
Transformation de la voix humaine
Prenez par exemple votre rap préféré, un NTM, un MC Solaar, ou bien encore un slam de Grand Corps Malade. Passez-le à la moulinette du logiciel TRAX, et vous entendrez les voix de ces artistes changer de genre ou d’âge : en tournant quelques molettes, TRAX pourra vous faire entendre ce même rap avec une voix de femme, ou bien une voix de vieil homme, selon ce que vous préférez. C’est magique ? Comment donc est-ce possible ?
Le principe physique
Sur le plan physique, les différences entre la voix d’un homme et celle d’une femme s’expliquent par la taille des cordes vocales et celle du conduit vocal, qui sont plus petites chez la femme.
Les physiciens acousticiens disposent d’un modèle qui met en correspondance les caractéristiques physiques du conduit vocal avec les caractéristiques de la voix qui en émane. Ce modèle met en relation une « source » et un « filtre ». La source, ce sont les cordes vocales et la glotte qui vibrent, créant des pulsations périodiques de l’air envoyé par les poumons. Ensuite, ces pulsations sont transmises au filtre, c’est-à-dire le conduit vocal, qui accentue certains modes de la vibration.
Si les cordes vocales vibrent rapidement, c’est le cas des femmes, la fréquence est élevée, et la voix produite est aiguë. Inversement, si elles vibrent lentement, c’est le cas des hommes, la fréquence est basse, et la voix est grave. La vibration des cordes vocales est une caractéristique individuelle de chaque personne. Avec les caractéristiques du conduit vocal, elles créent le « timbre » de chaque voix, ce qui fait qu’une voix humaine est si reconnaissable et si différente d’une autre. Intuitivement, le timbre est ce qui distingue par exemple le violon du piano, ou encore ce qui distingue Ella Fitzgerald de Billie Holiday (dans le cas où les deux chantent la même note).
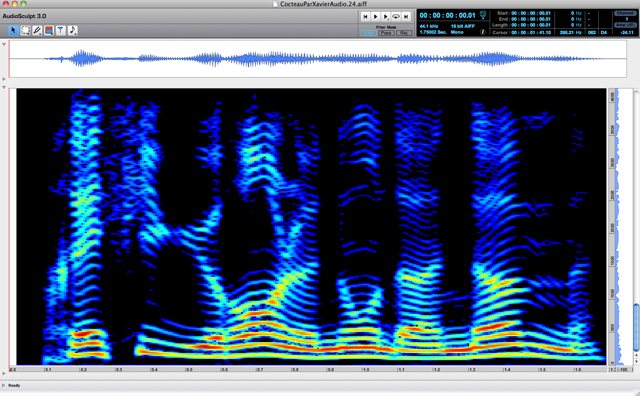
Spectrogramme de la voix d’un homme parlant (logiciel AudioSculpt).
L’échelle de temps, représentée horizontalement, va ici de 0 à 1.8 s, par pas de 0.1 s. L’échelle de fréquence, représentée verticalement, va de 0 à 4300 Hz.
La distance verticale entre les raies horizontales caractérise la hauteur de la voix. La couleur de ces raies caractérise leur énergie. Plus elles sont rouges, plus il y a d’énergie. Un rouge très foncé correspond à -15 dB, à l’autre extrémité le noir correspond à -65 dB. Les zones à énergie localement élevée sont les « formants », qui décrivent le timbre et sont les indices permettant de distinguer les voyelles entre elles.
Ces caractéristiques physiques de la voix peuvent être vues sur un « spectrogramme », qui est une représentation de la distribution de l’énergie du signal sonore, en fonction du temps (axe horizontal) et en fonction des fréquences (axe vertical). On voit d’abord une structure fine avec des raies horizontales plus ou moins colorées. La distance régulière entre ces raies représente la hauteur de la voix.
Pour les voix féminines, cette distance sera alors plus grande que pour les voix masculines. Cela traduit le fait que la voix est plus haute. La hauteur de la voix parlée d’un homme est comprise entre 70 et 160 Hertz ; et celle d’une femme entre 130 et 300 Hertz.
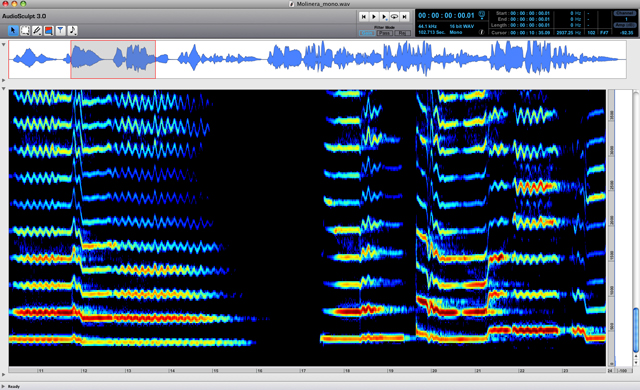
Spectrogramme de la voix d’une femme chantant(logiciel AudioSculpt).
L’échelle de temps, représentée horizontalement, va ici de 10 à 24 s, par pas de 1 s. L’échelle de fréquence, représentée verticalement, va de 0 à 4000 Hz.
Les raies sont plus espacées que chez un homme, car la hauteur de la voix (ou pitch) est plus élevée. On peut distinguer les petites oscillations régulières du pitch qui sont liées au vibrato de la voix chantée.
Dans un spectrogramme, la première bande correspond à la fréquence fondamentale du son (ou hauteur du son), et les autres bandes bleues ou vertes correspondent aux « harmoniques » de ce même son (multiples entiers de la fréquence fondamentale). Les couleurs représentent la distribution d’énergie dans les raies, et correspondent aux résonances données par le conduit vocal. Ainsi les zones rouges sont les zones de fréquences que le conduit vocal fera résonner le plus. C’est cette distribution d’énergie qui représente le timbre d’une voix.
Changer le genre de la voix – comment ça marche ?
Pour changer une voix d’homme en voix de femme, il faut donc d’abord changer la hauteur de la voix. Ensuite, il faut changer le timbre. Le timbre englobe à la fois la « couleur » de la voix, et la qualité de pureté du son : est-il bruité, la voix est-elle rauque, y a-t-il du souffle ?
Ainsi pour transformer une voix d’homme en voix de femme, on agit sur deux paramètres : la hauteur du son (source de l’excitation) et le timbre (du résonateur). Pour agir sur le timbre, on change la distribution d’énergie des raies, en changeant la position des « formants », c’est-à-dire les régions rouges du spectrogramme.
Chez un homme, la taille du conduit vocal étant plus longue, les formants sont comprimés vers les fréquence basses; inversement chez une femme, avec un conduit vocal plus petit, les formants sont plus espacés.
Les logiciels de transformation de la voix humaine développés à l’IRCAM ont pour nom AudioSculpt (à partir de 1993) et TRAX (à partir de 2008). Alors qu’AudioSculpt travaille sur la transformation du son en général, TRAX a spécifiquement été créé pour les transformations de la voix humaine, parlée ou chantée.
Le logiciel TRAX est commercialisé par la société Flux depuis fin juillet 2010.
Le logiciel TRAX permet de manipuler à la fois la hauteur de la voix et la disposition des formants de cette voix, il modifie ainsi son timbre ou plus précisément sa couleur. Regardez et écoutez un exemple sur la vidéo ci-dessous.
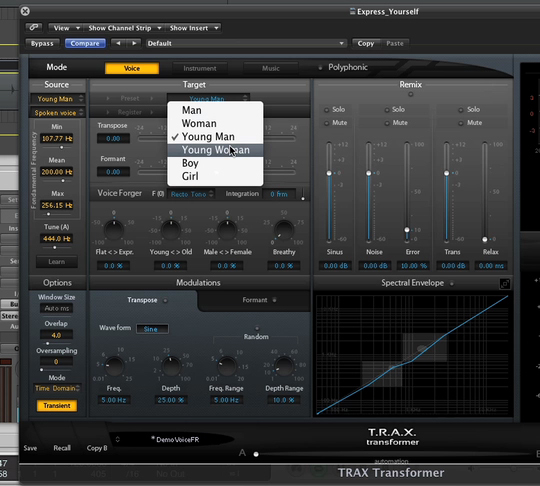
Démonstration du logiciel TRAX. Une voix masculine est transformée en voix féminine.
Visionner la vidéo – Durée : 45 s.
Vous trouverez d’autres exemples sur le site de l’IRCAM, notamment une démonstration de transformation de voix chantée de femme.
Changer l’âge de la voix – comment ça marche ?
Pour changer l’âge d’une voix, ce sont les mêmes paramètres qui sont modifiés, mais différemment combinés. Les enfants ont en effet un conduit vocal encore plus petit que les adultes. Avec le logiciel, on utilise et combine différemment d’autres valeurs de hauteur et de position des formants afin d’obtenir une voix de jeune enfant par exemple.
De plus, pour obtenir un effet d’âge supplémentaire, on agit aussi sur un autre paramètre, la « modulation de l’intonation ». Une personne jeune a tendance à « moduler » plus, c’est-à-dire qu’elle varie plus la hauteur de sa voix ou ambitus au sein d’un même discours. Or ce phénomène diminue avec l’âge. Pour agir sur la modulation, on change la courbe de l’évolution de la hauteur de la voix au cours du temps.
À quoi ça sert ?
Le premier client qui s’intéresse de près à ces applications est l’industrie du cinéma, qui peut avoir besoin de modifier les voix des comédiens pour des raisons variées.
Par exemple, pour le film « Farinelli » (réalisé par Gérard Corbiau en 1994), qui avait pour thème les castrats – ces chanteurs du XVIIIe siècle, dont il n’existe bien sûr pas d’enregistrements, qui avaient une voix chantée presque féminine. Le réalisateur a ainsi fait appel à l’IRCAM pour recréer la voix des castrats à partir du mélange savamment dosé d’enregistrements d’une voix de chanteur et d’une voix de chanteuse.
Plus récemment, dans son film « Les amours d’Astrée et Céladon » (2007), Eric Rohmer a lui aussi eu recours aux logiciels de transformation de la voix. Un des personnages du film devait déguiser sa voix d’homme en voix de femme pour les besoins de l’intrigue, mais le résultat obtenu par le comédien n’était pas très convaincant. Alors la voix du personnage masculin a été retouchée et « féminisée » par l’utilisation du logiciel.
Deuxième utilisation possible pour l’industrie du cinéma : modifier les voix des doubleurs, ou bien encore obtenir plusieurs voix différentes avec un seul doubleur, ce qui représente une économie de moyens.
L’autre grand client très intéressé par la transformation de la voix humaine est l’industrie du jeu vidéo, qui s’en sert pour donner des voix aux personnages des jeux, pour multiplier les voix en partant d’une seule, ou bien encore pour leur donner un effet ludique ou électro façon robot.
Du texte à la parole
Un ordinateur peut-il reproduire une voix humaine et l’utiliser pour lui faire prononcer un discours inédit non enregistré ? Dans une certaine mesure, oui ! Le « Text to Speech » est un autre outil passionnant de synthèse de la voix, développé entre autres à l’IRCAM.
Pour ce faire, il faut disposer de plusieurs heures d’enregistrement de la voix parlée d’un individu – ce qui n’est pas une mince affaire. Ensuite, le logiciel peut « apprendre » cette voix afin de la reproduire. Après cette phase d’apprentissage, on fournit alors un texte au logiciel, qui est capable de « traduire » ce texte écrit en discours oral en utilisant la voix parlée originale de départ. Étourdissant, non ? Des essais saisissants ont été réalisés avec la voix d’un acteur célèbre lisant un livre numérique. Le principe ? Cela repose en fait sur l’analyse et la concaténation des micro-éléments de la parole enregistrée. C’est pour cela que la qualité de ressemblance entre la voix synthétisée et la voix source est si bonne. Mais deux limites importantes existent : premièrement, la quantité importante d’heures d’enregistrements qui est nécessaire, et deuxièmement, le fait que le matériau de l’enregistrement de départ limite l’expressivité de la voix.
Comme exemples, nous utilisons deux textes synthétisés. Le premier est une synthèse à partir du texte « le petit chaperon rouge » utilisant un enregistrement d’une voix d’un acteur interprétant un autre texte. L’expressivité de la voix est correcte, même si la « prosodie » paraît un peu étrange.
Le deuxième est une synthèse du texte « tu sais quoi ? je suis tellement content ! » utilisant un enregistrement d’une voix non professionnelle neutre. Dans ce deuxième cas, on constate que l’expressivité plate de la voix enregistrée dans la base n’est pas bien adaptée au texte.
Changer l’identité d’une voix
Transformer la voix d’un individu donné en la voix d’un autre individu donné, est-ce possible? Pour l’instant, dans ce cas précis, on n’en est encore qu’à un stade embryonnaire de recherche.
Dans ce cadre dit de la « conversion d’identité » entre deux voix, il faut disposer d’enregistrements d’au moins 10 minutes de chacune des deux voix disant le même texte – ce qui n’est pas non plus facile à obtenir. On appelle alors « voix-source » la voix qui sert de base, et « voix-cible » celle que l’on veut pouvoir manipuler pour lui faire prononcer un nouveau discours. L’ordinateur, en alignant temporellement les deux enregistrements, est capable d’ « apprendre » la fonction de correspondance ou de transformation entre les deux voix, les différences entre les formants, et les changements de la couleur de la voix en général.
L’industrie du cinéma est là encore très intéressée par une telle promesse de conversion de la voix : faire parler des personnages célèbres ayant réellement existé avec leur voix véritable ! Imaginez qu’un comédien incarnant le général de Gaulle parle avec la voix du général…
La conversion de la voix intéresse également l’industrie du jeu vidéo : il s’agirait par exemple de pouvoir faire en sorte que les joueurs d’un jeu puissent parler avec la voix d’un personnage du jeu par exemple. Une firme japonaise travaille actuellement aussi sur la piste d’un jeu de karaoké où l’on pourrait chanter avec la voix d’Elvis Presley.
Les Européens ne sont pas en reste, et un projet de recherche sur la traduction automatique est en cours actuellement. Il s’agit de rendre possible la traduction automatique orale en utilisant la voix de l’utilisateur du logiciel pour enregistrer le mot à traduire, et utiliser cette même voix pour produire le mot traduit (projet EMIME).
Enjeux
Mais l’éthique dans tout ça ? Est-il bien raisonnable de chercher à manipuler les voix humaines dans tous les sens, au point d’absolument tout modifier, le genre, l’âge, l’identité ? Oserait-on imaginer faire tenir à un homme politique célèbre un discours qu’il n’a jamais tenu ? Quelles en seraient les conséquences ?
Pour l’instant, les logiciels de conversion d’identité de la voix n’en sont qu’aux balbutiements, la qualité atteinte n’étant pas encore suffisante. Mais pour combien de temps ?
Depuis longtemps, les « sciences forensiques » comme la criminologie s’intéressent à tous ces outils de manipulation de la voix, et étudient à la loupe la question de l’imposture vocale, dans la mesure où des enregistrements vocaux peuvent être produits comme preuves devant les tribunaux. L’histoire de l’imposture vocale remonte cependant à bien plus loin que les logiciels de synthèse et de transformation de la voix. De fait, certains individus rares sont naturellement doués du talent de contrefaire leur voix et d’imiter celle d’autres de leurs congénères, faisant ainsi naturellement ce que les logiciels ont appris à faire systématiquement.
Dans combien de temps aurons-nous sur nos i-phones des applications qui permettront de donner l’heure, d’annoncer le temps qu’il fait, ou de donner les cours de la bourse avec notre propre voix ou bien avec celle de notre chanteur préféré ?
Remerciements à Axel Röbel, et à Xavier Rodet, Pierre Lanchantin, Christophe Veaux, Nicolas Obin, de l’équipe Analyse/Synthèse du son à l’IRCAM.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
