Et plus vite si affinités…
Nous assistons depuis plusieurs années à la révolution des processeurs multicœurs. Les microprocesseurs de nos ordinateurs sont chargés d’exécuter toutes les opérations, calculs… Ils contiennent désormais plusieurs cœurs et bientôt des dizaines, ce qui leur permet de traiter de nombreuses tâches simultanément. Cette révolution lance de grands défis, dont celui de la gestion des affinités dans ces machines. En effet, la vitesse d’exécution d’une tâche peut varier significativement selon le cœur qui sera chargé de la traiter.
Principe de localité et mémoire cache
Les processeurs et cœurs travaillent sur des objets généralement stockés en mémoire. Ils doivent aller chercher ces données dans la mémoire, les traiter puis ranger le résultat dans la mémoire. Lire ou écrire dans la mémoire prend de l’ordre de 100 nanosecondes. Cela peut paraître très faible, mais c’est en fait énorme quand on le compare à la vitesse d’exécution des processeurs actuels : ils peuvent désormais traiter plusieurs opérations par nanoseconde !

© Inria / C. Tourniaire
Il est important que ces accès lents à la mémoire ne ralentissent pas trop le traitement de ces milliards d’instructions par seconde. Le processeur va donc rapatrier les données dont il a besoin à l’avance, les garder près de lui pendant qu’il les utilise puis les renvoyer en mémoire une fois terminé.
On peut comparer ce comportement à celui d’un employé qui doit travailler sur des documents papier. Les documents étant stockés dans un dossier dans une armoire, il va ramener le dossier sur son bureau pendant qu’il travaille sur ces documents, puis ranger le dossier dans l’armoire. Le fait de poser le dossier complet sur son bureau lui permet en fait de récupérer plusieurs documents d’un coup et donc de ne pas avoir à retourner à l’armoire plusieurs fois.
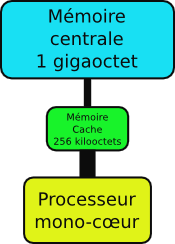
Machine avec un seul processeur (contenant un seul cœur).
Il y a une dizaine d’années, la plupart des machines étaient essentiellement composées d’un seul processeur (contenant un seul cœur) et d’un banc mémoire. Entre les deux, une petite zone de mémoire cache (256 kilo-octets ici, intégrée au processeur depuis) stockait les informations les plus couramment utilisées pour permettre d’y accéder plus rapidement, en évitant d’aller lire jusque dans la mémoire principale, plus grande mais plus lente.
Dans un ordinateur, les processeurs utilisent une petite mémoire spéciale appelée Cache pour garder temporairement les données dont ils ont besoin. Elles sont renvoyées en mémoire plus tard, quand on ne s’en sert plus. Quand une donnée est dans le cache, on peut y accéder beaucoup plus vite, en quelques dizaines de nanosecondes. Ainsi, la mémoire cache permet d’accélérer les travaux (jusqu’à 10 fois), car certaines données sont presque immédiatement disponibles, sans avoir à faire des aller-retours vers la mémoire principale.
Bien entendu, produire des mémoires aussi rapides coûte cher. Si on était capable de les produire en très grande quantité et à moindre coût, on les utiliserait à la place de la mémoire principale ! En pratique, la taille des caches est fortement limitée par leur coût et par la taille des circuits électroniques qu’ils occupent dans les processeurs. On a donc des caches (bureau de l’employé) relativement petits (en général quelques kilooctets ou mégaoctets) qui permettent d’accéder très rapidement à une partie des données, tandis que la mémoire principale (l’armoire) permet d’accéder à beaucoup plus de données (plusieurs gigaoctets) mais beaucoup moins rapidement.
L’intérêt des caches dans les ordinateurs est dû au principe de localité : une donnée utilisée récemment a de fortes chances d’être réutilisée très bientôt. On parle de « chances » car le processeur ne sait pas à l’avance ce que le programme va faire. Il essaie donc d’anticiper en utilisant le principe de localité, qui peut avoir tort, mais a heureusement tout de même souvent raison. Ce principe est en fait également valable pour notre employé : tous les documents qu’on laisse posés sur le bureau vont probablement resservir dans un futur proche. Ceux qui ne resserviront pas sont normalement archivés dans l’armoire (ou jetés à la poubelle). Mais le principe peut avoir tort, car l’employé ne sait pas forcément à l’avance quelle surprise un dossier va lui réserver ou quelle tâche prioritaire son patron pourrait soudainement lui confier.
Caches et affinité entre tâches et données
Le principe de localité introduit une affinité pour les données manipulées actuellement. Comme on les utilise beaucoup en ce moment, on veut privilégier ces données pour y accéder rapidement. D’où l’intérêt de les laisser dans le cache (sur le bureau), qui est plus petit mais plus rapide que la mémoire normale (l’armoire). Heureusement pour le programmeur, il n’a pas besoin de choisir lui-même quelles données mettre dans le cache. Le matériel va essayer de le faire automatiquement… grâce au principe de localité, et ça marche assez bien. Mais le programmeur peut éventuellement essayer d’aider le cache, en faisant en sorte de bien respecter le principe. Par exemple, il vaut mieux parcourir un dossier dans l’ordre, car le cache pourra deviner que vous allez bientôt avoir besoin des pages suivantes. Si par contre, vous le lisez dans le désordre, le cache pourra moins vous aider.
La présence du cache devient cependant intrigante quand l’ordinateur contient plusieurs processeurs (ou cœurs de calcul). Il faut en effet veiller à continuer à exécuter chaque tâche sur le cœur où on l’a commencée. Ainsi, elle bénéficiera d’un accès privilégié aux données précédemment chargées dans le cache. Si on déplace la tâche sur un autre cœur, il faudra recharger toutes ces données dans le cache de ce cœur, comme un employé qui devrait ramasser tous ses dossiers pour changer de bureau, régler le nouveau siège, etc. Ces tâches ont donc en fait une affinité pour un cœur. Et la respecter est un bon moyen d’améliorer la vitesse d’exécution. Sauf si certains cœurs sont inutilisés, auquel cas il faudra tout de même envisager de rompre l’affinité pour mieux répartir la charge de travail sur l’ensemble du système.
Partage de données entre tâches
Un autre problème lié aux machines multiprocesseurs et multicœurs est l’accès simultané à la mémoire par différents cœurs. Tant qu’ils manipulent des dossiers différents, aucun problème. Mais s’ils veulent utiliser le même dossier, ils vont se disputer au moment de le rapporter sur leur bureau respectif. Concrètement, l’un va prendre le dossier et travailler un peu dessus, puis l’autre va lui reprendre temporairement, puis lui rendre… ce qui n’est pas très productif. On parle de ping-pong entre les caches.
Dans le cas présent, le matériel ne peut pas grand chose pour aider le programmeur. Ce dernier doit donc veiller lui-même à éviter cette situation, à moins qu’elle ne soit strictement nécessaire. Concrètement, il ne faut pas placer dans le même dossier deux documents indépendants qui risqueraient d’être utilisés par deux employés différents en même temps. On parle de Faux partage. Si deux documents du même dossier doivent tout de même être utilisés par deux employés en même temps, il faudra alors veiller à ce que ces employés soient proches l’un de l’autre, afin de réduire les coûts d’échange entre eux.
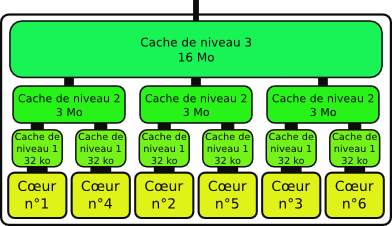
Un processeur contenant six cœurs et 3 niveaux de cache. Chaque cœur dispose de son propre cache (niveau 1, petit mais très rapide). Chacune des trois paires de cœurs dispose de plus d’un cache partagé de niveau 2 (plus gros et moins rapide). Enfin, un gros cache de niveau 3 est partagé entre tous les cœurs (gros, moins rapide, mais toujours plus rapide que la mémoire principale). Plus une donnée est souvent utilisée, plus elle aura de chances d’être disponible dans un cache de niveau bas, et donc d’être accessible rapidement. À l’inverse, une donnée peu utilisée a de fortes chances de rester dans la mémoire principale et donc de ne pas être accessible très rapidement.
Il s’agit donc d’identifier au préalable les tâches ayant des affinités entre elles (en particulier du partage de données) puis de les exécuter sur des cœurs proches. Ce dernier point impose de bien connaître l’ordinateur que l’on utilise, et c’est beaucoup moins facile qu’il n’y paraît. En effet, avec la multiplication des processeurs et des cœurs, les machines deviennent extrêmement compliquées et il n’est pas évident pour un utilisateur de savoir quels cœurs vont être physiquement proches. Par ailleurs, il y a désormais différents niveaux de cache. Un premier niveau souvent spécifique à chaque cœur, puis des niveaux supérieurs partagés entre certains cœurs… mais pas entre tous. On se retrouve donc avec une hiérarchie de caches plus ou moins partagés entre différents cœurs. Plus deux cœurs sont proches, plus ils partagent de cache, et plus les échanges entre eux seront rapides. On a donc besoin d’outils logiciels pour caractériser cette hiérarchie matérielle.
Détecter les affinités entre tâches est un problème encore plus difficile. Certaines techniques tentent de le faire à la compilation (quand le programme est transformé en code machine). Mais cela nécessite que le comportement du programme soit prévisible, et en particulier qu’il ne dépende pas des données qu’on va lui confier. On peut également tenter de détecter les affinités pendant l’exécution, notamment en observant les informations fournies par certains processeurs. Il faut alors être capable d’analyser ces informations rapidement et de modifier dynamiquement le comportement du programme en fonction de la hiérarchie matérielle. Et garder à l’esprit qu’il vaut souvent mieux laisser les tâches là où elles ont commencé à s’exécuter. Bref, un casse-tête pour les programmeurs, et même pour les chercheurs ! Heureusement, tout le mécanisme de cache est géré par le matériel de manière transparente. Nos programmes peuvent donc s’exécuter sans tenir compte de toutes ces contraintes, mais ils iront moins vite…
Machines NUMA et affinités pour la mémoire
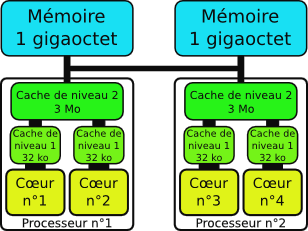
Une machine NUMA (Non-Uniform Memory Access) constituée de deux processeurs bi-cœurs. La mémoire principale est répartie entre ces deux processeurs. L’intégralité de cette mémoire reste toujours accessible, mais les données seront accessibles plus rapidement si elles sont stockées dans un banc mémoire proche du processeur qui effectue l’accès.
L’avènement des machines multicœurs multiprocesseurs a également conduit à une modification de la mémoire principale. Au lieu d’avoir une unique grande armoire centrale pour tous les employés, on répartit plusieurs armoires différentes dans l’entreprise et on essaie de placer les dossiers de chaque employé dans l’armoire la plus proche de lui. Chaque employé peut toujours accéder aux autres armoires, mais elles sont plus loin et l’accès sera donc plus lent. Mais c’est censé être rare, puisque les dossiers doivent a priori être bien rangés. En informatique, on parle d’accès mémoire non uniforme (NUMA), et la plupart des serveurs disponibles de nos jours présentent cette caractéristique.
Les machines NUMA ont introduit un nouveau type d’affinité, entre les tâches et les données en mémoire, indépendamment du cache. Il faut en effet veiller à ce qu’un employé utilise des dossiers proches de lui, ou réciproquement, à ce que ses dossiers soient rangés dans une armoire proche de lui. Là encore, le matériel ne peut pas aider le programmeur. Ce dernier devra lui-même déplacer les tâches et/ou les données pour les regrouper. Là aussi, détecter une rupture d’affinité est difficile, et la migration peut de plus être très lente. Il faut donc veiller à prendre les bonnes décisions au bon moment pour respecter les affinités (et donc accélérer l’exécution) tout en répartissant la charge de calcul sur l’ensemble de la machine, sans déplacer trop souvent les tâches ou les données. Là encore, un casse-tête !
Et bien d’autres affinités
La complexité des ordinateurs ne s’arrête malheureusement pas là. En plus d’avoir plusieurs processeurs, plusieurs cœurs dans chacun d’entre eux, des caches partagés entre certains cœurs, et différents bancs mémoire NUMA, les machines ont également des périphériques qui peuvent être plus proches de certains cœurs que d’autres. Par exemple, la carte graphique qui affiche les images à l’écran ou la carte réseau qui vous connecte à Internet peut voir ses performances varier selon le cœur où s’exécutent les programmes qui les utilisent. Cette affinité pour les périphériques apparaît en particulier dans le calcul haute performance où des machines très complexes sont utilisées pour résoudre de très gros problèmes mathématiques.
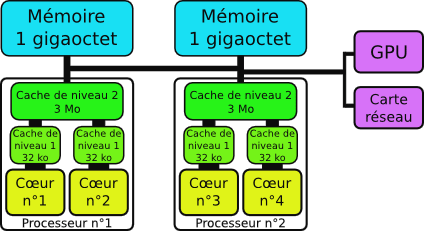
Une machine NUMA où la carte graphique (GPU) et la carte réseau sont plus proches d’un des deux processeurs que de l’autre. L’affichage de données à l’écran ou l’envoi de données sur le réseau sera plus rapide si ces données sont stockées dans un banc mémoire proche du périphérique.
Enfin, on voit apparaître de nos jours des ordinateurs hétérogènes ou hybrides qui contiennent différents types de cœurs de calcul. Certains cœurs sont capables de traiter rapidement des calculs très simples sur de grandes quantités de données (c’est le cas des processeurs graphiques). D’autres sont adaptés au multimédia (traitement audio par exemple, comme le processeur Cell de la PlayStation 3). Enfin, les processeurs classiques sont moins rapides, mais savent résoudre des problèmes plus difficiles. Combiner ces différents types de processeurs permet d’atteindre des puissances de calcul gigantesques, comme en témoignent les 8 millions de milliards d’opérations par seconde que peut traiter le supercalculateur japonais K-computer, le plus puissant du monde aujourd’hui. Mais encore faut-il être capable de reconnaître les besoins en calcul des différentes tâches, c’est-à-dire des affinités entre certains calculs et certains cœurs, pour ensuite les répartir intelligemment sur les différents types de cœurs.
Les affinités de certains calculs pour certains cœurs ou certains périphériques viennent s’ajouter à la longue liste des affinités qu’il faut respecter pour améliorer les performances des machines. Trouver une répartition respectant au mieux les affinités est un problème d’optimisation qu’on est encore loin de savoir résoudre efficacement. Et on est même loin de savoir détecter ces différentes affinités de manière précise. Les chercheurs s’interrogent d’ailleurs sur la nécessité de changer la façon dont on programme les ordinateurs pour pouvoir détecter plus facilement toutes ces affinités. En attendant, nos ordinateurs peuvent fonctionner correctement, mais nos programmes vont certainement moins vite que si nous étions capable de maîtriser toutes ces contraintes !
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
