Histoire du traitement d’images
Quel est le point commun entre la robotique médicale, où un chirurgien est guidé dans ses actes grâce à des images sur un écran, la reconnaissance des montants manuscrits des chèques bancaires, la télédétection, c’est-à-dire l’analyse de photos satellites, par exemple pour évaluer un phénomène de pollution, et les systèmes de détection d’obstacles des automobiles ?
Toutes ces applications, et bien d’autres, font appel à du traitement d’images, que ce soient les images médicales de nos organes obtenues par radiographie ou scanner, les images d’un chèque, celles de la Terre vue de satellite, ou celles d’une route…
1. Des premières images à leur traitement

Au CERN, dans les années soixante, projection et mesure des images prises dans une chambre à bulles (image CERN).
Le besoin de traiter les images est rapidement devenu une évidence, dès les années cinquante en physique des particules – où les scientifiques scrutent les composants ultimes de la matière en bombardant des atomes les uns contre les autres – pour détecter des trajectoires particulièrement complexes. « Dès 1960, il fallait analyser 10 000 à 100 000 images par expérience dans les chambres à bulles pour déterminer les trajectoires de milliers de particules grâce à plusieurs caméras réparties », rappelle Serge Castan.
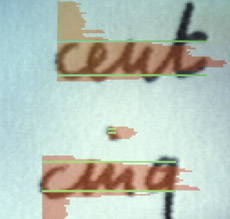
Système de reconnaissance d’écriture manuscrite.
Dans les années soixante, les chercheurs se sont intéressés à la lecture optique pour reconnaître les caractères dactylographiés d’un texte. En termes d’images, cette application semblait abordable : le nombre de caractères est limité et l’image est contrastée. « Le professeur René de Possel (1905-1974), alors directeur de l’Institut Blaise Pascal à Paris, a mené beaucoup de recherches sur le sujet », précise Serge Castan.
« Il avait mis au point un lecteur optique dès 1965, et fit fonctionner en 1969 la première machine à lire automatiquement les textes imprimés. En 1976, on disposait d’un système complet de reconnaissance de 1 000 caractères dactylographiés par seconde. » Pour l’écriture manuscrite, il a fallu attendre une vingtaine d’années de plus pour que de telles techniques soient opérationnelles, par exemple pour lire les adresses postales ou les montants des chèques bancaires.
« En 1972, je travaillais sur la reconnaissance de l’écriture à l’IRIA », se rappelle Marc Berthod. « Il y avait plusieurs façons de communiquer un caractère manuscrit à l’ordinateur. Nous cherchions à reconnaître le caractère pendant qu’il était tracé, et nous utilisions à cette fin des tablettes graphiques, des grillages de fils électriques qui captaient la présence d’un stylo. D’autres écrivaient directement à l’écran avec un lightpen, un crayon optique, dont le tracé était révélé par son interaction avec un flying-spot, un faisceau lumineux balayant l’écran de façon continue. »
D’une manière générale, jusqu’à la fin des années soixante, les images, que ce soient des photos de satellites, des images d’ADN au microscope électronique ou des radiographies, étaient de mauvaise qualité, difficiles à exploiter. Les optiques étaient peu performantes, provoquant de nombreuses aberrations géométriques et chromatiques. Traiter des images a d’abord consisté à les restaurer en corrigeant tous ces défauts d’acquisition. En parallèle, se posaient deux problèmes : leur volume – plusieurs milliers de pixels par ligne sur plusieurs milliers de lignes – difficile à stocker, et surtout leur traitement, très lent. Il fallait donc comprimer les images (sans trop de détérioration) pour parvenir à les traiter en temps réel. « Beaucoup de recherches ont été menées dans les années soixante dans le domaine de la compression d’images, en particulier pour l’image animée, autrement dit la télévision », explique Henri Maître. « Les premiers travaux se situent entre 1957 et 1962, surtout aux États-Unis. Ensuite, dès 1965-1970, une large communauté de chercheurs à travaillé à comprimer ces gros volumes de données. » Les codages actuels des images numériques (Jpeg) ou des vidéos (Mpeg) sont les descendants lointains des travaux de cette époque.
2. Du traitement des images à leur interprétation automatisée
L’idée d’automatiser l’interprétation des images est apparue dès le début : il a d’emblée paru opportun de les classer, de les faire traiter par des ordinateurs. « Les plus gros besoins ont rapidement émergé du côté des images médicales », selon Henri Maître. « Dans les années soixante, on a assisté à un fabuleux essor de la radiologie, en particulier des radiographies pulmonaires. À cette époque, en France, quelque 40 millions de radiographies étaient prises par an. » Autant d’images qu’il fallait ensuite analyser pour détecter des tumeurs, des anomalies… On pratiquait aussi de plus en plus d’examens de sang, de cellules, de tissus.
« Dans les années soixante-dix, nous avons tenté de développer des caméras pour analyser les plaquettes sanguines », explique Marc Berthod. « Il fallait déterminer le taux de plaquettes saines après décongélation dans des prélèvements congelés destinés à des transfusions sanguines. Les médecins savaient les reconnaître sur des images de microscopes, en particulier en fonction de leur forme, de leurs contours. Pourtant, nous ne sommes pas parvenus à trouver des algorithmes suffisamment fiables pour automatiser cette détection », regrette t-il.
L’idée était de faire une présélection des images, pour limiter le travail des médecins à une ultime expertise. « Le fait est que, malgré le travail entre 1960 et 1965 de nombreux radiologues et cytologistes (spécialistes de l’étude des cellules), comme les professeurs Jacques-Louis Binet (Hôpital de la Pitié Salpêtrière, Paris), Jean-Louis Lamarque à Montpellier, Maurice Laval-Jeantet et Emmanuel A. Cabanis à Paris, ou les professeurs Jean-Marie Scarabin et Jean-Louis Coatrieux à Rennes, ces tentatives d’interprétation d’images médicales, très en pointe à leur époque, ont échoué », ajoute Henri Maître. Il s’est avéré quasi impossible de remplacer l’œil averti d’un expert par un ordinateur. Les modélisations étaient trop complexes à mettre au point. Les travaux continuent néanmoins.
« L’imagerie médicale a finalement investi le monde du diagnostic », poursuit-il. « Les scanners ou l’IRM (Imagerie par résonance magnétique), techniques qui se sont développées grâce aux travaux de l’époque, nous permettent désormais d’étudier l’intérieur du corps humain aussi bien que l’on examinait l’extérieur. » Dans le monde entier, les chercheurs planchent sur des images aussi complexes que celle du cerveau (imagerie cérébrale fonctionnelle). « Ces travaux en imagerie médicale sont aussi à la base de l’essor de la robotique médicale : le chirurgien peut être guidé dans son intervention grâce à une reconstitution tridimensionnelle des organes » ajoute Marc Berthod.
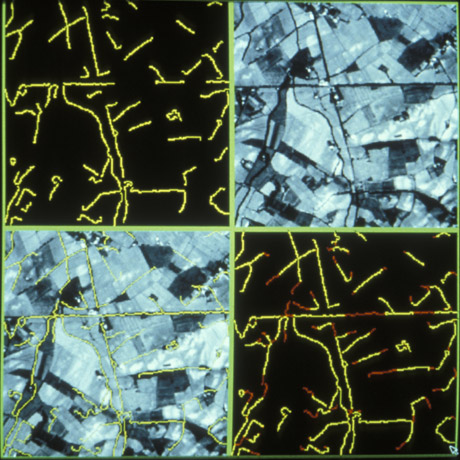
Interprétation d’une image aérienne.
Dans les années 1960, les images prises du ciel (imagerie aérienne ou satellitaire) se multipliaient aussi. « On pouvait en tirer une multitude d’informations comme la progression de la désertification d’une région, l’évolution des zones urbaines ou des informations tactiques pour les militaires », précise Serge Castan. « Entre 1960 et 1965, les Américains ont beaucoup investi dans ce domaine pour leur défense », selon Henri Maître. « Leurs travaux sur l’amélioration et l’interprétation d’images numériques spatiales se sont révélés de très bonne qualité. On sait aussi depuis peu que les Russes relevaient ce même défi, à la même époque, mais à partir d’observation visuelle d’hommes embarqués dans des satellites. Ils ont beaucoup étudié les performances du système visuel humain dans l’espace mais, du coup, n’ont pas développé autant les algorithmes de reconnaissance de forme. »
3. La reconnaissance de forme, clé de la compréhension de l’image
Or que ce soit pour déchiffrer un texte dactylographié ou manuscrit, pour compter des chromosomes, reconnaître une tumeur, un char ou un avion de guerre, la compréhension de l’image, sa classification passe toujours par la reconnaissance d’une forme. « Plusieurs approches théoriques ont été développées », explique Olivier Faugeras.

Détection de contours dans une scène de bureau.
L’image originale suivie de l’image calculée.
« Les premières consistaient à faire des calculs à partir de l’image et construire des représentations symboliques de plus en plus complexes, d’abord en deux dimensions tel que sur l’image, puis tridimensionnelles, pour tenter de restituer une description proche de notre propre vision. » Un peu partout dans le monde, les chercheurs ont mis au point des méthodes mathématiques permettant de détecter les contours des objets à partir des changements rapides de contraste dans l’image, des ombres et des lumières, des régions homogènes en couleur, en intensité, en texture.
« Dès 1964, des chercheurs français, Georges Matheron (1930-2000) et Jean Serra, ont développé une autre approche théorique (baptisée morphologie mathématique) et un outil spécifique (l’analyseur de texture breveté en 1965, ndlr) d’abord pour analyser des microphotographies de terrain et évaluer des teneurs en minerai, puis pour d’autres applications comme la cytologie (caractérisation et comptage de cellules) » rappelle Olivier Faugeras. En 1968, ils créent le Centre de morphologie mathématique de l’Ecole des Mines de Fontainebleau. Leurs outils d’analyse et d’interprétation d’images sont longtemps restés franco-français, jusqu’à ce qu’un américain, Robert Haralick (Université du Kansas à cette époque, de Seattle actuellement), en fasse une large publicité dans les années quatre-vingts, en les adaptant à de nombreuses applications : industrielles comme l’inspection radiographique des ailes d’avions de Boeing, aériennes ou médicales.
D’autres chercheurs, comme les américains Marvin Minsky et Seymour Papert du MIT (Massachussets Institute of Technology) ont considéré le problème dans l’autre sens, en cherchant à formaliser et à faire reproduire par l’ordinateur notre propre processus de reconnaissance d’images, donc notre propre vision. Cette démarche était dans l’air du temps, au cœur des promesses de « l’intelligence artificielle » qui devait permettre de mettre l’intelligence en équations et doter les ordinateurs de toutes les capacités humaines de raisonnement, mémoire, perception. Or la vision s’est révélée être un domaine particulièrement complexe à modéliser tant elle est basée sur une quantité phénoménale de connaissances a priori fondées sur notre intelligence et notre expérience.
À la fin des années cinquante, les Américains Marvin Minsky et Seymour Papert, chercheurs au MIT (Massachussets Institute of Technology), demandent un été à quelques étudiants de formaliser la perception visuelle pour l’intégrer au perceptron, un des premiers outils d’intelligence artificielle, développé en 1960 par Frank Rosenblatt (Université de Cornell, USA). « À cette époque », rappelle Olivier Faugeras, « on ne se rendait pas compte des « calculs » énormes que notre cerveau réalise pendant les quelques millisecondes qui nous suffisent à analyser une scène. On avait encore l’illusion que c’était facile. Minsky a assurément été influencé par cette erreur de jugement. » À l’instar des ambitions de ces chercheurs pour formaliser la vision, l’engouement de l’époque pour ce type de problématique a conduit beaucoup de recherches à l’échec.
4. De l’interprétation des images à la vision par ordinateur
« Un grand nom de la vision par ordinateur est assurément David Marr (1945-1980) », rappelle Radu Horaud. « Ce neurophysiologiste et mathématicien anglais qui travaillait aussi au MIT a été un des premiers à définir les bases formelles de la vision par ordinateur en intégrant des résultats issus de la psychologie, de l’intelligence artificielle et de la neurophysiologie. Selon son formalisme : dans un premier temps, on observe ce que l’on peut détecter, une vision « brute » de l’image. Dans un second temps, on perçoit ce qu’on désire voir, une vision abstraite qui nous permet de reconnaître comme tel un chien, une table ou la tour Eiffel. C’est là que nous faisons appel à notre intelligence, notre mémoire, nos connaissances a priori. » À ce titre, David Marr a jeté les bases des sciences cognitives.
« David Marr avait coutume d’illustrer les bases du formalisme mathématique qu’il a développé grâce à l’image d’un dalmatien dans la neige », raconte Radu Horaud. « Sans connaissance a priori, l’observateur n’y perçoit que des taches noires sur un fond blanc. Passer de ces contrastes à l’identification formelle d’un chien requiert intelligence et mémoire. » Autant de capacités innées, particulièrement complexes à formaliser.
« La vision par ordinateur s’est aussi développée selon une autre approche, initiée par des chercheurs comme Lawrence G. Roberts, qui selon moi a inventé la discipline lors de sa thèse en 1965 au MIT », considère Olivier Faugeras. « Il est parvenu à produire des représentations en 3 dimensions de polyèdres simples à partir d’une image en 2 dimensions. C’est aussi à ce titre un précurseur de la synthèse d’images. » La vision par ordinateur s’est ainsi d’abord développée à partir de reconnaissance de formes simples et abstraites comme des cubes ou des polyèdres dont on détectait les sommets et les côtés. Par la suite, des images numérisées ont progressivement été utilisées au gré des possibilités des ordinateurs.
Cet art japonais du papier plié a été un des premiers terrains d’essai de la vision par ordinateur. Comment faire interpréter à un ordinateur un mode d’emploi en deux dimensions, pour lui permettre de construire l’objet (une cocotte en papier, un avion, un cygne…) en trois dimensions ? De la résolution de ces problématiques sont issus les développements actuels de vision en robotique, par exemple pour les équipements de détection d’obstacles dans les automobiles.
« À cette époque, peu de recherches théoriques étaient menées en Europe », selon Olivier Faugeras. « Elles étaient surtout faites aux États-Unis, au MIT ou dans des universités comme Maryland près de Washington (où enseignait Azriel Rosenfeld), Amherst (Massachusetts), Stanford (avec Thomas Binford et ses célèbres élèves dont Rodney A. Brooks qui dirige actuellement le laboratoire d’intelligence artificielle du MIT). Les chercheurs européens partaient aux États-Unis et revenaient souvent dans leur pays créer des équipes de recherche en vision par ordinateur, traitement d’images, intelligence artificielle… » Tel fut d’ailleurs le cas d’Olivier Faugeras qui est entré à l’INRIA, Institut national de recherche en informatique et en automatique, (alors IRIA) en 1976, après un séjour de quelques années à l’université d’Utah.

Olivier Faugeras en 1978 fait un exposé sur le traitement numérique des images.
5. Le traitement d’images au gré des ordinateurs
« Pour autant, ce n’est que dans les années quatre-vingts que ces théories ont réellement commencé à être développées », considère Henri Maître. « Avant, les ordinateurs étaient beaucoup trop limités en mémoire et vitesse de calcul pour traiter des images. On utilisait des formules mathématiques simplifiées à l’extrême. On passait autant de temps à faire de l’électronique pour parvenir à afficher nos images qu’à les interpréter. D’ailleurs la moitié de la littérature scientifique était consacrée à ces aspects électroniques. » Les chercheurs devaient par exemple afficher leurs images sur des listings papier collés. « Pour parvenir à stocker une image dans l’ordinateur, il fallait prendre son temps », ajoute Serge Castan : « rien à voir avec les appareils photo numériques actuels capables de stocker des millions de pixels en quelques centièmes de seconde. Il fallait plusieurs secondes pour numériser une image. »
Pas d’images en couleur évidemment à cette époque mais du noir et blanc. Un des moyens les plus communs d’afficher des images consistait à les imprimer sur de grands listings. « On parvenait à obtenir 5 à 10 niveaux de gris en imprimant des caractères superposés », se souvient Henri Maître. « Ensuite, chaque listing comptant 128 caractère par ligne, il fallait donc en juxtaposer deux pour reconstituer nos images de 256×256 caractères à l’époque. Cela représentait d’énormes quantités de listing à coller. »
À la demande d’Olivier Faugeras, l’IRIA est un des premiers laboratoires français à avoir fait l’acquisition, en 1976, d’un ordinateur digne de ce nom : un ordinateur 32 bits avec une mémoire de 512 ko. (Aujourd’hui, le moindre ordinateur en a au moins 1000 fois plus.) « Quand je suis arrivé à l’IRIA, nous avions un vieil ordinateur qui se programmait au « fer à souder », comme on disait », se rappelle Olivier Faugeras. « En décrivant les performances des ordinateurs sur lesquels on travaillait aux États-Unis, j’ai facilement convaincu mon patron de l’époque, Jacques-Louis Lions, d’investir dans une autre machine beaucoup plus puissante. Nous avons ensuite dû consacrer près d’un an pour la programmer. Tout était à concevoir. »
« Avant de disposer d’ordinateurs programmables, il fallait écrire les programmes et les taper sur des cartes perforées », raconte Radu Horaud. « Ils étaient ensuite lus par une machine pour être transmis à l’ordinateur. » C’était il y a trente ans. « On chargeait la machine de ces paquets de cartes le matin », ajoute Serge Castan. « À midi, on pouvait espérer avoir le résultat. »
Marc Berthod ajoute : « Nous avons équipé notre ordinateur 32 bits d’un coûteux processeur spécialisé permettant d’effectuer certains calculs élémentaires à la volée. En revanche, il fallait encore 30 secondes à une minute pour faire de la reconnaissance de forme sur une image, à cause de la complexité des traitements nécessaires. »
Rien à voir avec les capacités des moindres ordinateurs et autres appareils portables actuels, capables de traiter des images presque instantanément. Néanmoins, même les ordinateurs les plus récents ne sont pas encore assez performants pour résoudre certains problèmes, en particulier en imagerie médicale. Les quantités d’informations à stocker et à traiter restent problématiques, par exemple pour expertiser un cœur qui bat, la nature bénigne ou maligne d’une tumeur, ou pour répondre aux problèmes les plus complexes de vision par ordinateur, ceux qui nécessitent une analyse comparable à celle de notre intelligence. En revanche, beaucoup d’applications sont déjà courantes comme les traitements sur les images des appareils photo numériques que chacun peut faire sur son ordinateur personnel, ou les effets spéciaux au cinéma pour mélanger des images virtuelles tridimensionnelles à une scène.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
