
Les systèmes de recommandation : une catégorisation
L'essentiel
Avec l'avènement du web et les évolutions technologiques, entre autres, la masse de données à exploiter ou analyser est devenue très volumineuse. Si bien qu'il est devenu difficile de savoir quelles sont les données à rechercher et où les trouver. Des techniques informatiques ont été développées pour faciliter cette recherche ainsi que l'extraction des informations pertinentes. Celle sur laquelle nous nous concentrons dans cet article est la recommandation. Il s'agit de guider l'utilisateur dans son exploration des données afin qu'il trouve des informations pertinentes.
Les systèmes de recommandation ont été étudiés dans des domaines divers et variés comme le web, le e-commerce et bien d'autres. Nous abordons ici différentes approches pour proposer des recommandations à un utilisateur. Les trois approches les plus courantes sont celles basées sur le contenu — comme dans Pandora —, les approches collaboratives — celle d'Amazon.com par exemple — et les approches hybrides (qui sont une combinaison des deux précédentes) — par exemple celle de Netflix.
Dans le contexte actuel de déluge de données et d’informations, des techniques informatiques pour faciliter la recherche ainsi que l’extraction des informations pertinentes sont une aide utile à la prise de décision. L’une d’entre elles est la recommandation.
Les systèmes de recommandation ont été étudiés dans de nombreux domaines [Neg15b] : la recherche d’informations, le web, le e-commerce, l’exploitation des usages du web et bien d’autres.
Les algorithmes de recommandation les plus connus sont ceux utilisés sur des sites web de commerce électronique. En effet, des sites comme Amazon.com ou des fournisseurs similaires en ligne s’efforcent de présenter à chaque utilisateur quelques suggestions de produits qu’il pourrait vouloir acheter.
Le principe est d’utiliser comme entrées les intérêts d’un client pour générer une liste de produits recommandés. De nombreuses applications se basent seulement sur les produits que les clients achètent et les évaluent explicitement pour représenter leurs intérêts, mais de tels systèmes peuvent aussi prendre en compte d’autres attributs, y compris les produits consultés, les données démographiques et les artistes préférés.
Dans les systèmes de recommandation, l’utilité d’un élément est généralement représentée par un score qui indique comment un utilisateur particulier a aimé un élément particulier.
Le problème principal à résoudre est l’estimation de scores pour des éléments qui n’ont pas encore été évalués par un utilisateur. Le nombre d’éléments ainsi que le nombre d’utilisateurs du système peuvent être très importants ; il est, de ce fait, difficile que chaque utilisateur puisse voir tous les éléments ou que chaque élément soit évalué par tous les utilisateurs. Lorsqu’il est possible d’estimer des scores pour les éléments non encore évalués, les éléments ayant les scores estimés les plus élevés peuvent être recommandés à l’utilisateur.
Considérons l’exemple suivant, où des utilisateurs évaluent des films. Le tableau ci-dessous indique les scores connus pour chaque utilisateur (en ligne) et pour chaque film (en colonne).
Exemple 1
| u(c,i) | Harry Potter | L’Âge de glace | L’Âge de glace 2 | OSS 117 | Bienvenue chez les Ch’tis |
| Elsa | 8 | 2 | 7 | ||
| Marie | 9 | 8 | 3 | 6 | |
| Arnaud | 3 | 5 | 5 | ||
| Patrick | 5 | 3 | 3 | 3 |
Les systèmes de recommandation sont classés en fonction de l’approche utilisée pour estimer les scores manquants.
- méthode basée sur le contenu : l’utilisateur se verra recommander des éléments semblables (au sens d’une mesure de similarité entre éléments) à ceux qu’il a préférés dans le passé.
Dans l’exemple ci-dessus, les films « L’Âge de glace » et « Bienvenue chez les Ch’tis » ont été évalués quasiment de la même manière par Elsa. On observe par ailleurs que les caractéristiques des films « L’Âge de glace » et « L’Âge de glace 2 » sont très « proches ». Le système recommande donc le film « L’Âge de glace 2 » à Elsa, en lui assignant le meilleur score qu’elle a attribué aux films « L’Âge de glace » et « Bienvenue chez les Ch’tis », c’est-à-dire 8. - méthode collaborative ou basée sur le filtrage collaboratif : l’utilisateur se verra recommander des éléments que d’autres utilisateurs ayant des goûts et des préférences similaires (au sens d’une similarité entre utilisateurs et éléments) ont aimé dans le passé.
Reprenons l’exemple 1 précédent. Elsa et Marie aiment toutes les deux « L’Âge de glace » et « Bienvenue chez les Ch’tis » et n’ont pas aimé « OSS 117 » ; leurs avis similaires sur ces films suggèrent qu’en général Marie et Elsa sont du même avis. Donc, « Harry Potter » est une bonne recommandation pour Elsa, puisque Marie l’aime. Le système assigne ainsi au film « Harry Potter », pour Elsa, le score que Marie a donné à ce film, c’est-à-dire 9. - méthode hybride : combinaison des deux méthodes précédentes.
Bien que les systèmes de recommandation permettent de recommander des éléments pertinents à un utilisateur, ils s’avèrent inopérants lorsque de nouveaux éléments sont ajoutés au catalogue ou lorsque les utilisateurs sont différents ou nouveaux. Ce problème du démarrage à froid (cold-start problem) est rencontré lorsque les recommandations sont nécessaires pour des éléments ou des utilisateurs pour lesquels nous n’avons aucune information explicite ou implicite. Il y a donc deux problèmes liés au démarrage à froid [Klo09] : nouvel utilisateur et nouvel élément.
Les approches basées sur le contenu
Pour les recommandations basées sur le contenu (voir [PB07] pour plus de détails), la tâche consiste à déterminer quels éléments du catalogue coïncident le mieux avec les préférences de l’utilisateur. Une telle approche ne requiert pas une grande communauté d’utilisateurs ou un gros historique d’utilisation du système. La figure 1 illustre ce processus.
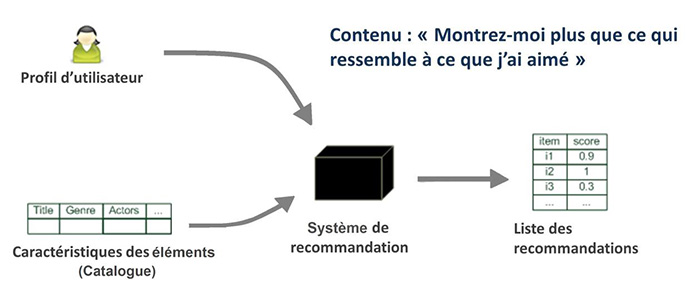
Figure 1 : Un système de recommandation basé sur le contenu (adapté de [JZFF10]).
La manière la plus simple de décrire un catalogue d’éléments est d’avoir une liste explicite des caractéristiques de chaque élément (on parle aussi d’attributs, de profil d’élément, etc.). Pour un livre par exemple, on peut utiliser le genre, le nom des auteurs, l’éditeur ou toute autre information relative au livre, puis stocker ces caractéristiques (dans une base de données par exemple).
Le profil de l’utilisateur est exprimé sous forme d’une liste d’intérêts basée sur les mêmes caractéristiques. La coïncidence entre les caractéristiques des éléments et le profil de l’utilisateur peut être mesurée de différentes manières :
- l’indice de Dice ou d’autres mesures de similarité [BYRN99],
- le TF-IDF (Term Frequency-Inverse Document Frequency) [SWY75],
- les techniques basées sur la similarité des espaces vectoriels (les approches bayésiennes [PB07], les arbres de décision, etc.) couplées avec des techniques statistiques, lorsqu’il y a trop de mots-clés.
Les systèmes de recommandation basés sur le contenu présentent les avantages suivants :
- ils recommandent des éléments similaires à ceux que les utilisateurs ont aimés dans le passé ;
- ils prennent en compte le profil des utilisateurs qui est la clé pour avoir les recommandations les plus pertinentes pour chacun ;
- faire coïncider les préférences de l’utilisateur et les caractéristiques des éléments fonctionne pour de nombreux types de données (textuelles, numériques, etc.) puisqu’on utilise généralement des listes de mots-clés ;
- les données relatives aux autres utilisateurs sont inutiles ;
- il n’y a pas de problème de démarrage à froid lorsqu’un nouvel élément est ajouté au catalogue ou de faible densité puisqu’il s’agit de faire coïncider les préférences de l’utilisateur et les caractéristiques des éléments ;
- il est possible de faire des recommandations à des utilisateurs avec des goûts « uniques » ;
- il est possible de recommander de nouveaux éléments ou même des éléments qui ne sont pas populaires.
Cependant, de tels systèmes ont aussi des inconvénients :
- tous les contenus ne peuvent pas être représentés avec des mots-clés (par exemple, les images) ;
- des éléments représentés par le même ensemble de mots-clés ne peuvent pas être distingués ;
- les utilisateurs ayant visualisé un très grand nombre d’éléments posent un problème (trop d’informations dans le profil de l’utilisateur à faire coïncider avec les caractéristiques des éléments) ;
- lorsqu’un nouvel utilisateur commence à utiliser le système, il n’existe pas d’historique ;
- un risque de « sur-spécialisation » apparaît, c’est-à-dire que l’on se limite aux éléments similaires et que les réponses sont trop homogènes ;
- les profils des utilisateurs restent difficiles à élaborer et, qui plus est, il faut prendre en compte l’évolution des intérêts de l’utilisateur ;
- pour que le système produise des recommandations précises, l’utilisateur doit fournir un feedback sur les suggestions retournées mais cela est chronophage pour lui ;
- finalement, ces systèmes sont entièrement basés sur les scores d’éléments et les scores d’intérêt : moins il y a de scores, plus l’ensemble de recommandations possibles est limité.
Exemple 2
Considérons un catalogue de livres, tel que l’extrait présenté dans le tableau 1, ainsi que l’extrait du profil de l’utilisatrice Marie, basé sur ses précédents achats de livres et sur les informations qu’elle a données concernant ses préférences, tel qu’illustré par le tableau 2. Nous souhaitons proposer à Marie des livres susceptibles de lui plaire. Il s’agit de faire coïncider le tableau 1 et le tableau 2 et de définir quels livres correspondent le mieux aux préférences de Marie. Le tableau 3 résume la coïncidence entre les deux autres tableaux (oui : les informations coïncident ; non : les informations ne coïncident pas). Ainsi à partir du tableau 3, intuitivement, les livres « Shining » et « Millenium » pourraient être recommandés à Marie (puisque les caractéristiques de ces deux livres coïncident le mieux avec les préférences de Marie).
| Titre | Genre | Auteur | Prix | Mots-clés |
| Shining | Thriller | S. King | 19,50 | Alcoolisme, Colorado, Médium, Surnaturel, Hôtel, … |
| Millenium | Policier | S. Larsson | 23,20 | Journalisme, Investigation, Meurtre, Suède, Politique, … |
| Le Journal de Bridget Jones | Romance | H. Fielding | 8,50 | Célibataire, Humour, Amour, Trentenaire, Journal intime, … |
Tableau 1 : Extrait du catalogue de livres.
| Identifiant | 1 | |
| Informations personnelles | Prénom | Marie |
| Sexe | Femme | |
| Livres | Genres | Thriller, Policier |
| Auteurs | S. King, M. Connelly | |
| Titres | Docteur Sleep, Joyland, Intervention Suicide, Darling Lilly, … | |
| Mots-clés | Détective, Meurtre, Surnaturel, … | |
| Prix moyen | 20 | |
| Films | Genres | Jeunesse, Dessins animés, Humour |
| Réalisateur | G. Lucas | |
Tableau 2 : Extrait du profil de l’utilisatrice Marie.
| Préférences utilisateur | Shining | Millenium | Bridget Jones |
| Genre | Oui | Oui | Non |
| Prix | Oui | Oui | Oui |
| Auteur | Oui | Non | Non |
| Mots-clés | Oui | Oui | Non |
Tableau 3 : Coïncidence entre les caractéristiques des livres et les préférences de Marie indiquées dans son profil.
En pratique : la web-radio Pandora
Pandora est une web-radio (accessible uniquement aux États-Unis) incorporant un service automatisé de recommandation musicale créé par le Projet du Génome Musical (Music Genome Project).
Pandora a collaboré avec des milliers de musicologues pour construire le Projet du Génome Musical, dans lequel chaque chanson est étiquetée avec un « génome » basé sur environ 450 caractéristiques musicales ou « gènes » (certains genres de musique ont plus de gènes que d’autres).
Dans Pandora, l’utilisateur indique d’abord le nom d’un artiste ou un titre de musique. Puis le système prend en charge la suite de la liste musicale, sélectionnant les titres se rapprochant musicalement du premier choix.
Voix, instruments, effets, rythmes, pas moins de 400 aspects musicaux sont analysés pour chaque nouvelle musique et le répertoire de Pandora intègre plus de 10 000 artistes.
Par exemple, si vous aimez les chansons d’Aretha Franklin, vous aurez accès non seulement à la gamme des morceaux de cette artiste, mais également à plusieurs extraits musicaux d’autres chanteuses de jazz, de soul et de rhythm and blues, comme Dinah Washington et Etta James.
De plus, à chaque nouveau titre proposé par le système, l’utilisateur peut le noter favorablement ou défavorablement, permettant d’affiner les choix du système. Quatre options sont proposées à l’internaute :
- « Thumbs up » (pouce tourné vers le haut) qui indique à Pandora de jouer davantage de musiques similaires à celle-ci,
- « 0 response » (pas de réponse) qui indique qu’il n’y a pas de changement dans les préférences musicales,
- « Zzzz » qui entraîne que le titre ne sera plus joué pendant un mois
- et « Thumbs down » (pouce tourné vers le bas) qui indique à Pandora de ne plus jouer ce titre et d’éviter les musiques similaires. Au deuxième vote négatif portant sur un morceau du même artiste, Pandora filtrera ses recommandations musicales afin que l’artiste ne soit plus disponible dans la liste de lecture de l’internaute.
Les approches basées sur le filtrage collaboratif
Les systèmes basés sur le filtrage collaboratif (voir la référence [SFHS07] pour plus de détails) produisent des recommandations en calculant la similarité entre les préférences d’un utilisateur et celles d’autres utilisateurs [Neg15b]. De tels systèmes ne tentent pas d’analyser ou de comprendre le contenu des éléments à recommander. La méthode consiste à faire des prévisions automatiques sur les intérêts d’un utilisateur en collectant des avis de nombreux utilisateurs. L’hypothèse sous-jacente de cette approche est que ceux qui ont aimé un élément spécifique dans le passé auront tendance à aimer cet élément spécifique, ou un autre très « proche », à nouveau dans l’avenir. La figure 2 illustre ce processus.
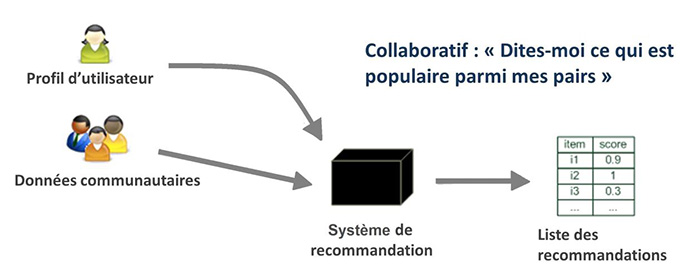
Figure 2 : Un système de recommandation collaboratif (adapté de [JZFF10]).
- de nombreuses préférences d’utilisateurs sont enregistrées ;
- un sous-groupe d’utilisateurs est repéré dont les préférences sont similaires à celles de l’utilisateur qui cherche la recommandation ;
- une moyenne des préférences pour ce groupe est calculée ;
- la fonction de préférence qui en résulte est utilisée pour recommander des éléments à l’utilisateur qui cherche la recommandation.
Il est possible de distinguer trois types d’approches pour définir la similitude ou la similarité :
- les approches Item-to-Item basées sur la similarité entre les éléments (items). Notons que cette approche s’adapte à un nombre très important d’utilisateurs ou d’éléments.
- les approches User-to-User basées sur la similarité entre les utilisateurs (users). Notons que cette approche n’est pas adaptée à un nombre très important d’utilisateurs.
- et les autres approches.
Nous avons déjà utilisé l’approche User-to-User dans l’exemple 1 :
Marie et Elsa ont des avis similaires ; Marie apprécie aussi « Harry Potter », c’est donc une bonne recommandation pour Elsa.
Utilisons maintenant l’approche Item-to-Item sur ce même exemple.
Elsa et Marie aiment « L’Âge de glace » et « Bienvenue chez les Ch’tis ». Cela suggère que, en général, les personnes qui aiment « L’Âge de glace » aimeront aussi « Bienvenue chez les Ch’tis », donc « Bienvenue chez les Ch’tis » pourra être recommandé à Arnaud (qui aime « L’Âge de glace »).
Les systèmes de recommandation collaboratifs, par leur diversité, s’appuient donc sur de nombreuses techniques, qu’il s’agisse de :
- similarité entre utilisateurs (coefficient de corrélation de Pearson [RN88], etc.) ou de sélection de voisinage (les algorithmes basés sur la recherche de voisinage) pour les approches User-to-User ;
- similarité entre éléments (la mesure de similarité cosinus [Qam10], etc.) pour les approches Item-to-Item ;
- techniques de prédiction de scores (analyse en composantes principales ou ACP, factorisation de matrices, analyse sémantique latente, règles d’association, approches bayésiennes, etc.) pour les autres approches.
Les systèmes de recommandation collaboratifs ont comme avantages :
- d’utiliser les scores d’autres utilisateurs pour évaluer l’utilité des éléments ;
- de trouver des utilisateurs ou groupes d’utilisateurs dont les intérêts correspondent à l’utilisateur courant ;
- et plus il y a d’utilisateurs plus il y a de scores : meilleurs sont alors les résultats.
Cependant, de tels systèmes ont aussi des inconvénients :
- trouver des utilisateurs ou groupes d’utilisateurs similaires est difficile ;
- le système de recommandation se heurte à la faible densité de la matrice Utilisateurs X Éléments ;
- de plus, il existe aussi le problème du démarrage à froid (cold-start problem) : lorsqu’un nouvel utilisateur utilise le système, ses préférences ne sont pas connues et lorsqu’un nouvel élément est ajouté au catalogue, personne ne lui a attribué de score ;
- dans les systèmes avec un grand nombre d’éléments et d’utilisateurs, le calcul croît linéairement ; des algorithmes appropriés sont donc nécessaires ;
- la « non-diversité » : il n’est pas utile de recommander tous les films avec l’acteur Antonio Banderas à un utilisateur qui a aimé l’un d’eux dans le passé.
En pratique : l’exemple d’Amazon
Amazon.com utilise des algorithmes de recommandation pour personnaliser la boutique en ligne pour chaque client. Le magasin change radicalement en fonction des intérêts des clients, montrant des produits de programmation à un ingénieur logiciel ou des jouets pour bébés aux jeunes parents.
L’algorithme d’Amazon.com est basé sur le filtrage collaboratif appliqué aux éléments (Item-based collaborative filtering ou Item-to-Item). Le calcul en temps réel de cet algorithme s’adapte à la fois au nombre de clients et au nombre de produits dans le catalogue.
Amazon.com utilise les recommandations comme un outil de marketing ciblé. Cliquer sur le lien « Vos recommandations » conduit les clients dans une zone où ils peuvent filtrer leurs recommandations par ligne de produit et/ou par domaine, évaluer les produits recommandés, évaluer leurs achats antérieurs, et comprendre pourquoi les produits sont recommandés (voir la figure 3 : ces recommandations pourraient correspondre à l’utilisatrice Marie, rencontrée dans les différents exemples précédents). De plus, comme illustré sur la figure 4, le panier de recommandations propose aux clients des suggestions de produits sur la base des produits dans leur panier. La fonction est similaire aux achats impulsifs dans une ligne de caisse du supermarché, sauf que sur Amazon.com, les achats impulsifs sont ciblés pour chaque client. En effet, Amazon.com utilise des algorithmes de recommandation pour personnaliser son site web en fonction des intérêts de chaque client. Ces algorithmes sont basés sur le filtrage collaboratif Item-to-Item. Le calcul en temps réel s’adapte au nombre de clients et au nombre de produits dans le catalogue. Il fait coïncider chacun des produits achetés et notés par l’utilisateur avec des produits similaires, puis combine ces produits similaires dans une liste de recommandations. Pour déterminer la correspondance la plus proche d’un produit donné, l’algorithme construit une matrice de produits similaires en trouvant les produits que les clients ont tendance à acheter ensemble. Plus précisément, pour construire cette matrice, l’algorithme trouve des produits similaires à chacun des achats et des évaluations de l’utilisateur, agrège ces produits, puis recommande les produits les plus populaires ou les plus corrélés. Ce calcul est très rapide, car il dépend seulement du nombre de produits que l’utilisateur a achetés ou notés [Neg15b].

Figure 3 : « Vos recommandations » sur le site Amazon.com.

Figure 4 : Panier de recommandations sur le site Amazon.com.
Les approches hybrides
Un système de recommandation hybride utilise des composants de différents types d’approches de recommandation ou s’appuie sur leur logique (voir [Bur02] pour un aperçu). Par exemple, un tel système peut utiliser à la fois des connaissances extérieures et les caractéristiques des éléments, combinant ainsi des approches collaboratives et basées sur le contenu [Neg15b].
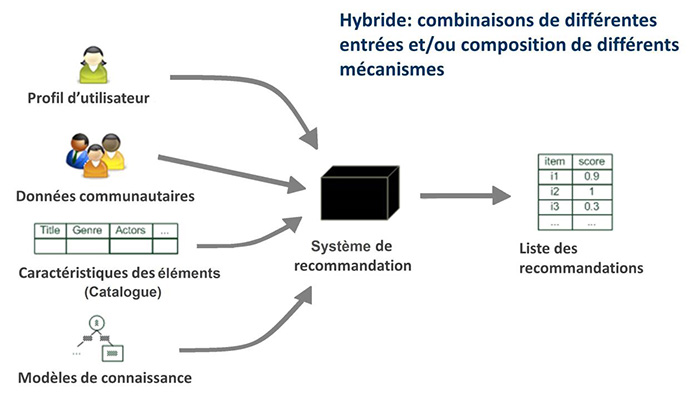
Figure 5 : Le système de recommandation hybride (adapté de [JZFF10]).
La figure 5 illustre ce processus. Notons qu’une approche hybride étant une combinaison d’approches, elle présente les avantages des approches qui la composent tout en limitant leurs inconvénients [Neg15b]. Il existe trois grandes catégories de combinaisons de systèmes de recommandation pour concevoir un système de recommandation hybride [Bur02, JZFF10] : la combinaison monolithique (monolithic hybridization design), la combinaison parallèle (parallelized hybridization design) et la combinaison tubulaire (pipelined hybridization design).
« Monolithique » décrit une conception d’hybridation qui intègre les aspects de différentes stratégies de recommandation en un seul algorithme. Comme illustré sur la figure 6, différents systèmes de recommandation y contribuent puisque l’approche hybride utilise des données d’entrée additionnelles qui sont spécifiques à un autre algorithme de recommandation, ou bien les données d’entrée sont complétées par une technique et exploitées par une autre. Par exemple, un système de recommandation basé sur le contenu qui exploite également des données communautaires pour déterminer des similarités entre éléments relève de cette catégorie.
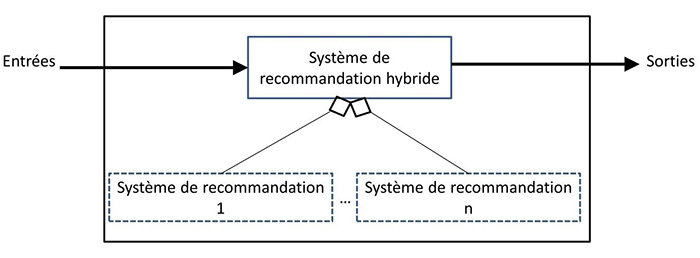
Figure 6 : Conception d’hybridation monolithique (traduction de [JZFF10]).
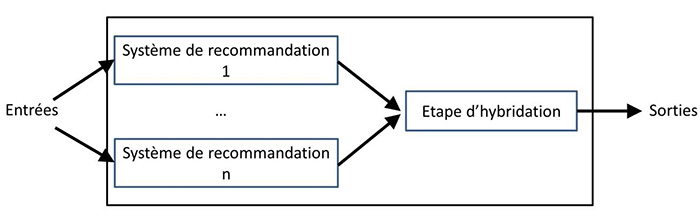
Figure 7 : Conception d’hybridation parallèle (traduction de [JZFF10]).
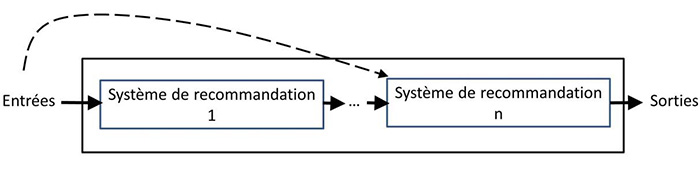
Figure 8 : Conception d’hybridation tubulaire (traduction de [JZFF10]).
En pratique : les recommandations de Netflix
Netflix, un service de location de films en ligne, permet aux utilisateurs de louer des films pour un forfait mensuel, en fonction d’une liste de films prioritaires qu’ils souhaitent voir (leur « file d’attente »). Les films sont envoyés aux utilisateurs ou livrés par voie électronique. Dans le cas de DVD, lorsque l’utilisateur a fini de regarder le film, il suffit de retourner le DVD par la poste et le prochain DVD est automatiquement envoyé par la poste, sans frais de port. La durée de souscription des abonnés est liée au nombre de films qu’ils regardent et apprécient. Si les abonnés ne parviennent pas à trouver des films qui les intéressent, ils ont tendance à abandonner le service. Proposer aux abonnés des films qu’ils vont adorer est donc essentiel à la fois aux abonnés et à la société. L’entreprise encourage donc les abonnés à évaluer les films qu’ils regardent.
À ce jour, la société a recueilli plus de 1,9 milliard de notes de plus de 11,7 millions d’abonnés sur plus de 85 000 titres depuis octobre 1998. La société a livré plus de 1 milliard de DVD, expédiant plus de 1,5 million de DVD par jour. Elle reçoit plus de 2 millions d’évaluations par jour.
Le système de recommandation (hybride) de la société Netflix, Cinematch, analyse les scores cumulés de films et les utilise pour faire plusieurs centaines de millions de prédictions personnalisées aux abonnés, par jour, chacune basée sur leurs goûts particuliers. Le système de recommandation Cinematch analyse automatiquement les scores cumulés de films de façon hebdomadaire en utilisant une variante du coefficient de corrélation de Pearson avec tous les autres films afin de déterminer une liste de films « semblables » qui sont susceptibles de plaire. Puis, comme l’utilisateur fournit des scores, la partie en ligne et temps réel du système calcule une régression multivariée basée sur ces corrélations pour déterminer une prédiction unique et personnalisée pour chaque film recommandable fondée sur ces scores. Si aucune recommandation personnalisée n’est disponible, la note moyenne obtenue à partir de tous les scores donnés au film, est utilisée. Ces prédictions sont visualisées sur le site web via des étoiles rouges [BEN07].
L’importance de prévoir les scores avec précision est si élevée que Netflix a offert, depuis octobre 2006, certains prix, comme un prix d’un million de dollars pour le premier algorithme qui pourrait battre de 10 % son propre système de recommandation. Le prix a finalement été remporté en 2009, par une équipe de chercheurs appelée Bellkor’s Pragmatic Chaos [KOR09], après plus de trois années de compétition [Neg15b].
Pour être exact, l’algorithme devait avoir une erreur quadratique moyenne (RMSE) inférieure de 10 % à celle de l’algorithme de Netflix sur un ensemble test pris à partir de scores réels d’utilisateurs de Netflix. Pour développer leur algorithme, les participants ont reçu un échantillon de données (également des données réelles de Netflix). Les gagnants des différents prix sont tenus de documenter et publier leurs approches publiquement, permettant à chacun de comprendre et de tirer profit des connaissances et des techniques nécessaires pour atteindre les meilleurs résultats possibles.
[BEN07] J. Bennett, S. Lanning, «The Netflix Prize», Proceedings of the KDD Cup Workshop 2007, New York, ACM, p.3-6, août 2007.
[Bur02] Robin Burke. Hybrid recommender systems: Survey and experiments. User Modeling and User-Adapted Interaction, 12(4): 331-370, November 2002.
[BYRN99] Ricardo A. Baeza-Yates and Berthier Ribeiro-Neto. Modern Information Retrieval. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA, 1999.
[JZFF10] Dietmar Jannach, Markus Zanker, Alexander Felfernig, and Gerhard Friedrich.
Recommender Systems: An Introduction. Cambridge University Press, New York, NY, USA, 1st edition, 2010.
[Klo09] M. A. Klopotek. Approaches to cold-start in recommender systems. Studia Informatica: systems and information technology, Vol. 1(12): 47-54, 2009.
[KOR09] Y. Koren, The BellKor Solution to the Netflix Grand Prize, 2009.
[LIN03] G. Linden, B. Smith, J. York, « Amazon.com recommendations: item-to-item collaborative filtering », Internet Computing, IEEE, vol.7, n°1, P.76-80, janvier 2003.
[Neg15b] Elsa Negre. Systèmes de recommandation – Introduction. ISTE, 2015.
[PB07] Michael J. Pazzani and Daniel Billsus. The adaptive web. chapter Content-based Recommendation Systems, pages 325-341. Springer-Verlag, Berlin, Heidelberg, 2007.
[Qam10] Ali Mustafa Qamar. Generalized Cosine and Similarity Metrics : A Supervised Learning Approach based on Nearest Neighbors. Thèses, Université de Grenoble, Novembre 2010.
[RN88] Joseph L. Rodgers and Alan W. Nicewander. Thirteen Ways to Look at the Correlation Coefficient. The American Statistician, 42(1): 59-66, 1988.
[SFHS07] J. Ben Schafer, Dan Frankowski, Jon Herlocker, and Shilad Sen. The adaptive web. chapter Collaborative Filtering Recommender Systems, pages 291-324. Springer-Verlag, Berlin, Heidelberg,2007.
[SWY75] G. Salton, A. Wong, and C. S. Yang. A vector space model for automatic indexing. Commun. ACM, 18(11): 613-620, November 1975.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Elsa Negre