Naissance des langages de programmation
Pour comprendre le défi posé par la programmation des ordinateurs, il faut brièvement rappeler le principe de leur fonctionnement. Une machine à programme enregistré comporte un jeu d’instructions dont chacune réalise une opération élémentaire : opération arithmétique, transfert d’information entre mémoire et accumulateur, branchement conditionnel, etc. Une instruction est représentée par une suite de bits dans la mémoire, selon un codage conventionnel.
Pour prendre un exemple, inventons une machine où ajouter le contenu de l’emplacement de mémoire d’adresse 1576 à celui de l’accumulateur s’écrirait :
01010 11000101000 (1)
On suppose que les 5 bits de gauche désignent l’opération à effectuer (il y a donc 25 = 32 opérations possibles). Ici, l’addition est l’opération n° 10 (01010 en binaire). Les 11 bits de droite codent l’adresse de l’opérande (on peut donc adresser une mémoire de 211 = 2048 emplacements). On conçoit bien que l’écriture d’un programme sous cette forme était une tâche délicate, fastidieuse, et sujette aux erreurs !
Un premier progrès fut réalisé au début des années 1950 par l’invention des langages d’assemblage. Dans un tel langage, l’opération ci-dessus pourrait s’écrire :
add longueur (2)
add représente l’opération d’addition (01010) et longueur désigne l’adresse 1576. Notons que le nom add est défini une fois pour toutes dans le répertoire des instructions disponibles et que longueur est un nom choisi par le programmeur en relation avec l’application qu’il traite. Un programme appelé assembleur, fourni avec la machine, assure la traduction de la forme (2) vers la forme (1), seule interprétable par l’ordinateur. L’assembleur assure d’autres fonctions telles que le placement automatique des données en mémoire (ainsi, c’est lui qui définit une adresse pour la variable longueur) et la gestion des sous-programmes. Une forme rudimentaire d’assembleur était déjà présente dans la machine EDSAC (le premier calculateur à programme enregistré) sous la forme d’« ordres initiaux » câblés.
Si l’introduction de l’assembleur améliorait nettement la situation grâce à un premier pas vers l’abstraction, un défaut fondamental subsistait : un programme en assembleur est écrit en termes de ce que sait faire la machine ; or, on souhaite une expression en termes de ce que veut faire l’utilisateur. Une telle expression a en outre l’avantage d’être indépendante de la machine. C’est ce saut conceptuel qui va être réalisé avec l’invention des langages de programmation.
Le premier langage de haut niveau est Plankalkül, défini par Konrad Zuse, un ingénieur allemand, vers la fin de la Seconde Guerre mondiale. Les concepts de ce langage étaient très en avance, même par rapport à ceux définis dix ou quinze ans plus tard. Mais il est resté ignoré et n’a été implanté que dans les années 1970 à titre historique. Entre 1954 et 1960 ont été introduits de nombreux langages de programmation, dont nous retenons les quatre suivants : Fortran, Cobol, Algol et Lisp, en raison de leur très large diffusion pour les deux premiers et de leur influence sur les langages ultérieurs pour les deux suivants.
FORTRAN
Fortran (Formula translator) est le premier langage de haut niveau ayant connu une large diffusion. Mais plusieurs travaux expérimentaux [1], au début des années 1950, avaient préparé le terrain, en proposant à la fois des notations abstraites et le moyen de les mettre sous forme exécutable. Le terme de « programmation automatique » était alors utilisé pour qualifier ces travaux. Il traduisait l’espoir, que l’on sait aujourd’hui infondé, d’une très large automatisation du processus de production des programmes.

Carte Fortran avant perforation.
© Inria / G. Dugast.
La définition de Fortran et sa traduction en code binaire, la compilation, sont issues d’un projet mené au sein de la compagnie IBM par John Backus et son équipe. Le facteur économique — réduction du coût de développement des programmes — a joué un rôle important dans la définition de ce projet et explique le soutien constant que lui a apporté IBM, malgré les risques liés à son caractère innovant. Les dates-clés sont 1954 (rapport préliminaire) et 1956 (manuel de référence et premier compilateur sur l’IBM 704).
Un exemple de programme dans la notation de la toute première version de Fortran est donné ci-dessous (extrait de la référence citée en note 1). Le travail qu’il réalise, qui n’a d’autre intérêt que d’illustrer quelques traits du langage, est le suivant :
Lire 11 valeurs (soit A0, A1, …, A10) dans cet ordre.
Itérer la séquence suivante pour I = 10, 9, … 0 dans cet ordre :
- calculer Y = (√ |AI|) + 5 AI3
- si Y ≤ 400, imprimer les valeurs de I et de Y, sinon imprimer la valeur de I et 999 [2].
2 READ A
3 2 DO 3,8,11 J=1,11
4 3 I=11-J
5 Y=SQRT(ABS(A(I+1)))+5*A(I+1)**3
6 IF (400. >=Y) 8,4
7 4 PRINT I,999.
8 GO TO 2
9 8 PRINT I,Y
10 11 STOP
On peut noter les traits suivants :
- l’identification de certaines instructions par des étiquettes numériques ;
- une instruction d’itération DO spécifiant les limites de la séquence à itérer pour une suite de valeurs de la variable J, et l’instruction à exécuter à la fin (ici la sortie du programme) ;
- une instruction conditionnelle IF, spécifiant les instructions à exécuter selon le résultat d’une comparaison ;
- une formule (ligne 5), comportant l’accès à un tableau de valeurs et des appels de fonctions.
Le type d’une variable est spécifié par sa lettre initiale (de I à N : entier, autres lettres : réel).
Outre l’expressivité, l’efficacité du code produit était considérée comme un facteur déterminant dans l’acceptation du langage. On sait aujourd’hui que la génération de code efficace est l’un des aspects les plus délicats de l’écriture d’un compilateur. Cela explique sans doute la durée de développement du premier compilateur (deux ans) et sa taille (vingt-cinq mille lignes de programme en assembleur). En revanche, les aspects liés à la sécurité, à la détection des erreurs et aux outils de mise au point ont été largement sous-estimés, car on croyait que l’utilisation d’un langage de haut niveau suffirait à éliminer les erreurs de programmation.
Fortran était destiné au calcul scientifique, la principale application à l’époque, et son usage s’est vite répandu auprès des scientifiques et des ingénieurs. Il s’agissait d’une révolution dans l’usage des ordinateurs, puisque des utilisateurs non spécialistes pouvaient écrire leurs propres programmes après deux ou trois semaines de formation. À travers des évolutions successives (Fortran IV, Fortran 77, Fortran 95, etc.), Fortran est resté le langage de référence pour le calcul scientifique, grâce notamment à sa bibliothèque de fonctions mathématiques. Il s’est adapté au calcul parallèle, via l’usage de compilateurs permettant d’extraire des séquences parallélisables des programmes.
ALGOL
Un grand nombre de langages furent proposés dans les années 1955-57 ; en l’absence de cadre conceptuel bien défini, il y avait peu de critères pour les comparer et les évaluer. Pour mettre de l’ordre dans ce paysage, la communauté scientifique créa un groupe de travail chargé de définir un langage « universel » de programmation, orienté vers le calcul scientifique, avec un accent sur la généralité, la sécurité et la rigueur de la définition. Ce groupe était principalement composé d’universitaires américains et européens ; John Backus, le créateur de Fortran, en faisait partie, ainsi que John McCarthy, qui travaillait à la même époque sur Lisp.
Définir un langage comme résultat d’un travail de groupe est une entreprise périlleuse quand la principale qualité recherchée est l’unité conceptuelle. Néanmoins, grâce surtout au travail de Peter Naur [3], rapporteur du groupe, le résultat final fut un langage dont C. A. R. Hoare a pu dire qu’il représentait « un progrès notable sur la plupart de ses successeurs ». Une première version, Algol 58, a été définie en 1958, mais la version de référence est Algol 60, défini par le Revised Report on the Algorithmic Language Algol 60, paru en 1962. Ce document de quarante-trois pages est l’un des textes clés de l’histoire de l’informatique. Il introduit notamment la notation métalinguistique BNF — initialement Backus Normal Form, rebaptisée Backus-Naur Form — qui reste un instrument de base pour la définition des grammaires hors contexte et qui a inspiré maintes notations ultérieures.
Les travaux sur les grammaires formelles ont commencé dans les années 1930 et se sont surtout développés dans les années 1950-60. Ils étaient inspirés par l’espoir de fournir un modèle pour les langages naturels, sous la forme d’un mécanisme de génération des phrases du langage. En 1956, Noam Chomsky a proposé une classification des grammaires formelles selon leur pouvoir d’expression. Les grammaires de type 2, dites « hors contexte » (context free) se sont révélées très utiles pour la définition et la compilation des langages de programmation. Nous en donnons une description intuitive (voir une définition rigoureuse dans Wikipedia ).
Une grammaire hors contexte définit un langage. Elle comporte un nombre fini de symboles dits terminaux (non décomposables, par exemple des lettres, des signes mathématiques, etc.) et un nombre fini de symboles dits non terminaux, qui représentent les catégories de phrases du langage. La génération de ces phrases est définie par un ensemble de règles de production de la forme :
où A est un symbole non terminal et α une suite (éventuellement vide) de symboles terminaux et non terminaux. La flèche exprime que le symbole A peut être remplacé par la suite α (indépendamment du contexte dans lequel il apparaît). Un même symbole peut apparaître en partie gauche de plusieurs règles (il a donc plusieurs possibilités de remplacement). Par exemple, supposons que les symboles terminaux soient : x y + – * / ( ), les symboles non terminaux S et T, et les règles de production :
| T → x T → y S → S+T S → S-T | S → S*T S → S/T T → (S) S → T |
Cette grammaire définit une classe S d’expressions arithmétiques bien formées construites avec les opérations + – * / et les variables x et y. Des exemples de telles expressions sont :
Un arbre de dérivation est une manière d’exprimer la génération d’une phrase à partir des règles de production. L’application d’une règle se traduit par une descente d’un niveau dans l’arbre, et la phrase est la suite des symboles de plus bas niveau (les feuilles de l’arbre, en rouge sur la figure) lue de gauche à droite. Si cet arbre est unique pour une phrase donnée, la grammaire est non ambiguë, ce qui est évidemment souhaitable. Ainsi l’arbre de dérivation de x*(y-x) est (a) :
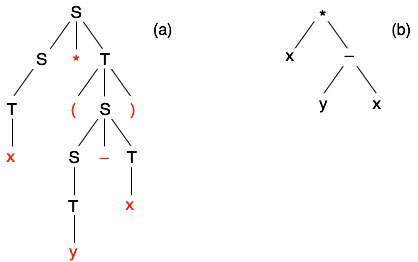
Un tel arbre, sous la forme simplifiée (b), est très utile dans un compilateur pour l’analyse des instructions d’un langage de programmation et pour la génération du code machine qui leur correspond (pour cette dernière opération, il faut annoter l’arbre par des règles sémantiques, exprimant par exemple que le symbole * représente une multiplication et doit donc être traduit en utilisant l’instruction machine correspondante). Une notation commode pour la description d’une grammaire hors contexte est la BNF (Backus-Naur Form), introduite dans le rapport Algol 60. Voici un extrait de ce rapport :
Chaque ligne représente une règle de production. Le symbole ::= est équivalent à la flèche introduite plus haut. Le symbole | sépare les choix possibles de productions. Les noms entre crochets < et > désignent les non terminaux ; les autres symboles sont ceux des terminaux. Un identificateur est ainsi défini (récursivement) comme une suite non vide de lettres et de chiffres commençant par une lettre. La grammaire des expressions arithmétiques introduites plus haut est définie en BNF par :
On notera la récursivité directe et croisée (les expressions sont définies au moyen des expressions et des termes et les termes au moyen des expressions). Mais chacune des définitions comporte une variante permettant de terminer la récursion.
La notation BNF permettait une définition rigoureuse de la syntaxe du langage, c’est-à-dire de la forme des constructions qu’il autorise. L’autre aspect à prendre en compte est la sémantique, c’est-à-dire la signification de ces constructions, autrement dit l’effet de leur exécution. La sémantique pose des problèmes beaucoup plus complexes que la syntaxe, et les premiers outils permettant sa définition formelle ne devaient apparaître que dans les années 1970. La sémantique d’Algol 60 est définie avec beaucoup de soin dans le rapport, mais en utilisant le langage naturel.
Algol remédiait à deux faiblesses constatées pour Fortran : le manque de rigueur dans sa définition et son faible degré de sécurité. Ce dernier point était particulièrement critique : ainsi, une variable était implicitement « déclarée » (connue du programme) lors de sa première apparition. Donc une simple erreur de saisie, comme 1 à la place de I ou vice-versa était rarement détectée, car le compilateur lui trouvait généralement une interprétation [4].
Les variables d’un programme Algol doivent être explicitement déclarées, avec leur type (entier, réel ou booléen). Le langage a une structure de blocs emboîtés qui permet la définition de tableaux de taille variable et l’allocation dynamique de données. Une attention particulière a été portée à la définition des procédures. Une procédure est une séquence réutilisable d’instructions, réalisant une tâche spécifiée, désignée par un nom et comportant généralement des paramètres.
comment déplace la tour de hauteur N du plot x vers le plot z ;
if N>0 then
begin
hanoi(N-1, x, z, y);
deplacer(x,z);
hanoi(N-1, y, x, z);
end ;
Une procédure peut être récursive (son corps contient un appel à elle-même), comme l’illustre l’exemple des tours de Hanoï.
Une tour de Hanoï de hauteur N, appelée tour(N) dans la suite, est constituée d’un ensemble de N disques de diamètres différents, percés d’un trou central, et enfilés sur un plot vertical par ordre de diamètre décroissant. On dispose de trois plots appelés 1, 2, 3. Une tour(N) est initialement installée sur le plot 1. Le problème consiste à la déplacer vers le plot 3, en utilisant le plot 2 comme lieu de rangement intermédiaire et en respectant les règles suivantes :
- on ne peut déplacer qu’un disque à la fois ;
- on ne peut déplacer qu’un disque situé au sommet de sa pile ;
- on ne peut poser un disque que sur un disque de diamètre supérieur ou sur un plot vide.
Notons que le problème pour une tour(N) peut être résolu simplement si on sait le résoudre pour une tour(N-1). En effet une tour(N) est un disque unique surmonté par une tour(N-1). On transporte alors cette tour(N-1) du plot 1 au plot 2 avec le plot 3 comme intermédiaire (opération a). On déplace le disque restant du plot 1 au plot 3 (opération b). Enfin, on transporte la tour(N-1) du plot 2 au plot 3 avec le plot 1 comme intermédiaire (opération c), ce qui termine le travail. La figure ci-dessous schématise ces opérations.
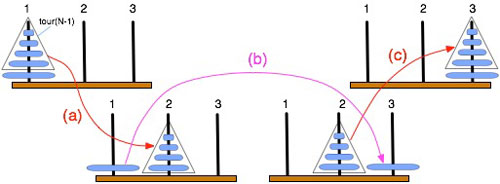
On ramène ainsi le problème pour N disques au problème pour N-1 disques, et on arrive ainsi de proche en proche à un disque unique, pour lequel la solution est immédiate. Dans la procédure écrite en Algol 60, on retrouve les phases a, b, c décrites plus haut.
Évaluons le nombre de mouvements Nmouv(N) pour N disques. On a, d’après le schéma du programme :
Nmouv(N) = 2 Nmouv(N-1) + 1
En effet on déplace deux fois la tour(N-1) en a et c, et une fois le disque de base en b.
Comme Nmouv(1) = 1, on a par récurrence :
Nmouv(N) = 2n – 1
On peut noter que le disque le plus petit est déplacé lors d’un mouvement sur deux, et que le disque de base n’est déplacé qu’une seule fois.
Une légende orientale dit que la fin du monde surviendra quand sera achevé le déplacement d’une tour(64) installée lors de la création du monde. À raison d’un mouvement par seconde, il y faudrait 584 milliards d’années…
Il s’agit de déplacer des disques de diamètres différents entre trois plots, de manière à obtenir une tour où les disques sont empilés du plus grand au plus petit. Ci-dessus, l’écriture de la procédure en Algol 60.
L’appel hanoi(N, 1, 2, 3) exécute le déplacement d’une tour de N disques. Si on lui fournit un paramètre N négatif ou nul, la procédure ne fait rien. Si N = 1, son effet se réduit à deplacer(1,3), ce qui est bien le résultat souhaité.
La procédure deplacer(x, y), non décrite ici, déplace un disque depuis le plot x vers le plot y (concrètement, elle pourrait visualiser le déplacement sur l’écran, voire commander le bras d’un robot qui effectuerait l’opération).
Le même exemple est présenté plus loin écrit en langage Lisp.
Le passage de paramètres peut se faire par valeur ou par nom.
Dans une procédure, on distingue les paramètres formels, qui figurent dans la déclaration de la procédure, et les paramètres effectifs, fournis lors de l’appel. Le mode de passage des paramètres spécifie la correspondance entre paramètres formels et effectifs. Algol 60 autorise deux modes de passage :
- l’appel par valeur, dans lequel la valeur du paramètre effectif est évaluée une fois pour toutes à l’entrée de la procédure et ne change plus au cours de l’exécution de celle-ci,
- l’appel par nom, dans lequel le nom du paramètre effectif est recopié textuellement dans le corps de la procédure à la place du paramètre formel, et l’expression correspondante est réévaluée à chacune de ses apparitions.
Comme les paramètres effectifs peuvent être des expressions contenant d’autres paramètres, l’appel par nom permet notamment d’établir dynamiquement (lors de l’appel de la procédure) des dépendances entre paramètres, comme l’illustre l’exemple suivant, dû à Jørn Jensen.
Cette procédure peut être utilisée de manière générique pour calculer la somme des termes d’une série entre les indices debut et fin. La variable i désigne l’indice du terme courant, lui-même désigné par la variable terme ; ces deux variables sont passées par nom. La dépendance entre terme et i est établie au moment de l’appel de la procédure. Ainsi (en supposant que k soit une variable entière déclarée précédemment)
somme(1, 20, k, 1/k) calcule la somme pour i allant de 1 à 20 des valeurs de 1/i
et
somme(0, 15, k, (k+2)/(2*k+1)) calcule la somme pour i allant de 0 à 15 des valeurs de l’expression (i+2)/(2i+1).
En effet, le paramètre k, qui remplace i, change de valeur à chaque étape de l’itération et le paramètre terme est remplacé dans le corps de la procédure par l’expression (fonction de k) fournie lors de l’appel. Les valeurs des paramètres debut et fin sont en revanche fixées lors de l’appel.
Ce mode de passage de paramètres illustre une technique générale, l’évaluation paresseuse (le calcul d’une valeur se fait le plus tard possible au cours de l’exécution). L’appel par nom autorise une grande capacité d’expression, mais son usage peut conduire à des effets de bord mal maîtrisés.
En outre, cette construction est complexe à compiler et peu efficace à l’exécution. Pour ces raisons, l’appel par nom a disparu dans les langages impératifs qui ont succédé à Algol 60. Il a été remplacé par l’appel par référence, dans lequel le paramètre effectif ne peut être qu’une variable du type spécifié dans la déclaration de la procédure, mais non une expression. Un accès à cette variable est réalisé lors de chacune de ses occurrences dans le corps de la procédure. Un mécanisme analogue à l’appel par nom existe toujours dans les langages fonctionnels.
Les premiers compilateurs datent de 1960 (X1 Algol d’Edsger Dijkstra et Jaap Zonneveld sur Electrologica X1, Elliott Algol de C.A.R. Hoare sur Elliott 803). Le premier compilateur pour le langage complet est celui de Peter Naur et Jørn Jensen pour la machine Dask de Regnecentralen et plus tard le Gier. Si relativement peu de programmes ont été écrits en Algol, ce langage a largement été utilisé comme support privilégié pour la publication d’algorithmes (son nom dérive de Algorithmic Language).
Algol est le point de départ de la lignée des « langages algoliques » qui compte notamment Algol W (Niklaus Wirth et C. A. R. Hoare), et Pascal (Niklaus Wirth) ainsi qu’Algol 68 (langage défini par un groupe de travail de l’IFIP avec un objectif de généralité et de rigueur de définition). L’influence d’Algol 60 se fait encore sentir sur les langages à objets, à travers Simula 67. Les déclarations, les blocs emboîtés et les procédures récursives restent un héritage universel.
Algol 60, Algol W et Pascal ont été très largement utilisés pour l’enseignement de l’algorithmique et de la programmation, en raison de leur expressivité, de leur facilité de compréhension et de la rigueur de leur définition. Pascal a d’ailleurs été initialement conçu pour cet usage pédagogique, avant de connaître une diffusion plus large.
Une limitation d’Algol 60 est l’absence de prise en compte des fichiers et des entrées-sorties : chaque constructeur de compilateur devait définir ses propres conventions liées à la machine, ce qui nuisait à la portabilité des programmes. Ce défaut fut corrigé plus tard, notamment dans Pascal.
COBOL
Le langage Cobol (Common Business Oriented Language) a été défini aux États-Unis par un comité rassemblant des délégués d’agences gouvernementales et de sociétés informatiques. Les applications dites « de gestion » (comptabilité, gestion de stocks, gestion de personnel, etc.) commençaient à se développer dans les entreprises et le langage Fortran y était peu adapté.
Le langage a été inspiré par deux prédécesseurs, Flowmatic (1956, Remington Rand Univac), créé par Grace Hopper, et Comtran (Commercial Translator, 1957, IBM). Le rapport de définition a paru en 1959 et les premiers compilateurs ont fait l’objet de démonstrations en décembre 1960. Deux programmes pratiquement identiques ont été exécutés sur un calculateur RCA et un calculateur Remington Rand Univac. C’est très probablement la première expérience portant sur la portabilité de programmes, qui était l’un des objectifs initiaux.
Une idée sous-jacente à la conception de Cobol est que l’usage de verbes en langage naturel pour traduire l’exécution d’actions simplifierait la compréhension des programmes et rendrait donc leur construction accessible à des personnels moins qualifiés que les programmeurs professionnels. Il s’agissait évidemment d’une illusion qui fut assez vite dissipée.
IDENTIFICATION DIVISION.
PROGRAM ID. Iteration-If.
AUTHOR. Michael Coghlan.
DATA DIVISION.
WORKING STORAGE SECTION.
01 Num1 PIC 9 VALUE ZEROS.
01 Num2 PIC 9 VALUE ZEROS.
01 Result PIC 99 VALUE ZEROS.
01 Operator PIC X VALUE SPACE
PROCEDURE DIVISION.
Calculator.
PERFORM 3 TIMES
DISPLAY « Enter First Number : » WITH NO ADVANCING
ACCEPT Num1
DISPLAY « Enter Second Number : » WITH NO ADVANCING
ACCEPT Num2
DISPLAY « Enter Operator (+ or *) : » WITH NO ADVANCING
ACCEPT Operator
IF OPERATOR = « + » THEN
ADD Num1, Num2 GIVING Result
ENDIF
IF OPERATOR = « * » THEN
MULTIPLY Num1 BY Num2 GIVING Result
ENDIF
DISPLAY « Result is = « , Result
END PERFORM
STOP RUN
L’exemple ci-dessus donne une idée de quelques constructions de Cobol. On distingue plusieurs sections, dont une section de définition des données (DATA DIVISION) et une section de programme (PROCEDURE DIVISION). Les données sont ici des chaînes de caractères, mais la plupart des types standard existent. La notation PIC 9 est un modèle (picture) spécifiant ici une donnée à un seul chiffre décimal. Ce système de description est généralisé. Une attention particulière, gestion oblige, est portée à la présentation externe des données et aux entrées-sorties. Les identificateurs peuvent être très longs : la lisibilité des programmes étant jugée fondamentale, il en résulte une certaine verbosité du langage. On remarque que chaque instruction commence par un mot clé, en général un verbe ; ce mot clé est suivi de différents paramètres, en général en nombre variable. Le langage permet les itérations (PERFORM) et les instructions conditionnelles (IF … THEN).
Cobol manque d’élégance et ses constructions n’encouragent guère l’écriture de programmes bien structurés. En dépit de ces défauts, il est resté le langage de référence en matière de programmation de gestion. On estimait en 1997 que 80 % des programmes exécutés étaient écrits en Cobol. Une dernière remarque, peut-être anecdotique : beaucoup de programmes en Cobol codaient les dates sur deux chiffres et ont dû être révisés pour permettre le passage à l’an 2000, ce qui a nécessité de faire appel à de nombreux « cobolistes » retraités.
Cobol n’a pas eu de descendants, mais, comme pour Fortran, de multiples versions ont accompagné l’évolution du domaine.
LISP
Le langage Lisp (List Processing) a été défini vers 1958 par John McCarthy, alors au MIT, pour la représentation symbolique des données et leur manipulation, avec en particulier des applications à l’intelligence artificielle. Lisp a été inspiré par Ipl2, langage créé par Newell, Shaw et Simon pour faire du traitement de listes sur le calculateur Johnniac, et par Flpl (Fortran List Processing Language).
Lisp présente plusieurs traits qui le distinguent des principaux langages de la fin des années 1950.
- Lisp est un langage fonctionnel, inspiré par le lambda calcul introduit par Alonzo Church au milieu des années 1930, formalisme de puissance équivalente à celle d’une machine de Turing. Par opposition aux langages impératifs, tels que Fortran ou Algol, fondés sur l’usage de variables explicitement modifiables par affectation, un langage fonctionnel repose sur un mécanisme unique, l’appel de fonction. L’appel d’une fonction délivre un résultat unique à partir de zéro ou plusieurs paramètres (ou arguments). Plusieurs appels d’une même fonction avec les mêmes arguments donnent des résultats identiques. Tout effet de bord (modification d’un état global après un appel de fonction) est ainsi exclu. Pour des raisons d’efficacité, une opération d’affectation existe néanmoins en Lisp, mais il est recommandé de restreindre son usage.
- Les éléments du langage sont les atomes (symboles élémentaires) et les listes (suites d’éléments pouvant être des atomes ou des listes). Les fonctions de base permettent de construire une liste (cons), de délivrer le premier élément d’une liste (car), ou la liste privée de son premier élément (cdr), etc.
Une caractéristique centrale du langage est que programmes et données ont une représentation unique, la liste. Un programme se présente sous la forme d’une collection de fonctions. Chacune d’elles est représentée par une liste dont le premier élément est le nom de la fonction et les suivants sont ses arguments, qui peuvent eux-mêmes contenir des appels de fonctions. Un programme peut ainsi construire une liste définissant une fonction, puis exécuter celle-ci. Cette capacité sert notamment dans certaines applications d’intelligence artificielle, dans lesquelles on a besoin de créer dynamiquement des programmes.
Une fonction peut être définie de plusieurs manières :
- elle est fournie dans la bibliothèque de base : c’est le cas par exemple des fonctions de manipulation de listes (car, cons, cdr, list, append, etc.) et des fonctions mathématiques (+, -, *, /, sin, cos, etc.) ;
- elle est définie explicitement au moyen de la fonction defun (voir exemple ci-après) ;
- elle est écrite de façon anonyme au moyen de la fonction lambda. Par exemple, la fonction anonyme (lambda (arg) (+ arg 1)) délivre la valeur de son argument (supposé être un nombre) augmentée de 1. Ainsi ((lambda (arg) (+ arg 1)) 4) délivre 5.
Deux fonctions spéciales interdépendantes, eval et apply, servent respectivement à évaluer une expression (atome ou liste) et à exécuter une fonction.
(list (list ’DÉPLACER ’DISQUE d ’DE x ’VERS y)))
(defun hanoi (n x y z)
; déplace une tour de hauteur n de x vers z
(cond ((> n 0)
(append (hanoi (- n 1) x z y)
(deplacer n x z)
(hanoi (- n 1) y x z)))))
Ci-dessus, l’exemple des tours de Hanoï, dont la structure est identique à celle du programme correspondant en Algol 60. Notons que la fonction append construit une liste en concaténant les éléments des listes fournies en arguments, alors que la fonction list construit une liste dont les éléments sont ses arguments.
Notons aussi l’usage du signe ’, abréviation de la fonction quote, qui bloque l’évaluation de l’expression qui le suit, cette expression étant alors utilisée comme une constante.
Les disques sont numérotés dans l’ordre croissant de leur taille. L’appel (hanoi 3 ’1 ’2 ’3) produit le résultat suivant :
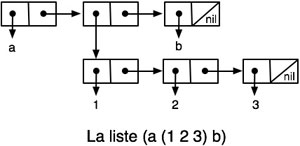
La représentation interne des listes en mémoire fait appel à des pointeurs (information qui désigne une adresse de mémoire). La figure ci-dessous en montre un exemple. Les emplacements contenant les listes sont alloués dynamiquement dans la mémoire. Lorsque l’espace disponible est épuisé, un programme appelé ramasse-miettes (garbage collector) détermine les portions de mémoire inutilisées et les remet dans l’espace libre.
Alors que Fortran, Cobol et Algol sont des langages compilés (traduits en code binaire), un programme Lisp peut être interprété (directement exécuté par un programme appelé interprète, qui combine les fonctions eval et apply) ou compilé (le premier compilateur date de 1962).
Après plus de cinquante ans, Lisp est toujours utilisé, avec des phases de plus ou moins grande popularité. Il a donné lieu à de nombreux dialectes et sur-langages. L’un des plus populaires est probablement Scheme, très utilisé pour l’enseignement de l’algorithmique.
Le principal héritage de Lisp est le développement des langages fonctionnels, notamment les dérivés de ML (Robin Milner, 1973) comme Haskell ou OCaml dont l’importance est aujourd’hui croissante.
Rétrospective et prospective
Paradoxalement, les deux langages qui ont été le plus utilisés, et de loin, sont ceux qui ont eu le moins d’influence sur les langages ultérieurs. Le monde académique a ignoré Cobol et souvent méprisé Fortran. Ainsi Dijkstra, apôtre de la rigueur, jugeait que Cobol abîmait l’esprit et prétendait exiger de ses doctorants qu’ils n’aient aucune connaissance de Fortran !
Dans les années 1960-70, chercheurs et industriels ont poursuivi le mythe du « langage idéal ». Dans l’euphorie des années 1960, on a cru pouvoir créer un langage-cible universel pour les compilateurs, Uncol. Compte tenu de l’état des connaissances, cette tentative était prématurée. Néanmoins, les langages-cibles des machines virtuelles modernes réalisent partiellement cet ancien espoir.
Dans une note plus réaliste, PL/1 (essai de mariage, chez IBM, de Fortran et Cobol) et Ada (grand projet du département de la Défense des États-Unis) ont également visé l’universalité. Malgré quelques succès notables, PL/1 est tombé en désuétude et Ada reste confiné à un marché de niche.
La plupart des concepts qui ont dominé l’évolution des langages de programmation étaient présents dans Algol et Lisp :
- les constructions de base (voir Les ingrédients des algorithmes) ;
- la récursivité ;
- les premiers éléments de la notion de type, introduite dans Algol, étendue plus tard dans les langages fonctionnels issus de ML, lui-même héritier de Lisp ;
- les outils de description des grammaires et leur usage pour la construction de compilateurs ;
- la gestion dynamique de la mémoire ;
- les techniques de base des interprètes, la notion de méta-circularité (écriture d’un interprète ou d’un compilateur dans le langage même dont il traite les programmes).
À la fin des années 1960, la prise de conscience de la difficulté de la programmation, et du fait que le choix d’un langage ne résolvait pas tous les problèmes, a conduit au développement du génie logiciel, qui a (entre autres) mis en évidence deux aspects initialement négligés :
- le fait que les programmes avaient une durée de vie nettement plus longue que prévu, et qu’il fallait pouvoir les adapter à l’évolution des environnements et des machines ; l’exemple du passage à l’an 2000 en est une illustration ;
- l’importance de la construction modulaire, qui s’est révélée génératrice de problèmes difficiles, à la fois conceptuels et techniques, qui restent encore présents aujourd’hui.
Parmi les recherches actuelles, on peut citer des tentatives pour combiner différents styles de langages (à objets, logiques, fonctionnels) ; des exemples en sont Oz et Scala. D’autres travaux portent sur des langages spécialisés bien adaptés à un domaine particulier d’application. Des exemples anciens en sont les langages de script (interprétés) utilisés pour l’accès aux fonctions d’un système d’exploitation (les shells d’Unix) ou pour la manipulation de symboles et l’édition (Awk). Plus récemment, on peut citer Xslt pour la transformation de structures en XML, et divers langages spécialisés dans la manipulation de composants logiciels, le développement de protocoles de communication, ou l’écriture de pilotes de systèmes d’exploitation.
Le cahier des charges des tout premiers langages de programmation, pas toujours explicité, comportait avant tout le haut niveau et la puissance d’expression, l’efficacité et enfin la facilité d’apprentissage et la commodité de lecture. La rigueur sémantique et la sécurité ne figuraient initialement qu’au second plan. Aujourd’hui, cette liste se lit plutôt dans l’ordre inverse : le « haut niveau » va sans dire et l’efficacité n’est plus vraiment le problème dominant, au point de remettre à l’honneur les techniques interprétatives. En revanche, un fort accent est mis sur deux points :
- la rigueur sémantique, allant jusqu’à la capacité de certification (preuve formelle que le programme répond à ses spécifications). Des progrès notables ont été faits sur ce plan dans les dernières années (systèmes de types évolués, analyse statique, outils d’aide à la preuve) ;
- la sécurité, sous deux aspects : protection contre les fautes de programmation, protection contre les attaques malveillantes. Ce dernier problème, qui reste encore très ouvert, dépasse le strict cadre des langages et touche aussi les communications et les systèmes d’exploitation.
La réponse à ces questions est un enjeu majeur de notre future société à base d’informatique ubiquitaire.
Ce document fait partie d’une série consacrée à divers aspects de l’histoire de l’informatique, réalisée en conjonction avec un projet de musée virtuel sur ce thème, porté par l’association ACONIT.
Notes
[1] Voir une étude détaillée dans : D. E. Knuth and L. T. Pardo. “The early development of programming languages” in Encyclopedia of Computer Science and Technology, Marcel Dekker, New York, 1977, pages 419-96.
[2] Cette première version (V1) de Fortran avait diverses limitations qui se traduisent ainsi dans l’écriture du programme :
a) La spécification disait d’imprimer le texte « TOO LARGE ». Mais on ne pouvait pas, dans la V1, imprimer les chaînes de caractères. C’est pourquoi le texte a été remplacé par la valeur conventionnelle « 999 ».
b) La variable J = 11 – I a été introduite pour pouvoir itérer sur des valeurs croissantes, seule possibilité permise par la V1.
c) Notons enfin que, selon les conventions de la V1, la suite de variables A0 … A10 est représentée dans le programme par un tableau A indexé de 1 à 11. Donc AI est représentée par A[I+1].
[3] Ce travail a valu à Peter Naur le prix Turing en 2005. John Backus l’a obtenu en 1977 et John McCarthy en 1971.
[4] On attribue à une erreur de ce type la perte d’une fusée Mariner en 1962.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

