Le tatouage de son
Les années 1990 ont vu apparaître une nouvelle forme du « jeu du gendarme et du voleur », entre les compagnies de distribution de disques ou Major (telles Sony, Universal Music, EMI) et les internautes peu soucieux des droits de propriété intellectuelle. Actuellement, le comité américain MUSIC (Music United for Strong Internet Copyright) estime à 243 millions le nombre de fichiers illégalement téléchargés par mois sur Internet.
Une première réponse de l’industrie du disque pour faire face à ce problème est apparue sous la forme des fameux DRM (Digital Right Management), visant une gestion hardware ou software des droits d’utilisation et de reproduction des contenus audio. Leur utilisation a donc été prévue dans les formats audio émergeant (la norme MPEG4 par exemple). Pour autant, leur utilisation est aujourd’hui fortement remise en cause car étant fortement propriétaires, ils limitent ainsi les supports sur lesquels ils peuvent être lus.
Le tatouage audio, envisagé dès les années 1990 mais longtemps laissé aux services de « Recherche et Développement », apparaît aujourd’hui plus encore comme un maillon essentiel de la riposte contre le piratage. En tatouant le contenu audio, on réussit à insérer directement dans le signal de musique une « marque », par exemple un numéro d’identification, sans que cette marque ne perturbe l’écoute de l’enregistrement. Cette marque peut alors authentifier le propriétaire du document, ou permettre de tracer le document piraté et de remonter au pirate, puisqu’elle suivra le signal audio dans tous ces transferts sur des lecteurs audio ou à travers le réseau Internet. Explications.
Le son, une histoire de perception
Un son est avant tout une onde acoustique émise par un objet en mouvement et propagée dans l’air jusqu’à l’oreille. Par une succession de procédés mécaniques (stimulation du tympan, excitation de la cochlée, etc.) cette onde est convertie en message électrochimique à destination des nerfs auditifs, qui véhiculent l’information jusqu’au cerveau, où le son est alors interprété.
Comment fonctionne cette interprétation ? L’onde acoustique (le son) en question est communément représentée sous forme de sinusoïdes caractérisées par leurs amplitudes qui varient dans le temps. On parle alors d’une représentation « temporelle » du signal sonore.
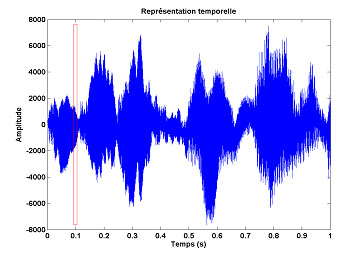
Portion de 1 seconde de l’œuvre « Partita n° 3 » de J.C. Bach en représentation temporelle du signal.
Ce signal étant très variant dans le temps, on préfère l’analyser localement sur des portions (ou fenêtres) d’une vingtaine de millisecondes où l’on peut faire l’hypothèse que les propriétés statistiques du signal ne changent pas.
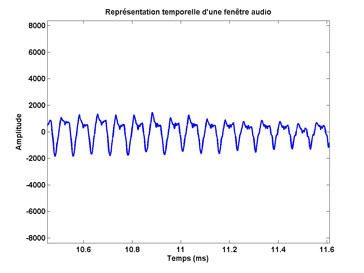
Extrait de 20 millisecondes de la portion de l’œuvre « Partita n° 3 » de J.C. Bach en représentation temporelle du signal.
Pour interpréter ce son, notre oreille et notre cerveau vont être sensibles à la fois à la fréquence d’oscillation des vibrations ressenties, qui déterminera la hauteur du son (aigu ou grave), et à leur puissance, qui déterminera l’intensité du son (faible ou fort). On parle alors d’interprétation fréquentielle du signal sonore. La fréquence étant mesurée en Hertz (Hz) et la puissance en décibel (dB).
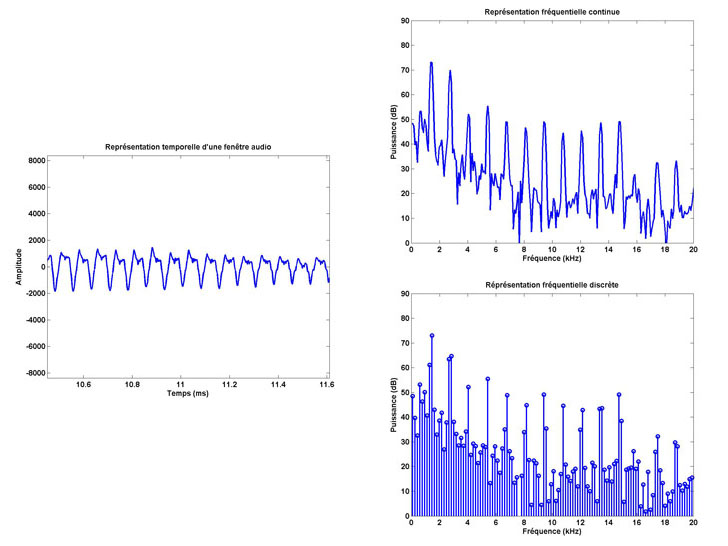
Représentation temporelle (à gauche), fréquentielle continue (à droite, haut) et fréquentielle discrète (à droite, bas) du signal « Partita n° 3 » de J.C. Bach sur 20 ms.
Si notre oreille est un excellent analyseur fréquentiel du signal sonore, elle ne peut toutefois faire cette analyse que dans une gamme de fréquences audibles qui s’étale entre 20 Hz à 20 kHz, mais également au dessus d’un seuil de puissance suffisant pour exciter le tympan et être entendu (le seuil d’audition absolu de l’ordre de 0 dB). Pour en apprécier l’étendue, donnons quelques ordres de grandeur :
- la fréquence moyenne de la voix d’un homme est de 125 Hz,
- la fréquence moyenne de la voix d’une femme est de 240 Hz,
- la fréquence d’un La de diapason est de 440 Hz,
- la fréquence du Si 5e du piano est de 1976 Hz,
- la puissance d’un murmure à 2 mètres est de 40 dB,
- la puissance du bruit d’un poids lourd sur l’autoroute à 10 mètres est de 90 dB et marque le seuil de danger au delà duquel on peut craindre des lésions irréparables de l’oreille,
- la puissance du bruit d’un atelier de chaudronnerie est de 120 dB (limite de la douleur).
Aussi puissant et performant soit-il, notre système auditif (oreille, cerveau) possède toutefois des défauts, notamment celui de ne pas savoir distinguer deux sons « très proches ». Prenons l’exemple d’une sirène d’alarme qui couvre les voix de badauds. À l’instant t, un son masqué, ici les voix des badauds, est rendu inaudible par la présence (ou l’ajout) d’un second son, le son masquant, ici la sirène d’alarme. C’est ce que l’on appelle le phénomène de masquage.
Dans les années 1940, des études en psychoacoustique ont permis de modéliser ce phénomène lorsque deux sons, masqué et masquant, sont deux signaux purs (autrement dit deux sinusoïdes) ajoutés temporellement l’un à l’autre. Ce modèle permet de déterminer le seuil de puissance du son masqué en dessous duquel il ne sera pas perceptible et donc recouvert par le son masquant. Inversement, si la puissance du son masqué est au dessus de ce seuil, les deux sons seront alors perceptibles. Exprimé à partir de la représentation fréquentielle du signal acoustique, ce seuil est appelé seuil de masquage.
Ces seuils sont expérimentaux : on demandait à un auditeur averti (qui disposait souvent d’ « oreilles en or ») d’écouter plusieurs configurations de masquant, masqué, et d’indiquer s’il était capable de distinguer ou non les deux sons.
Faites le test vous même avec cette applet Java. Attention à la puissance d’écoute…
Pour accéder à l’applet Java, autorisez les applets du domaine https://interstices.info. Si votre navigateur n’accepte plus le plug-in Java, mais que Java est installé sur votre ordinateur, vous pouvez télécharger le fichier JNLP, enregistrez-le avant de l’ouvrir avec Java Web Start.
Avec cette applet, expérimentez l’ajout de deux sons purs.
À droite s’affiche la représentation fréquentielle des 2 sons purs. Pour définir les caractéristiques de ces 2 sons purs à l’aide de la souris, cliquez dans le cercle rouge (positionné au départ à la fréquence 0 kHz et à la puissance 60 dB) et déplacez le curseur pour modifier la puissance du son (axe vertical) et sa fréquence (axe horizontal). Faites de même avec le cercle bleu.
À gauche s’affiche la représentation temporelle des 2 sons purs, ainsi que de leur somme.
Les graphiques sont modifiés en temps réel en accord avec les modifications appliquées aux sons.
Utilisez le menu en bas à gauche pour modifier le niveau de zoom dans la représentation temporelle des sons, et pour activer ou désactiver l’écoute du son.
L’intérêt du masquage pour la compression audio et le tatouage
Cette capacité de masquage a très rapidement intéressé les chercheurs en audio, lorsqu’il a fallu compresser les signaux sonores, c’est-à-dire utiliser de moins en moins d’information (de bits) pour représenter les signaux numérisés et en diminuer leur poids. Il devenait possible de distinguer dans un son l’information perceptible de l’information inaudible, et donc, idéalement, de ne représenter le signal qu’avec l’information perceptible. Le masquage a également ouvert les portes au tatouage, car s’il est possible de supprimer de l’information inutile, car inaudible, dans le signal, il est aussi possible d’en ajouter. On peut donc voir le tatouage comme l’ajout au signal audio d’un autre son, rendu inaudible à la seule condition que sa puissance soit inférieure au seuil de masquage du signal dans lequel il va se « cacher ».
La psychoacoustique des années 1940 fournit ce seuil lorsque le signal audio est un son pur (une sinusoïde correspondant à un « tut » ; voir l’applet ci-dessus). Mais il est bien entendu qu’un signal audio est bien plus riche qu’une simple sinusoïde, puisque c’est une combinaison complexe (une somme pondérée) de sinusoïdes élémentaires réparties sur tout l’axe des fréquences (comme le montre l’image précédente). On préfère alors à la représentation fréquentielle discrète, une représentation fréquentielle continue appelée Densité spectrale de puissance (DSP).
Partant de ce constat, en combinant les seuils de masquage individuels de chaque sinusoïde présente dans le signal audio en un seul seuil de masquage global, il sera possible de caractériser le pouvoir masquant du signal sur tout l’axe des fréquences et obtenir ainsi la limite de DSP du tatouage pour être inaudible. Or, la difficulté d’une telle transformation est que la psychoacoustique n’établit pas de quelle façon l’effectuer.
Plusieurs modèles, historiquement conçus dans un contexte de compression audio, notamment le modèle MPEG n° 1 utilisé dans le codeur MP3, puis dans un contexte de tatouage (modèles de Gomes, de Garcia, par exemple) ont été développés et testés expérimentalement sur des auditeurs. Ils permettent d’obtenir le seuil de masquage global, dont l’allure ressemble à celle de la figure ci-dessous, et donnent une limite de densité spectrale de puissance au tatouage pour être inaudible. Notons que ce seuil est valable pour une portion de 20 millisecondes du signal audio et doit être recalculé pour chaque nouvelle portion (fenêtre), où les propriétés du signal audio changent.
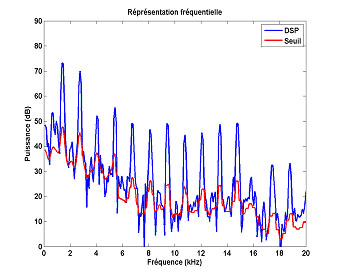
Densité spectrale de puissance (représentation fréquentielle continue) et seuil de masquage (en rouge) sur une fenêtre d’analyse du signal « Partita ».
Le tatouage, une histoire de transmission
Il existe aujourd’hui plusieurs techniques permettant d’insérer un tatouage dans un signal sonore. Ne sera exposée ici que la technique additive dans le domaine temporel, car elle donne une bonne idée des grands principes qui guident les schémas de tatouage.
Les techniques de tatouage additives reposent sur les aspects psychoacoustiques que nous venons de décrire, mais ils s’inscrivent aussi dans une chaîne de communication numérique traditionnelle.
Une chaîne de communication numérique vise la transmission efficace d’une information (un message binaire) d’un émetteur à un récepteur, par exemple deux ordinateurs reliés par le canal Internet ou Wifi : le message binaire, une suite de 0 et de 1 (représentant un texte, une image ou une marque), est converti par l’émetteur en un signal physique (analogique), le signal modulé, et transmis au récepteur, qui analyse le signal reçu (après l’avoir démodulé) pour retrouver le message binaire (numérique) initial. Or, au cours de la transmission du message, celui-ci peut être brouillé ; un bruit de canal (l’environnement en Wifi par exemple) peut s’ajouter au signal reçu (des bits seront erronés) et venir perturber la bonne récupération du message.
L’efficacité du système est donc fortement liée au rapport existant entre la puissance du signal émis et la puissance du bruit qui s’y est ajouté. C’est ce que l’on nomme le Rapport Signal à Bruit ou RSB ; plus le RSB est élevé, plus le récepteur sera efficace et le taux d’erreur sera faible.
Les systèmes de tatouage additifs reposent eux aussi sur le même principe qu’une chaîne de communication numérique.
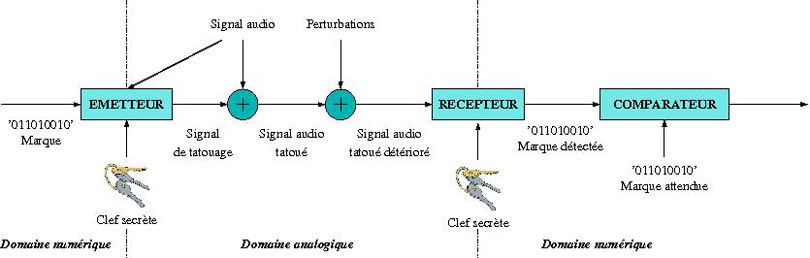
Chaîne de communication d’un système de tatouage.
Lorsque l’émetteur construit un signal tatoué, il définit comment transformer la marque (la suite de 0 et 1 correspondant par exemple au nom identifiant le propriétaire du document ; mais il peut aussi s’agir d’une photo) pour la transmettre cachée dans un signal audio. Cette marque n’est autre qu’un message binaire qu’il convertit (qu’il module) en un signal physique (un son analogique) avant qu’il soit ajouté au signal audio qu’il viendra tatouer. Cette modulation exploite une clef secrète connue seulement du propriétaire.
Le signal audio tatoué est ensuite transmis par un canal (incluant toutes les perturbations licites ou non appliquées sur un signal tatoué) au récepteur. Ce récepteur extrait, en analysant le signal et en exploitant la clef secrète, la marque binaire cachée. Pour finir, la marque détectée et la marque attendue (celle qui a effectivement été cachée) sont comparées : si les deux sont suffisamment similaires, on conclut que le document appartient au propriétaire de la clef.
Les performances d’un tel système sont elles aussi très dépendantes du Rapport Signal à Bruit (RSB). En effet, du point de vue du récepteur, le signal utile est le tatouage lui-même (qui va lui permettre d’identifier le propriétaire) ; tandis que le son (le signal audio principal) peut être vu comme un bruit qui perturbe l’extraction du tatouage. Le RSB est donc ici le rapport de puissance entre le tatouage et le bruit audio.
Ce Rapport Signal à Bruit, qui détermine la performance du système, doit être choisi volontairement faible : s’il est trop important, le tatouage risque de devenir audible. Inversement, il ne doit pas être trop faible, sinon, le récepteur ne pourra pas récupérer la marque cachée.
Étant donnée cette faible valeur du RSB, un système de tatouage s’apparente beaucoup à la transmission fortement brouillée d’un satellite interplanétaire vers la terre, où la distance émetteur/récepteur et le canal atmosphérique très variable, brouillent fortement les données. Ces systèmes utilisent une modulation très particulière, appelée « modulation par étalement spectral ».
Cette technique de modulation offre un double avantage pour les systèmes de tatouage. Elle permet une résistance accrue du système aux canaux fortement brouillés, ce qui lui vaut d’être couramment utilisée par les systèmes de positionnement par satellite (GPS, Galiléo, etc.) ainsi que par les systèmes de téléphonie gérant plusieurs utilisateurs (Code Division Multiple Access). D’autre part, elle est basée sur un signal aléatoire, pouvant faire office de clef et de secret (connu seulement du propriétaire du document) ; à ce titre elle est souvent utilisée dans les applications militaires (transmission cachée).
Dès lors, partant de cette technique de modulation, il faudra assurer le fameux compromis entre inaudibilité et efficacité de détection, en jouant sur le RSB.
Décrivons maintenant l’ensemble du processus de tatouage d’un son.
Comment construire un système de tatouage ?
Processus d’émission du signal tatoué
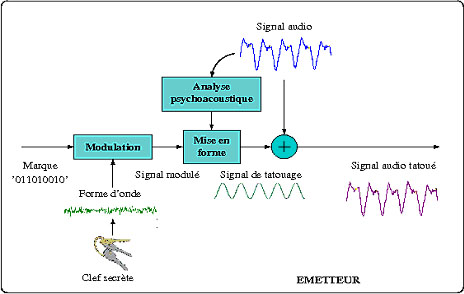
Schéma de l’émission d’un système de tatouage.
Supposons que la marque à cacher (la signature du propriétaire par exemple) est la suite de 9 bits « 011010010 » et que l’on souhaite la cacher dans un signal (un morceau de musique par exemple). Cette marque pourra bien évidemment être cachée plusieurs fois dans le signal, mais on ne considère ici qu’une seule insertion sur une portion totale de 180 ms ; c’est-à-dire que chaque bit sera caché dans des portions de 20 ms (20 ms x 9 bits = 180 ms).
Étape de modulation : « fabrique » d’un signal porteur de la marque à tatouer
Les 9 bits à tatouer (binaires) doivent chacun être convertis (modulés) en signaux analogiques porteurs de la même information que le bit. Pour ce faire, on utilise un signal temporel d’une durée identique à la portion de signal à tatouer, ici 20 ms. Mais le signal utilisé a pour propriété d’avoir une Densité Spectrale de Puissance (DSP) égale à 1 qui l’a rend constante (ou plate) quelle que soit sa fréquence (d’où le nom d’étalement spectral). Il correspond, à l’écoute, à un bruit sans harmonie.
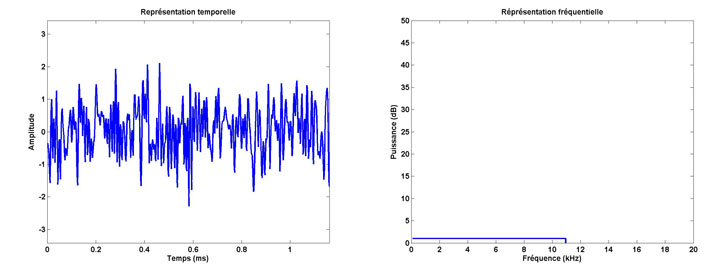
Représentation temporelle (à gauche) et fréquentielle (à droite) d’un signal à étalement spectral (DSP = 1).
L’opération de conversion (modulation) consiste simplement à coder ce signal temporel (dont la DSP est plate) de la façon suivante :
– si le bit à tatouer est ‘0’, le signal temporel est multiplié par une valeur négative (ici la valeur -1);
– si le bit à tatouer est ‘1’, le signal temporel est multiplié par une valeur positive.
La valeur exacte de chacune des portions de ce signal temporel sera déterminée par la clef secrète du propriétaire d’une façon pseudo-aléatoire tandis que son signe multiplicatif dépend du bit de tatouage.
Le signal modulé porteur de la marque à cacher sur 180 ms s’obtient finalement en concaténant toutes les portions de signaux ainsi modulés sur 20 ms.
À ce stade, insistons sur le fait que ce signal qui vient d’être modulé est construit complètement indépendamment du signal audio que nous souhaitons tatouer (le morceau de musique initial). Mais l’ajouter tel quel au signal audio ne garantirait en aucune façon son inaudibilité. Il faut donc le « mettre en forme » pour le rendre inaudible lorsqu’il sera ajouté au signal audio.
Étape de mise en forme spectrale : modification du signal modulé porteur de la marque en un signal de tatouage
Cette mise en forme spectrale a un double objectif :
1) Garantir que le signal de tatouage soit inaudible. Comme nous l’avons expliqué précédemment, il faut donc que ce signal de tatouage ait une DSP (Densité spectrale de puissance) inférieure ou égale au seuil de masquage du signal audio dans lequel il sera inséré.
2) Garantir un RSB (Rapport Signal à Bruit) le plus élevé possible pour permettre la détection et la récupération du tatouage. Ce RSB peut être calculé directement dans le domaine fréquentiel : il est proportionnel à l’aire de la DSP. Donc plus la DSP du tatouage est grande (tout en étant limitée par le seuil) meilleure sera le RSB.
Le meilleur compromis entre ces deux contraintes est en fait obtenu lorsque la DSP du signal de tatouage tangente le seuil de masquage : il sera égal ou au plus près du seuil de masquage. Autrement dit, le son créé à partir du signal modulé sera très ressemblant au son initial (que l’on veut tatouer) mais dans une forme inaudible.
Il convient donc de calculer le seuil de masquage de chacune des 9 portions de 20 ms du signal audio initial (qui accueilleront les 9 portions de 20 ms du signal de tatouage). Le signal modulé précédemment (portant la marque à cacher) sera ensuite filtré pour obtenir le signal tatouage dont la DSP est le seuil de masquage du signal audio. Il aura donc la même allure fréquentielle que le seuil de masquage mais sera inaudible en présence du signal audio. En reproduisant cette opération sur toutes les fenêtres de 20 ms, on construit ainsi le signal de tatouage.
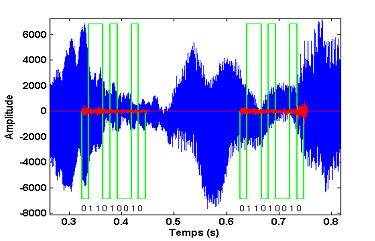
Signal de tatouage dans le domaine temporel : la marque binaire (en vert) est insérée 2 fois sur une fenêtre de 180 ms de signal audio (en bleu) grâce au signal de tatouage (en rouge).
Étape d’insertion : ajouter le signal de tatouage dans le signal audio
Le signal audio tatoué est finalement obtenu en ajoutant le signal de tatouage ainsi créé au signal audio.
Processus de réception du signal tatoué
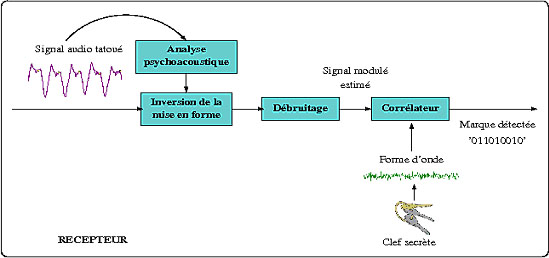
Schéma de réception d’un système de tatouage.
Le récepteur du signal audio tatoué va chercher à récupérer la marque cachée dans le signal audio reçu. Si dans le cas de l’émetteur, le signal audio était considéré comme une couverture de son tatouage, en revanche, dans le cas du récepteur, le signal audio va être considéré comme du bruit (puisque c’est la marque qui l’intéresse avant tout). L’opération du récepteur consiste donc à inverser les modifications effectuées sur le signal par l émetteur.
Étape d’égalisation : inverser les effets du signal audio par filtrage
En premier lieu, il est nécessaire de recalculer le filtre de mise en forme utilisé par l’émetteur en effectuant une analyse psychoacoustique du signal audio tatoué et en calculant son seuil de masquage. Le filtre ainsi obtenu sera peu différent du filtre utilisé par l’émetteur. Le récepteur pourra donc filtrer le signal audio tatoué avec le filtre inverse de celui qu’il vient d’obtenir et ainsi inverser une grande part de la mise en forme spectrale du signal de tatouage (c’est le procédé d’égalisation de type Zero-Forcing).
Reste ensuite à supprimer le signal audio. Le récepteur a donc recours à un second filtre, un égaliseur de Wiener, couramment utilisé en débruitage de son. Mais dans ce cas, il ne s’agit pas de nettoyer le signal audio d’un bruit (lié par exemple à de mauvaises conditions d’enregistrement) mais de nettoyer le signal de tatouage pour lui enlever le signal audio !
Au final, on récupère une estimation du signal modulé temporel dont les valeurs de signe sont positives si on avait tatoué un ‘1’, et négatives si on avait tatoué un ‘0’.
Étape de détection de la marque cachée : relire le signal modulé estimé sous forme d’une marque binaire
On procède ensuite à la projection du signal obtenu sur la forme d’onde par un simple calcul de corrélation ; puis en fonction du signe de cette corrélation, on décide si le bit reçu sur les 20 ms de signal est un ‘1’ ou un ‘0’. En appliquant ce traitement sur les 9 fenêtres (portions) de signal, on récupère la marque de 9 bits.
Étape de décision : établir la preuve de propriété
Pour vérifier si cette marque est bien celle du propriétaire concerné, il convient de réaliser ce processus sur toutes les fenêtres du signal audio comportant la marque cachée et de faire la moyenne des résultats obtenus avant de prendre une décision.
Robustesse aux perturbations
Les perturbations qui peuvent être appliquées au signal audio tatoué sont nombreuses et très variées. Un système de tatouage robuste doit permettre de détecter la marque même lorsque le signal audio tatoué est corrompu par celles-ci. En plus des opérations licites apportées par les réseaux de diffusion sur l’audio, certes classiques mais souvent non-linéaires (compression, conversion analogique-numérique et réciproquement, filtrage, compresseur de dynamique, ajout d’écho, etc.), on dénombre également toutes les actions illicites (par exemple, le cropping, l’inversion d’échantillons) effectuées par un pirate. La seule contrainte du pirate est de ne pas trop corrompre (abîmer) le signal audio pour que son contenu reste exploitable. On peut donc considérer que le bruit introduit par ces distorsions est de même puissance que le tatouage.
On ne se propose pas ici de lister toutes les solutions envisagées pour rendre le système robuste à toutes les perturbations. On préfère se concentrer sur celle qui paraît être la plus incompatible avec le tatouage : la compression MPEG.
On dit souvent que la compression supprime les parties inaudibles du signal audio, et donc à fortiori, supprime le tatouage. Il faut néanmoins approfondir cette première analyse de la compression pour comprendre pourquoi le tatouage peut lui résister. La compression n’est pas tant un problème de suppression des composantes inaudibles que de représentation des composantes les plus audibles. On dispose d’un budget de bits (196 kbit/s pour les MP3 de bonnes qualités, 64 kbit/s pour les plus compressés) qui doit être utilisé à bon escient pour représenter le signal. Une grande partie de ce budget est donc alloué aux composantes les plus significatives (en terme de perception), qui sont les basses fréquences. Les hautes fréquences, moins audibles, ne sont souvent pas représentées (donc supprimées) dès lors que le budget est trop petit.
Au même titre, les composantes basses fréquences du tatouage sont relativement bien conservées (à une erreur de représentation près) mais les composantes hautes fréquences risquent fort d’être complètement perdues.
Pour rendre le tatouage robuste à la compression MPEG, on choisit donc de le concentrer dans les basses fréquences et de ne pas tatouer les hautes fréquences. Le signal de tatouage est donc étalé dans une bande de fréquence limitée (de 0 à 11 kHz si l’on veut être robuste à MPEG 196 kbit/s, de 0 à 6 kHz pour des taux de compression plus faibles), comme on peut le voir sur la figure.
En termes de performance : quelques ordres de grandeur
Il est difficile, à l’heure actuelle, de faire une synthèse des performances que l’on peut attendre d’un système de tatouage ; ces dernières sont très dépendantes du dimensionnement et de la paramétrisation du système de tatouage choisis en fonction des applications, qui (on l’a déjà mentionné) sont très nombreuses.
On estime aujourd’hui qu’avec des débits de l’ordre de 10 bits/s, on peut atteindre des taux de 1 erreur tous les 1000 bits même en présence de perturbations contraignantes. Des performances prometteuses qui laissent penser que le tatouage pourra être utilisé pour protéger efficacement les contenus audio numériques, à condition que la technique soit sûre !
Pour l’heure, la seconde réponse des Major au problème de la protection de la propriété intellectuelle est déjà en cours : Microsoft a déposé récemment un brevet sur le « tatouage audio discret ». Elle s’accompagne d’une prise de conscience des pouvoirs publics qui s’attellent à légiférer au niveau national et international l’utilisation de cette signature numérique.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Cléo Baras
Enseignante-chercheur UJF à GIPSA-lab (Grenoble Parole Images Signal et Automatique)