La programmation des grilles informatiques
L’image idyllique du chercheur qui, pour disposer d’un maximum de puissance, brancherait son ordinateur à une grille informatique aussi aisément que s’il allumait la lumière, est encore une utopie. Porter une application scientifique sur une grille reste une affaire de spécialiste. La principale raison à cela réside dans l’hétérogénéité des grilles : une grille, ce sont des centaines – voire des milliers – de processeurs parfois différents les uns des autres, gérés par des systèmes d’exploitation de plusieurs types, et qui communiquent entre eux via des réseaux de natures variées. Conséquence de cette hétérogénéité : aucune solution de programmation ne s’est encore distinguée. Le paysage de la programmation des grilles informatiques propose plusieurs itinéraires.
La solution la plus naturelle pour porter une application sur une grille informatique est d’étendre les techniques de programmation employées sur les machines parallèles des centres de calculs. Dans le cas du calcul parallèle, le code est morcelé en tâches qui seront exécutées sur des processeurs distincts. Prenons l’exemple d’une simulation numérique de l’aérodynamisme d’un avion. Les équations qui régissent le comportement aérodynamique sont résolues dans le volume de l’espace correspondant au fuselage. Ce volume est discrétisé par un maillage, dont les morceaux sont distribués à des processeurs distincts, qui effectueront donc des calculs sur une partie du problème seulement. De nombreux codes de calcul parallèles sont ainsi développés suivant ce principe, s’appuyant presque toujours sur le standard MPI de programmation parallèle par « échange de messages » entre processeurs. Pour porter ces codes sur une grille – opération qu’on appelle « gridifier » – on peut ensuite faire appel à une infrastructure logicielle clé en main, comme Globus, qui se charge de dispatcher les calculs non pas sur les processeurs d’une machine mais sur tout le réseau. Le problème est que les versions standard de ces logiciels ignorent l’hétérogénéité des grilles, ce qui les rend très peu efficaces.
Des objets pour véhiculer les requêtes
Pour améliorer les performances de ces codes, des informaticiens ont recours au concept d’objets distribués. Les objets informatiques sont les stricts équivalents numériques des objets réels. Comme eux, ils possèdent des attributs (l’équivalent du fait qu’il s’agit d’une voiture ou d’une paire de ciseaux), une identité (le numéro de série de la voiture), et une utilisation spécifique (une paire de ciseaux sert à couper). L’intérêt des objets est essentiellement de simplifier la programmation. Un programme qui fait appel à des objets est plus lisible, plus condensé, qu’un programme écrit d’un seul tenant – de la même manière qu’il est plus rapide de décrire un salon en disant qu’il contient une table plutôt que quatre tiges de bois surmontées d’une plaque horizontale. Dans leur version distribuée, les objets peuvent résider n’importe où sur un réseau en tant qu’entités autonomes, et communiquer librement entre eux. Imaginons une simulation numérique programmée avec des objets distribués qui cherche à effectuer un calcul sur une grille. La simulation enverra sur le réseau un objet « calcul » qui possèdera les paramètres du calcul à exécuter et la nature du calcul. Au premier carrefour du réseau, cet objet sera intercepté par un serveur, qui l’interrogera sur sa fonction. L’objet lui répondra : « mon unique fonction est de donner tels paramètres en entrée et d’attendre qu’on effectue dessus telle opération » (autrement dit « je suis une paire de ciseaux et je cherche des feuilles de papier à couper »). L’objet possède ainsi une certaine autonomie ; il intervient seul dans la transaction avec les serveurs, sans faire appel à l’ordinateur de départ. Le serveur aiguillera ensuite l’objet calcul vers la bonne machine, où il remplira sa mission.
La méthode la plus sûre pour rendre ces objets compatibles avec l’ensemble du parc informatique d’un réseau hétérogène consiste à les programmer en langage informatique Java. Java a été conçu précisément pour permettre l’exécution du même code informatique sur tous les systèmes d’exploitation. C’est par exemple le parti pris par l’équipe OASIS (de l’INRIA, du CNRS et de l’université de Nice Sophia Antipolis). OASIS a en outre développé des technologies logicielles innovantes, telle la localisation d’objets mobiles, grâce à laquelle un calcul peut être débuté sur une machine et transféré sur une autre en cours d’exécution.
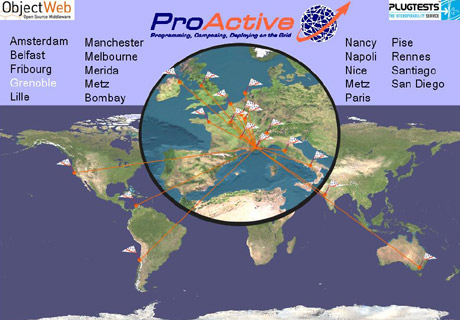
Les 800 processeurs du plugtest, répartis dans 20 villes pour 12 pays différents.
Le résultat de ces travaux est ProActive, un intergiciel open source qui a séduit aussi bien des institutions académiques que des industriels. Pour les industriels, l’emploi de la programmation par objets facilite la gridification d’applications, car il s’agit de la méthode typique de programmation des ingénieurs développeurs. L’ETSI, un organisme européen de standardisation des télécommunications, a organisé fin 2004 un plugtest (une rencontre où les ingénieurs viennent confronter leur logiciels en situation réaliste), où ProActive a pu démontrer ses capacités. Une application construite avec le logiciel a en effet été déployée sur pas moins de 600 machines réparties sur une vingtaine de sites distribués sur toute la planète et spécialement mis en réseau pour l’occasion. La gridification d’une application de ce type sur des matériels aussi hétérogènes (PC, stations Sun… pour les processeurs ; Windows, Linux, Solaris… pour les systèmes d’exploitation) a été une première.
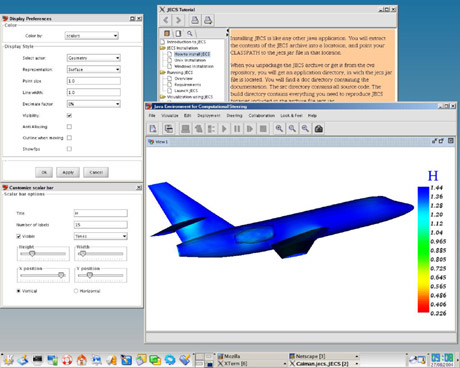
Capture d’écran d’une application développée avec ProActive.
(Image : équipe CAIMAN, INRIA).
Des composants à réutiliser
L’approche par objets reste valable seulement pour certaines applications scientifiques. Les simulations numériques développées par les chercheurs eux-mêmes sont généralement écrites d’un seul tenant et de ce fait ne peuvent pas être dispatchées en objets. Toutefois, elles sont de plus en plus constituées de plusieurs pans, plus ou moins indépendants, qui, eux, peuvent être séparés. La science moderne aime en effet à mélanger les genres : prévoir le climat en faisant interagir les remous des océans et les humeurs de l’atmosphère, étudier la dynamique du réseau sanguin grâce des modèles mêlant l’hydrodynamique (pour le flux du sang) et la mécanique des solides (pour la dilatation des veines). Généralement, ces sous-parties de simulations sont issues de travaux différents et constituent des programmes à part entière. D’où l’idée récente de ne pas les regrouper comme le voulait l’usage, mais de les laisser dissociées à l’intérieur d’entités informatiques indépendantes de grande envergure : les composants.
L’idée de la programmation par composants est ancienne, mais a seulement été concrétisée dans les années quatre-vingt-dix. Les codes se sont alors mis à incorporer des centaines voire des milliers d’objets, ce qui rendait l’architecture sous-jacente du programme invisible. Le principe de la programmation par composant est de décomposer le code global en briques de programmation – les composants – de taille modeste et donc aisément gérables. On retrouve là une philosophie identique à celle qui a poussé à créer les objets, mais à un niveau hiérarchique plus haut. Pour les applications scientifiques, l’avantage d’utiliser ce type de programmation est double : non seulement les composants, ou sous-modèles, peuvent être exécutés de façon autonome, un tiers-programme se chargeant de décrire leur interaction, mais ils pourront aussi être réutilisés ensuite dans d’autres simulations ; le modèle de diffusion du sang pourra être réemployé pour une simulation des battements du cœur par exemple.
L’une des opérations à réaliser pour transformer un morceau de code en composant est l’« encapsulation ». Encapsuler consiste à masquer la complexité interne du code. Ainsi le code se réduit, en entrée, aux paramètres nécessaires pour qu’il effectue le calcul, et, en sortie, aux résultats du calcul. Cette opération limite le risque de bug : aucune définition de fonction ou de paramètre n’est commune à plusieurs composants ; les composants sont véritablement indépendants. Or rien dans les environnements de programmation n’est prévu de façon standard pour « encapsuler » les codes parallèles à l’intérieur de composants. L’équipe PARIS (de l’INRIA, du CNRS, de l’ENS-Cachan, de l’université de Rennes 1 et de l’INSA-Rennes), est la première à développer une plate-forme complète de développement, Padico, permettant de le faire. Cette plate-forme comprend aussi l’intergiciel GridCCM, qui permet aux composants de s’échanger efficacement des données lorsque les composants encapsulent des codes de calcul parallèle.
 |
 |
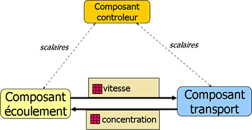
| Principe du couplage entre composants. Les composants « écoulement » et « transport » s’échangent les champs physiques (la vitesse est l’inconnue principale de l’écoulement, et sert de « moteur » au transport, la concentration en sel est calculée par le transport, et sert à modifier la densité, qui permet de calculer l’écoulement). Ces échanges représentent un volume de données important. Les échanges avec le composant contrôleur sont beaucoup plus limités (quelques valeurs de contrôle). Image : Michel Kern, INRIA. |
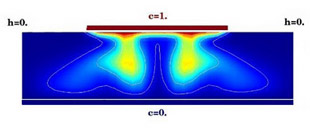
Exemple de calcul. Dans l’expérience d’Elder (cas test classique du domaine), on verse du sel sur la partie rouge au sommet du bassin rectangulaire, initialement rempli d’eau douce. Le sel, étant plus lourd, descend par gravité, mais l’évolution provoque des digitations instables (de façon analogue aux instabilités de Rayleigh-Taylor). Les lignes représentent les iso-concentrations en sel (de 1 au sommet, à 0 en bas du bassin). Image : Caroline de Dieuleveult, Édouard Canot et Jocelyne Erhel (équipe SAGE, IRISA). |
GridCCM a notamment été utilisé pour mettre en œuvre pour l’une des premières fois en France le principe de programmation par composants dans une application de calcul scientifique, à l’occasion d’une collaboration, financée dans le cadre de l’ACI GRID, entre les laboratoires de Géosciences de Rennes, l’Institut de mécanique des fluides et des solides de Strasbourg et trois équipes de l’INRIA (SAGE, PARIS et ESTIME). L’un des buts du projet était de modéliser l’intrusion d’eau de mer dans les nappes d’eau souterraines, en couplant, grâce à des composants, deux simulations numériques, l’une concernant le transport du sel par l’eau douce, et l’autre le déplacement d’eau dans la roche.
Quels que soient les modes de programmation adoptés pour déployer une application sur une grille – méthodes standard, par objets distribués ou par composants -, ces techniques doivent prouver leur efficacité à grande échelle, sur un réseau dense d’ordinateurs hétérogènes.

Grappe de PC de l’IRISA qui participe à Grid’5000.
© INRIA / Photo Jim Wallace
Internet paraît le bon candidat pour ce réseau, mais ses possibilités sont en réalité très limitées. Impossible par exemple de contrôler le cheminement et la vitesse des fichiers. Parce qu’Internet a été conçu à l’origine avec des visées militaires, le protocole standard de communication d’Internet (qui définit comment deux machines dialoguent), TCP/IP, a en réalité un seul but : assurer la robustesse des transmissions d’un maximum d’utilisateurs. C’est-à-dire garantir leur bon acheminement quels que soient les obstacles sur le trajet (nœuds du réseau en panne, lignes coupées, embouteillages…), ce qui implique que les données ne sont envoyées qu’après plusieurs tests qui vérifient si l’intégrité des informations est garantie sur la ligne. La vitesse des communications en souffre. Internet n’étant donc pas le lieu idéal d’expérimentation, la France s’est dotée en septembre 2004 de Grid’5000, premier instrument permettant l’étude des grilles informatiques à grande échelle. Il relie des grappes (des réseaux à petite échelle d’ordinateurs hétérogènes) situées dans une dizaine de laboratoires répartis dans tout l’hexagone. Il s’agit d’une première par le nombre de processeurs (5000 à terme) et également par la possibilité donnée aux chercheurs de maîtriser l’intégralité des paramètres de la grille. Les chercheurs français misent beaucoup sur Grid’5000 pour faire émerger les technologies de grille les plus efficaces.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
