
La carotte et le bâton… et Tetris
1. Apprendre à jouer à Tetris… en théorie
Les êtres vivants ont naturellement la capacité d’améliorer, au fil de leurs expériences, leurs réactions à l’environnement : ainsi, face à une situation donnée, une action entraînant une sensation agréable à plus ou moins long terme sera davantage choisie dans des circonstances analogues qu’une action suivie d’une réponse moins favorable.
L’apprentissage par renforcement a pour objectifs la compréhension et la conception de systèmes informatiques possédant cette aptitude : comment, par exemple, concevoir un programme informatique qui serait capable d’apprendre de façon autonome à jouer à Tetris ? La sensation, agréable ou non, est remplacée par une récompense numérique, positive (une carotte) ou négative (un coup de bâton). Le programme va alors expérimenter les différentes actions qui s’ouvrent à lui au cours du jeu. Petit à petit, pour chaque situation, le programme devra apprendre à choisir les « bonnes » actions. Toute la difficulté réside dans la nécessité de trouver de bons compromis :
- Faut-il explorer l’environnement, au risque d’effectuer de mauvaises actions, ou faut-il exploiter en priorité les actions déjà connues comme étant bonnes, au risque de ne jamais découvrir de meilleures actions ?
- Est-il important d’obtenir immédiatement une récompense élevée, au risque d’avoir de nombreuses récompenses négatives plus tard ?
Modéliser Tetris comme un Processus de Décision Markovien
Initialement inspiré par des travaux en psychologie et développé par la communauté de l’intelligence artificielle, l’apprentissage par renforcement est aujourd’hui reconnu comme un problème entrant dans le cadre mathématique du contrôle optimal, et peut s’appuyer sur un modèle formel qui porte le nom de « Processus de Décision Markovien » (PDM). Un PDM permet de décrire d’une façon générale un agent informatique qui prend des décisions de sorte à bien contrôler un système. À chaque instant, l’agent observe l’état du système. À partir de cet état, l’agent choisit une action. Cette action a deux effets immédiats : le système évolue vers un nouvel état et l’agent reçoit une récompense (ou subit un coût). À l’instant suivant, l’agent se trouve dans une situation analogue, à ceci près que l’état du système peut être différent et que l’agent devra de nouveau faire le choix d’une action, qui ne sera pas forcément la même.

Principe d’un Processus de Décision Markovien.
Le terme « Markovien » désigne un système qui vérifie une propriété fondamentale : la propriété de Markov. Celle-ci signifie que lorsque le système est dans un état, et que l’agent effectue une certaine action, l’état suivant et la récompense obtenue ne dépendent que de l’état actuel, et pas des états précédents. En d’autres termes, le passé (la manière d’être arrivé jusqu’à l’état actuel) n’a plus d’importance, seul le présent (l’état actuel) a une influence sur le futur.
Modéliser un problème sous la forme d’un PDM revient à définir l’ensemble des états du système, l’ensemble des actions de l’agent, la dynamique du système (comment on passe d’un état à un autre), ainsi que les récompenses et les coûts. Pour nous familiariser avec les PDM, voici comment nous pourrions modéliser le jeu de Tetris.
Célèbre jeu vidéo créé en 1985 par Alexey Pajitnov, Tetris est un jeu de réflexion dans lequel le joueur doit empiler des pièces de différentes formes de manière à créer des lignes horizontales. Les pièces tombent les unes après les autres depuis le haut de la zone de jeu. Le joueur peut faire pivoter la pièce courante et la déplacer horizontalement, afin de la placer comme il le souhaite sur les pièces déjà posées. Il existe 7 pièces différentes.
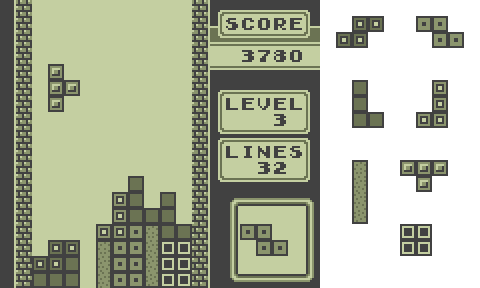
Le jeu de Tetris original.
Une fois la pièce posée, une nouvelle pièce arrive, choisie aléatoirement uniformément parmi les 7 pièces existantes. Chaque fois qu’une ligne horizontale est pleine, celle-ci est supprimée. Tout ce qui est au-dessus descend d’une ligne et le joueur marque un point. La partie est perdue lorsqu’il n’y a plus de place en haut de la zone de jeu pour poser une nouvelle pièce. L’objectif est de réaliser le plus grand nombre de lignes possibles avant de perdre la partie.
On sait aujourd’hui qu’une partie de Tetris ne peut pas durer indéfiniment : quelle que soit la qualité du joueur, il existe des séquences de pièces qui finiront toujours par arriver et qui feront perdre la partie. Par ailleurs, on sait que Tetris est un problème très difficile à résoudre : même si la séquence des pièces est connue à l’avance, calculer un comportement optimal est un problème NP-complet.
Après une courte réflexion, les choix suivants s’imposent :
- L’état contient deux informations : la configuration actuelle du mur et la pièce courante.
- Une action est également composée de deux informations : la colonne et l’orientation dans lesquelles on va lâcher la pièce courante.
- La dynamique, rappelons-le, décrit comment on passe d’un état à un autre quand on choisit une action ; elle découle donc de la définition des états et des actions. Étant donné un état et une action, c’est-à-dire un mur et une pièce qu’on vient de lâcher, on obtient un nouveau mur (sans oublier l’éventuelle suppression des lignes qui pourraient se trouver complétées)… et pour avoir un nouvel état (un état contient un mur et une pièce !), il faut encore préciser comment sera choisie la prochaine pièce : on en sélectionne une aléatoirement avec une probabilité uniforme.
- Finalement, la récompense est d’évidence le nombre de lignes qui sont complétées au moment où on pose la pièce courante.

Application au jeu de Tetris d’un Processus de Décision Markovien.
Valeur et décisions optimales
Pour l’instant, nous avons simplement décrit un modèle… Comment faire maintenant pour que notre programme de Tetris prenne de bonnes décisions ? Que doit-on mettre dans notre programme pour qu’il reçoive le plus de récompenses lors de ses parties ? L’apprentissage par renforcement, qui a pour but de trouver la séquence d’actions qui maximise les récompenses, est la solution que nous allons envisager ici.
Les mathématiciens du contrôle optimal, dont notamment Richard Bellman, ont eu l’idée remarquable d’introduire le concept de valeur optimale. La valeur optimale d’un état est la somme maximale des récompenses qu’il est possible de recevoir en moyenne à partir de cet état. Les algorithmes d’apprentissage par renforcement cherchent à calculer la valeur optimale de chaque état. Si on connaît cette valeur pour chaque état, il est alors facile de choisir la meilleure action à faire dans un état donné : c’est tout simplement celle qui mène à des états dont la valeur optimale est la plus grande. On montre que lorsque la propriété de Markov est vérifiée, la valeur optimale est la solution d’une équation particulière, dite équation de Bellman. Cette équation établit une relation entre la valeur optimale d’un état et la valeur optimale des états auxquels il peut mener. Ainsi, on a une équation pour chaque état, et trouver la valeur optimale de toutes les états revient à résoudre le système composé de l’ensemble de ces équations. On peut par exemple résoudre ce système par un algorithme de « programmation dynamique ».
À partir d’un état s, si on fait l’action a, si on arrive dans l’état s’ et si ensuite on agit optimalement, le cumul des récompenses sera :
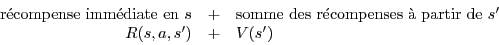
où R(s,a,s’) est la récompense lorsqu’on fait l’action a dans l’état s et qu’on arrive dans l’état s’, et V(s’) la valeur optimale de l’état s’.
On ne sait pas exactement dans quel état s’ on va arriver car s’ dépend aléatoirement de l’état et de l’action, ce que l’on note s’~suivant(s,a). Il est alors naturel de considérer le retour moyen si l’on fait l’action a à partir de l’état s, c’est-à-dire :
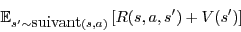
Ce qui nous intéresse au fond, c’est le meilleur retour moyen à partir de l’état s :
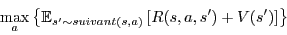
Par définition, c’est aussi la valeur optimale V(s). La valeur optimale satisfait donc le système d’équations suivant :
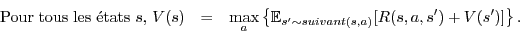
C’est ce qu’on appelle l’équation de Bellman.
Pour illustrer cette équation et le calcul de sa solution, la valeur optimale, considérons un problème simple dans lequel un rat se déplace dans un labyrinthe pour y trouver un fromage.
Calcul de la valeur optimale de chaque état pour un rat dans un labyrinthe.
Dans chaque case du labyrinthe, qui sont donc les états de notre Processus de Décision Markovien, on voudrait que le rat apprenne à choisir la meilleure action pour rejoindre au plus vite le fromage. Nous considérons que les 5 actions du rat sont : haut, bas, droite, gauche, rester. Après chaque action, le rat reçoit une « récompense » de -1 et une « récompense » de -4 quand il se cogne dans un mur.
Dans le cas du petit labyrinthe :

et lorsque les déplacements du rat ne sont pas bruités, l’équation de Bellman caractérisant la valeur optimale s’écrit
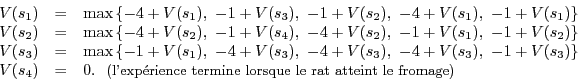
Pour calculer la valeur optimale de chaque case du labyrinthe dans ce contexte, on utilise un algorithme de programmation dynamique, Itérations sur les valeurs, qui à chaque étape, donne une estimation de plus en plus précise de valeur optimale d’une case.
Au début du calcul, la valeur optimale V(s) estimée de chaque case s est initialisée à 0. À chaque itération de l’algorithme, on améliore l’estimation de la valeur optimale de chaque case s en utilisant l’équation de Bellman de la manière suivante :
- pour chaque case s, la nouvelle estimation de sa valeur optimale, que l’on note NV(s) est celle donnée par le côté droit de l’équation de Bellman:
- pour chaque case s, la nouvelle estimation devient l’estimation courante de la valeur optimale : V(s) devient NV(s).
- si l’estimation de la valeur optimale n’est pas assez précise, on recommence à l’étape 1). L’erreur d’estimation est directement proportionnelle à la différence entre l’ancienne estimation V(s) et la nouvelle NV(s). Pendant le calcul, l’erreur courante sur la précision du calcul est affichée sur la ligne du bas de l’application.
À tout moment du calcul, les flèches indiquent pour chaque case l’action optimale à effectuer en fonction de la valeur optimale courante. S’il n’y a pas de flèche, le rat n’essaiera pas de bouger.
Plusieurs paramètres influencent le calcul de cette valeur optimale :
- précision (réel supérieur à 0.0001) : le calcul de la valeur optimale se poursuit tant que cette précision n’est pas atteinte.
- bruit (entre 0 et 1) : ce paramètre permet de rendre le sol glissant. Ainsi, par exemple, un rat qui VEUT aller à gauche réussit son mouvement avec une probabilité de (1-bruit), sinon sa véritable action est prise au hasard parmi les autres actions.
On peut remarquer que, quand il n’y a pas de bruit, le rat aura tendance à suivre le plus court chemin. On remarque d’ailleurs que, sans bruit, la valeur optimale d’une case est égale à « moins la longueur du chemin jusqu’au fromage ». Par contre, si on augmente le bruit, le rat s’éloignera aussi des murs par peur de glisser vers eux. On peut s’en rendre compte avec, par exemple, un niveau de bruit supérieur ou égal à 0,2 dans le « grand » environnement.
Revenons à présent à Tetris. Dans ce cadre, comme la récompense est le nombre de lignes que l’on vient de compléter, optimiser la somme des récompenses revient à maximiser le nombre de lignes effectuées durant une partie, c’est-à-dire le score ! Et la valeur optimale introduite par les mathématiciens est tout simplement le meilleur score moyen à venir si dans une configuration du mur on lâche la pièce courante de telle ou telle manière. Comme précédemment, le mieux est évidemment de choisir l’endroit qui nous prédit le meilleur score ou encore la plus grande valeur optimale. On mesure ici la beauté de la théorie du contrôle optimal : si on est capable de calculer cette valeur optimale, c’est-à-dire simplement de résoudre une équation, on peut immédiatement en déduire comment jouer à Tetris de façon optimale.
Mais qu’en est-il en pratique ?
2. Construction pratique d’un contrôleur pour Tetris
Le jeu de Tetris comprend 10×20 =200 cases. Chaque case du jeu peut être vide ou pleine. Il y a donc à peu près 7×2200 = 1060 états… et environ une trentaine d’actions. C’est beaucoup trop pour que l’on puisse espérer résoudre l’équation de Bellman avec suffisamment de précision, voire même stocker le résultat dans un ordinateur. Même en stockant 10 milliards de valeurs dans un ordinateur, il faudrait 1050 ordinateurs pour stocker la valeur optimale de tous les états ! Or, il n’y a qu’un milliard d’ordinateurs (109) dans le monde…
Résolution exacte d’un mini-Tetris
Contrôleur optimal de mini-Tetris 5×5.
Pour commencer, considérons une version réduite du jeu de Tetris, un mini-Tetris en quelque sorte. Si, au lieu des 10×20 cases, on joue sur un jeu contenant seulement 5×5 cases, alors les calculs et le stockage des valeurs optimales deviennent possibles.
Dans ce cas, il y a un peu moins de 225 murs possibles, et donc un peu moins de 7×225 soit environ 230 millions d’états. Avec un ordinateur de bureau actuel, un algorithme de programmation dynamique, et un peu de patience (une centaine d’heures de calculs), on peut résoudre l’équation de Bellman : on dispose alors des valeurs optimales pour toutes les situations qui pourraient survenir et on en déduit la manière optimale de jouer au mini-Tetris.
Le concept de valeur optimale est intéressant à bien des égards. En regardant la valeur calculée pour les états correspondant au début d’une partie (qui rappelons-le est égale au meilleur score que l’on peut obtenir), on peut voir que si on joue de nombreuses fois à ce mini-Tetris, on fera entre 13 et 14 lignes en moyenne par partie. On sait de plus qu’on ne peut pas faire mieux…
Voulez-vous vous mesurer à ce contrôleur optimal ?
Résolution approchée du jeu de Tetris original
Est-on contraint de se limiter au mini-Tetris (5×5) ? Est-il désespéré de s’attaquer au jeu de Tetris original (10×20) ? Pas tout à fait : s’il est impossible de résoudre exactement l’équation de Bellman, nous pouvons essayer de la résoudre approximativement.

Contrôleur approximativement optimal pour jeu de Tetris 10×20 (début d’une partie).
Le très grand nombre d’états de ce jeu pose concrètement deux problèmes :
- Le système d’équations que nous souhaitons résoudre contient autant d’équations qu’il y a d’états !
- Comme nous l’avons déja mentionné, même si nous étions capables de les calculer, il serait impossible de stocker les valeurs optimales pour l’intégralité des états !
La solution conjointe à ces deux difficultés repose sur deux idées fondamentales :
- La première idée est de laisser le programme jouer un certain nombre de parties et de considérer uniquement les états observés. On espère ici que se limiter à un sous-ensemble suffisamment représentatif des états suffira à donner une bonne approximation au système d’équations original.
- La seconde idée consiste à utiliser une fonction paramétrée, c’est-à-dire un moyen d’estimer la valeur optimale d’un état donné à partir d’un nombre réduit de paramètres. L’astuce est qu’au lieu de stocker autant de valeurs que d’états, il suffira de stocker les paramètres de notre fonction (on a typiquement quelques dizaines ou centaines de paramètres).
Les techniques d’apprentissage par renforcement exploitent alors le déroulement de ces parties (les états visités et les récompenses obtenues) afin de régler les paramètres de l’architecture d’approximation, de sorte qu’elle fournisse des valeurs aussi proches que possible de la valeur optimale, autrement dit du score futur qu’il est possible de réaliser. Ainsi, à l’image d’un animal dans son environnement, notre programme exploite sa propre expérience afin d’améliorer son comportement.
Avec une vingtaine de paramètres, on peut ainsi construire un joueur de Tetris qui fait en moyenne de l’ordre de 30 000 lignes par partie. On reste encore loin des meilleurs programmes spécifiques à Tetris, comme celui de Pierre Dellacherie qui réalise plusieurs millions de lignes par partie grâce à une grande connaissance experte. Cependant, l’avantage des techniques que nous venons de décrire est qu’elles permettent à l’ordinateur d’apprendre de manière autonome. Elles sont ainsi applicables telles quelles à de nombreux autres domaines : optimisation d’une chaîne de production, pilotage acrobatique d’un hélicoptère, déploiement d’une flotte de satellites…
Pour en savoir plus sur Tetris et sur l’apprentissage par renforcement, nous vous proposons quelques références, en anglais.
- Un ouvrage (en ligne) sur le domaine de l’apprentissage par renforcement : Richard S. Sutton and Andrew G. Barto Reinforcement Learning: An Introduction
- La notice de Wikipédia sur Richard Bellman
- Un site très intéressant sur le jeu de Tetris : celui de Colin Fahey
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
