
Idée reçue : Les algorithmes prennent-ils des décisions ?
Penser que les algorithmes décident de tout se rapproche de l’assertion bien connue : « c’est la faute de l’ordinateur ! ». Et pourtant, les ordinateurs ne s’organisent pas dans l’intention de nuire ou de tromper. Il faut se méfier de la tentation d’une trop grande personnification à propos de ce qui se rapporte aux ordinateurs et aux algorithmes. Il est ainsi évident que les algorithmes ne décident pas de tout. Au-delà de cette sentence définitive, nous pouvons nous interroger sur la relation entre algorithme et décision.
Les algorithmes décident
Avant de se prononcer, il faut préciser ce qu’est un algorithme et ce qu’il fait. Si nous répondons déjà que les algorithmes décident, il faut définir ce qu’ils sont et ce qu’ils font. Il est aujourd’hui commun de définir un algorithme comme une suite d’instructions permettant d’obtenir un résultat. Cette définition est suffisamment floue pour signifier beaucoup de choses en même temps. Dans son édito d’avril 2017 de la revue de la SIF (PDF), Jean-Marc Petit part d’une définition constructive de ce qu’est un algorithme « un algorithme, c’est la preuve d’un théorème » afin de mettre en avant le principe du calcul, puis ouvre sur d’autres problématiques. Un algorithme est cette description mécanique, qui est en même temps une preuve au sens mathématique et l’élément de base de l’informatique. L’algorithme fait ainsi le lien avec les mathématiques (et l’idée de l’existence d’une preuve derrière ces calculs) sans définir l’informatique comme une branche particulière des mathématiques.
C’est à partir des algorithmes que nous pouvons penser l’ensemble de la discipline informatique. Une fois qu’un algorithme a été conçu, nous pouvons l’implémenter pour le mettre en œuvre sur des données, et au final obtenir un résultat. Le code ou le programme résultant permet ainsi de passer de la description abstraite qu’est l’algorithme à l’obtention réelle d’un résultat qu’est l’objectif de l’algorithme. Ces programmes doivent encore être rassemblés dans des logiciels qui organisent l’ensemble des calculs à opérer à partir de toutes les briques de base pour obtenir ce fameux résultat que nous promettons depuis au moins trois phrases. Et ce résultat revêt des natures différentes, que ce soit la preuve d’un théorème, un résultat numérique (permettant de prédire l’évolution climatique par exemple) ou la mise en place d’une interaction homme-machine. Tout cela concerne l’informatique et a en commun le principe algorithmique. Dans la suite, nous continuerons à parler d’algorithmes bien qu’il s’agisse d’objets plus complexes.
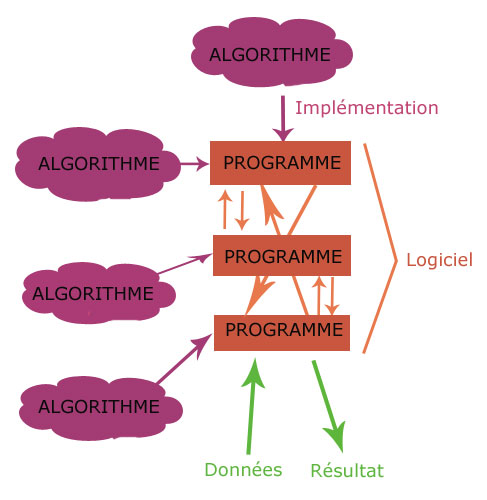
Figure 1 : Vue schématique de la relation algorithme/programme/logiciel entre les données et le résultat. Dessin © Maxime Amblard.
Partons de l’acceptation que les algorithmes prennent des décisions. Il est souvent vrai qu’ils contiennent des parties où des choix sont faits. Si on les regarde seulement de manière extérieure, ces choix peuvent apparaître comme pris par l’algorithme lui-même. Et bien souvent le non spécialiste n’a ni l’envie ni la compétence pour plonger dans le code qui rend concret l’algorithme pour comprendre comment le choix s’opère. En fait, même les spécialistes n’ont pas envie de plonger dans un code qu’ils n’ont pas produit. L’algorithme aurait donc décidé.
Cette idée est renforcée par le fait que les algorithmes modernes travaillent sur des tâches qu’un humain seul ne pourrait pas accomplir. Il ne faudrait pas se méprendre, les logiciels ne dépassent pas les humains. En fait, leur capacité conceptuelle (les algorithmes) reste très inférieure à celle des humains, mais leur aptitude à la tâche est bien plus grande. Ils sont donc capables de travailler plus longtemps et en appliquant exactement les consignes (contrairement aux humains qui finissent par se déconcentrer ou par répondre à d’autres contraintes et sollicitations sociales). C’est ce qui explique qu’un théorème comme le théorème des quatre couleurs ait été prouvé par un ordinateur et non par un humain.
Les algorithmes au sens informatique sont apparus avec l’invention des premières machines dotées d’automatismes, notamment dans les usines. Les interactions de ces automates avec le monde physique impliquent qu’ils aient la capacité de s’adapter aux situations et donc de prendre explicitement des décisions. Plus encore, on parle depuis longtemps d’aide à la décision en recherche opérationnelle. Aujourd’hui, les concepteurs ne demandent plus seulement aux algorithmes d’interagir avec des objets physiques mais aussi de travailler à partir de grandes masses de données. Ils sont capables de trouver des liens entre des affaires pénales à partir des différents recueils de lois et de la jurisprudence. Sans se substituer aux avocats ou aux juges, ils proposent des résultats étonnants sur des données complexes et abstraites.
Les algorithmes ne décident pas seuls
Pourtant, si cette première exploration sur la capacité de décision des algorithmes est valide, la question est plus complexe. La capacité de décision peut être conférée à celui qui contrôle l’algorithme, sans qu’on sache véritablement de qui il s’agit. Il existe de nombreux exemples dans la littérature de fiction dans lesquels les scientifiques ayant construit un monstre se retrouvent dépassés par ce dernier, comme Frankenstein. On pourrait alors supposer que les logiciels avec leurs codes, leurs algorithmes et leurs données pourraient eux aussi dépasser leurs créateurs et renverser cette notion de contrôle. Par manque de clarté, on peut conjecturer que de la complexité naîtrait l’intelligence des ordinateurs, et que l’artificiel prendrait le pas sur l’humain. La faute du choix incomberait donc aux algorithmes qui décideraient. C’est un raccourci que l’on retrouve souvent.
Remontons la piste. Si ce n’est pas l’algorithme qui décide, c’est peut-être la personne qui l’invente. C’est probablement plus vrai. Au moment de décider du fonctionnement de l’algorithme, on fixe les choix qu’il fera. Par exemple, le calcul est souvent réalisé avec des approximations et les résultats sont interprétés à partir de ces approximations introduisant de fait des biais. La décision reviendrait à l’humain qui crée l’algorithme. Il y a là une relation importante entre l’algorithme et son créateur ou sa créatrice. Pierre Levy dans son livre « La programmation considérée comme un des Beaux-Arts » (éditions La Découverte, 1992) propose de considérer qu’il y a une co-opération entre l’intelligence, naturelle, de l’homme et celle, artificielle, de la machine. Ainsi des co-décisions s’opèrent : la décision est effectivement réalisée par l’algorithme, mais la motivation de la décision revient à l’humain qui définit l’algorithme. Le dessein derrière le calcul doit ainsi être attribué à la tête pensante et non à l’algorithme.
Les algorithmes utilisés dans les usines opèrent une transformation du contexte par leur capacité de production, changeant la nature de la relation au travail. Leur présence participe à une vision politique de la société. Leur déléguer explicitement le processus de décision a dès lors des conséquences. Par exemple, la gestion de marchés boursiers par le trading virtuel réagissant à la micro-seconde fait prendre le risque de déclencher des krachs boursiers sur le prix des matières premières, ce qui peut conduire à des situations dramatiques dans certains pays. Une dernière illustration est le micro-krach boursier qui a pu être « maîtrisé » en 2015 lorsque des tweets ont relayé la prise d’otage du président américain à la Maison Blanche. En quelques minutes, les algorithmes ont décidé de liquider certains titres qui ont été échangés dans des volumes faramineux. Les autorités de marché ont été contraintes de suspendre les cours le temps de vérifier l’exactitude de l’information et d’annuler les échanges de titres sur un laps de temps donné. Comme cela était faux, tout est rentré dans l’ordre. Dans cet exemple, les algorithmes prennent des décisions, mais la motivation qui les pousse à les prendre ne peut pas leur incomber à eux seuls.
Nous ne sommes probablement pas en mesure de définir explicitement la part de chaque protagoniste dans la chaîne de co-décision partant du créateur ou de la créatrice de l’algorithme, et passant par les programmeurs et programmeuses, les propriétaires des logiciels produits à la fin, les utilisateurs et utilisatrices finaux du logiciel, celles et ceux qui créent des données, ainsi que celles et ceux qui emploient ce petit monde. Chaque cas singulier montre que cette chaîne est complexe.
Tous ces éléments n’ont rien de nouveau et s’inscrivent dans une évolution assez ancienne de la discipline informatique. Des transformations profondes semblent à l’œuvre pour que la notion d’algorithme ait une place aussi importante aujourd’hui. Si l’idée de la co-décision n’est pas nouvelle, elle est très présente dans l’organisation de nos vies. De plus, elle n’est pas réservée à des situations très techniques comme l’organisation d’une entreprise, mais se rapproche au plus près de notre quotidien et de notre intimité. Le mouvement d’ubérisation de notre société en est une illustration. Cette évolution peut masquer les moments de décision, rendant la frontière de la co-décision assez floue, d’où la nécessité d’expliquer largement ce qui se passe dans la science informatique pour rappeler que les algorithmes ne peuvent que co-décider.
Apprentissage et données
Pour compliquer les choses, les nombreux résultats récents obtenus à partir des réseaux de neurones ou des apprentissages automatiques, tel que le moteur de traduction de Google, soulèvent un nouveau type de questions. Dans ce cas, les moments de choix à l’intérieur de l’algorithme ne sont pas explicités dans l’algorithme, mais sont le résultat de l’apprentissage. Il n’y a pas de décision prise par un humain, et la décision est directement motivée par les données utilisées. Ainsi, elle se fait plus immatérielle et il est difficile de parler de coopération. La responsabilité se retrouve diluée. Si cette perspective procure un sentiment de plus grande objectivité pour l’algorithme qui serait débarrassé de la subjectivité de son co-décideur humain, le dessein ne disparaît par pour autant. Il a déjà été démontré que ces algorithmes sont autant biaisés que ne l’est la société et leur apprentissage relaie certains préjugés qui apparaissent dans les jeux de données. Par contre, la responsabilité d’utiliser telles ou telles données qui participent à la décision finale relève d’un arbitrage.
Une longue chaîne de responsabilité
Ainsi, il est difficile de remonter la chaîne de décision, parce que ce n’est probablement pas le créateur ou la créatrice des algorithmes qui participe de la co-décision finale avec eux. Il y a bien une chaîne de multiples protagonistes intervenant dans le processus de décision. C’est encore plus difficile si l’on considère des situations complexes mobilisant un grand nombre d’acteurs, comme pour le cas des robots tueurs de l’armée ou celui des juges numériques.
Ces exemples posent d’ailleurs un problème pour définir les relations contractuelles et juridiques entre tous les maillons de la chaîne de co-décision. Pourtant, le surgissement dans notre quotidien des logiciels pose explicitement la question de leur statut. Pour ne prendre qu’un exemple extrême, les décès dus à des objets contrôlés par des algorithmes illustrent la nécessité de répondre à la question de la responsabilité morale et à celle du statut juridique, comme l’explique Alexei Grinbaum dans son article Binaire/TCF.
Discuter de cette responsabilité inhérente à l’utilisation d’algorithmes pointe les problèmes éthiques sous-jacents à l’informatique. Il ne faut pas négliger les questions déontologiques soulevées par la production et l’utilisation des algorithmes. En effet, si, au moment de son développement, on peut considérer qu’un algorithme est défini dans une perspective particulière, pour un dessein choisi, il faut envisager qu’il est possible de l’en dévoyer. Celles et ceux qui produisent et/ou utilisent ces algorithmes doivent situer leur production dans une perspective plus large que les usages directs prévus. Un exemple se trouve dans les algorithmes d’identification d’e-réputation ou de leaders d’opinion sur les réseaux sociaux. S’il s’agit de mesurer l’impact de ces stars des réseaux sociaux, les conséquences sont assez faibles pour que la responsabilité ne soit pas lourdement engagée. Mais s’il s’agit de déterminer qui sont les contestataires d’un régime dictatorial, on comprend bien que la responsabilité de la co-décision n’est pas de même nature.
Pour conclure, la question de la décision ne peut pas s’appréhender de manière directe pour ce qui concerne les algorithmes. Il apparaît qu’ils sont engagés dans un processus plus global fait de coopération. Nous avons montré que la co-décision se dilue dans une chaîne complexe, qui pose des questions éthiques et juridiques dépassant le cadre de cet article. Dans tous les cas, il ne faut pas céder à la tentation de reléguer la responsabilité de l’ensemble du processus à un seul terme comme algorithme, qui ne peut se retrouver seul accusé en cas de problèmes.
NDR : L’auteur souhaite remercier les relectrices pour leurs remarques précises et précieuses qui ont profondément amélioré et transformé le texte.
 Cette œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution – Pas d’Utilisation Commerciale – Pas de Modification 4.0 International.
Cette œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution – Pas d’Utilisation Commerciale – Pas de Modification 4.0 International.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Maxime Amblard
Professeur des universités à l'Université de Lorraine, chercheur en traitement automatique des langues au Loria, dans l'équipe Inria Sémagramme.