
sous licence Creative Commons
Comment entraîner une IA sans données : la physique en renfort
Les méthodes d’Intelligence Artificielle (IA) permettent aujourd’hui de construire des modèles décrivant des systèmes très complexes, en travaillant seulement à partir de données d’observation. C’est le cas par exemple en analyse de comportement de foule, domaine pour lequel on ne dispose pas de modèle mathématique mais pour lequel de nombreuses données vidéo sont disponibles. Mais que devient cette démarche d’apprentissage lorsque les données sont rares, voire inexistantes ? Cette situation arrive lorsqu’on s’intéresse à des systèmes difficiles à instrumenter, par exemple un cœur de centrale nucléaire, ou lorsqu’on souhaite concevoir un objet qui n’existe pas encore. En l’absence de données d’observation, l’IA peut-elle nous permettre de construire des modèles en se basant sur les seules lois de la physique, dont la plupart sont connues depuis des décennies voire des siècles ? Immersion dans le monde des réseaux neuronaux informés par la physique.
La modélisation basée sur les données
L’approche standard pour modéliser un phénomène en utilisant l’IA est de chercher à approcher des données observées dans la vie réelle. Plus la quantité de données accessibles est importante et plus la construction du modèle sera facilitée. Ce paradigme de modélisation connaît des succès indiscutables dans des domaines variées comme l’analyse du trafic routier ou la prédiction météorologique.
Pour illustrer la méthode sur un cas concret, considérons un système physique simple : une masse attachée à deux ressorts fixés à leurs extrémités aux parois d’une boite transparente remplie d’un liquide, comme on peut le voir ci-dessous :
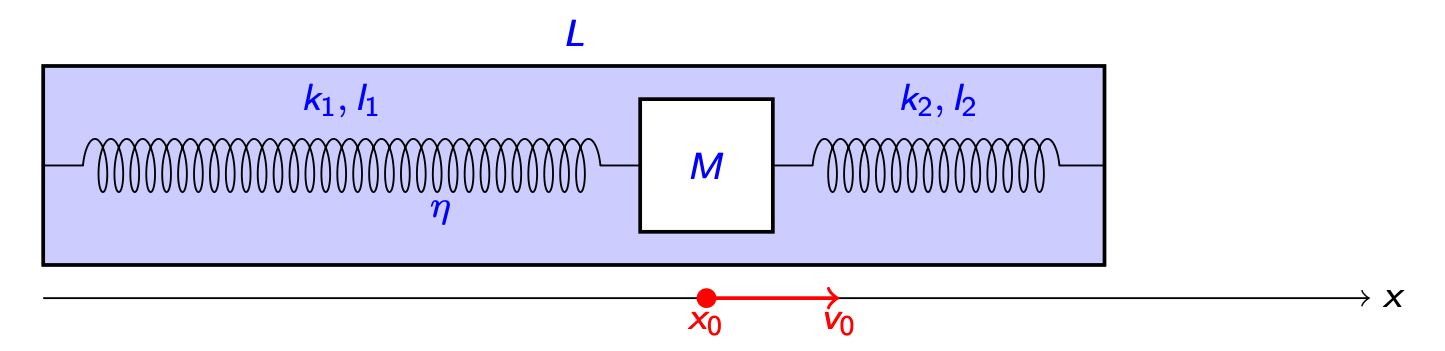
On suppose que la masse ne peut se déplacer que dans la direction horizontale. Le problème à résoudre est alors le suivant : étant données une position initiale \(x_0\) et une vitesse initiale \(v_0\), quelle sera la position de la masse aux instants ultérieurs ? Pour définir parfaitement ce problème, on doit connaitre les caractéristiques des ressorts (raideur \(k\) et longueur au repos \(l\)), du liquide (coefficient de frottement \(η\)) et de la boite (longueur \(L\)). On peut souligner que ce problème est formellement similaire à la prédiction météorologique : étant connue la situation actuelle en termes de pression, vent, température, on cherche à prédire le temps aux dates futures.
Essayons tout d’abord de résoudre ce problème en modélisant le phénomène à partir de données. Pour cela, on suppose qu’on peut observer la position de la masse à quelques instants, par exemple en disposant un appareil photographique prenant des clichés du dispositif à des instants définis. Ainsi, on peut constituer un ensemble de \(N\) paires d’observations (temps \(t\), position \(x\)), représentant les mesures réalisées, comme dans le graphique ci-dessous :
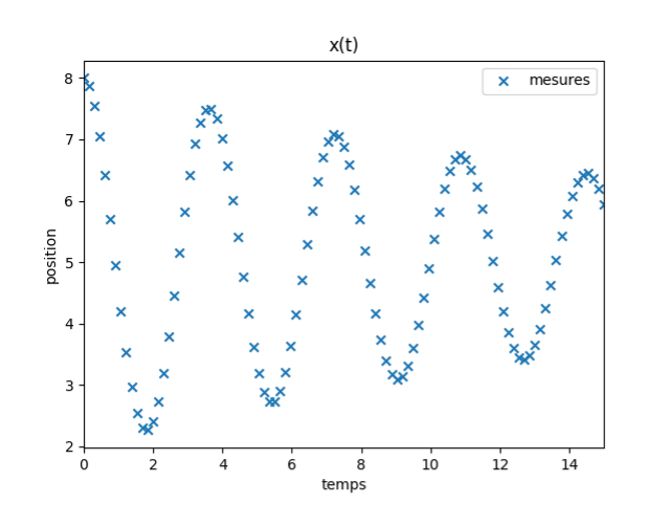
On constate que, pour les conditions de l’expérience, la masse a un mouvement oscillant, avec un amortissement qui réduit progressivement l’amplitude des déplacements.
On souhaite désormais construire un modèle du phénomène, c’est-à-dire une formule mathématique ou numérique permettant d’estimer la position à tous les instants. Pour cela, on s’appuie sur un réseau neuronal multicouche [voir la référence bibliographique 1]. Il s’agit d’un ensemble de neurones artificiels organisé en couches successives, agissant comme une sorte de fonction universelle qui transforme une valeur d’entrée (ici le temps \(t\)) en une valeur de sortie (ici la prédiction de la position de la masse \(x_θ\)), étant donné les poids \(θ\) des connexions neuronales. Il est inutile de décrire plus en détail le fonctionnement du réseau, il suffit de savoir que le choix des poids du réseau détermine entièrement son comportement. Par la suite, si on souhaite que le modèle décrive fidèlement le phénomène (le déplacement de la masse), il faut que ces poids soient précisément ajustés. C’est cette étape fondamentale qu’on appelle entraînement et qui s’appuie sur les données mesurées. Plus précisément, on cherche durant l’entraînement les poids \(θ\) du réseau qui vont permettre de réduire l’erreur de prédiction de la position aux instants mesurés. On cherche ainsi à minimiser la grandeur \(L_{data}\)\(=\)\(|x_θ(t_i)-x(t_i)|\), où les \(t_i\) sont les dates d’observation. Une fois entrainé, le réseau approchera au mieux les données. Cette tâche est réalisée à l’aide d’un algorithme d’optimisation numérique, comme la méthode de descente de gradient [voir la référence 2].
Pour tester cette approche, on sépare les mesures en deux ensembles : les mesures réalisées entre les instants \(0\) et \(10\) serviront de données utilisées pour l’entraînement, tandis que celles entre les instants \(10\) et \(15\) seront des observations tests pour juger de la capacité du modèle à prédire l’évolution future du système. Une fois le réseau entraîné à partir des données, on obtient le résultat suivant :

On constate que le réseau de neurones entraîné à partir des données entre les instants \(0\) et \(10\) reproduit fidèlement les mesures sur cet intervalle. Cependant, la prédiction des instants futurs est complètement erronée et n’est pas du tout en accord avec les observations. Cette expérience met en évidence une faiblesse structurelle de la modélisation à partir de données : dès qu’on s’éloigne de la zone de mesure, le modèle devient inopérant. On constate donc que le réseau n’a pas vraiment appris le phénomène physique, il a juste cherché à mimer les données fournies. Il est intéressant de voir ce qu’on obtient lorsque ces données deviennent rares. On réitère donc l’expérience en considérant pour l’entraînement seulement \(11\) points de données, en l’occurrence une mesure sur sept, toujours dans l’intervalle \(0\) à \(10\). On obtient alors ces résultats :

Même si le modèle parvient à reproduire globalement le comportement oscillant entre les instants \(0\) et \(10\), il est beaucoup moins précis. Ce n’est pas l’entraînement qui est en cause, car on constate que l’erreur aux points de données est proche de zéro, mais c’est la faible densité de données qui conduit à un modèle défaillant. Ces deux expériences montrent bien l’impact critique de la localisation et de la densité des données pour la construction de modèles. Dès lors, comment utiliser cette approche de modélisation lorsque les données sont rares ou même inexistantes, comme c’est le cas si on considère désormais une boîte opaque ? Une piste possible est de baser l’entraînement sur les lois de la physique et non plus sur des mesures expérimentales.
Les lois de la physique
On connaît en effet depuis plusieurs siècles le principe physique en œuvre dans le phénomène qui nous intéresse ici, puisque c’est Newton qui l’a énoncé en 1687 [voir la référence 3] : le produit de la masse du système par son accélération est égal aux forces extérieures exercées. Détaillons ce principe : l’accélération est la variation de vitesse au cours du temps, qui est elle-même la variation de position. Traduit en langage mathématique, cela représente donc la dérivée seconde de la position \(x″(t)\). Les forces extérieures correspondent aux forces exercées par les ressorts, qui sont opposées à leur allongement (\(x(t)-l\)) et proportionnelles à leur raideur \(k\) [voir la référence 4], et à la force de frottement fluide qui est opposée à la vitesse \(x′(t)\) et proportionnelle au coefficient \(η\) [voir la référence 5]. Le principe de Newton se traduit finalement par une équation, qualifiée de différentielle car elle fait apparaître les dérivées de la fonction recherchée \(x(t)\) :
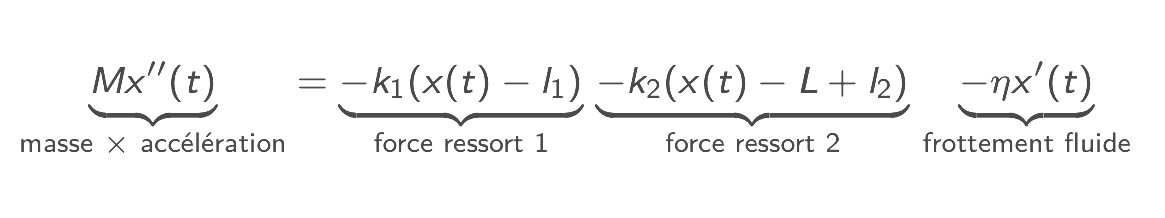
Cette loi physique ne donne pas d’information directe sur la valeur du déplacement mais fournit une information sur ses variations à chaque instant. Voyons maintenant comment elle peut être utilisée selon un paradigme d’apprentissage, par une approche appelée réseaux neuronaux informés par la physique.
L’apprentissage basé sur la physique
L’idée centrale est d’adapter la phase d’entraînement : on remplace la minimisation de l’erreur vis-à-vis des données par la minimisation de l’erreur vis-à-vis de la loi physique. Pour évaluer cette erreur, on considère un ensemble d’instants au cours de l’intervalle de temps à étudier et on calcule pour chaque instant \(t_i\) la position \(x_θ(t_i)\) par le réseau de neurones, ainsi que les dérivées \(x_θ′(t_i)\) et \(x_θ″(t_i)\). Ces dernières sont faciles à calculer en pratique car le réseau n’est finalement qu’une fonction mathématique un peu complexe. On peut alors évaluer l’erreur commise sur le principe de Newton par le réseau de neurones, pour un ensemble de poids \(θ\) donnés. Cette grandeur correspond à \(L_{phys} = | M x_θ″(t_i) + k_1 ( x_θ(t_i) – l_1) + k_2 ( x_θ(t_i) – L + l_2) + η x_θ’(t_i) |\). Il reste alors à ajuster les poids du réseau \(θ\) pour que la sortie du réseau minimise \(L_{phys}\), par un algorithme d’optimisation. On utilise tout de même une donnée pour fixer la position et la vitesse initiale. Lorsqu’on applique cette approche à notre problème, on obtient alors le résultat suivant :
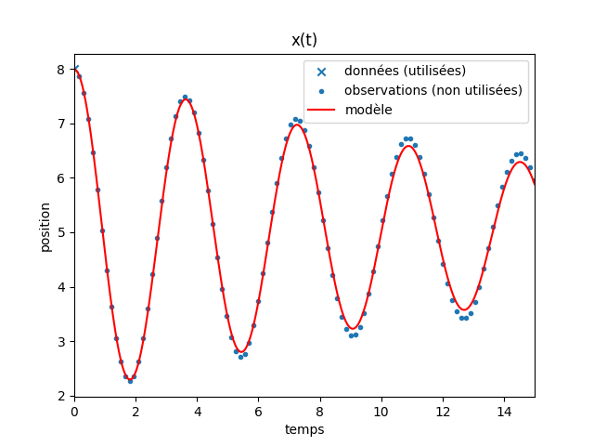
On constate que le réseau entrainé uniquement avec une donnée initiale et le respect du principe physique est capable de prédire l’évolution du système sur l’intégralité de l’intervalle de temps avec une bonne précision. C’est donc un progrès considérable par rapport au modèle construit à partir de données mesurées. On remarque cependant que le modèle a tendance à amortir trop fortement les oscillations à mesure que le temps progresse. Cet effet est dû à l’absence de données en termes de valeurs à l’exception de l’état initial : à partir de la donnée au temps \(0\), le modèle est construit en tenant compte uniquement des variations temporelles. L’erreur commise a donc tendance à s’accumuler au cours du temps et progressivement la prédiction s’écarte de la réalité.
Pour corriger ce défaut, la solution la plus simple est de fournir quelques données d’entraînement en plus de la donnée initiale, si on en dispose, de manière à recaler le modèle à quelques instants. On aboutit ainsi à une méthodologie d’entraînement hybride, basée à la fois sur le principe physique et quelques données. Considérons par exemple un ajout de \(11\) points de données, de manière à retrouver la seconde expérience pour laquelle le modèle basé seulement sur les données donnait un résultat médiocre. On constate alors qu’en utilisant conjointement ces données et le principe physique pour l’entraînement, le modèle conçu permet une prédiction très précise sur l’ensemble de l’intervalle de temps considéré, même pour des données rares localisées entre les instants \(0\) et \(10\).
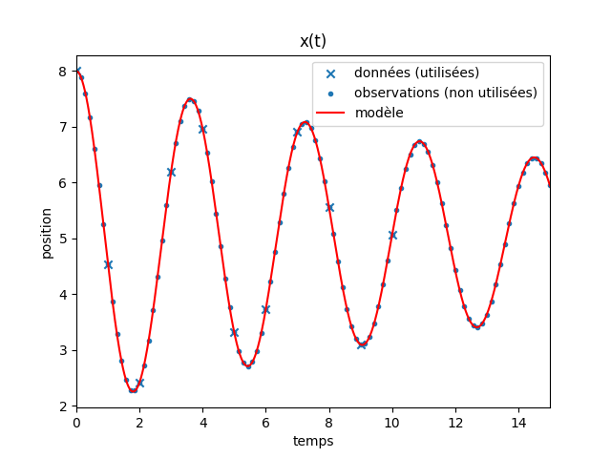
Cette méthodologie hybride semble finalement être une approche prometteuse, retenant à la fois les avantages de l’apprentissage basé sur les données et la puissance des principes de la physique.
Les enjeux et les limites
Il faut cependant prévenir tout enthousiasme prématuré. En effet, si cette approche aboutit à des résultats impressionnants pour des problèmes simples, comme celui présenté ici, de nombreuses difficultés surviennent lorsqu’on s’attaque à des problèmes plus complexes. Le point faible de cette méthode se cache dans la phase d’entraînement : la minimisation de l’erreur devient très difficile dès qu’on considère des lois physiques plus sophistiquées, faisant intervenir par exemple plusieurs équations ou mêlant des dérivées spatiales et temporelles. De même, la minimisation simultanée de l’erreur portant sur les données et celle portant sur les lois physiques aboutit à un problème d’optimisation ardu, mettant en échec la plupart des algorithmes connus aujourd’hui. Il s’agit donc là d’une véritable problématique de recherche actuelle.
Une autre limitation réside dans le coût de calcul associé à ces techniques d’apprentissage. Si on considère un problème pour lequel on dispose d’outils de simulation dédiés, comme par exemple la méthode des éléments finis [voir la référence 6], la comparaison des deux méthodologies révèle que l’approche par apprentissage peut être mille fois plus lente que les outils de simulation standards. Ce n’est pas complètement étonnant, dans la mesure où ces derniers ont bénéficié de 40 ans de maturation et sont généralement écrits spécifiquement pour résoudre un problème précis, tandis que les méthodes d’apprentissage sont bien plus générales. Cela signifie que la simulation par apprentissage ne doit pas être perçue comme un remplaçant des méthodes standards, mais ouvre des possibilités nouvelles, comme la modélisation hybride basée sur quelques données et des lois physiques, présentée dans cet article. Une autre perspective d’intérêt concerne la construction de modèles dits paramétriques, c’est-à-dire capables de prédire l’évolution du système pour des configurations de fonctionnement variables. Pour le cas traité dans cet article, on pourrait vouloir prédire le déplacement du système pour un intervalle de raideur des ressorts et un intervalle de coefficient de frottement. Par un outil de simulation standard, cela nécessiterait de réaliser plusieurs milliers de simulations indépendantes (par exemple 10 simulations en faisant varier le ressort 1, fois 10 simulations pour le ressort 2, fois 10 simulations en faisant varier le frottement). Avec une approche d’apprentissage informée par la physique, il suffit de faire varier ces coefficients dans la loi physique lors de l’entraînement pour construire un modèle unique, valide pour l’ensemble des configurations souhaitées, pour un coût de calcul inchangé. Cette approche possède donc un potentiel important, que ce soit pour modéliser des systèmes difficiles d’accès pour la mesure ou pour construire des modèles englobant des phénomènes physiques variables.
- [1] lien wikipedia « réseau de neurones artificiels », page consultée le 25/05/2026.
- [2] lien wikipedia « algorithme du gradient », page consultée le 25/05/2026.
- [3] lien wikipedia « loi du mouvement de Newton », page consultée le 25/05/2026.
- [4] lien wikipedia « ressort (mécanique élémentaire) », page consultée le 25/05/2026.
- [5] lien wikipedia « frottement fluide », page consultée le 25/05/2026.
- [6] lien wikipedia « Méthode des éléments finis », page consultée le 25/05/2026.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Régis Duvigneau
Directeur de recherche Inria au sein de l'équipe de recherche ACUMES.