage de programmation fonctionnelle Caml, dans le cadre du projet FORMEL. Pendant cette période, en 1985, il s’envole pour une autre année sabbatique, à l’université Carnegie Mellon cette fois. Et dans les années quatre-vingt-dix, il conçoit et réalise avec Thierry Coquand et Christine Paulin-Mohring, la première version du système Coq, assistant de preuves. En parallèle, il coordonne les travaux d’un consortium européen (Logical Frameworks puis Types), et invente les structures de focus en contexte.
Puis pendant trois ans, il devient le délégué aux relations internationales de l’INRIA, avant de revenir à la recherche. C’est alors qu’il conçoit une boîte à outils Zen de manipulation phonologiques et morphologiques en Objective Caml, qui permet la segmentation et l’étiquetage du sanskrit. En 2003, il est dans l’équipe SIGNES de linguistique computationnelle, et étudie l’interface syntaxe / sémantique.
Entre l’Institut de France et la culture indienne
Son élection comme membre de l’Académie des sciences, en novembre 2002, couronne ces résultats, et bien d’autres non évoqués ici, dans le domaine de la logique et de la mécanisation du raisonnement. Il s’est en outre déjà fait une solide réputation dans le domaine du sanskrit, avec le premier dictionnaire sanskrit-français en ligne. A-t-il ainsi tourné le dos à l’édifice conceptuel qu’il avait patiemment construit, pendant une trentaine d’années ? Loin de là : « Le traitement de la langue naturelle, ce qu’on nomme linguistique computationnelle, se situe au carrefour entre la linguistique, la logique et l’informatique ». Avec la logique et l’informatique, il est en pays de connaissance. Reste à mettre en œuvre les outils théoriques dont il dispose pour parvenir à « segmenter » le texte sanskrit de manière cohérente, au regard de sa sémantique, de sa syntaxe, de sa morphologie.
On trouve dans la Bhagavadgita, le texte le plus sacré de l’Inde, le vers suivant (24[2]17) :
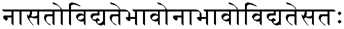
En caractères latins, la transcription est la suivante : nasatovidyatebhavonabhavovidyatesata.h.

Un manuscrit sanskrit ancien sur feuille de palmier, de l’Oriental Research Institute (Mysore).
© Gérard Huet.
Le philosophe advaita (non dualiste) Shankara (VIIIème siècle) l’interprète ainsi :
« NA ASATA.H VIDYATE BHAVA.H NA ABHAVA.H VIDYATE SATA.H »
Soit : « DE L’IRRÉEL NE VIENT PAS L’ÊTRE, LE NÉANT NE VIENT PAS DU RÉEL ».
Son adversaire dvaita (dualiste) Madhva (XIIIème siècle) lit ce vers ainsi :
« NA ASATA.H VIDYATE ABHAVA.H NA ABHAVA.H VIDYATE SATA.H »
Soit : « DE L’IRRÉEL NE VIENT PAS LE NÉANT, LE NÉANT NE VIENT PAS DU RÉEL ».
Il ne s’agit pas juste d’une interprétation philosophique différente, il s’agit d’abord d’une lecture grammaticale différente permise par les règles de transformation phonétique, qui induisent un non-déterminisme de la segmentation de la phrase en mots. On voit la difficulté de l’analyse de la phrase sanskrite, qui peut comme ici introduire une négation, ou ne pas l’introduire. De la présence ou de l’absence de cette négation vient ici le néant ou l’être.
Gérard Huet
Les problèmes d’ambiguïtés ne sont pas les moindres. Ces ambiguïtés de sens, on les rencontre de manière similaire en reconnaissance de la parole, quelle que soit la langue. Contrairement à l’écrit en effet, la segmentation en mots de la langue parlée, et donc sa compréhension, suppose implicitement la connaissance du vocabulaire et de la syntaxe. S’ajoute à cela l’utilisation volontaire, par les auteurs de textes sanskrits, de mots polysémiques. L’informaticien se trouve alors confronté à l’identification d’un procédé productif déterministe, celui intentionnel de l’écriture d’une phrase, par des techniques d’analyse nécessairement non déterministe : celles-ci doivent permettre d’évaluer la probabilité des différentes solutions possibles. Parmi les outils utilisés : des concepts logiques, algorithmiques, des techniques d’automates finis…
Réapprendre à déchiffrer le texte ?
Mais comment valider la « lecture » de l’ordinateur ? Comment savoir si cette mécanisation d’un processus, traditionnellement considéré comme intelligent, conduit à l’interprétation juste ? C’est-à-dire à la restitution rigoureuse du texte voulu par son auteur ? C’est un problème de linguistique, pour lequel Gérard Huet s’efforce de monter une collaboration avec des collègues sanskritistes. Quant à la méthodologie mise en œuvre, est-elle transposable pour d’autres problèmes de linguistique computationnelle ? Il l’espère. Ce détour par une langue si étrangère, a priori, aux langues occidentales pourrait bien porter ses fruits là où on ne s’y attendait pas. Un regard neuf, de l’étranger, sur nos langues alphabétiques.
Newsletter
Le responsable de ce traitement est Inria. En saisissant votre adresse mail, vous consentez à recevoir chaque mois une sélection d'articles et à ce que vos données soient collectées et stockées comme décrit dans notre politique de confidentialité
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
