Évolution des processeurs pour le plus puissant des accélérateurs de particules

La puce Intel Premium Pro (ci-dessus) lancée en 1995. Elle fut à l’origine du passage massif aux PC pour les calculs de la physique des hautes énergies.
Photo © Intel
Ces dernières années, principalement grâce à la loi de Moore, le monde a assisté à une course sans précédent : celle vers des densités de plus en plus grandes pour les circuits intégrés. En 1995, lorsqu’il a été question d’utiliser des PC standard pour les calculs de la physique des hautes énergies, les (micro)processeurs basés sur l’architecture x86, qui étaient largement implantés dans d’autres segments du marché, possédaient déjà entre 3 à 10 millions de transistors. Les microprocesseurs actuels sont constitués de plus de 300 millions de transistors, sur une surface de la taille d’un ongle, et l’on prévoit — suivant la loi de Moore — que cette évolution se poursuivra pendant au moins encore une décennie, c’est-à-dire durant la plus grande partie de la période de fonctionnement du LHC.
Architecture des processeurs
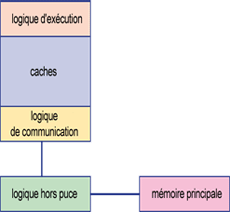
Les trois composants d’une puce de microprocesseur : la logique d’exécution pour le traitement lui-même, le cache pour le stockage temporaire des données et la logique de communication pour les transferts de données vers la logique hors puce puis vers la mémoire principale.
Infographie © CERN
En résumé, un processeur se compose d’une logique d’exécution (comprenant les registres), d’une hiérarchie de cache (généralement 2 à 3 niveaux) et d’autres éléments comme la logique de communication pour l’interaction avec le monde extérieur.
À l’époque des puces 386 et 486 — les générations de processeurs apparus à la fin des années 1980 —, le processeur exécutait un seul train d’instructions dans l’ordre, c’est-à-dire en respectant exactement la structuration du code par les compilateurs. Avec la mise à disposition de transistors supplémentaires, les ingénieurs ont décidé de modifier ce mécanisme d’exécution simple de deux manières. Tout d’abord, ils ont permis aux instructions d’être traitées en parallèle, de la même manière que l’on passe des commandes à plusieurs chefs travaillant en parallèle dans une cuisine. Si des instructions voisines sont indépendantes les unes des autres, il n’y aucune raison d’attendre que la première instruction soit terminée avant de lancer la seconde. Cette stratégie est nommée exécution « superscalaire », et nous a conduits du premier Pentium à deux ports en parallèle, via le Pentium Pro avec trois ports, à la microarchitecture Intel Core 2 actuelle à 6 ports.
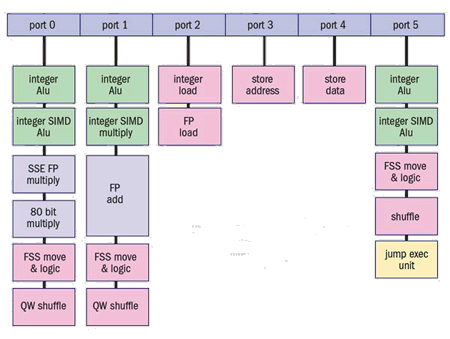
Structure simplifiée de la logique d’exécution dans la microarchitecture Core 2. Différents ports donnent accès à des unités d’exécution spécifiques chacune réservée à une tâche spécifique.
Alu = arithmetic, logical unit (unité arithmétique logique)
FP = floating point (virgule flottante)
SIMD = single instruction multiple data (instruction unique s’appliquant à plusieurs données)
SSE = streaming SIMD extensions (extensions SIMD en continu)
FSS = FP/SIMD/SSE2
QW = quadword (mot quadruple 64 bits)
Jump exec unit (unité d’exécution de branchement)
Infographie © CERN
Outre l’accroissement du nombre de ports, les concepteurs ont également étendu le jeu d’instructions de sorte que les instructions puissent être exécutées sur plusieurs éléments de données en une seule fois. Connu sous le nom de Single Instruction Multiple Data (SIMD), ce concept est utilisé par exemple dans les extensions SIMD x86. En général, ces instructions s’exécutent sur des données de 128 bits, soit quatre nombres de 32 bits (entiers ou à virgule flottante), soit deux nombres de 64 bits (entiers longs ou doubles), mais d’autres combinaisons sont également possibles. Ces instructions peuvent être considérées comme des « instructions vectorielles » et atteignent habituellement leur efficacité maximale pour des programmes de type matriciel ou vectoriel.
Les extensions SIMD, généralement appelées Streaming SIMD Extensions (ou SSE en abrégé), comportent 70 instructions supplémentaires pour les Pentium III (microprocesseurs de la gamme x86). Elles ont été introduites pour la première fois en février 1999 par Intel.
Pour alimenter les ports d’exécution mentionnés précédemment, il est nécessaire d’identifier le plus de parallélisme possible. C’est pourquoi les ingénieurs ont ajouté un mécanisme pour l’exécution out-of-order (OOO). Ce mécanisme permet au processeur de rechercher des instructions indépendantes à l’intérieur d’une « fenêtre d’instructions » (100 instructions en moyenne) et de l’envoyer vers un port libre chaque fois que cela est possible. Au fur et à mesure que les ingénieurs ont incorporé des circuits de plus en plus denses, un grand nombre de transistors sont devenus utilisables sur une seule puce, ce qui a permis, en troisième lieu, l’augmentation de la taille des caches. Alors que ceux inférieurs au mégaoctet ont constitué le standard pendant longtemps, il n’est pas rare désormais de trouver des processeurs avec des caches de plus de 10 Mo : le processeur Xeon MP le plus récent, par exemple, possède un cache de niveau 3 (L3) de 16 Mo et le processeur Itanium 2 un cache de 24 Mo.
Évolution vers la technologie multicœurs


Processeurs Intel Core (en haut) et Core 2 (en bas). Le dernier fournit deux fois plus de fonctionnalités sur la même puce avec presque le même budget de puissance électrique.
Photo © Intel
Pourtant, plusieurs points restaient encore à améliorer pour optimiser l’utilisation des transistors. Les ingénieurs ont alors inventé le « multi-threading » (multi-flot simultané ou « SMT ») au niveau de la puce : c’est un mécanisme par lequel des transistors supplémentaires sont utilisés pour conserver simultanément « l’état » de deux processus légers (ou « threads ») dans la logique d’exécution, tout en partageant les unités d’exécution et les caches. La logique de commande de la puce bascule entre les deux processus légers (aussi appelés fils d’exécution) selon un algorithme prédéterminé, généralement « round-robin » (répartition de charge) ou « switch on long waits » (basculement lors de temps d’attente longs). Dans le cas où l’on ne trouve pas les données dans le cache, on obtient un défaut de cache, qui oblige à lire les instructions ou les données dans la mémoire principale. Cela libère une période de centaines de cycles pouvant être utilisée par l’autre fil d’exécution (tant que celui-ci ne crée pas lui-même un autre défaut de cache). Ce mécanisme n’est en aucun cas limité à deux fils d’exécution, certains fournisseurs fonctionnant déjà avec de plus grands nombres.
On parle de défaut de cache lorsqu’un programme a besoin d’accéder à un bloc (ensemble de données de taille fixe) qui n’est pas dans le cache. Il faut alors les copier de la mémoire principale vers le cache, ce qui est évidemment plus coûteux qu’un accès direct au cache.
Ayant observé le multi-threading ainsi qu’une croissance exponentielle du « budget transistor », il est facile de deviner l’étape suivante. Plutôt que de conserver les unités d’exécution et les caches comme unique ressource, les processeurs multicœurs répliquent tout, conduisant ainsi à une puce possédant plusieurs unités de traitement indépendantes à l’intérieur. Dans le futur, il est facile de voir comment ce mécanisme — en plus de l’accroissement du cache mentionné précédemment — peut être utilisé pour faire face à la croissance des transistors.
Étant donné que la technologie multicœurs oblige à repenser la conception globale du matériel et, plus important encore, le modèle global de programmation logicielle, il n’y a actuellement pas de consensus dans l’industrie sur ce que pourrait être le meilleur compromis. Sun Microsystems, sur son processeur T1 « Niagara », propose actuellement huit cœurs à exécution dans l’ordre, chaque cœur supportant quatre fils d’exécution. Intel livre déjà son premier processeur à quadruple cœur (lancé récemment au CERN), bien que quelques puristes fassent remarquer que ce dernier est construit avec deux composants à double cœur pour l’instant. AMD quant à lui, a annoncé que son processeur à quadruple cœur sur puce unique sera disponible pendant l’été. Intel a récemment fait la démonstration d’une puce microprocesseur de recherche téraflop à 80 cœurs ; il semble donc clair que la mise sur le marché de nombres de cœurs à deux chiffres n’est pas si éloignée que ça.
Comment concilier au mieux matériel et logiciel ?
Dans la communauté des physiciens des particules dans son ensemble, et notamment au sein du CERN openlab, beaucoup de temps a été consacré à étudier les caractéristiques d’exécution du logiciel utilisé en physique des hautes énergies et en particulier pour le grand collisionneur de hadrons. Notre travail a couvert l’étude des compilateurs, l’évaluation des performances, le profilage des codes à l’aide de moniteurs matériels, l’échange d’informations avec les concepteurs de puces, etc. Ce travail nous a permis d’évaluer la pertinence des différentes manières de déployer les transistors pour le logiciel utilisé en physique des hautes énergies.
Dans openlab, nous avons été mandatés au départ pour étudier les avantages et les inconvénients de l’exécution de codes pour la physique des hautes énergies sur le processeur Itanium 64 bits qui depuis ses débuts en 2000 a proposé 6 ports d’exécution, le même nombre que le Core 2 actuel.
La triste vérité pour ces deux familles de processeurs est qu’à ce niveau, nos programmes présentent trop peu de parallélisme. Lorsque nous mesurons le nombre moyen d’instructions par cycle, nous trouvons généralement des valeurs qui tournent autour de 1 (ou moins pour certains programmes). On est loin du parallélisme maximal, particulièrement lorsqu’on prend en compte les instructions SSE. Ceci est dû à la manière séquentielle (« faisons une chose à la fois ») dont est écrit le logiciel pour la physique des hautes énergies.
Une des manières standard d’exprimer le parallélisme au niveau des instructions est d’écrire des boucles de taille petite à moyenne, d’où les compilateurs peuvent extraire des composants parallèles. Bien sûr, dans les programmes de physique des hautes énergies, nous avons des boucles d’événements mais elles sont simplement trop longues et ne sont pas « vues » par les compilateurs qui ne décortiquent généralement que les petits blocs de code d’un trait. Il en résulte que les compilateurs ne voient que des parties de code principalement séquentiel.
Examinons un exemple simple plutôt typique dans lequel nous testons si un point est à l’intérieur ou à l’extérieur d’un bloc (dans la direction des x). Notez que le matériel génère trois micro-opérations de chargement à la volée :
Load point (O); Load origin (O); Subtract; Load a mask; Obtain the absolute value via an and instruction; Load the half-size; Compare; Branch conditionally;
Le matériel parallèle pourrait traiter ces instructions en deux ou trois cycles. Toutefois, la nature séquentielle du code ainsi que le temps d’attente encouru par les chargements depuis le cache et la soustraction et comparaison virgule flottante, entraînent une séquence qui prend environ 10 cycles. En d’autres termes, la séquence du programme n’exploite que 10 à 20 % des ressources d’exécution disponibles.

Représentation schématique de la manière dont une tâche simple (vérifier si un point est à l’intérieur d’un bloc) est exécutée sur un processeur multiport pipeliné, tel que Core 2. Les instructions C sont d’abord traduites en code machine ou assembleur par le compilateur, puis exécutées sur les différents ports. La présentation montre la progression du programme en tenant compte des temps d’attente, comme le temps nécessaire pour charger les données depuis le cache. Notez que les trois micro-opérations de chargement load sont générées à la volée par le matériel. L’exécution s’effectue en parallèle lorsque cela est possible ; toutefois l’exécution out-of-order n’est pas prise en compte. Cela montre comment la plupart de la logique d’exécution est laissée au repos.
Infographie © CERN
Heureusement, d’autres mécanismes de déploiement des transistors marchent mieux pour nous. Les programmes en physique des hautes énergies bénéficient de l’exécution out-of-order (OOO). Cela signifie que même lorsque les compilateurs ont disposé le code séquentiellement, le moteur matériel OOO est capable de réduire le temps d’exécution en trouvant les étapes pouvant être exécutées en parallèle. Cela a pu être constaté, par exemple, lorsque le test mentionné précédemment est étendu au test x puis y puis z. Les compilateurs disposent les tests séquentiellement, mais le moteur OOO chevauche l’exécution et minimise le temps utilisé pour calculer le test pour les deux directions supplémentaires de plus de 50 % par rapport au temps initial. Ceci est vraiment une bonne nouvelle si nous devions un jour faire face à plus de trois dimensions, mais nous constatons déjà actuellement un gain très net.
En ce qui concerne les caches, les programmes de physique des hautes énergies ne semblent pas avoir besoin de tailles importantes. Nos programmes présentent une bonne localité de cache avec des défauts de cache limités à environ 1 % de tous les chargements. Ceci n’est quand même pas sans conséquences car, comme mentionné précédemment, le temps d’attente vers la mémoire principale se monte à quelques centaines de cycles. Les processeurs modernes permettent aux données d’être préchargées via une fonction matérielle ou des instructions contrôlées par le logiciel, mais nous n’avons pas vu de preuve indiquant que les chemins d’exécution pour le logiciel en physique des hautes énergies étaient suffisamment réguliers pour en profiter de manière importante.
L’utilisation des techniques de multiflot simultané (SMT) n’a pas fait l’objet d’une étude sérieuse dans notre communauté. Ceci est probablement dû au fait que les tâches que nous traitons sont gourmandes en temps de calcul, avec peu de défauts de cache, et que le gain potentiel est donc limité. Il peut même être limité à des pourcentages à un chiffre en termes de débit d’exécution. D’autre part, plus de fils d’exécution doivent être exécutées simultanément, ce qui augmente les besoins en mémoire et par conséquent le coût de l’ordinateur. Le gain en termes de performance par rapport au coût n’est donc pas très net.
Toutefois, avec les processeurs multicœurs, nous arrivons à un mécanisme en adéquation avec le traitement des données en physique des hautes énergies. Chaque événement physique étant indépendant des autres, les tâches que nous avons à effectuer sont de fait parallèles, ce qui nous permet de lancer autant de processus (ou tâches) qu’il y a de cœurs sur une puce. Cependant, cela nécessite une augmentation de la taille de la mémoire pour prendre en charge les processus supplémentaires (ce qui rend les ordinateurs plus onéreux). Tant que le trafic mémoire ne devient pas un goulot d’étranglement, nous constatons une augmentation pratiquement linéaire de la vitesse de traitement d’un tel système. Une analyse effectuée avec ROOT/PROOF l’a démontré de manière élégante lors du lancement de la puce à quadruple cœur au CERN.
ROOT est une boîte à outils logicielle orientée objet dédiée à l’analyse de données et à leur représentation graphique. Développé au CERN pour la communauté des physiciens des hautes énergies, ROOT est aussi utilisé dans d’autres domaines scientifiques où d’importantes masses de données doivent être traitées.
PROOF (Parallel ROOT Facility) en est l’extension permettant l’analyse en parallèle d’ensembles volumineux de fichiers ROOT.
Si la taille de la mémoire et le trafic bus correspondant deviennent des goulots d’étranglement, nous pouvons facilement atténuer le problème en exploitant nos boucles d’événements. Le calcul lié à chaque événement peut être réparti sous forme de thread dans un modèle de mémoire partagée où un seul processus occupe tous les cœurs à l’intérieur d’une puce. Ceci devrait permettre un passage à l’échelle aisé avec l’augmentation du nombre de cœurs et nous permettre de profiter de la loi de Moore pendant encore de nombreuses années.
Optimisation du compilateur
Presque tous les gros logiciels spécialisés sont produits par notre communauté. Qu’il s’agisse de générateurs d’événements, de logiciels de simulation, de structures de reconstruction ou de boîtes à outils d’analyse, nous remarquons qu’ils ont tous une chose en commun, ils sont tous au format source.
Le moyen le plus évident pour optimiser ce logiciel est d’utiliser un outil de profilage qui indique où le temps d’exécution est dépensé. Lorsqu’un point chaud (hot spot) est découvert, le code source est modifié par le développeur pour voir si les performances s’améliorent. Dans de rares cas, la conception elle-même du programme doit être revue pour corriger de graves problèmes de performances.
Dans openlab, nous avons aussi adopté une autre approche en travaillant avec des développeurs de compilateur pour améliorer le back-end du compilateur, la partie qui génère le code binaire à exécuter. Cette approche possède un grand potentiel, car les améliorations apportées au générateur de code peuvent conduire à de meilleures performances pour toute une gamme d’applications, toutes celles qui exploitent une caractéristique de langage donnée, par exemple.
Cette approche présente cependant deux défis importants à relever. Le premier est que vous devez maîtriser cet « ancien » langage « parlé » par le processeur, appelé code assembleur ou code machine.
Le deuxième défi est lié à l’exécution OOO, qui rend difficile l’interprétation des vitesses d’exécution : même si vous pensez que le compilateur fait quelque chose de superflu ou d’inefficace, vous ne pouvez pas supposer que l’élimination ou la simplification entraînera une augmentation correspondante de la vitesse.
Le traitement détaillé de ce domaine complexe sort du cadre de cet article mais permettez-moi d’énumérer quelques-uns des domaines où les programmeurs devraient essayer fortement d’aider les compilateurs en prêtant attention aux éléments suivants :
- Désambiguïsation en mémoire des pointeurs de données ou des références.
Pour les êtres humains, il est souvent clair que les pointeurs tels que *in et *out renvoient à des zones mémoire complètement différentes. Pour un compilateur avec une visibilité limitée du code, cela peut ne pas être évident et le force à générer des séquences de code qui sont trop « conservatrices ». - Eléments de boucles optimisables.
Les compilateurs et les processeurs « de grande taille » sont vraiment efficaces lorsque des éléments de boucle sont présents dans toutes les parties importantes d’un programme (Voir par exemple le Mersenne Twister).
Ce code, appelé Mersenne Twister, génère une séquence de nombres pseudo-aléatoires. (Exemple tiré de CLHEP, basé sur le générateur de M. Matsumoto et T. Nishimura, Mersenne Twister : Un générateur de nombres pseudo-aléatoires uniformément distribué sur 623 dimensions, avec pour période le nombre premier de Mersenne 219937-1, uniforme sur l’intervalle (0,1).)
Le code en bleu représente une boucle tandis que le code en rouge doit être exécuté de manière séquentielle. Les deux séquences sont parcourues environ une fois pour chaque nombre généré. Toutefois, le temps d’exécution d’une boucle n’est qu’une fraction de la partie séquentielle.

Infographie © CERN
- Minimisation des instructions if et switch.
Les programmes complexes avec des structures if-else imbriquées peuvent facilement limiter la capacité des compilateurs à créer un code efficace. Si ce type de structure ne peut pas être simplifié, il faudrait au moins s’assurer que le code le plus fréquemment utilisé est en haut et non pas en bas de la structure. - Fonctions mathématiques.
Les appels inutiles devraient toujours être évités, car ces fonctions sont en général très coûteuses à calculer étant donné que les compilateurs tendent à les incorporer en tant que train d’exécution unique.
Pour améliorer le profilage de l’exécution du logiciel, CERN openlab travaille activement avec l’auteur d’un puissant logiciel appelé perfmon2. Ce logiciel deviendra bientôt l’interface universelle dans le noyau Linux pour surveiller les performances de tous les processeurs.
À l’ère du Grand collisionneur de hadrons
Depuis plus de dix ans, la physique des hautes énergies vogue sur la vague des technologies PC. Cela a permis de mettre à la disposition de notre communauté de gigantesques ressources de calcul. En janvier 2007, le recensement des ressources de la grille de calcul pour le LHC a montré que plus de 30 000 processeurs sont interconnectés et que ce nombre continuera à croître.
Certains points doivent cependant être notés. L’un d’entre eux est que nous exploitons le matériel d’exécution à 10-20 %, mais étant donné le rapport du coût entre les développeurs « chers » et le matériel « bon marché », je ne m’attends pas à ce que quelqu’un tienne à revoir nos structures de programmes de manière fondamentale.
Un autre problème est la limite en mégawatts pour nos centres informatiques. Au CERN, nous pensons saturer la capacité de refroidissement de notre centre de calcul dans quelques années. Il sera alors impossible d’ajouter plus d’ordinateurs pour faire face à l’augmentation prévue de la demande et la seule solution peut être d’optimiser davantage pour augmenter le rendement du matériel déjà installé.
D’un point de vue positif, les systèmes multicœurs qui augmentent le nombre de cœurs d’exécution disponibles de génération en génération (à budget de puissance constant, avec un rendement énergétique accru) joueront certainement en notre faveur.
Les fournisseurs, comme Intel, nous ont dit que nous sommes considérés comme des clients « idéaux » pour ces systèmes. Souhaitons simplement que les Google et les Yahoo de ce monde aideront aussi à créer une forte demande. Ceci est absolument vital, car il est improbable que les utilisateurs de PC usuels à domicile seront aussi enthousiastes en ce qui concerne les systèmes multicœurs, dont on ne perçoit les avantages que s’ils exécutent plusieurs processus en parallèle, alors que dans le cas d’un processus unique, on ne constate que peu d’accélération, voire aucune.
Enfin, il est important de se rappeler ce qui s’est passé à l’époque du Grand collisionneur électrons-positons (LEP), de 1989 à 2000. Nous avons démarré avec de gros ordinateurs et des superordinateurs, transitant par des stations de travail RISC pour terminer avec des PC x86. Somme toute, cela nous a fourni plus de mille fois la puissance de calcul que celle avec laquelle nous avons commencé. J’espère sincèrement que l’industrie informatique nous aidera à faire les mêmes prouesses pendant l’ère du LHC.
Une première version anglaise de cet article est parue dans le numéro d’avril 2007 du CERN Courier, traduite ici avec leur aimable autorisation (voir l’article original).
Newsletter
Le responsable de ce traitement est Inria. En saisissant votre adresse mail, vous consentez à recevoir chaque mois une sélection d'articles et à ce que vos données soient collectées et stockées comme décrit dans notre politique de confidentialité
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
