Les réseaux grillent les limitations
Il ne fait plus guère de doute que la puissance informatique est une arme économique. En aéronautique, les maquettes sont délaissées au profit des simulations numériques. En biologie, l’essentiel du décryptage du génome humain a reposé sur les épaules… d’ordinateurs. Même l’action de l’Homme face au réchauffement climatique, qui concerne l’avenir de la planète, dépend des cogitations numériques de machines, en particulier de l’une des plus puissantes d’entre elles, le supercalculateur japonais Earth Simulator.
Cependant, même le plus puissant des supercalculateurs ne suffit plus pour satisfaire aux besoins sans cesse croissants de la simulation numérique. Les centres de calcul se mettent donc en réseau pour construire des grilles informatiques, incarnations de l’adage « L’union fait la force ». L’idée des grilles est de fédérer des ressources informatiques réparties à l’échelle d’un laboratoire, d’une entreprise, d’un centre de calcul, d’un organisme de recherche, etc., et d’additionner leur puissance pour bâtir virtuellement un supercalculateur. Le mot « grille » fait référence à l’anglais « power grid », qui désigne le réseau électrique. En effet, les hérauts des grilles informatiques imaginent idéalement les grilles aussi simples d’utilisation que le réseau électrique : il suffirait de se brancher à la grille pour disposer d’une puissance de calcul infinie et bon marché.
Attention, cela ne signifie pas que les grilles informatiques seront amenées à remplacer les supercalculateurs. Il s’agit ici d’une offre complémentaire. D’ailleurs, certaines grilles s’appuient sur les supercalculateurs des centres de calcul ; c’est le cas par exemple du consortium européen DEISA (Distributed European Infrastructure for Supercomputing Applications).
1. Partager la puissance
Les grilles informatiques revêtent plusieurs visages. L’un d’entre eux est le « desktop grid ». Il consiste à mettre la puissance inutilisée des machines des particuliers ou des salariés d’une entreprise au service d’un programme de recherche. Ainsi, un particulier désirant partager sa puissance installe sur sa machine un logiciel dédié, qui s’exécute en fond de tâche, tel un économiseur d’écran, et envoie les résultats obtenus au serveur de l’application.
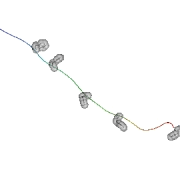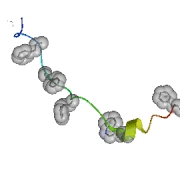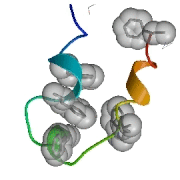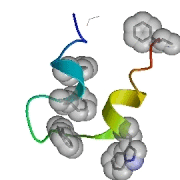
L’un des premiers résultats obtenus par folding@home : simulation d’un repliement du domaine carboxy-terminal (headpiece) de la villine
(une protéine parmi les plus petites et les plus rapides à se replier).
© Vijay Pande et Stanford University
Le projet pionnier, SETI@home, dont l’objectif est de sonder les signaux électromagnétiques venus de l’espace à la recherche d’intelligence, réunit aujourd’hui 400 000 participants pour une puissante totale de 60 téraflops (60 mille milliards d’opération élémentaires par seconde), soit plus que Earth Simulator (35 téraflops). Devant ce succès, divers projets lui ont emboîté le pas, dans les domaines de la prévision du climat (climat-prediction.com), la simulation de repliement de protéines (folding@home), ou encore la quête d’étoiles à neutrons (Einstein@home). Les entrepreneurs eux aussi se rendent compte qu’ils croulent littéralement sous la ressource de calcul inusitée. Une étude menée par Dataquest a démontré que la majorité des sociétés n’emploient que 5 à 20 % des capacités de leurs ordinateurs pendant les heures ouvrables et pratiquement zéro le reste du temps. Monsanto, Alcatel et Aventis font partie des entreprises ayant déployé sur leur réseau interne une grille pour leurs projets de recherche et développement.
Le développement d’applications fonctionnant selon le principe du desktop grid nécessite la mise au point de techniques logicielles spécifiques, en vue de préserver l’intégrité de la machine hôte. Par définition, le programme que le particulier ou le salarié accepte sur son ordinateur est apte à y déclencher des actions. C’est un fichier exécutable qui, le cas échéant, par malveillance ou simplement à cause d’un bug, peut corrompre la machine à la manière d’un virus. Pour surmonter ce problème, une des stratégies est comparable à celle des artificiers démineurs, qui enferment les colis suspects à l’intérieur d’un récipient ultra résistant pour prévenir l’explosion. Elle consiste à engendrer dans l’ordinateur du participant une « machine virtuelle », sorte de sous-système d’exploitation qui confinera le logiciel : si l’application se révèle agressive, c’est ce sous-système d’exploitation qui en pâtira et non le vrai système d’exploitation qui gère l’ordinateur. Les chercheurs de l’équipe Grand-Large (de l’INRIA, du CNRS, de l’université de Paris Sud et de l’université des Sciences et Technologies de Lille) se sont penchés sur ces problèmes, dans le cadre du projet XtremWeb.
2. Les grilles décentralisées
Dans le cas le plus général, une grille informatique n’est pas architecturée autour d’un serveur unique qui centralise les résultats, comme dans le cas du desktop grid, mais distribuée sur plusieurs serveurs. La plus importante grille de production (c’est-à-dire non expérimentale) de ce type est EGEE, qui mutualise des ressources de 70 organismes européens, répartis dans 27 pays. En France, le CNRS, le CEA ou encore la CGG (Compagnie Générale de Géophysique) y participent. Dans ce mode d’architecture, la requête de calculs est transparente pour l’utilisateur connecté à la grille. Imaginons qu’il s’agisse d’un biologiste cherchant à calculer une conformation de molécule. Il aura au préalable copié son application sur chaque serveur du réseau. Et lorsqu’il désirera lancer son calcul de conformation depuis son ordinateur, c’est un « intergiciel » qui décidera sur quel serveur exécuter le calcul. Les intergiciels sont les intermédiaires entre des applications de type différent, par exemple un programme de simulation numérique et un serveur de calcul, ou encore un serveur de calcul et une base de données.
Visualisation d’ondes gravitationnelles, générée en utilisant Globus.
Visualisation créée par Werner Benger, équipe de visualisation de NCSA/AEI Potsdam/Wash U/ZIB.
Une application portée sur une grille informatique nécessite pour fonctionner une palette d’intergiciels, qui ne sont pas situés uniquement sur la machine de l’utilisateur, mais répartis sur tout le réseau. Ces intergiciels offrent un ensemble de services. Ce sont eux qui gèrent les communications entre machines, afin que la tâche demandée par le chercheur soit effectuée sur un serveur de la grille. Le package d’intergiciels de grille le plus courant est Globus, développé aux États-Unis, notamment par le laboratoire national Argonne et l’université de Californie Sud.
Un service tient un rôle prédominant parmi les intergiciels de grille : l’ordonnanceur. Il est chargé de distribuer les calculs. Il détermine, sur la base d’informations remontant de tous les serveurs, le meilleur site pour exécuter le calcul, c’est-à-dire celui qui répondra au mieux à la sollicitation de l’utilisateur, en termes de vitesse d’exécution, de mémoire, de capacité disque, de type de processeur, etc. Ces informations sont essentiellement le taux d’occupation des machines, auquel s’ajoutent, selon les intergiciels, d’autres critères tels que le temps de calcul ou le temps de rapatriement de fichiers depuis une base de données. Dans leurs versions les plus simples, par exemple l’américain NetSolve et le japonais Ninf, les ordonnanceurs prennent leur décision en interrogeant simultanément tous les serveurs sur leur taux d’occupation.

Modèle numérique de terrain, calculé avec DIET.
Image : équipe GRAAL.
C’est une faiblesse : si le parc de serveurs se chiffre en milliers de machines, l’ordonnanceur ne sait plus où donner de la tête et peut s’en trouver bloqué.
Dans des versions plus sophistiquées, tel le français DIET, conçu par les chercheurs de l’équipe GRAAL (commune à l’INRIA, au CNRS et à l’ENS-Lyon), le choix du serveur s’effectue à la manière d’une coupe sportive, avec une finale, des demi-finales, des quarts de finale… : une escadre d’agents logiciels veille sur des dizaines de serveurs et élimine du choix les serveurs non adaptés, une autre escadre, plus réduite, choisit ensuite parmi cette première sélection de machines, et ainsi de suite jusqu’au choix final du serveur élu. Ce mode pyramidal de décision représente l’avantage de s’adapter à toute taille de grille.
Un autre outil pour l’ordonnancement des calculs, nommé Kaapi, a été développé par les chercheurs de l’équipe MOAIS du laboratoire ID de Grenoble. Son originalité est d’intégrer des algorithmes efficaces pour l’ordonnancement des tâches sur les différents processeurs, tout en tenant compte de la volatilité des machines. Kaapi a été utilisé avec succès avec l’instrument Grid’ 5000 sur une application résolvant le problème de l’affectation quadratique. Il s’agit d’un problème qui a de très nombreuses applications pratiques tant en informatique qu’en productique, électronique ou architecture, mais se montre extrêmement difficile à résoudre.
3. Les grilles pour stocker des données
Le besoin en puissance de calcul n’est pas la seule motivation des recherches sur les grilles informatiques. Le monde universitaire doit en effet faire face à un autre besoin, tout aussi irrépressible : le stockage de volumineuses quantités de données. Deux exemples. Les chercheurs en sciences de la Terre qui surveillent le niveau de l’ozone atmosphérique via satellite rapatrient chaque jour pour cette seule tâche environ 100 gigaoctets de données (soit environ 150 CD-ROM). Pire, le futur accélérateur de particules du CERN, le Large Hadron Collider (LHC), quant à lui, sera un monstre de champs électromagnétiques, mais aussi de données : durant ses quatre premières années d’exploitation, on estime qu’il engendrera pour plus de 15 petaoctets de fichiers, l’équivalent d’environ 20 millions de CD-ROM !
Pour permettre l’accès de telles masses de données aux chercheurs du monde entier, il est impensable de les stocker sur un serveur unique. Le serveur sera noyé sous les requêtes et rapidement congestionné, la gestion des pannes de machine sera problématique. Il existe bien aujourd’hui des embryons de bases de données distribuées sur un réseau, mais celles-ci ne gèrent au maximum que quelques dizaines de serveurs. L’unique solution est de distribuer la masse d’information sur les sites d’un réseau grâce aux techniques pair à pair (P2P), les mêmes qui sont mises en pratique sur Internet pour l’échange de fichiers musicaux et vidéo. Les réseaux P2P cumulent plusieurs avantages : ils permettent en principe de relier autant de machines que l’on souhaite ; ils autorisent le traitement simultané de plusieurs requêtes, ce qui a priori est un gage de vitesse ; et enfin, moyennant l’installation de doublons des fichiers parmi les serveurs, ils se moquent des pannes – si un serveur s’écroule, il reste encore son jumeau.
Malgré ces avantages, les réseaux P2P tels qu’on les connaît aujourd’hui sont loin des exigences des bases de données. Ils n’autorisent des recherches que via le nom des fichiers, alors que les bases de données laissent l’utilisateur interroger la base sur son contenu même (la taille du patient, son sexe… pour le cas d’une base médicale). Par ailleurs, aucun réseau P2P classique ne garantit l’exhaustivité des réponses, contrairement aux bases de données qui ont une vision omnisciente de leur catalogue. Et les réseaux P2P adaptés aux grilles doivent réaliser de la véritable distribution de données : il faut que chaque machine puisse, à tout moment, non seulement aller chercher une information stockée dans le réseau, mais aussi la modifier.
Trois topologies de réseau P2P sont en compétition pour résoudre le plus efficacement ces problèmes : l’architecture non structurée, où chaque poste communique avec ses voisins, qui communiquent à leur tour avec leurs voisins par inondation du réseau, le réseau structuré à l’aide d’une « table de hachage distribuée » (qui assigne les fichiers aux différents sites du réseau), où chaque poste connaît l’emplacement d’un nombre restreint d’informations sur le réseau ; et la topologie intermédiaire, où les communications entre postes s’effectuent à travers des nœuds pivots qui jouent un rôle dominant dans les échanges. Pour ne pas présager de la réussite future de l’un des modes, les logiciels P2P pour grilles informatiques s’efforcent d’être compatibles avec les trois.
La solution qui utilise une table de hachage distribuée consiste à découper le fichier à stocker en petits blocs (quelques kilooctets), puis à attribuer à chaque bloc une clé d’identification unique qui permettra de vérifier l’authenticité du contenu. Ensuite, grâce à une table de hachage distribuée, chaque bloc est répliqué et les copies sont assignées à plusieurs sites répartis le plus uniformément possible. Pour récupérer le fichier, la machine n’a plus qu’à récupérer une copie de chaque bloc et à les assembler.
Une telle organisation pose néanmoins un problème majeur : lorsque plusieurs machines ont un droit d’écriture sur les données, deux versions différentes du même bloc peuvent se trouver simultanément sur le réseau. Plusieurs écoles coexistent pour pallier cette erreur : verrouiller toutes les copies existantes avant d’en modifier une, ou bien utiliser un protocole de diffusion de la copie qui garantit que les copies reçoivent les modifications dans le même ordre et qu’ainsi, à tout moment, elles sont similaires, ou encore réconcilier les versions divergentes par la connaissance de la sémantique des données, comme dans le cas des répertoires.
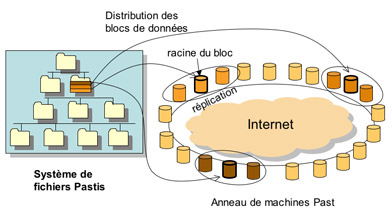
Principe du système Pastis.
Image : équipe REGAL.
Le système Pastis<, développé par les chercheurs de l’équipe REGAL (commune à l’INRIA et au laboratoire LIP6 du CNRS et de l’université Paris 6), fonctionne selon ce schéma général. Il repose sur la table de hachage distribuée open source PAST, conçue par l’université de Rice à Houston. L’évaluation des performances de Pastis s’est faite, indirectement, en comparant sa rapidité à celle du système de fichiers avec serveur central sous Unix, NFS. Pastis s’est révélé seulement de 1,4 à 1,8 fois plus lent que NFS, soit mieux que ses principaux concurrents, le système IVY de l’institut technologique du Massachusetts et OceanStore de l’université de Berkeley, tous deux étant de 2 à 3 fois plus lents que NFS.
Newsletter
Le responsable de ce traitement est Inria. En saisissant votre adresse mail, vous consentez à recevoir chaque mois une sélection d'articles et à ce que vos données soient collectées et stockées comme décrit dans notre politique de confidentialité
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
