Les débuts d’une approche scientifique des systèmes d’exploitation
1. La notion de virtualisation

L’IBM 704, un ordinateur typique des années 1950.
© Lawrence Livermore National Laboratory, via Wikimedia Commons
Trois dates marquent les débuts de l’histoire des systèmes d’exploitation :
- 1951 : livraison des premiers ordinateurs commerciaux.
- 1956 : réalisation du premier système d’exploitation, un moniteur de traitement par lots pour l’IBM 704, par des ingénieurs de General Motors et North American Aviation.
- 1967 : première édition de la conférence ACM Symposium on Operating Systems Principles (Principes des systèmes d’exploitation), devenue la principale conférence scientifique du domaine.
Un lecteur pressé pourrait en conclure que les ordinateurs ont été gérés pendant cinq ans par des procédures manuelles et que les systèmes d’exploitation des dix années suivantes ont été réalisés sans l’aide de principes scientifiques. Cette dernière affirmation, un peu abrupte, n’est pourtant pas loin de traduire la réalité, une situation qui explique la réputation de « pratiquants de magie noire » longtemps attachée aux programmeurs des systèmes [1].
Rappelons que le système d’exploitation d’un ordinateur a deux fonctions complémentaires (voir le document La naissance des systèmes d’exploitation) : fournir aux utilisateurs une interface plus commode que celle de la machine physique pour réaliser et exploiter leurs applications ; gérer les ressources de cette machine pour les allouer aux activités qui en ont besoin.
L’interface présentée aux utilisateurs par un système d’exploitation est celle d’une machine virtuelle, image idéalisée de la machine physique sous-jacente. La notion de virtualisation est centrale pour comprendre le fonctionnement des systèmes, et c’est d’abord à partir de cette notion qu’est née, dans les années 1965-70, l’approche scientifique des systèmes d’exploitation.
En informatique, la virtualisation est une opération qui met en correspondance un objet concret (physique) et un objet abstrait (virtuel), image idéalisée du premier. C’est d’abord un outil intellectuel qui facilite la conception d’un système informatique. L’association virtuel-physique trouve ensuite une mise en œuvre concrète dans la phase de réalisation.
La virtualisation peut s’exercer de deux manières :
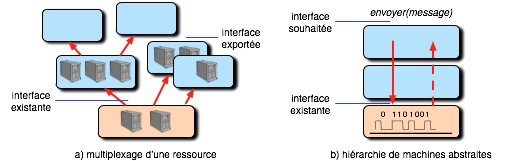
Figure 1. Les deux aspects de la virtualisation.
- dans le sens ascendant (figure 1a). On dispose d’une ressource physique que l’on distribue à un ensemble d’utilisateurs par multiplexage (attribution de la ressource aux demandeurs par tranches de temps successives), créant ainsi des ressources virtuelles. C’est ainsi que l’on parle de processeur virtuel, de mémoire virtuelle, de machine virtuelle, des notions examinées en détail dans la suite. L’interface exportée, celle des ressources virtuelles, peut être identique à celle de la ressource physique, ou peut en être différente. Une ressource virtuelle peut elle-même être virtualisée (c’est-à-dire partagée) ;
- dans le sens descendant (figure 1b). On souhaite réaliser un composant fournissant une certaine interface (dans l’exemple illustré, un envoi de message). On dispose d’un composant fournissant une interface différente (dans l’exemple, une liaison physique de bas niveau). Pour fournir l’interface souhaitée, on définit une hiérarchie descendante de composants qu’on appelle machines abstraites, chacune utilisant la suivante et la dernière s’appuyant sur l’interface existante. La conception procède ainsi par raffinements successifs avec des va-et-vient éventuels.
La virtualisation s’est révélée un outil précieux pour la compréhension et la construction des systèmes d’exploitation, dans lesquels le partage des ressources par multiplexage est un mécanisme central. En outre, la réalisation d’un système fait souvent appel à la décomposition hiérarchique, qui permet de traiter indépendamment ses différentes fonctions, qui relèvent elles-mêmes de la virtualisation. La première illustration de cette démarche a été apportée par l’informaticien Edsger Dijkstra dans un article [2] resté célèbre.
2. Virtualisation des processeurs et de la mémoire
Virtualisation du processeur
Le premier objet virtualisé fut le processeur — on parlait à l’époque d’unité centrale — l’organe d’exécution de la suite d’instructions qui constituent un programme. L’intérêt de la virtualisation vient du fait qu’on demande au processeur d’exécuter concurremment plusieurs tâches. Contrairement à ce qu’on pourrait croire, c’est toujours le cas, même quand l’ordinateur n’a qu’un utilisateur unique. En effet, cet utilisateur fait souvent fonctionner plusieurs applications en parallèle (consulter sa messagerie, éditer un document, chercher sur le Web, etc.). Et même dans le cas où il n’exécute qu’une seule application, le processeur doit gérer les communications — échanges sur le réseau, transferts vers le disque dur, gestion de l’écran et du clavier, etc. — même si l’essentiel du travail est délégué à des organes auxiliaires.
Le passage du processeur d’une tâche vers une autre se fait par un mécanisme appelé interruption : un signal est envoyé au processeur, qui suspend l’exécution de la tâche en cours, sauvegarde les données nécessaires à sa reprise ultérieure, reprend les données relatives à la nouvelle tâche et entame l’exécution de celle-ci. En l’absence de précautions particulières, cette interruption peut survenir à un moment quelconque. Elle est déclenchée par une cause extérieure à la tâche en cours, qui peut donc être interrompue en n’importe quel point de son exécution. Les causes d’interruption peuvent être, par exemple, un signal d’horloge marquant la fin d’un temps d’exécution fixé, ou un signal de fin de transfert sur un disque, etc. Ainsi, si plusieurs tâches utilisent le processeur, ce dernier exécutera alternativement des séquences d’instructions de ces tâches (en bleu sur la figure 2 ci-dessous).
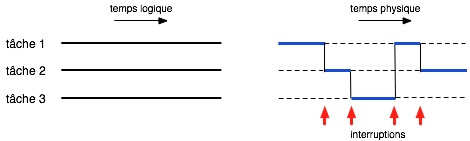
Figure 2. Exécution de tâches sur un processeur.
Ces tâches sont logiquement parallèles, au sens où elles sont simultanément en cours d’exécution. Mais sur le plan physique, le processeur n’exécute à un instant donné qu’une seule de ces tâches, les autres étant en attente (on parle alors de pseudo-parallélisme). Pour avoir un parallélisme réel, il faudrait disposer d’autant de processeurs que de tâches.
Utilisé sans autres précautions, ce mode de fonctionnement présente un risque potentiel que nous illustrons par l’exemple d’un ordinateur gérant des comptes bancaires. Imaginons que deux personnes, à partir de points d’accès différents, effectuent au même moment une opération sur un même compte (ici le compte n°867A). La première dépose 1 000 €, la seconde dépose 3 000 €. Ces deux opérations constituent deux tâches, dont nous donnons ci-dessous le programme. On notera que ce programme de dépôt est identique pour les deux tâches, mais que chacune utilise ses propres variables de travail, respectivement courant1, nouveau1 et courant2, nouveau2.

Supposons maintenant que l’exécution de ces deux tâches suive un schéma analogue à celui de la figure 2, et que leurs instructions respectives soient exécutées dans l’ordre suivant :
1.1 ; 1.2 ; 2.1 ; 2.2 ; 2.3 ; 1.3
On voit alors que le résultat final a été d’augmenter le montant du compte de 1 000 €, alors que l’effet attendu était une augmentation de 4 000 € : l’une des mises à jour a été perdue !
On pourra objecter que cet exemple est artificiel et que la probabilité d’occurrence d’une telle situation est extrêmement faible. C’est peut-être vrai dans ce cas particulier ; mais d’une part, une telle erreur n’est pas admissible, d’autre part, il faut surtout remarquer que les entrées-sorties produisaient chaque seconde des dizaines d’interruptions sur les premiers ordinateurs qui exécutaient pendant ce temps des dizaines de milliers d’instructions. La probabilité de survenue d’une incohérence au cours d’une journée devenait alors non négligeable. Et de fait, les premiers systèmes d’exploitation étaient sujets à des pannes aléatoires non-expliquées, que l’on attribuait à des défaillances transitoires du matériel alors moins fiable que de nos jours. En réalité, il s’agissait souvent d’erreurs de synchronisation lors d’un transfert, entraînant une perte d’information et une incohérence de l’état interne du système. Mais l’analyse ci-dessus n’avait pas été faite.
En 1965, Edsger Dijkstra publie l’article fondateur [3] de la théorie de la synchronisation, en introduisant la notion de processus, une activité séquentielle autonome pouvant interagir avec d’autres processus. Il formalise ainsi la notion intuitive de « tâche », un travail confié à un ordinateur, en séparant la description du travail à effectuer par une machine (le programme) de l’entité dynamique et évolutive dans le temps que constitue son exécution (le processus). Cette différence est comparable à celle qu’il y a entre la description d’une recette dans un livre de cuisine et son exécution concrète avec l’utilisation d’ingrédients et d’ustensiles divers.
On peut dès lors séparer l’aspect fonctionnel du processus, la description de ce qu’il fait, de la gestion des ressources nécessaires à son exécution : de ce point de vue fonctionnel, le processus peut être vu comme s’exécutant sur un processeur virtuel toujours disponible, un processus en attente s’exécutant à vitesse nulle. On dissocie ainsi l’activité logique, la seule intéressante pour l’utilisateur, des contingences matérielles de son exécution et notamment de l’allocation d’un processeur réel. Ces derniers aspects ne disparaissent pas, mais ils sont du ressort du système d’exploitation et demeurent invisibles à l’utilisateur. Ne restent alors à régler pour ce dernier que les interactions voulues entre plusieurs processus, telles que l’échange d’information ou la création de sous-processus pour décomposer un travail en unités élémentaires.
Qu’il s’agisse de compétition entre processus pour l’allocation de ressources au niveau du système d’exploitation, ou de coopération au niveau logique, il faut identifier et régler les cas d’incohérence potentielle tels que celui illustré plus haut. Dans cet exemple, la solution consiste à imposer qu’une seule des séquences d’instructions présentées puisse s’exécuter à la fois, chacune d’elle étant « atomique » (non sécable). Ainsi, leur effet global ne peut être que celui résultant de l’exécution de ces séquences l’une après l’autre, tout entrelacement étant exclu.
Les problèmes de synchronisation entre processus peuvent être réduits à un petit nombre de situations simples, dont celle illustrée ci-dessus appelée exclusion mutuelle. Ces problèmes ont été élégamment résolus par divers mécanismes, dont les sémaphores, inventés par Dijkstra en 1965, et les moniteurs, à un niveau plus élevé d’expression, introduits au début des années 1970 par les informaticiens C. A. R. Hoare et Per Brinch Hansen. Plus tard, la notion d’exécution atomique a été étendue pour couvrir les cas de défaillance, grâce à la notion de transaction, due à Jim Gray. Cette notion est maintenant standard dans tous les systèmes de gestion de bases de données.
Des processus parallèles peuvent avoir des relations de compétition pour l’accès à des ressources partagées ou de coopération pour l’exécution d’un travail commun. Le bon fonctionnement de ces relations exige de satisfaire des contraintes pour éviter les incohérences, telles que celle mise en évidence dans l’exemple de l’application bancaire. La synchronisation vise à organiser les relations entre processus en vue de respecter les contraintes imposées. En dernier ressort, elle est réalisée en faisant attendre un processus, c’est-à-dire en arrêtant temporairement sa progression, jusqu’à ce qu’il puisse reprendre son exécution sans violer les contraintes spécifiées.
Initialement, la synchronisation était réalisée par des mécanismes de bas niveau, utilisant des instructions spéciales ne pouvant être exécutées que dans un mode dit « superviseur » réservé au système d’exploitation.
Le premier outil de synchronisation de niveau plus élevé, accessible aux programmes d’application, est constitué par les sémaphores, introduits en 1965 par Edsger Dijkstra. Un sémaphore réalise l’effet d’une barrière, bloquante dans certaines conditions. Intuitivement, un sémaphore fonctionne comme un portillon automatique actionné par des jetons. Quand il n’y a pas de jetons dans l’appareil, le portillon est bloqué, et une file d’attente se forme à l’entrée. Quand on dépose un jeton et que des personnes attendent, le portillon s’ouvre et laisse passer une (et une seule) de ces personnes, et le jeton est consommé (il disparaît). On peut déposer des jetons d’avance : le portillon laissera ensuite passer autant de personnes qu’il y a de jetons (consommant ces jetons), et se bloquera quand il n’y aura plus de jetons.
Dans le monde des processus, un sémaphore (soit s) est associé à un compteur entier (soit ns) ; si ns est positif, le portillon est débloqué et la valeur de ns indique le nombre de « jetons » présents dans l’appareil (dans l’analogie du portillon) ; s’il est négatif ou nul, alors le portillon est bloqué, et la valeur absolue de nsindique la longueur de la file d’attente. Lorsqu’on crée un sémaphore, on donne à nsune valeur initiale, qui est positive ou nulle (c’est le nombre initial de jetons dans l’appareil).
Deux opérations sont associées à un sémaphore s et peuvent être exécutées par un processus ; nous les décrivons avec l’analogie du portillon :
- attendre(s) : le processus (soit p) tente de franchir le portillon associé à s. Si nsest positif (il y a des jetons dans l’appareil), p continue son exécution (il franchit le portillon) et un jeton est consommé. Sinon, p se bloque (entre dans la file d’attente), et doit attendre qu’un autre processus le débloque au moyen de l’opération décrite ci-dessous. Dans tous les cas, ns est diminué de 1.
- libérer(s) : cette opération revient à introduire un jeton dans le portillon associé au sémaphore s. S’il y avait une file d’attente devant ce portillon, l’un des processus en attente peut passer et continuer son exécution, et le jeton est consommé. Sinon, le jeton s’ajoute à ceux qui étaient déjà dans l’appareil. L’opération libérer n’a aucun effet sur le processus qui l’exécute (elle n’est jamais bloquante). Dans tous les cas, nsest augmenté de 1.
Nous illustrons l’usage des sémaphores au moyen de deux exemples.
Le premier exemple est celui de l’exclusion mutuelle, illustré par l’application bancaire décrite dans le corps de l’article. Plusieurs processus s’exécutent en parallèle. Dans le programme de chacun d’eux, on définit une séquence, dite section critique, telle qu’un seul processus au plus puisse être, à un instant donné, en train d’exécuter sa section critique. Le problème est simplement résolu en définissant un sémaphore (appelons-le mutex, pour « mutuelle exclusion »), dont le compteur est initialisé à 1 (il y a initialement un jeton dans l’appareil). Le programme des processus s’écrit alors ainsi :

Avec l’analogie du portillon, le premier processus qui se présente à l’entrée peut passer (un jeton est présent et il est consommé). Tant que le processus est dans la section critique, le portillon est bloquant car il n’y a pas de jeton. À la sortie de la section critique, le processus remet un jeton dans l’appareil, qui laissera donc passer le processus suivant.
Le bon fonctionnement de ce dispositif exige que, lorsque deux processus exécutent « simultanément » attendre(mutex) — c’est-à-dire qu’ils se présentent ensemble à l’entrée du portillon —, l’un d’entre eux et un seul puisse effectivement passer. Une condition analogue vaut pour libérer. L’implémentation des sémaphores doit garantir ces conditions, ce qui revient à dire que l’exécution des opérations attendre et libérer doit elle-même se faire en exclusion mutuelle.
On peut généraliser ce schéma d’exécution en initialisant le sémaphore mutex à une valeur ksupérieure à 1 (mettant donc k jetons dans l’appareil). Alors k processus au plus pourront simultanément exécuter leur section critique.
Le second exemple que nous proposons est celui du fonctionnement d’une imprimante. Un processus éditeur envoie du texte à imprimer à un processus imprimeur qui commande l’imprimante. L’intérêt d’avoir deux processus est que l’imprimante puisse fonctionner en parallèle avec le processeur, qui pourra alors exécuter d’autres applications. Comme le processus éditeur fournit des données plus vite que l’imprimeur ne peut les consommer (l’imprimante étant beaucoup plus lente que le processeur), on interpose entre les deux processus une zone de mémoire appelée « tampon », suite d’emplacements (ou cases) dont chacun contient une page. L’éditeurdépose des pages dans le tampon, et ces pages sont prélevées par l’imprimeur qui libère les cases correspondantes.
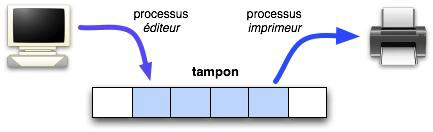
Les contraintes de synchronisation entre ces deux processus s’expriment ainsi :
- L’éditeur ne peut déposer une page dans le tampon que si celui-ci n’est pas plein, c’est-à-dire s’il contient au moins une case libre. Autrement, il « écrasera » une page encore non imprimée.
- L’imprimeur ne peut retirer une page du tampon que si celui-ci n’est pas vide, c’est-à-dire s’il contient au moins une page destinée à être imprimée, et qui ne l’a pas encore été.
Si l’une de ces conditions n’est pas satisfaite, le processus correspondant doit se bloquer en attendant qu’elle le soit ou que la totalité des pages soit imprimée.
Le programme suivant réalise cette synchronisation. On définit deux sémaphores nvide et nplein, dont les compteurs dénotent respectivement, à un instant donné, le nombre de cases vides et le nombre de pages à imprimer dans le tampon. La valeur initiale de nvide est N (le nombre de cases du tampon), celle de nplein est 0.

Les opérations déposer et retirer gèrent le tampon en assurant que les pages sont retirées dans l’ordre où elles ont été déposées (la méthode la plus simple est de considérer le tampon comme circulaire, le successeur de la dernière case étant la première). On vérifiera que ce programme réalise bien la synchronisation spécifiée. On notera que les deux sémaphores nvide et nplein jouent un rôle symétrique : en effet, l’éditeur crée dans le tampon des cases pleines et consomme des cases vides, alors que l’imprimeur y crée des cases vides et consomme des cases pleines.
Ce mode de synchronisation s’étend aisément au cas de plusieurs processus producteurs de pages à imprimer et d’imprimantes multiples. Il est à la base de nombreux mécanismes utilisés dans les systèmes d’exploitation, comme les échanges avec les fichiers, ainsi que les « tubes » servant à la communication entre processus dans le système Unix.
Les sémaphores sont en général réalisés par programme dans le noyau d’un système d’exploitation. Des propositions ont été faites pour les réaliser matériellement par microprogramme. Au moins deux ordinateurs conçus dans les années 1970 disposaient de tels sémaphores : le Honeywell (plus tard Bull) Series 60 level 64, déjà mentionné, et le Solar 16-65 de SEMS, destiné à la commande de procédés industriels.
- Edsger W. Dijkstra (1930-2002), mathématicien et informaticien néerlandais. Il est connu pour des avancées décisives dans le domaine des systèmes d’exploitation (modèle en couches du système THE, mise en évidence de la notion de processus, invention des sémaphores), mais aussi pour sa contribution au domaine des langages, de l’algorithmique et de la conception raisonnée des programmes. Il a reçu le prix Turing en 1972.
- Fernando J. Corbató (né en 1926), informaticien américain, a dirigé la conception et le développement des premiers systèmes en temps partagé : CTSS (1961), puis Multics (1965), projet qui a joué un rôle fondateur dans le domaine des systèmes d’exploitation. Il a reçu le prix Turing en 1990.
- Jack B. Dennis (né en 1931) est un informaticien américain, qui a apporté des contributions dans les domaines de l’architecture des ordinateurs, des systèmes d’exploitation et de la théorie du calcul. Il est notamment connu pour l’introduction de la segmentation, modèle de structuration de la mémoire virtuelle et pour ses travaux sur la sécurité. Il a reçu le prix Eckert-Mauchly en 1984 et la médaille IEEE John von Neumann en 2013.
- Charles Anthony Richard (« Tony ») Hoare (né en 1934), informaticien britannique. Il a apporté des contributions dans plusieurs domaines : algorithmique (l’algorithme de tri rapide quicksort), langages, logique de la programmation. Dans le domaine des systèmes d’exploitation, il a introduit la notion de moniteur (outil de synchronisation) et inventé un modèle de communication entre processus (CSP). Il a reçu le prix Turing en 1980.
- Per Brinch Hansen (1938-2007) est un informaticien danois qui a fait une grande partie de sa carrière aux États-Unis. Il est notamment connu pour sa contribution à l’invention des moniteurs (avec C. A. R. Hoare), pour la conception du calculateur RC 4000 et du noyau de son système d’exploitation (structuration rigoureuse d’un système de commande en temps réel), et pour la création de plusieurs langages de programmation pour processus parallèles (dont Concurrent Pascal). Il a reçu le IEEE Computer Pioneer Award en 2002.
- Peter J. Denning (né en 1942) est un informaticien américain, connu pour ses contributions dans le domaine de la mémoire virtuelle : modèle de l’espace de travail (working set) pour le comportement des programmes, explication du phénomène de l’écroulement.
- Dans un domaine connexe : James (« Jim ») Gray (1944-2007) est un informaticien américain connu pour ses travaux sur la tolérance aux fautes par redondance matérielle et logicielle, et pour l’invention du concept de transaction, qui généralise le modèle d’action atomique pour prendre en compte les défaillances. Les transactions sont un outil essentiel pour tous les traitements comportant des accès à des bases de données. Il a reçu le prix Turing en 1998.
Ces problèmes de synchronisation connaissent depuis quelques années un regain d’actualité avec l’apparition des processeurs multicœurs qui introduisent le parallélisme à un niveau beaucoup plus fin que dans les situations antérieures.
L’allocation de ressources (processeur, mémoire) aux processus peut par ailleurs donner lieu à deux phénomènes indésirables qui ont été identifiés et compris dès la fin des années 1960 :
- l’interblocage (en anglais deadlock), qui se traduit par le blocage mutuel de plusieurs processus, dont chacun attend des ressources occupées par les autres ;
- la privation, qui résulte de l’usage de priorités : un processus de faible priorité peut voir ses demandes indéfiniment retardées par une arrivée continue de processus plus prioritaires. En outre, l’usage de priorités peut donner lieu à un autre phénomène indésirable, plus subtil à analyser, l’inversion de priorités, dans lequel l’ordre d’exécution des processus n’est pas conforme aux priorités qui leur sont attachées.
Divers remèdes sont connus, dont les plus usuels reposent sur l’utilisation d’un ordre : l’interblocage est évité si tous les processus demandent leurs ressources dans le même ordre ; la privation est évitée si les processus sont servis dans l’ordre de leur arrivée ; si on veut néanmoins utiliser des priorités, on peut faire croître la priorité d’un processus avec son temps d’attente.
Virtualisation de la mémoire
Dans les premiers ordinateurs, la mémoire centrale était une ressource coûteuse, donc peu abondante. Même dans les applications mono-utilisateurs, elle était souvent trop petite pour contenir l’ensemble des programmes et des données. Les programmeurs devaient alors recourir à des schémas d’exécution avec recouvrement (overlay), où un découpage ingénieux des programmes permettait de les charger par « tranches » à la demande depuis une mémoire secondaire de grande capacité (tambour ou bande magnétique). Cela causait un surcroît de travail non négligeable pour les programmeurs et pénalisait le temps d’exécution.
Une avancée décisive fut réalisée en 1961 à l’université de Manchester, avec le concept de « mémoire à un niveau », mis en œuvre dans l’ordinateur Atlas [4]. Les programmes d’application pouvaient utiliser un espace d’adressage beaucoup plus grand que celui disponible sur la mémoire principale, l’information étant contenue dans l’ensemble constitué par la mémoire principale et la mémoire secondaire à tambour. Deux notions essentielles étaient ainsi introduites :
- la dissociation entre les adresses utilisées par les programmes — nous les appelons « virtuelles » bien que ce terme n’ait été introduit que plus tard — et les adresses physiques des emplacements correspondants en mémoire principale ou secondaire ;
- la gestion automatique par le système d’exploitation, et non par les programmeurs, de la correspondance entre adresses virtuelles et adresses physiques.
Ce dernier aspect impliquait la gestion des transferts entre mémoire principale et mémoire secondaire pour amener en mémoire principale l’information nécessaire, lors de son utilisation. Ce transfert était réalisé par « pages » de taille fixe (512 mots sur l’Atlas). Comme les programmes étaient souvent réutilisés, un algorithme d’apprentissage était mis en place pour réduire le temps global de ces transferts, ses performances étant voisines de celles obtenues par un programmeur expérimenté. Néanmoins, les performances se dégradaient rapidement quand la charge dépassait un certain seuil. Ce phénomène d’« écroulement » ne fut compris et traité qu’en 1968 (voir plus loin).
Dans les années 1965-68 furent posées les bases scientifiques de la mémoire virtuelle, toujours largement en vigueur aujourd’hui [5]. Deux aspects complémentaires furent ainsi approfondis :
- l’organisation et la protection de la mémoire virtuelle, telle que vue par les utilisateurs ;
- la mise en œuvre concrète de cette mémoire, notamment dans les systèmes en temps partagé, qui se développaient rapidement à cette époque.
La figure 3 montre schématiquement le principe de réalisation d’une mémoire virtuelle pour un processus. On a distingué, dans la mémoire physique, la notion de page (contenu) de la notion de case (contenant, ou suite d’emplacements pouvant accueillir une page).
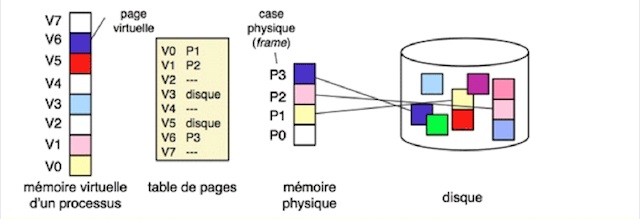
Figure 3. Réalisation d’une mémoire virtuelle.
La mémoire virtuelle peut être plus grande que la mémoire physique mais pas plus grande que la capacité d’adressage du processeur. Une page virtuelle dont le contenu est en mémoire physique est immédiatement accessible. Une page virtuelle dont le contenu n’est que sur disque doit être amenée en mémoire physique pour être accessible ; il faut pour cela lui trouver une case libre. S’il n’y a plus de case libre, il faut en libérer une et donc copier son contenu sur disque s’il a changé.
Dans ce schéma, la mémoire virtuelle est implicitement définie comme un espace unique d’un seul tenant. Un schéma plus élaboré fut proposé en 1965 par Jack Dennis, du MIT [6]. Il repose sur la notion de segment, c’est-à-dire d’unité logique d’information constituée d’une tranche de mémoire de taille variable composée d’emplacements contigus. Un utilisateur peut ainsi organiser ses informations en plusieurs segments (modules de programmes, différentes données, etc.). Des segments peuvent être partagés entre plusieurs utilisateurs. L’accès aux segments doit pouvoir être protégé contre des accès non-autorisés. Le schéma initial (illustré par la figure 3 ci-dessus) devient un cas particulier, celui d’un segment unique de taille fixe.
Avec les performances des processeurs de l’époque, une mise en œuvre efficace de la segmentation supposait qu’elle soit inscrite dans l’architecture même de la machine. Quelques machines à mémoire segmentée furent ainsi réalisées, notamment le GE 645, utilisé par Multics, un système expérimental en temps partagé construit au MIT de 1965 à 1970 en association avec les Bell Labs et General Electric (voir le document La naissance des systèmes d’exploitation). Néanmoins, l’idée d’une architecture à mémoire segmentée ne s’imposa pas généralement. Même si les processeurs actuels permettent d’utiliser des adresses segmentées, les systèmes d’exploitation courants comme Unix ou Windows n’utilisent pas ce mécanisme (sinon pour un usage interne limité).
La notion de segment, gardant toutefois tout son intérêt, est simulée par une voie logicielle, en définissant des tranches de mémoire à l’intérieur d’une mémoire virtuelle unique de grande taille, elle-même réalisée par un mécanisme matériel de pagination. Les systèmes usuels adoptent cette solution et assurent, également par voie logicielle, la protection sélective des segments.
Dans un système multi-utilisateur, comme l’étaient les systèmes en temps partagé du début des années 1970, chaque utilisateur peut exécuter un ou plusieurs processus, dont chacun dispose de sa mémoire virtuelle (comme illustré sur la figure 4 ci-dessous). L’isolation entre mémoires virtuelles est assurée par les tables de pages séparées, conservées par le système d’exploitation dans des zones protégées.
Bien que la mémoire virtuelle soit un outil de travail remarquable, il ne faut pas oublier qu’elle représente en quelque sorte un achat à crédit : pour que son contenu puisse être utilisé, un emplacement de mémoire virtuelle doit recevoir en fin de compte un support réel en mémoire centrale. Cet aspect avait été mal perçu par les concepteurs des premiers systèmes en temps partagé : à force de distribuer abondamment le « crédit », il arrivait un moment où les ressources physiques ne pouvaient plus faire face aux demandes cumulées. C’était le phénomène d’écroulement, qui conduisait à une paralysie complète du système.
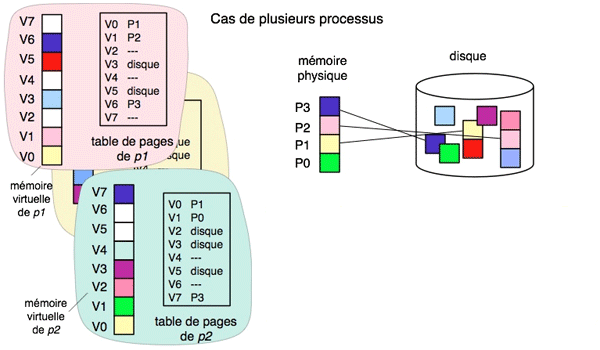
Figure 4. Mémoire virtuelle dans un système multi-utilisateur.
Chaque processus possède sa propre mémoire virtuelle, indépendante de celles des autres processus (il a donc sa propre table de pages). Des processus peuvent partager des pages, à la même adresse (page V0) ou à des adresses différentes (page V6 de p1 et V7 de p2).
Les causes de ce phénomène furent expliquées en 1968 en utilisant un modèle simple de comportement des programmes, et un remède fut trouvé, fondé sur l’observation et la limitation de la charge instantanée de la même manière qu’on traite la congestion d’une autoroute par une restriction temporaire des entrées. Le principe de la limitation de charge est toujours utilisé aujourd’hui, bien que la grande taille des mémoires physiques rende le problème moins aigu.
Dans les années 1966-67, les premiers systèmes en temps partagé utilisant la mémoire virtuelle étaient sujets à un phénomène appelé écroulement (en anglais thrashing), qui survenait quand la charge augmentait. L’écroulement est caractérisé par une forte activité des échanges entre mémoire principale et disque, et une faible activité de l’unité centrale. En conséquence, les processus exécutant les applications, qui partagent l’unité centrale, n’avancent plus qu’à vitesse réduite, et le temps de réponse prend des valeurs inacceptables.
Ce phénomène trouva en 1968 une explication et un remède. On commença par étudier le comportement d’un programme d’application unique dans un environnement comportant une mémoire virtuelle supportée par une mémoire principale et un disque organisés en pages de taille fixe. Le programme est initialement rangé sur le disque avec ses données. L’accès à une instruction ou à une donnée absente de la mémoire — un « défaut de page » — provoque le chargement en mémoire principale de la page qui la contient. Lorsque la mémoire est pleine, une case de mémoire doit être libérée pour accueillir la page à charger. Le choix de cette case est réalisé par un algorithme de remplacement.
L’examen du comportement des programmes d’application en fonction de la taille de mémoire principale mise à leur disposition révéla une tendance largement partagée :
- pour chaque programme, il existe une taille de mémoire critique au-dessous de laquelle l’exécution du programme provoque un taux de défaut de pages très rapidement croissant quand on diminue la taille de la mémoire.
- cette taille critique dépend peu de l’algorithme choisi pour le remplacement des pages. Ainsi, un choix au hasard n’est pas beaucoup plus pénalisant qu’un algorithme qui essaie de minimiser le nombre de transferts.
En d’autres termes, la mémoire allouée à un programme peut être « comprimée » jusqu’à un certain seuil, mais pas en-deçà sous peine d’une dégradation considérable des performances. Ce comportement s’explique si on remarque que chaque programme a un « espace de travail » (en anglais working set, notion due à Peter J. Denning), qui regroupe les instructions et données utilisées dans un certain intervalle de temps. L’expérience montre que ces informations récemment utilisées ont une forte probabilité d’être réutilisées dans un futur proche. C’est le phénomène de « localité », qui résulte notamment de l’usage de boucles, de la réutilisation fréquente de certaines procédures, de l’accès groupé aux données, etc. De manière plus précise, un programme évolue dans le temps entre des « phases » successives séparées par de brèves périodes transitoires, la composition et la taille de l’espace de travail changeant d’une phase à l’autre. Le comportement des programmes en mémoire restreinte peut s’expliquer ainsi : la taille critique n’est autre que la taille moyenne de l’espace de travail.
Le phénomène de l’écroulement trouve alors son explication, au moins qualitative : tant que la mémoire principale peut contenir l’ensemble des espaces de travail des programmes en cours d’exécution, ces programmes s’exécutent normalement. Mais si ce seuil est dépassé (en raison d’une charge trop élevée), les programmes sont « comprimés » au-dessous de leur taille critique, le taux de défauts de page s’envole (et avec lui l’activité des échanges entre mémoire et disque), et l’unité centrale passe l’essentiel de son temps à attendre les informations nécessaires à la progression des programmes, le temps de transfert d’une page depuis le disque étant considérablement supérieur à la durée du cycle d’exécution des instructions.
Le principe de la prévention de l’écroulement était dès lors trouvé : détecter en continu le début de l’écroulement, et réduire alors le nombre de programmes partageant la mémoire jusqu’à retrouver une situation normale. La première mise en œuvre expérimentale de cette idée fut réalisée par IBM sur une installation dédiée à cet effet [ref.]. Nous la décrivons ci-après.
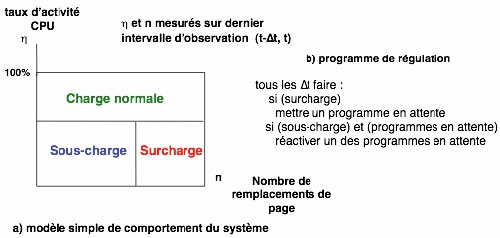
La partie (a) de la figure représente un diagramme d’état simple destiné à caractériser schématiquement l’écroulement au moyen de deux paramètres mesurés périodiquement : le taux d’activité de l’unité centrale et le taux d’activité du canal d’échange entre mémoire et disque. On définit trois zones : charge normale, sous-charge, et surcharge (avec risque d’écroulement). L’objectif de la régulation est d’éviter que le système ne pénètre dans la zone de surcharge, mais sans pour cela entraver le fonctionnement normal. Le programme de régulation (partie b), exécuté périodiquement, fonctionne donc ainsi : si la surcharge est détectée, retirer un programme de l’ensemble de ceux partageant la mémoire ; si le système est en sous-charge et que des programmes attendent (car ils ont été retirés antérieurement), réintégrer un de ces programmes.
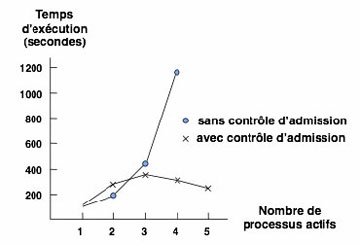
La figure ci-dessus montre l’effet de cette régulation, qui est spectaculaire. En l’absence de régulation, l’écroulement commence au-dessus d’une certaine charge et s’amplifie ; la régulation maintient les performances à une valeur normale.
Tous les systèmes en temps partagé adoptèrent dès lors une forme de régulation directement inspirée de ce schéma, en y ajoutant souvent des améliorations fondées sur une analyse plus fine du comportement des programmes.
[ref.] Brawn, Barbara S., and Gustavson, Frances G. Program Behavior in a Paging Environment. In Proceedings of the AFIPS Fall Joint Computer Conference, pages 1019-1032, 1968.
3. Vers des machines virtuelles
Machines virtuelles et hyperviseurs
Après le processeur et la mémoire, l’étape suivante de la virtualisation est celle d’une machine tout entière. En fait, le terme de « machine virtuelle » recouvre plusieurs modes de fonctionnement. Nous nous intéressons seulement ici à la virtualisation d’une machine complète ; une autre forme de virtualisation, dont nous ne parlerons pas, réalise un mécanisme d’interprétation des langages de programmation.
Le principe d’un système de machines virtuelles, tel qu’il a été introduit par IBM entre 1965 et 1967, est schématisé sur la figure 5 (ci-dessous). Au-dessus d’une machine physique sont réalisées un certain nombre de machines « virtuelles » qui présentent à leurs utilisateurs une interface (jeu d’instructions, système d’interruptions, organes d’entrée-sortie) identique à celle de la machine sous-jacente. Ces machines sont complètement isolées les unes des autres : un programme s’exécutant sur une machine virtuelle ne peut lire ou modifier le contenu d’une autre machine virtuelle ; une défaillance logicielle d’une machine virtuelle n’a aucun effet sur les autres machines.
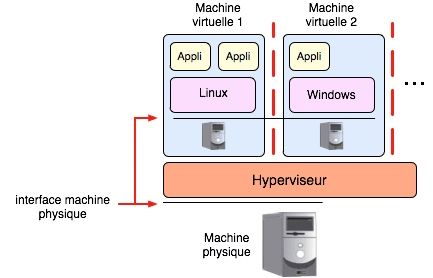
Figure 5. Hyperviseur et machines virtuelles.
La réalisation d’un système de machines virtuelles repose sur un composant logiciel appelé hyperviseur, qui s’exécute directement sur la machine physique, dont il constitue en quelque sorte un « super système d’exploitation ». La réalisation d’un hyperviseur pose des problèmes techniques délicats, car il doit virtualiser l’intégralité de la machine de base, y compris les mécanismes physiques de bas niveau tels que les interruptions, tout en assurant l’isolation mutuelle des machines virtuelles.
À quoi servent les machines virtuelles ? L’isolation mutuelle permet de faire fonctionner plusieurs systèmes d’exploitation différents sur une même machine physique. Néanmoins, la première utilisation des machines virtuelles a consisté à faire exécuter un grand nombre d’instances du même système, chacun servant un utilisateur unique : on simule ainsi un système en temps partagé. C’est le principe du système CP/CMS introduit en 1967 par le centre de recherche d’IBM de Cambridge sur l’ordinateur 360/67, spécialement conçu pour réaliser la mémoire virtuelle. Ce système, qui combinait un générateur de machines virtuelles (CP) et un logiciel interactif d’interprétation de commandes (CMS), exécuté sur chacune des machines, connut un grand succès, alors que le système d’exploitation « officiel » en temps partagé développé par IBM, Time Sharing System (TSS), ne réussit pas à atteindre ses objectifs.
Une extension du principe des machines virtuelles consiste à simuler des machines ayant un jeu d’instructions différent de celui de la machine physique sous-jacente. On peut ainsi expérimenter le jeu d’instructions d’une machine avant de la construire, ou faire exécuter des programmes écrits pour une machine dont on ne dispose pas d’exemplaire physique.
La réalisation d’un système de machines virtuelles pose le problème suivant : chaque machine virtuelle, étant une copie de la machine physique, doit fournir exactement la même interface que cette dernière. Or cette interface comporte des instructions dites « privilégiées », qui touchent aux mécanismes de base de la machine physique : système d’interruptions, commande des entrées-sorties, mémoire virtuelle. Comment réaliser ces instructions en exemplaires multiples tout en évitant les interférences sur le fonctionnement de la machine ? La solution repose sur des détails de mise en œuvre de ces instructions privilégiées.
Pour comprendre les problèmes posés par la réalisation d’un hyperviseur, il faut rappeler certains détails du fonctionnement des ordinateurs de la fin des années 1960 et des systèmes d’exploitation réalisés pour ces machines. Un ordinateur pouvait fonctionner dans deux modes : un mode dit superviseur, dans lequel tout le jeu d’instructions du processeur était disponible, et un mode dit utilisateur, dans lequel étaient interdites certaines instructions dites privilégiéescommandant le fonctionnement de dispositifs « sensibles » de l’ordinateur : interruptions, commande des entrées-sorties, choix du mode, etc. Une grande partie des programmes composant le système d’exploitation s’exécutaient en mode superviseur.
Que se passe-t-il lorsqu’un programme en mode utilisateur essaie d’exécuter une instruction privilégiée ? Est alors actionné un dispositif appelé déroutement, ou trappe, qui donne le contrôle à un programme du système d’exploitation. Ce dernier doit exécuter un traitement approprié. Les trappes sont également utilisées par les applications pour demander un service au système d’exploitation, tel qu’une opération sur un fichier ou l’exécution d’une entrée-sortie.
Un mécanisme analogue est utilisé pour réagir à un événement issu de l’ordinateur, tel que signal d’horloge, fin de transfert sur un organe périphérique, signal issu d’un appareil connecté, etc. L’arrivée d’un tel événement, dit interruption, suspend l’exécution du programme en cours et donne le contrôle à un programme du système d’exploitation qui va exécuter un traitement approprié. Trappes et interruptions sont des mécanismes voisins, le premier étant actionné de haut en bas, le second de bas en haut dans la hiérarchie « machine-système-application ».
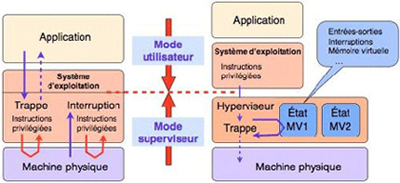
La partie gauche de la figure ci-dessus montre très schématiquement les communications au sein d’un système d’exploitation classique, utilisant les outils décrits plus haut. Sur la partie droite est représenté le fonctionnement d’un hyperviseur. On voit que la frontière entre mode utilisateur et mode privilégié ne se situe plus au niveau du système d’exploitation, mais à celui de l’hyperviseur. Les systèmes d’exploitation hébergés par les machines virtuelles gérées par l’hyperviseur s’exécutent donc maintenant en mode utilisateur.
Si un tel système d’exploitation exécute une instruction privilégiée, celle-ci est maintenant « trappée » par l’hyperviseur. Celui-ci gère l’ensemble des états de toutes les machines virtuelles qui fonctionnent au-dessus de lui. Le programme de trappe va d’abord déterminer la machine virtuelle à l’origine de l’opération exécutée. Il va ensuite modifier en conséquence l’état interne de cette machine : par exemple, si l’instruction trappée, issue de la machine virtuelle n°1 (MV1) était « masquer les interruptions », alors l’état de la machine MV1 va être mis à jour pour indiquer que les interruptions sont masquées (inhibées). L’hyperviseur partage l’usage de la machine physique par les différentes machines virtuelles. Il ne masque les interruptions sur la machine physique que durant l’exécution courante de MV1. Ainsi les systèmes d’exploitation fonctionnant sur les différentes machines virtuelles peuvent s’exécuter sans interférences mutuelles, même lorsqu’ils utilisent les instructions privilégiées pour accéder aux dispositifs de bas niveau de leurs machines respectives.
Les processeurs conçus dans les années 1990 contenaient de nouvelles instructions (« pseudo-privilégiées ») qui pouvaient s’exécuter dans les deux modes (superviseur et utilisateur), mais avaient un comportement différent selon le mode courant. Le fonctionnement de l’hyperviseur, tel que décrit plus haut, est alors mis en défaut car il repose sur le mécanisme des trappes, devenu inopérant. Il fallut alors concevoir un mode de fonctionnement adapté à cette nouvelle situation, dans lequel l’interface des machines virtuelles était différente de celle de la machine physique sous-jacente. Pour fonctionner sur ces machines virtuelles, les systèmes d’exploitation devaient alors être munis d’une couche basse d’adaptation pour utiliser cette nouvelle interface.
Virtualisation descendante
Les exemples vus jusqu’à présent illustrent la forme « ascendante » de virtualisation (partage de ressources par mutiplexage), la plus répandue. Donnons maintenant un exemple de virtualisation « descendante » (hiérarchie de machines abstraites).
Le système de gestion de fichiers (SGF) est un élément central de tout système d’exploitation. Il contient l’ensemble de l’information — programmes et données — gérée par le système, y compris divers composants du système lui-même.
L’interface externe du système de gestion de fichiers accessible aux utilisateurs comporte quelques opérations de base (créer, détruire, lire, écrire, etc.). Ces opérations ne sont pas toujours explicitement visibles par les utilisateurs, qui n’accèdent aux fichiers que par le biais de leurs applications ou d’une interface graphique (par exemple, placer dans la corbeille l’icone représentant un fichier). À ce niveau, les fichiers sont désignés par des noms symboliques attribués par les utilisateurs.
En dernier ressort, un fichier est représenté physiquement par une suite de bits sur le disque dur de l’ordinateur. La distance entre l’interface externe du système de gestion de fichiers et cette représentation physique des fichiers est franchie en plusieurs étapes, que nous illustrons par l’exemple du système de gestion de fichiers d’Unix (simplifié pour les besoins du document).
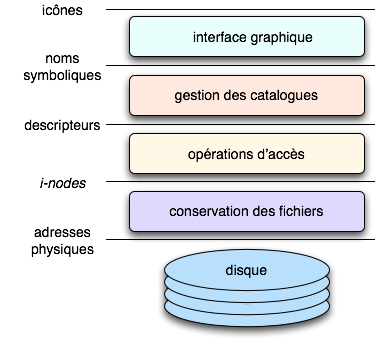
Figure 6. Système de gestion de fichiers.
En partant du niveau le plus bas (voir figure 6), le contenu d’un fichier est un ensemble de pages (sections de taille fixe) sur le disque. Ces pages ne sont pas nécessairement contiguës, car les emplacements disponibles ne le sont pas, en raison de l’ordre non prévisible des allocations et libérations. Chaque fichier possède une table d’implantation (i-node) indiquant les emplacements sur disque des pages qui le constituent.
Au second niveau sont réalisées les opérations d’accès au fichier : lecture et écriture, matérialisées par des accès aux emplacements du disque contenant le fichier. À ce stade, un fichier est désigné par un simple « numéro de descripteur », obtenu au moment de l’ouverture, qui permet un accès rapide à l’i-node gardé en mémoire principale, et donc à toutes les informations du fichier.
Au troisième niveau est organisée la désignation des fichiers par des noms symboliques choisis par les utilisateurs. On y trouve des structures arborescentes, les catalogues, qui organisent la désignation selon un modèle hiérarchique. Les catalogues sont eux-mêmes des fichiers, et chaque catalogue donne accès via leurs i-nodes aux fichiers qu’il contient.
Une couche supplémentaire réalise la mise sous forme graphique de ce système de désignation : les catalogues sont présentés à l’utilisateur comme une hiérarchie de dossiers, sous-dossiers, etc., visualisés sous forme d’icones. Les accès aux fichiers se font au travers d’applications (à chaque fichier est associée la liste des applications qui peuvent le manipuler). Ainsi, les opérations de création, lecture, écriture, etc., sont exécutées dans l’application et sont rendues invisibles aux utilisateurs. Néanmoins, les utilisateurs avertis peuvent avoir accès à ces opérations en utilisant l’interface disponible au niveau inférieur.
Au total, un système de gestion de fichiers réalise une virtualisation du disque physique mise en œuvre au moyen d’une hiérarchie de machines abstraites. Ainsi se combinent les deux formes de virtualisation.
La modélisation et les débuts d’une approche quantitative
La fin des années 1960 voit aussi se développer une approche quantitative des systèmes d’exploitation. Avec l’avènement des systèmes en temps partagé, cet aspect devient important car les performances du système sont beaucoup plus directement ressenties par ses usagers que dans un environnement non interactif. Or, en raison de la complexité de ces nouveaux systèmes, les performances dépendent de l’interaction de nombreux facteurs dont la compréhension nécessite une analyse fine.
L’outil proposé pour cette analyse repose sur la théorie des réseaux de files d’attente. Initialement développé pour des applications de recherche opérationnelle, cet outil est bien adapté à l’analyse des systèmes d’exploitation, dans lesquels les requêtes des usagers doivent « faire la queue » pour obtenir diverses ressources existant en quantité limitée : processeur, mémoire, bande passante pour l’accès à la mémoire secondaire, etc. Les méthodes à base de files d’attente vont permettre d’abord une modélisation partielle des systèmes : allocation du processeur, gestion des disques. On passe ensuite à la modélisation de systèmes d’exploitation complets, puis de réseaux d’ordinateurs. Les outils de simulation alors développés permettent de prévoir les performances d’un système existant, d’identifier les facteurs de dégradation de ces performances, et de dimensionner une installation pour répondre à une charge prévisible.
Qu’en est-il aujourd’hui ?
En quelques années, entre 1965 et 1969, le domaine des systèmes d’exploitation des ordinateurs est passé du stade d’un savoir-faire technique, d’ailleurs fort développé, à celui d’une discipline scientifique aidant à la compréhension et à la construction de ces objets complexes. Comment se sont aujourd’hui transformés les principaux aspects de ce domaine ?
Les recherches sur la virtualisation, très actives dans les années 1970, connurent une pause au début des années 1980. En effet, la large diffusion des ordinateurs individuels a fait passer au second plan les techniques de temps partagé.
Néanmoins, dans les années 1990, les ordinateurs individuels dépendaient de plus en plus de ressources distantes accessibles par les réseaux, et les systèmes multiprocesseurs connaissaient un grand développement. La complexité de ces nouveaux systèmes amenait un retour en grâce des techniques de virtualisation [8]. Aujourd’hui, l’informatique en nuages (cloud computing) repose entièrement sur la virtualisation, à très grande échelle, de ressources à différents niveaux : machines physiques, plates-formes logicielles, applications. Les problèmes de garantie de performance, d’isolation mutuelle et de sécurité continuent de se poser, mais dans un environnement technique beaucoup plus complexe.
Une conséquence de cette complexité est que l’administration et la commande des grands systèmes actuels dépassent désormais les capacités des opérateurs humains. La gestion autonome des systèmes informatiques (autonomic computing) est devenue un sujet de recherche très actif, à la frontière de l’informatique et de l’automatique. Des techniques élaborées de modélisation et de commande sont appliquées pour adapter les systèmes aux variations de charge, pour réagir aux défaillances, pour survivre aux attaques, pour économiser l’énergie, tout en évitant la dégradation des performances.
Le parallélisme reste un défi majeur. Il intervient aujourd’hui dans des contextes très divers. D’une part, le calcul parallèle à grande échelle, que ce soit sur des multiprocesseurs ou des « grilles » de machines en réseau, fait intervenir jusqu’à des centaines de milliers de processeurs. D’autre part, l’augmentation de la vitesse des processeurs réalisés en circuits intégrés trouve ses limites en raison de la difficulté d’évacuer la chaleur dans des circuits de plus en plus denses. L’augmentation des performances passe alors par la réalisation de systèmes « multicœurs » comportant un grand nombre de processeurs à l’intérieur d’une même puce de silicium.
En dépit de ces avancées techniques, le parallélisme demeure un domaine mal compris, pour lequel des progrès fondamentaux restent à accomplir.
Enfin, il faut mentionner une percée décisive récente dans le domaine des systèmes d’exploitation : en 2008-2009, une équipe australienne [9] a réalisé la preuve complète, au sens mathématique, de la validité d’un noyau de système d’exploitation, c’est-à-dire de la conformité de ce noyau à ses spécifications, elles-mêmes exprimées dans un formalisme rigoureux. Un système commercial réalisé autour de ce noyau certifié est maintenant très largement diffusé dans le public, notamment à l’intérieur de téléphones portables.
Ce document fait partie d’une série consacrée à divers aspects de l’histoire de l’informatique, réalisée en conjonction avec un projet de musée virtuel sur ce thème, porté par l’association ACONIT.
Remerciements à Claude Kaiser pour ses précieuses remarques.
Notes
[1] Nous utilisons souvent le terme de « système » à la place de « système d’exploitation », lorsqu’il n’y a pas d’ambiguïté.
[2] Dijkstra, Edsger W. The structure of the THE multiprogramming system. Communications of the ACM, vol. 11, 5 (1968), pp 341-346.
[3] Dijkstra, Edsger W. Cooperating sequential processes, Technological University, Eindhoven (1965). In Programming Languages, F. Genuys, ed., Academic Press, 1968, pp. 43–112.
[4] Kilburn, T., Edwards, D. B. G., Lanigan, M. J., and Sumner, F. H. One-level storage system. IRE Transactions, EC-11, 2 (April 1962), pp. 223-235.
[5] Denning, Peter J. (1970). « Virtual Memory ». ACM Computing Surveys 2 (3): 153–189
[6] Dennis, Jack B. Segmentation and the design of multiprogrammed computer systems. Journal of the ACM, vol. 12, 4, Oct. 1965, pp. 589-602.
[8] Smith, James E. and Nair, Ravi. Virtual Machines, Morgan Kaufmann, 2005.
[9] Klein, Gerwin; Elphinstone, Kevin; Heiser, Gernot; Andronick, June; Cock, David; Derrin, Philip; Elkaduwe, Dhammika; Engelhardt, Kai; Kolanski, Rafal; Norrish, Michael; Sewell, Thomas; Tuch, Harvey; Winwood, Simon « seL4: Formal verification of an OS kernel » (PDF). 22nd ACM Symposium on Operating System Principles. Big Sky, MT, USA (October 2009).
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

{kind=link}