
Une brève histoire du traitement d’image
Le traitement d’image numérique depuis son essor au tournant des années 1970 et 1980 s’était principalement appuyé sur plusieurs branches des mathématiques appliquées, comme notamment la géométrie, les statistiques (en particulier bayésiennes et markoviennes), le calcul variationnel (et les EDP), l’optimisation, pour modéliser et résoudre les problèmes posés. Les années 2010 ont connu un bouleversement conséquent avec l’émergence décisive de l’apprentissage profond et des réseaux neuronaux. Cet article va évoquer les grands aspects du traitement d’image numérique, sa grande diversité en termes de capteurs et de domaines d’application, en soulignant son évolution sur ces 20-30 dernières années, et terminer par un zoom sur le traitement vidéo.
Un peu de terminologie
Tout d’abord, commençons par un peu de terminologie. Le terme « traitement d’image » peut être pris dans une acception générique, mais dans la communauté scientifique, il désigne plutôt les traitements dits de bas niveau, qui font passer de l’image initiale à une autre image améliorée ou transformée, par filtrage, débruitage, déconvolution, ou détection de contour. Il est utilisé par analogie avec le traitement du signal. Le terme « analyse d’image », sans doute moins usité aujourd’hui, désigne quant à lui les opérations intermédiaires mais qui restent dans l’espace de l’image, comme la segmentation ou la classification d’image, la mise en correspondance entre images (pour la stéréovision notamment). Avec le terme « vision par ordinateur » (ou analyse de scène), l’objectif est alors d’accéder à une information sur la scène tridimensionnelle observée à partir d’une ou de plusieurs images, par reconstruction 3D, estimation du mouvement 3D, mais aussi par segmentation sémantique ou reconnaissance d’objets.
Diversité et évolution des capteurs, des images et des domaines d’applications
Aujourd’hui, à l’heure des smartphones et des réseaux, l’image numérique est perçue comme d’acquisition immédiate et aisée, d’accès facile, de disponibilité sans fin, de transmission instantanée. C’est un objet incontournable et finalement banal du quotidien. Évidemment, il n’en a pas toujours été ainsi. Dans les années 1970 et même au début des années 1980, les équipements d’acquisition et de visualisation d’images numériques, et par conséquent ces dernières, étaient rares et limités pour l’essentiel au domaine de la recherche. Par ailleurs, l’image numérique a revêtu et continue à revêtir bien d’autres formes que celle que l’on acquiert sur son smartphone, comme cela sera évoqué dans la suite.
Si l’on peut définir de manière élémentaire et générique une image numérique comme une matrice de pixels, en général à deux dimensions, parfois à trois dimensions (on parle alors de voxels, contraction de volume et pixel), elle peut en fait provenir de différentes sources et revêtir différents aspects. Cette diversité était présente dès l’origine, mais n’a fait que s’amplifier avec le temps principalement par l’évolution de la technologie des capteurs, et même s’accélérer au XXIe siècle.
La plus courante est certes l’image acquise par une caméra vidéo classique que cela soit pour le monde multimédia, la visioconférence, l’usage personnel, la vision robotique, les véhicules autonomes, la vidéosurveillance, voire en milieu sous-marin où on recourt néanmoins à l’imagerie acoustique (sonar) pour imager les fonds marins à longue distance. La caméra vidéo opère le plus couramment dans le spectre visible, mais également en infrarouge (IR), notamment en IR thermique. Cette instrumentation a beaucoup évolué en termes de miniaturisation, de traitement embarqué, de qualité d’image, de capacité de stockage, de consommation énergétique, de coût financier, ce qui a conduit à une diffusion massive dans beaucoup de secteurs d’activité, y compris pour les objets connectés. Sur une période relativement récente, est apparu un nouveau type de caméra, dit caméra à événements. Contrairement aux caméras classiques qui acquièrent une image (avec tous ses pixels) en un instant donné, ces caméras acquièrent en chaque pixel, de manière asynchrone, une mesure liée à un changement temporel de l’intensité lumineuse captée. Cela permet d’accéder à un échantillonnage temporel beaucoup plus fin et de capter immédiatement l’information à caractère dynamique, notamment celle liée au mouvement.

Image issue d’une vidéo aérienne, simulant les conditions d’acquisition d’un futur satellite, avec, surimposée, la segmentation des (très petits) véhicules en mouvement, autour du rond-point et dans les avenues, segmentation représentée par une couleur fonction de la direction de déplacement des véhicules.
Crédit Image © Airbus DS et résultat provenant de la thèse d’Étienne Meunier (Inria Rennes).
Il existe aussi deux grands domaines où le capteur peut être de nature différente et même très diverse : l’imagerie satellitaire et l’imagerie médicale. L’imagerie satellitaire recouvre la télédétection pour l’observation de la Terre (sols, milieux urbains, cartographie), la météorologie, l’océanographie, l’observation militaire. Les images peuvent être acquises dans différentes bandes spectrales de la lumière et aussi dans le domaine radar. La périodicité d’acquisition dépend notamment de la nature du satellite (satellites à défilement, satellites géostationnaires). Une évolution très récente est la possibilité d’acquérir aussi une vidéo sur un point de visée du satellite, permettant une analyse temporelle beaucoup plus fine. La résolution des images satellitaires (surface au sol couverte par un pixel), à ne pas confondre avec la taille des images, s’est aussi beaucoup améliorée ces dernières années. Elle dépend évidemment du type de satellite, mais peut descendre à moins de 20cm pour certains satellites. On peut aussi évoquer l’astronomie qui a connu des avancées spectaculaires avec successivement les télescopes spatiaux Hubble et James Webb, respectivement opérationnels à partir de 1990 et 2022, et leurs images spectaculaires de l’univers.
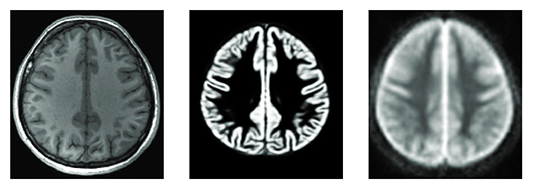
De gauche à droite :
a) IRM anatomique d’un cerveau humain
b) Segmentation / détourage de la substance grise
c) Perfusion cérébrale mesuré par une modalité spécifique d’IRM (l’Arterial Spin Labeling, ASL).
Crédit photo : ERL U1228 Empenn (Inserm/Inria/CNRS/Univ.Rennes) / IRISA.
L’imagerie médicale est un domaine ancien, mais toujours en pleine évolution, aussi bien pour ses dimensions cliniques que de recherche, avec une très large palette de modalités d’image exploitant différents types d’ondes et de rayonnement. On peut citer principalement l’échographie (ondes sonores), l’imagerie par résonance magnétique (IRM) anatomique et fonctionnelle, la radiographie et ses différentes modalités. Dans ce contexte, il est essentiellement question d’images à trois dimensions, dites volumiques. Il existe aussi des modalités plus complexes où chaque pixel contient une information vectorielle, comme l’IRM de diffusion.
Un autre domaine, sans doute moins connu du grand public, est la microscopie, en particulier la microscopie de la cellule en biologie. On peut distinguer la microscopie optique, incluant notamment la microscopie de fluorescence, et la microscopie électronique. La première permet d’observer les cellules vivantes, mais est limitée en pouvoir de résolution spatiale en raison de la limite de diffraction de la lumière. La seconde permet d’étudier des échantillons biologiques préparés par fixation chimique ou par cryofixation, jusqu’à des résolutions extrêmement petites, d’ordre nanométrique. Ce domaine a connu une très grande évolution, voire une révolution, ces 10-20 dernières années permettant d’accéder à l’infiniment petit du vivant, saluée par plusieurs Prix Nobel de Chimie attribués, en 2014, à Betzig, Hell et Moerner pour la super-résolution en microscopie optique, en 2017, à Dubochet, Frank et Henderson en cryomicroscopie électronique. On dispose aujourd’hui de microscopes optiques très performants permettant d’acquérir des séquences temporelles d’images volumiques à grande résolution spatiale.
La révolution du « deep learning »
L’année 2012 est habituellement le moment clé retenu de l’avènement de l’apprentissage profond (« deep learning » en anglais) en traitement d’image avec le dépassement très significatif, par le réseau convolutif profond AlexNet, des performances jusque-là atteintes dans un challenge de classification d’image (ImageNet). Il est bon néanmoins de se garder de toute « épiphanie », les émergences scientifiques ayant souvent une gestation plus ou moins cachée et plus ou moins longue, ce qui est en l’occurrence le cas. Les réseaux préexistaient depuis longtemps, mais la disponibilité simultanée de données massives (et annotées), d’une technologie de processeurs GPU très performants et d’algorithmes d’optimisation adaptés et efficaces, a permis cette réussite. Une réussite avant tout expérimentale, car aujourd’hui, on manque encore d’éléments d’analyse mathématique poussée permettant de modéliser théoriquement les performances obtenues (comme des théorèmes sur la convergence de l’apprentissage, la définition de bornes de confiance sur la prédiction du modèle, ou la fixation fondée des paramètres du modèle), même si des actions de recherche poussent en ce sens.
Au départ, il s’agit de modèles profonds supervisés, c’est-à-dire que l’entraînement du réseau nécessite la disponibilité d’une vérité terrain (en général fournie par une annotation manuelle) afin d’entraîner le réseau à résoudre la tâche proposée. Cette méthodologie a bouleversé la discipline du traitement d’image, où classiquement on concevait et spécifiait des étapes successives partant de l’extraction de caractéristiques des images jusqu’à la reconnaissance visée du contenu de l’image. Désormais, on pouvait prendre directement des images en entrée du réseau et en disposant de la vérité-terrain du problème traité sur un ensemble de données (classes des images par exemple pour un problème de classification), entraîner le réseau, avec à la clé précision et efficacité. Depuis 2012, la communauté du traitement d’image et de la vision par ordinateur s’est massivement investie dans l’apprentissage profond. Bien d’autres sujets que la classification d’image ont été assez rapidement appréhendés comme la segmentation d’image, à savoir le découpage de l’image en zones cohérentes selon un critère donné (la couleur, le mouvement, le type d’objet), ou le recalage d’images par la mise en correspondance d’éléments communs aux deux images selon une transformation géométrique. Il a néanmoins été plus long de traiter correctement par les réseaux profonds les problèmes dits inverses, comme la mesure du mouvement. La vision par ordinateur, comme le traitement du langage naturel (TLN), est un grand contributeur au développement de l’apprentissage profond, où on est progressivement passé à un apprentissage semi-supervisé, autosupervisé et non supervisé, car l’annotation manuelle s’avère dans beaucoup d’applications de la vision par ordinateur trop lourde, difficile, voire impossible à réaliser. Les architectures ont également beaucoup évolué, et une multitude en a été, et continue à être, définie : réseaux récurrents, auto-encodeurs, réseaux antagonistes génératifs, transformeurs, etc.
Zoom sur le traitement vidéo

Illustration de la segmentation du mouvement sur huit vidéos. De haut en bas : une image de la vidéo, le flot optique représenté en code couleur HSV (la teinte pour la direction, la saturation pour l’amplitude), les segments du mouvement (une couleur par segment). Figure provenant du manuscrit de thèse d’Étienne Meunier (Inria Rennes).
La plupart des capteurs permettent d’acquérir non seulement une image mais une séquence d’images ordonnées dans le temps. C’est bien sûr vrai pour les caméras vidéo selon une fréquence temporelle de 25 ou 30Hz, mais c’est aussi le cas en imagerie ultrasonore. On retrouve également des vidéos dites accélérées (ou « time lapse » en anglais), lorsque des images acquises à des intervalles de temps de secondes, voire de minutes ou d’heures, sont accolées pour former une vidéo permettant, par exemple, d’observer la dynamique intracellulaire en microscopie, ou l’évolution de la couverture nuageuse en météorologie. En imagerie satellitaire de télédétection, on parle plutôt de séries temporelles pour des acquisitions très espacées dans le temps de la même zone terrestre.
Une séquence d’images, de par sa dimension temporelle, offre l’accès à la perception du mouvement et donc à son analyse par des méthodes numériques adaptées. Le mouvement apparaissant dans une séquence d’images est la projection dans l’image 2D du mouvement 3D relatif entre la caméra, qui peut être sur un porteur également mobile, et la scène observée qui peut comporter des objets mobiles et des éléments statiques. Dans ce contexte, on pourra parler de traitement vidéo, qui recouvre de nombreuses tâches : détection, mesure, segmentation et interprétation du mouvement présent dans la vidéo, suivi des objets dans la vidéo (ou « tracking »), reconnaissance d’actions, indexation et recherche de vidéos par le contenu. Une tâche centrale est l’estimation du flot optique qui représente l’information dense et complète sur le mouvement entre deux images, car constitué du champ des vecteurs issus de chacun des pixels de l’image et pointant sur leur position dans l’image suivante. La mesure du flot optique a été l’apanage des approches statistiques et variationnelles jusqu’à l’avènement à la fin des années 2010 de méthodes s’appuyant sur l’apprentissage profond. On dispose désormais, dans un cadre supervisé, de réseaux neuronaux très performants et temps réel. La conception de modèles non supervisés, plus favorables à une bonne généralisation sur des types de vidéos absentes à l’apprentissage, est en plein développement.
L’émergence de nouvelles questions
En traitement d’image, comme dans d’autres domaines, le recours à l’apprentissage profond et les performances atteintes soulèvent désormais des questions d’éthique et d’explicabilité. Le déploiement de caméras s’étant largement développé dans l’espace public, le citoyen et le législateur doivent s’emparer des questions soulevées par leur usage et les traitements algorithmiques associés. Si le traitement d’image œuvre à une décision (navigation d’un véhicule autonome par exemple) ou un diagnostic (dans le domaine médical notamment), il devient nécessaire d’apporter des explications à une prédiction fournie par un modèle profond de traitement d’image.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Patrick Bouthemy
Directeur de recherche Inria, spécialiste en traitement d'image.
Photo © Inria / C. Lebedinsky