La post-génomique ou les mystères de la cellule
La post-génomique permet d’obtenir ce type d’informations à travers l’étude du transcriptome et du protéome. Ces termes, créés il y a une dizaine d’années par analogie avec le mot « génome », définissent respectivement l’ensemble des ARNm et des protéines que produit le génome à un moment et dans des conditions donnés. De nouveaux domaines de recherche qui ne peuvent être envisagés sans la bio-informatique…
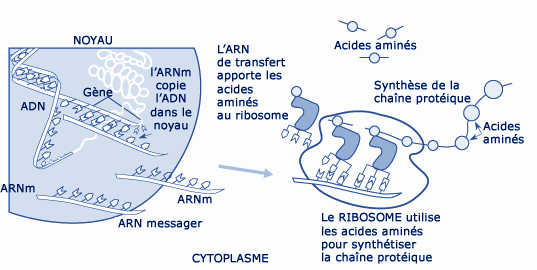
Le fonctionnement cellulaire, de l’ADN aux protéines.
© ORNL – U.S. Department of Energy Human Genome Program
1. Analyser le transcriptome

Puce à ADN :
Chaque ARNm exprimé par la cellule est représenté par un point (image CEA).
Le génome est le même dans toutes les cellules d’un organisme donné, et la machinerie cellulaire tente de le maintenir inchangé en réparant les mutations qui peuvent y être générées. En revanche, le transcriptome varie selon le stade de développement de la cellule, le type de cellule et sa situation physiologique (état sain ou pathologique).
Ainsi, le transcriptome est dynamique. L’analyser consiste à identifier, à un temps t, les séquences codantes du génome qui sont effectivement exprimées. L’étude du transcriptome repose en particulier sur la technologie des biopuces, ou puces à ADN, qui cherche à détecter les ARNm présents dans un mélange donné. Plusieurs dizaines de milliers de résultats peuvent être obtenus simultanément. Comme pour le séquençage du génome, les données sont produites en masse, nécessitant un traitement des résultats faisant intervenir la bio-informatique.
2. Analyser le protéome
Les protéines sont les acteurs principaux de la vie cellulaire, elles ont en charge la structure des tissus, le transport de molécules, la défense de l’organisme, la catalyse de réactions chimiques… Connaître la quantité de chaque protéine présente à un instant donné dans une cellule, et étudier son activité, permet donc de suivre au plus près le fonctionnement cellulaire. C’est ce à quoi s’emploie l’analyse du protéome qui, tout comme le transcriptome, évolue au cours du développement cellulaire et dépend de la cellule qui le produit. Cependant, même si les protéines proviennent de la traduction des ARNm, considérer le protéome comme le reflet exact du transcriptome serait une approximation. Entre autres raisons, citons le fait qu’un même ARNm peut donner plusieurs protéines différentes, plus ou moins actives. Soumises à analyse, les protéines peuvent livrer des informations supplémentaires et parfois plus précises que les ARNm.
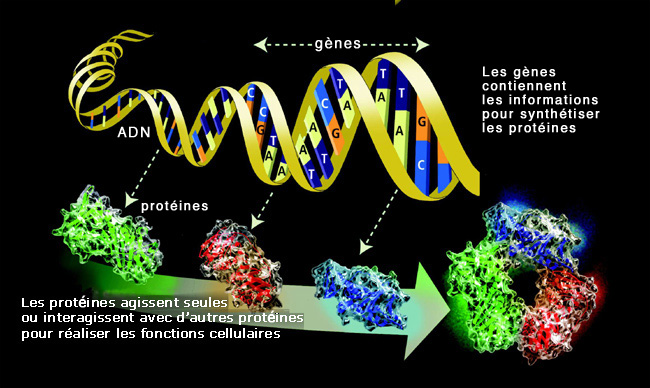
Les protéines, actrices principales de la machinerie cellulaire.
© ORNL – U.S. Department of Energy Human Genome Program
Séparer et fractionner… pour identifier
Les techniques employées en protéomique sont principalement au nombre de trois :
- la méthode dite de « double hybride »,
- l’électrophorèse bidimensionnelle sur gel et
- la spectrométrie de masse,
ces deux dernières techniques étant le plus souvent couplées.
L’électrophorèse bidimensionnelle sur gel et la spectrométrie de masse permettent de déterminer la nature et la quantité – ainsi que les variations de quantité – des protéines présentes dans un échantillon biologique. Dans une première étape, l’électrophorèse sépare les protéines du mélange étudié. Puis chaque protéine purifiée est découpée en peptides par une enzyme, à des endroits précis et constants de sa séquence qui dépendent de l’enzyme employée.
La masse des peptides est ensuite mesurée par spectrométrie, pour donner un « profil de fragmentation » spécifique de cette protéine. Il faut ensuite retrouver dans les bases de données disponibles à quelle protéine correspond le profil obtenu. Une autre stratégie pour identifier la protéine consiste à tenter de « remonter » jusqu’à son gène à partir des informations recueillies sur les peptides analysés.
Au-delà de ces deux méthodes d’identification de protéines inconnues, la combinaison de purification / caractérisation est à l’origine de multiples « tactiques » employées en protéomique, mais aussi en simulation de réseaux d’interaction.
La méthode de double hybride est quant à elle employée pour étudier les interactions entre protéines. Cette technique de biologie moléculaire met en évidence la capacité d’une protéine connue à interagir avec une protéine inconnue, permettant aussi de valider in vivo des hypothèses d’interaction protéique posées, par exemple, à la suite d’une recherche de similarité de séquences. À plus large échelle, les résultats obtenus aident à la construction de cartes, ou réseaux, d’interaction.
3. Simuler les réseaux d’interaction
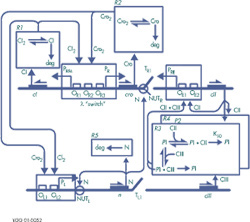
Un réseau d’interaction.
Tous les mécanismes cellulaires, et de ce fait tous les phénomènes qu’ils sous-tendent au niveau de l’organisme entier, résultent d’interactions. Interactions au niveau moléculaire, que ce soit entre protéine et ADN (régulation de l’expression des gènes), entre différentes protéines, ou entre protéine et ARN (par exemple, lors de la traduction). Connaître les réseaux d’interaction qui connectent les différents acteurs de ces mécanismes ouvre la voie à la compréhension du fonctionnement des organismes.
Les techniques utilisées pour l’étude du transcriptome et du protéome apportent des informations précieuses : quels gènes sont exprimés simultanément dans des conditions précises et quelles protéines interagissent.
Ces données expérimentales servent de point de départ aux bio-informaticiens. Les outils mathématiques développés simulent les interactions et gèrent la complexité créée par l’existence fréquente de boucles de rétroaction, positive ou négative, reliant les différentes molécules. À terme, le but de ces recherches est de parvenir à simuler des systèmes de plus en plus complexes, pour aboutir à la modélisation d’une cellule vivante, simplifiée. On imagine déjà aisément quelles pourraient être ses futures applications, en particulier en pharmacologie, pour tester l’effet de nouvelles molécules in silico.
Science fiction ? Quoi qu’il en soit, plusieurs projets s’y emploient actuellement, au Japon, aux États-Unis et en Europe.
4. Déterminer la structure tridimensionnelle des protéines
La structure tridimensionnelle d’une protéine est l’un des principaux éléments qui détermine sa fonction. C’est pourquoi la connaissance de cette structure constitue un enjeu majeur. Mais le repliement de la chaîne peptidique, qui conduit à l’assemblage de cette structure, est un phénomène complexe. Il met en jeu des interactions multiples entre les acides aminés de la protéine, mais aussi avec le solvant et parfois d’autres molécules (par exemple, le substrat pour une enzyme). Aussi, même dans le cas idéal où la séquence d’ADN donne directement la séquence en acides aminés de la protéine, cette information n’est pas suffisante pour déduire la structure de la protéine en question.
Cette difficulté ne décourage pas certains bio-informaticiens de tenter de mettre au point des algorithmes pour prédire la structure tridimensionnelle de protéines à partir de leur séquence en acides aminés.
Il existe également d’ambitieux programmes de détermination systématique de structures 3D de protéines, par cristallographie aux rayons X ou spectrométrie RMN. Les structures de ces « protéines-modèles » sont alors stockées dans des banques (par exemple, PDB), tout comme l’ADN après son séquençage. Elles servent ensuite, en quelque sorte, de « moules » dans lesquels on essaie d’ajuster les séquences protéiques de structure inconnue.

La structure 3D d’une protéine : l’hémoglobine (image Swiss-Prot).
Les chercheurs en bio-informatique ne manquent pas de pistes à explorer pour résoudre les mystères de la cellule.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

