

sous licence Creative Commons
Le problème du videur : la crédibilité des explications de l’IA en question
De plus en plus d’algorithmes dits d’IA (intelligence artificielle), sont déployés dans les entreprises ou institutions pour fournir des décisions aux utilisateurs. L’impact de ces algorithmes sur la vie de leurs utilisateurs varie fortement : il est relativement limité pour les algorithmes de recommandation (qui trient l’information disponible sur une plate-forme pour choisir un ensemble restreint d’objets à consommer par l’internaute), mais bien plus important pour les algorithmes d’allocation de crédit, et plus encore pour ceux qui déterminent les priorités d’hospitalisations.
Face à l’obscurité des décisions prises, et au fait que les paramètres de ces algorithmes ne sont généralement pas rendus publics, de plus en plus de personnes s’interrogent sur la justesse, l’absence de biais, ou les raisons précises de telle ou telle décision. Certaines plates-formes donnent des explications, qui restent laconiques (par exemple, YouTube : « Le public de X regarde aussi cette chaîne », ou Facebook : « Why am I seing this ad? »). L’explicabilité des systèmes d’intelligence artificielle sera-t-elle alors la pierre angulaire nécessaire à la confiance des utilisateurs confrontés aux décisions des algorithmes d’IA ? Probablement pas.
En effet, nous montrons dans cet article qu’il est très facile pour une entité malveillante de falsifier les explications de son algorithme décisionnel.
L’analogie du videur
Pour l’illustrer, nous partons d’une analogie entre le videur d’une boîte de nuit (qui décide si un client qui se présente peut entrer ou pas) et un classifieur (un algorithme d’IA qui attribue un label à chaque requête). D’un point de vue abstrait, le rôle du videur est d’abord d’observer chaque candidat à l’entrée en boîte de nuit, et ensuite de décider si le candidat peut entrer. En d’autres termes, il attribue un label (« peut entrer »/ »ne peut pas entrer ») à chaque requête (chaque client qui se présente) : c’est un classifieur binaire.
Obligeons maintenant notre videur à donner une explication pour chaque décision : le videur devient un classifieur explicable. L’idée peut à première vue paraître séduisante : si le videur doit s’expliquer, il lui sera plus difficile de baser sa décision d’admission sur de mauvais critères. La perspective pour le videur de devoir avouer qu’il sélectionne les candidats à l’entrée sur – par exemple – leur couleur de peau (alors que c’est interdit par la loi), nous apporterait une garantie de qualité sur le processus de sélection. C’est en tout cas le raisonnement qui a pu pousser la Commission européenne et différents organismes à envisager l’explicabilité des algorithmes comme une solution pour l’acceptation des techniques d’IA par le public.
Seulement voilà, le videur peut mentir. En effet, il peut librement refuser l’entrée à un individu pour des raisons discriminatoires (par exemple sa couleur de peau), tout en invoquant d’autres raisons dans son explication (par exemple sa tenue). Et puisqu’on ne peut pas « lire » dans la tête d’un videur, ce mensonge n’est pas détectable pour un utilisateur isolé. En résumé, si l’on doute de l’honnêteté du videur, ses explications ne changeront probablement rien au doute sur sa conduite.
Qu’en est-il de ce raisonnement dans le monde numérique ? L’exemple ci- dessus souligne que le nœud du problème réside dans la capacité du videur à inventer des explications. Pour étudier cette question dans le monde des classifieurs, nous devons formaliser quelques notions.
Un modèle simple d’explication des décisions
Classifieur : Nous considérons un classifieur parmi l’ensemble des classifieurs binaires, répondant « oui » ou « non » à des requêtes. Ces requêtes proviennent de l’espace d’attributs, qui ainsi décrit l’ensemble des attributs considérés par le classifieur pour exécuter son action. Nous considérons que cet ensemble contient deux types d’attributs : les attributs légitimes et les attributs discriminatoires. Les attributs légitimes sont ceux sur lesquels notre classifieur a le droit de baser sa décision et ses explications. Les attributs illégitimes — ici définis comme discriminatoires — sont les attributs qu’il n’a pas le droit d’utiliser. À titre d’exemple, si le classifieur implémente un videur, l’ensemble d’attributs légitimes encodera des informations du candidat à l’entrée sur le soin de sa tenue, ou sa possible ivresse. L’ensemble d’attributs discriminatoires encodera par contre des informations sur la couleur de peau ou le genre du candidat.
Discrimination : Cette partition des attributs d’entrée engendre une partition des classifieurs. On distinguera ainsi l’ensemble des classifieurs légitimes, c’est-à-dire n’utilisant que des attributs légitimes pour produire une décision, et l’ensemble complémentaire contenant les autres classifieurs qui utilisent au moins un attribut discriminatoire. Nous pouvons maintenant formuler la question qui nous anime : « face à un classifieur, peut-on déterminer s’il est discriminatoire ou pas, en se basant sur des explications accompagnant la décision ? »
Interaction : Il nous reste maintenant à préciser l’interaction que nous pouvons avoir avec le classifieur. Comme il s’agit d’un classifieur mis à disposition par une plate-forme, nous sommes devant une interaction en boîte noire : nous ne pouvons que lui soumettre des entrées, puis collecter chaque décision (sans aucune idée, donc, sur le traitement effectué sur ces entrées).
Explication : Enfin, ajoutons une explication : supposons que le classifieur soit explicable (ce qui n’est parfois pas une mince affaire, voire impossible nativement dans le cas des réseaux de neurones) et qu’il soit en mesure de produire pour chaque requête une explication de la décision. Supposons de plus que celle-ci soit si complète qu’elle permette de tout révéler, et en particulier de révéler si le classifieur s’est appuyé sur un attribut discriminatoire : une seule explication obtenue d’un classifieur discriminatoire révèle qu’il est discriminatoire.
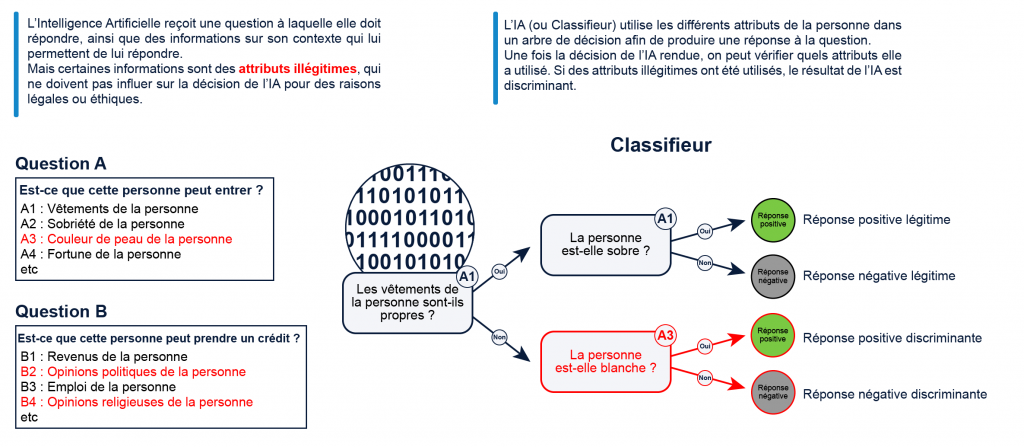
Nous avons dressé ici un tableau idyllique : puisque les utilisateurs doutent d’un classifieur, on leur fournit une explication. Si le classifieur était discriminatoire alors l’explication l’aurait révélé ; et si elle ne le révèle pas, alors les utilisateurs peuvent avoir confiance.
Ce type d’explication « idéale » est rarement rencontré en pratique : les explications des services en ligne sont généralement parcellaires. L’objectif ici est de montrer que le problème ne réside pas dans l’explication et que construire de meilleurs systèmes d’explications, bien que cela ne soit pas trivial, ne changera rien.
L’attaque « relations publiques »
Imaginons maintenant un fournisseur de service malhonnête, qui souhaite 1) prendre des décisions discriminatoires, et ceci 2) sans avoir à le révéler. Puisque toute explication issue du classifieur révèle la nature discriminatoire du traitement, l’astuce consiste a créer de toutes pièces un nouveau classifieur 1) qui produit la même décision que le précédent, et 2) qui est légitime. Ainsi, au moment de produire une explication correspondant à la décision initialement discriminatoire, le fournisseur de service malhonnête « invente » un nouveau classifieur, puis l’utilise pour produire une explication légitime.
À ce stade, il est important de comprendre que de trouver un tel nouveau classifieur est très aisé pour la plate-forme, puisqu’il suffit simplement d’une fonction passant par un seul point (correspondant aux entrées et à la décision discriminatoire). Une approche efficace pour fabriquer un tel classifieur consiste à partir du classifieur discriminatoire pour trouver un nouveau classifieur légitime. Illustrons ceci dans le cas d’un classifieur utilisant un arbre de décision : il suffit dans ce cas de supprimer les nœuds discriminatoires de l’arbre.
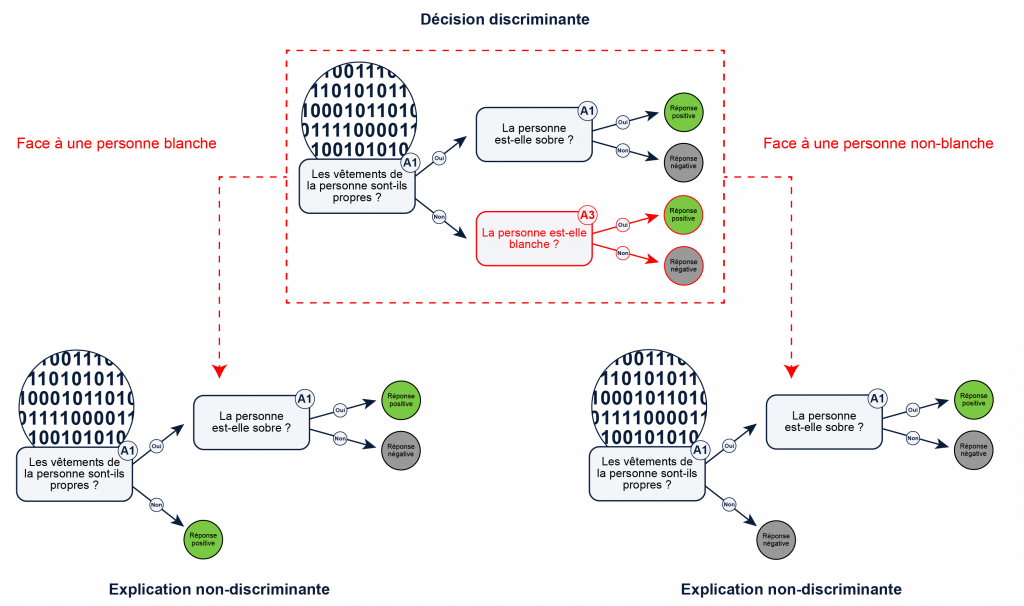
Un exemple de l’attaque des « relations publiques » sur un arbre de décision. Le classifieur encadré est discriminatoire puisqu’il base sa décision sur un critère discriminatoire en rouge : la couleur de peau. L’attaque consiste ici, pour ne jamais expliquer celui-ci, à supprimer tous les nœuds discriminatoires (rouges) et à les remplacer par la sous-branche du nœud correspondant à la situation à expliquer. Ainsi, face à un individu non blanc dont les vêtements sont sales, il sera expliqué que ces vêtements interdisent l’entrée (arbre dérivé de droite), et face à un individu aux vêtements sales mais blanc, il sera expliqué que ces vêtements permettent l’entrée (arbre dérivé de gauche).
Un videur qui discrimine sur la couleur de peau (arbre de décision encadré) et qui verra un client blanc se présenter (cas de gauche sur la figure) créera l’arbre de gauche pour expliquer sa décision. Dans le cas d’un client non blanc, l’arbre de droite sera créé, et justifiera sa décision de rejet par le fait que le client n’a pas les vêtements propres.
Conclusion
Une observation découle d’un tel exemple : un utilisateur seul ne pourra pas découvrir la tromperie, et donc la discrimination dont il a fait l’objet. Par contre, plusieurs utilisateurs pourraient mettre en commun les décisions auxquelles ils ont fait face, pour rechercher et exposer leurs incohérences. Une telle pratique s’observe déjà hors du monde numérique : certaines associations antiracistes font du « testing » sur des boîtes de nuit. Ce dernier point motive l’observation collaborative des décisions et explications des algorithmes d’IA.
Cependant, les classifieurs actuels s’appuient sur des milliers d’attributs pour produire une décision. Ainsi, trouver de telles incohérences devient difficilement accessible par le calcul, voire impossible : il faudra cibler certains attributs particuliers pour effectuer cette recherche et vérifier l’existence d’un biais.
Nous concluons ainsi que l’explicabilité de l’IA, dans sa forme actuelle, ne peut pas établir la confiance des utilisateurs envers les algorithmes décisionnels. Afin de construire cette confiance, nous pensons qu’il est important de développer des méthodes d’audit algorithmique dites « externes » ou « en boîte noire », plutôt que de compter seulement sur la bonne foi des plates-formes. De telles méthodes prendraient le parti d’observer les classifieurs en imitant le comportement des utilisateurs sur la plate-forme, ce qui permettrait d’automatiser la recherches d’incohérences, et donc de tromperies.
Remote Explainability faces the bouncer problem, Erwan Le Merrer, Gilles Trédan. In Nature Machine Intelligence 2, pages 529–539 (2020).
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !


Gilles Trédan
Chargé de recherche au sein du laboratoire d'Analyse et d'Architecture des Systèmes (LAAS) du CNRS.