
La naissance du génie logiciel
La fin des années 1950 voit la création des premiers langages de programmation de haut niveau. Dans la période euphorique qui suit, on pense que l’usage de ces nouveaux langages, qui viennent se substituer à l’assembleur, va résoudre les problèmes du développement des applications informatiques. Le terme de « programmation automatique », en vogue à l’époque, est représentatif de cet état d’esprit. Mais la réalité ne va pas tarder à se manifester…
La « crise du logiciel »
Dans les années 1960, l’informatique conquiert de nouveaux champs d’application. Initialement centrée sur le calcul scientifique, elle s’impose dans la gestion des entreprises, puis dans la commande de procédés industriels (chimie, nucléaire, productique), ainsi que dans les applications embarquées (avionique, spatial, communication, domaine militaire). Avec la naissance des sociétés de services informatiques, la production de logiciel, initialement concentrée chez les constructeurs d’ordinateurs et les grands utilisateurs, devient l’objet d’une industrie spécifique.
Au cours de cette période, la taille des systèmes informatiques connaît une croissance exponentielle. Ainsi, la taille (en milliers de lignes de code) du logiciel de base des machines IBM croît de 25 en 1958 (IBM 704) à 500 en 1964 (IBM 7090) puis à 5 000 en 1968 (IBM 360). Leur complexité, dont une estimation grossière est le nombre d’interactions entre les différents composants qui constituent un logiciel, croît en proportion.
Vers la fin des années 1960, un constat se fait jour : le développement des grands projets informatiques est de moins en moins bien maîtrisé. Les estimations de coût et de délai de production se révèlent inférieures à la réalité, souvent d’un facteur de 2 à 4. Les équipes de programmeurs sont confrontées à des problèmes de communication que l’encadrement peine à résoudre. Enfin, le logiciel produit ne répond pas toujours aux attentes ; il faut dire que les spécifications ne capturent pas toujours les besoins de manière adéquate, faute d’outils et de méthodes adaptés. La tâche de maintenance, qui devrait normalement consister à adapter le logiciel à l’évolution des besoins, vise surtout à corriger ses fautes, sans toujours éviter d’en introduire de nouvelles.
Face à ce sombre tableau, une prise de conscience se manifeste dans la communauté informatique : la production de logiciel manque du fondement rationnel présent dans d’autres techniques plus anciennes. De manière analogue au génie civil, au génie électrique et au génie chimique, il faut promouvoir un génie logiciel. L’initiative viendra de la division des affaires scientifiques de l’OTAN, qui organise en octobre 1968 sur la suggestion de F. L. Bauer, professeur à l’université technique de Munich, une conférence de travail sur les difficultés de la production de logiciel et les moyens de les surmonter. Intitulée Working Conference on Software Engineering, elle est considérée comme l’événement fondateur de cette nouvelle discipline et c’est elle qui popularise le terme de software engineering, traduit en français par « génie logiciel ».

Actes des conférences SE’68 (à gauche) et SE’69 (à droite).
Cette conférence (SE’68) a lieu à Garmisch, en Allemagne, et réunit plus de 50 participants (usagers de l’informatique, industriels et chercheurs). Elle sera suivie d’une seconde conférence (SE’69) sur le même thème, à Rome, en octobre 1969. Ces deux conférences n’ont pas apporté de solution immédiate à la crise du logiciel – ce n’était pas leur but – mais elles ont permis de faire le point sur la situation du domaine, d’identifier les grandes lignes de la discipline naissante du génie logiciel et de définir quelques uns de ses objectifs ainsi que des pistes de recherche. Si la conférence SE’68 a avant tout révélé l’étendue de la crise du logiciel, SE’69 a quant à elle approfondi certains aspects techniques, et a surtout mis en évidence des difficultés de communication au sein de la communauté : entre théoriciens et praticiens, entre chercheurs et industriels, entre constructeurs et utilisateurs. Ces problèmes n’étaient que le reflet de ceux du monde extérieur mais ils n’étaient pas attendus et, de fait, leur analyse constitua un thème majeur des discussions.
Fondements d’une discipline
Comment définir le génie (ou ingénierie), au sens de science et pratique de l’ingénieur ? C’est l’application de principes scientifiques à la conception et à la réalisation d’ensembles destinés à des fonctions utiles, de nature diverse selon le qualificatif attaché au terme « génie » (civil, chimique, électrique, etc.).
Le génie logiciel s’attache ainsi à définir et à appliquer des méthodes, des outils et des pratiques propres à assurer la production de logiciel répondant à des besoins spécifiés et respectant certains critères de qualité, eux-mêmes spécifiés, ainsi que des contraintes économiques. Par rapport à d’autres domaines, la spécificité du génie logiciel tient beaucoup au caractère immatériel des objets produits, qui résultent d’une construction intellectuelle. Deux conséquences en découlent : d’une part, le caractère malléable du produit, qui retentit sur ses modalités de production et d’évolution, et d’autre part, l’importance déterminante des facteurs humains.
Le cycle de vie du logiciel
De manière analogue à d’autres branches de l’ingénierie, la production du logiciel suit une série d’étapes que l’on appelle ici le cycle de vie. À chacune de ces étapes sont associés des outils et des méthodes propres à atteindre les objectifs visés. Si ces étapes sont clairement identifiées dès la conférence SE’68, les outils et les méthodes restent rudimentaires ou inexistants et leur fondement scientifique très loin d’être assuré. Les efforts menés dans le domaine du génie logiciel ont visé à fournir des méthodes et outils scientifiquement établis et à définir des règles de bonne pratique pour leur application. Ces efforts se poursuivent encore aujourd’hui.
La première mention du cycle de vie remonte à 1956, à propos de la conception du système SAGE (Semi-Automatic Ground Environment), un dispositif militaire de surveillance et de défense aérienne. Il s’agit du premier logiciel de grande envergure, comportant près de 500 000 instructions, ce qui était considérable pour l’époque. Mais cette expérience fut peu diffusée, et d’autres grands projets durent redécouvrir les principes développés dans SAGE.
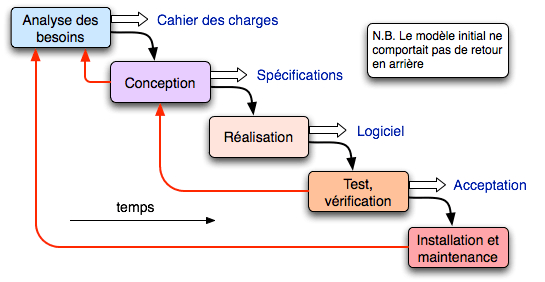
Modèle de la cascade simplifié.
Le cycle de vie, dans sa version initiale, était organisé en phases successives, selon un schéma qui fut plus tard appelé « modèle de la cascade » (figure ci-dessus, sans les flèches rouges).
La figure ci-après (présentée à SE’68) montre une autre vue du schéma de la cascade. D’une part, elle prend en compte la décomposition du logiciel en unités élémentaires, qui sont individuellement spécifiées, réalisées et testées, avant l’intégration et le test de l’ensemble. D’autre part, elle donne une indication approximative sur les ressources dévolues à chacune des phases. Enfin, elle intègre différentes fonctions de support technique. Néanmoins, les retours en arrière n’y apparaissent pas, ce qui a fait l’objet de critiques lors de sa présentation à SE’68.
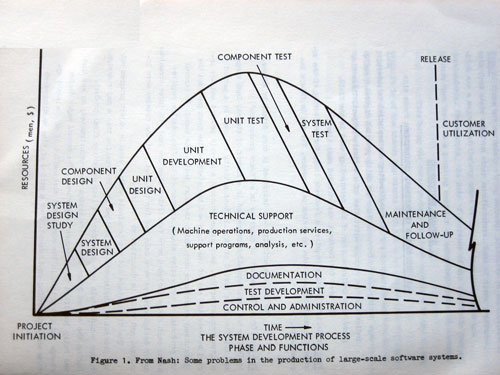
Les étapes du développement du logiciel (extrait des actes de la conférence SE’68).
Avec nos connaissances actuelles, on peut faire plusieurs remarques sur ce schéma, caractéristique de l’état de l’art en 1968.
- Les phases d’établissement du cahier des charges (design study) et de conception (system design, component design) mobilisent peu de ressources, alors que l’expérience a montré leur importance cruciale pour le succès d’un projet.
- Corrélativement, les phases de test absorbent une part importante des ressources, ce qui, en un sens, traduit le manque de garanties sur la qualité et l’efficacité des phases antérieures.
- La documentation apparaît comme une tâche accessoire et peu développée, alors que son importance est déterminante pour toute la vie du logiciel (dont on avait alors tendance à sous-estimer la durée).
L’intérêt de ce modèle est d’identifier les fonctions de chaque phase et de fixer des points de contrôle (les fins de phases), qui facilitent la planification et le pilotage du projet, chaque phase produisant un résultat qui peut être évalué et qui sert de base à la phase suivante. Néanmoins, ce modèle présenté à SE’68 montre de sérieux défauts :
- L’hypothèse sous-jacente est celle d’un monde parfait, où chaque phase fournit le résultat attendu. Il n’en est évidemment pas ainsi : des erreurs ou incohérences vont nécessairement apparaître. Ces critiques, déjà formulées à SE’68 et argumentées dans un article par l’informaticien américain Winston W. Royce, amenèrent à prévoir des retours en arrière (flèches rouges sur la figure).
- Le schéma de la cascade manque de souplesse : il s’accommode mal des modifications des besoins ou de l’environnement du projet au cours du développement. D’autre part, le logiciel utilisable n’est délivré qu’à une phase très tardive du cycle de vie. Cela retarde d’autant un retour d’expérience qui permettrait d’améliorer le produit. Des modèles de cycle de vie plus réactifs ont été proposés plus tard pour éviter ces défauts.
Les facteurs humains
Les facteurs humains jouent évidemment un rôle considérable dans la construction du logiciel. Deux aspects parmi d’autres illustrent cette situation :
- Le large spectre des compétences individuelles. En 1968, une étude fut entreprise par Sackman, Erikson et Grant, pour évaluer l’influence de l’adoption du temps partagé sur la productivité des programmeurs estimée selon divers facteurs : temps pour produire des programmes corrects pour des problèmes tests, efficacité du code produit, taille des programmes, etc. Si l’étude confirma que le passage au temps partagé améliorait nettement la productivité des programmeurs, elle mit en évidence un résultat moins attendu : l’ampleur des variations de productivité selon les individus, jusqu’à un facteur de l’ordre de 10 selon les critères !
- Les aspects psychologiques et sociologiques de la production de logiciel. Les grands projets de logiciel mettent en jeu des dizaines, voire des centaines de programmeurs, organisés en équipes. La qualité de la communication au sein même d’une équipe et entre les équipes, peut à elle seule déterminer le succès ou l’échec d’un projet. D’autres facteurs sont aussi importants, tels que le sentiment de propriété de chaque programmeur vis-à-vis de « son » code au sein d’un projet, ou le rôle du chef d’équipe. Ces aspects ont été étudiés en 1971 dans un livre de Gerald Weinberg : The Psychology of Computer Programming, qui connut un succès considérable.
Entre espoirs et déceptions : les sept premières années
Pourquoi se focaliser sur les sept premières années ? Il fallait choisir une limite, et en ce sens, la parution en 1975 du livre de Fred Brooks, The Mythical Man-Month, nous a semblé un choix approprié. Ce livre dresse en effet un bilan sévère des déconvenues des premières années. Les premières avancées du génie logiciel suscitèrent des espoirs, qui se révélèrent souvent fallacieux. La raison principale de ces déconvenues est une mauvaise appréhension des problèmes à résoudre et surtout une grave sous-estimation de leur difficulté. Cependant, quelques idées novatrices ont vu le jour au cours de cette période, préfigurant des avancées décisives à plus long terme.
Mythes et réalités

Image courtesy of Computer History Museum, © Addison-Wesley.
À sa parution en 1975, le livre The Mythical Man-Month (Le mythe de l’homme-mois) connut un fort retentissement. Son auteur, Fred Brooks, pouvait se prévaloir d’une grande expérience en génie logiciel, car il avait notamment dirigé le projet du système d’exploitation OS/360 de la série IBM/360, le plus gros ensemble logiciel de l’époque. La couverture même du livre illustrait de manière frappante la crise du logiciel : les animaux préhistoriques englués dans des mares de goudron figuraient les équipes de développement aux prises avec des difficultés insurmontables, que leurs efforts ne faisaient qu’aggraver. Voici quelques points saillants développés dans le livre :
- Lorsqu’un projet est en retard, ajouter de la force de travail ne fait qu’accentuer le retard. En effet, l’intégration des nouveaux arrivants consomme des ressources, et les difficultés de communication augmentent avec la taille de l’équipe.
- Le facteur déterminant du succès ou de l’échec d’un projet est l’unité conceptuelle de son architecture. Celle-ci ne peut être que le résultat du travail d’une toute petite équipe de personnes très qualifiées. La spécification d’architecture est une étape préliminaire, distincte de la réalisation. Brooks fait son mea culpa pour n’avoir pas suivi cette voie, par crainte d’un délai supplémentaire de trois mois. Le résultat fut « une erreur à plusieurs millions de dollars », le projet OS/360 ayant finalement glissé d’un an et le système étant resté difficile à maintenir et à faire évoluer.
- Un autre facteur essentiel, déjà mis en évidence entre autres dans le livre de Gerald Weinberg précédemment cité, est la qualité de la communication. D’où l’importance de l’organisation — structuration des équipes, répartition des rôles — et d’une documentation raisonnée évoluant en même temps que le projet.
- Un conseil au responsable de projet : « prévoyez de mettre une version à la poubelle ; vous le ferez de toutes façons ». Pour un projet complexe, le retour d’expérience est essentiel et le modèle de la cascade répondait mal à cet impératif.
Examinons maintenant l’évolution, dans ces premières années, des méthodes et outils associés aux différentes étapes du cycle de vie.
Architecture et conception
Trois aspects sont pris en considération : le cahier des charges, les méthodes de conception, et la modularité.
Le cahier des charges d’un système informatique est établi après une analyse des besoins auxquels il doit répondre et des contraintes économiques, techniques, réglementaires ou autres auxquelles il est soumis. Il ne doit pas faire d’hypothèses sur le mode de réalisation du système. Sur la période concernée, l’analyse des besoins était très peu formalisée et l’outil principal était le langage naturel, imprécis et parfois ambigu.
Alors que le cahier des charges exprime des besoins dans les termes de l’utilisateur, les spécifications transposent ces besoins en terme d’entités informatiques, en construisant un modèle du système à réaliser. Cette transposition est la phase de conception, qui vise d’abord à spécifier les fonctions du système, définies par leur interface ; il faut ensuite affiner ce schéma pour fournir un guide à la réalisation.
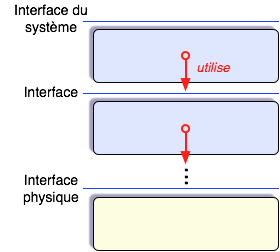
Hiérarchie de machines abstraites.
La première et importante avancée dans ce domaine fut l’idée de la conception descendante, proposée par plusieurs auteurs, en premier lieu Edsger W. Dijkstra. Le système d’exploitation « THE » qu’il a décrit en 1968 est un exemple de logiciel conçu en couches successives formant une hiérarchie de « machines abstraites », chacune utilisant l’interface de la couche immédiatement inférieure. La couche la plus haute réalise l’interface du système entier, la plus basse est celle du matériel. Ainsi, pour une couche donnée, on ne s’intéresse qu’à son interface en ignorant provisoirement son mode de réalisation, qui sera examiné plus tard : c’est le principe d’abstraction, outil très fécond qui s’applique aussi au stade de la réalisation et qui sera plus tard enrichi par le recours aux méthodes formelles.
Le besoin de guides méthodologiques pour la conception de logiciel était fort. Deux ouvrages non spécifiques à l’informatique stimulèrent la réflexion vers la fin des années 1960 ; le premier, Notes on the Synthesis of Form, était l’œuvre d’un architecte et urbaniste, Christopher Alexander. Le second, The Sciences of the Artificial fut celui d’un économiste, sociologue et pionnier de l’intelligence artificielle, Herbert A. Simon. Pour le logiciel, les premiers éléments de réponse datent des années 1970 (Warnier, plus tard Merise, Jackson et d’autres). Mais aucune de ces « méthodes » ne réussit à dominer le marché, ce qui explique leur multiplication.
L’un des points forts de la conférence SE’68 fut la présentation de l’informaticien Malcolm Douglas McIlroy : Mass produced software components. L’auteur plaide pour un mode de production de logiciel sous la forme de composants standard pouvant être paramétrés et assemblés à la demande, avec des spécifications précises et des garanties de qualité. Après tout, un tel modèle fonctionnait déjà avec succès dans l’industrie électronique. Ce schéma est complémentaire de celui de la conception descendante, chaque machine abstraite pouvant être réalisée comme un assemblage de modules.
Néanmoins, la vision de McIlroy ne parvint pas à se matérialiser, en raison notamment de la malléabilité du logiciel, opposée à la rigidité et à la séparation claire des fonctions des composants matériels. Ainsi, le risque est grand, en l’absence d’une stricte discipline, d’introduire des dépendances cachées entre modules : si l’utilisation d’un module dépend d’informations qui ne sont pas explicitement dans son interface, alors des modifications, a priori anodines, dans la réalisation du module pourront entraîner des défaillances difficiles à détecter.
Un article remarqué de David Lorge Parnas, un informaticien canadien, proposa en 1972 de fonder la décomposition sur les choix de conception plutôt que sur le flot d’exécution : un module correspond à une unité fonctionnelle identifiée lors de la conception, dont les modalités de réalisation doivent rester cachées à ses utilisateurs. L’idée est de faire en sorte qu’un changement dans un choix de conception ait un impact sur un nombre minimal de modules. Ce principe de « dissimulation de l’information non indispensable » reste un bon guide pour la décomposition d’un logiciel.
Il est difficile de mettre en œuvre une méthode en l’absence d’outils appropriés. Une tentative dans ce sens visait à distinguer la programmation globale (programming in the large), c’est-à-dire l’organisation d’un système en modules, de la programmation détaillée de chaque module (programming in the small). De même que cette dernière utilise un langage de programmation, la programmation globale utilise un langage d’interconnexion de modules (Module Interconnection Languages ou MIL). Néanmoins, ces langages, déclaratifs plutôt qu’impératifs, n’arrivèrent pas à s’imposer dans les usages. Le problème de l’expression de la structure globale d’un système est toujours d’actualité.
Enfin, la fin des années 1960 voit les premiers pas de la programmation par objets, autre approche de la modularisation, fondée sur deux idées : regrouper dans une même entité opaque (l’objet) des structures de données et les programmes destinés (et eux seuls) à les manipuler ; introduire un mécanisme de « classes » permettant de définir une hiérarchie de modèles extensibles et paramétrables pour la construction dynamique d’objets de même structure. Ces idées ont été
largement développées jusqu’à aujourd’hui.
Développement et test
Pour la construction de programmes, une étape fondamentale fut la création des premiers langages de programmation au milieu des années 1950. Néanmoins, ces langages (Fortran et Cobol) servaient surtout au développement d’applications ; le logiciel de base, notamment les systèmes d’exploitation comme OS/360 et celui des systèmes embarqués, étaient encore écrits en assembleur au milieu des années 1960. Les premiers systèmes d’exploitation programmés en langage de haut niveau, respectivement des sous-ensembles des langages Algol et de PL/1 (essai de mariage, chez IBM, entre Fortran et Cobol), furent Burroughs MCP et Multics.
Contrairement aux espoirs nés de leur adoption, il devint rapidement clair que l’emploi de langages de haut niveau ne suffisait pas à lui seul à garantir la validité des programmes. Il fallait introduire une discipline. En 1968, Dijkstra frappa les esprits en dénonçant dans son article Go to statement considered harmful, les méfaits de l’usage inconsidéré de l’instruction de branchement go to. Il énonça ensuite des principes de bonne programmation, sous le terme de « programmation structurée », dans un article intitulé Notes on structured programming. Cette idée fut également portée par Niklaus Wirth (père des langages Pascal et Modula-2 notamment) qui milita pour une application de la conception descendante à l’écriture de programmes. Mais ces principes ne furent pas toujours compris et la pratique de la « programmation structurée » se borna trop souvent à l’application mécanique de règles, en négligeant l’effort nécessaire pour une preuve, au moins informelle, de la validité des constructions (voir une discussion plus détaillée dans l’encart Apports et limites de la théorie).
La première question que se pose l’auteur d’un programme est : « mon programme fait-il bien ce que je lui demande ? ». Très tôt, des chercheurs reformulèrent cette question en : « peut-on prouver qu’un programme fait bien ce qu’on lui demande ? ». On sait depuis l’article fondateur de Turing paru en 1936 (voir le document Sous le signe du calcul) que la réponse à cette question, formulée dans sa généralité, est négative. Cela n’empêche pas de rechercher des solutions partielles, valables dans des cas spécifiques. Il fallait d’abord pouvoir définir rigoureusement la sémantique d’un programme, c’est-à-dire l’effet de son exécution, problème bien plus difficile que la définition de sa syntaxe (sa forme). L’article fondateur dans ce domaine est celui de Robert W. (« Bob ») Floyd, dont le titre Assigning meaning to programs (Attribuer un sens aux programmes) résume l’ambition. En simplifiant, l’idée de base est de définir l’état d’un programme comme l’ensemble de l’information qu’il manipule et d’attacher une assertion (une propriété de l’état) à l’entrée et à la sortie de chaque instruction (voir figure ci-dessous). Ainsi, l’exécution d’une instruction est vue comme une transformation bien spécifiée de l’état du système.
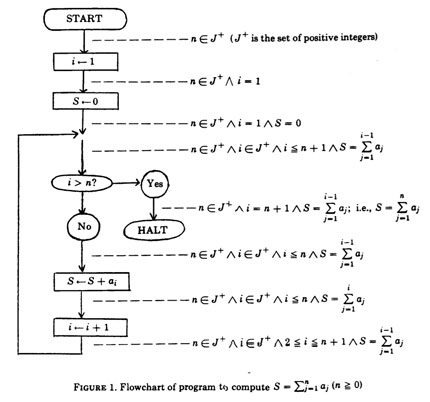
Analyse sémantique d’un programme simple.
Cette idée fut reprise et étendue par C. A. R. (« Tony ») Hoare, qui définit une logique (ensemble de règles de déduction) à base d’assertions et d’invariants. La construction clé de cette logique de Hoare s’exprime ainsi :
Vers le milieu des années 1970, des chercheurs du laboratoire IBM de Vienne se posèrent le problème d’automatiser la construction d’un compilateur à partir d’une définition formelle du langage qu’il traite. L’expérience avec le langage PL/1 ayant été positive, cette méthode fut plus tard étendue sous le nom de Vienna Development Method (VDM ) à la construction progressive de programmes à partir d’une spécification formelle écrite dans un langage approprié, VDM-SL (VDM-Specification Language).
D’autres chercheurs, s’appuyant sur les travaux de Floyd et de Hoare, se sont attachés à définir des méthodes d’écriture de programmes intégrant, par construction, la garantie de leur validité. Il faut ici citer à nouveau Dijkstra, qui proposait une « programmation disciplinée » garantissant des propriétés spécifiées, et l’informaticien Jean-Raymond Abrial qui posait en 1974 les bases de la méthode Z de spécification et de construction de programmes, préfigurant la méthode B, une méthode formelle de développement.
Néanmoins, dans les années 1970, le champ d’application pratique de ces méthodes restait limité à des programmes « jouets ». La vision prospective, défendue notamment à la conférence SE’69 par Dijkstra et Hoare, d’une possibilité, à terme, de preuve rigoureuse de programmes réels, se heurtait au scepticisme affiché des praticiens. L’avenir devait donner tort à ces derniers. Ainsi, par exemple, le document Comment faire confiance à un compilateur ? explique la preuve de la validité d’un compilateur du langage C, réalisée en 2005.
En conséquence, les erreurs (bugs ou « bogues ») ne disparurent pas, et les phases de mise au point et de test continuèrent de tenir une place très importante dans le cycle de vie du logiciel. Deux citations extraites des actes de la conférence SE’69 sont significatives :
- « Les programmeurs parlent de bugs pour préserver leur santé mentale ; un tel nombre d’erreurs serait psychologiquement insupportable » (Martin Hopkins, IBM).
- « Le test peut montrer la présence de bugs, non leur absence » (Edsger Dijkstra).
La mise au point consiste essentiellement à identifier et à corriger les erreurs. La phase de test repose sur l’exécution contrôlée du logiciel et de ses composants. Elle doit déterminer si le logiciel est acceptable et peut être délivré à ses utilisateurs. Plus précisément, la vérification vise à s’assurer que le logiciel est conforme à ses spécifications, alors que la validation permet de s’assurer que le logiciel remplit les clauses du cahier des charges.
Alors que la mise au point est pratiquement intégrée au développement, la phase de test, au moins dans le modèle de la cascade qui prévalait dans les années 1970, est confiée à une équipe distincte de celle de développement. En fait, les tests de validation doivent être planifiés dès l’élaboration du cahier des charges, et les tests de vérification dès la conception. Des scénarios de test sont préparés, l’objectif étant de couvrir toutes les situations de la vie du programme. Dès que le logiciel est un peu complexe, cet idéal est inaccessible, en raison de l’explosion du nombre de cas possibles : c’est le sens de la citation de Dijkstra.
On distingue le test unitaire, pour chacun des composants, du test d’intégration qui vérifie le système complet. En effet, même si chacun des composants est considéré comme correct, leur assemblage peut être défectueux en raison d’interactions imprévues entre les composants : interfaces non compatibles, dépendances cachées, problèmes de performances…
À l’issue du test, le logiciel est accepté s’il satisfait à toutes les épreuves. Sinon, les défauts sont identifiés, et un nouveau cycle est lancé, revenant à l’une des phases antérieures selon la nature des défauts constatés. Dans les années 1970, on considérait que le test mobilisait environ 50% des ressources consacrées à la production du logiciel.
Après la livraison du logiciel, la phase de maintenance vise à adapter le système à l’évolution de l’environnement et des besoins, et à corriger les erreurs non détectées lors de la phase de test. Quand une correction est appliquée au système, un test de non-régression vise à détecter — sans toujours y parvenir — l’introduction de nouvelles erreurs. On remarque souvent qu’au fil des corrections, le système devient de plus en plus difficile à maintenir, et cela d’autant plus que son intégrité conceptuelle est faible au départ : les corrections tendent à se propager à un nombre croissant de composants, augmentant l’« entropie » du système, autrement dit son manque de cohésion. Ce phénomène est aggravé par une sous-estimation générale de la durée de vie des logiciels.
Au cours du cycle de vie d’un logiciel, de nombreux outils sont mis en œuvre. Au début des années 1970 émergea l’idée de réunir ces outils (éditeurs, compilateurs, metteurs au point, outils de test, documentation, système de gestion de versions) dans un environnement de travail unique intégré et cohérent, pour faciliter la tâche des programmeurs et simplifier l’organisation du travail. Cette idée ne put se concrétiser qu’après la généralisation du temps partagé et du travail interactif sur terminaux alphanumériques, puis graphiques. Les programmes changèrent alors de support, les fichiers partagés accessibles en ligne remplaçant les cartes ou rubans perforés. Le premier environnement de développement intégré produit à l’échelle industrielle fut Maestro, réalisé en 1974-75 par une entreprise allemande, Softlab Munich. Maestro fonctionnait sur une machine et un système d’exploitation dédiés à son usage. Les nombreux environnements développés ultérieurement s’appuient sur les systèmes usuels.
Pour conclure

Un développeur au travail. Auteur : Matthew (WMF) – Own work. Licensed under CC BY-SA 3.0 via Wikimedia Commons.
Près d’un demi-siècle après sa création, la discipline du génie logiciel a-t-elle atteint ses objectifs initiaux ? Des avancées très significatives ont été réalisées ; plusieurs des acteurs cités ici ont été couronnés par le Prix Turing, la plus haute distinction en informatique, depuis Dijkstra dès 1972, Simon, Floyd, Hoare, Wirth et enfin Brooks en 1999. Force est néanmoins de constater que de grandes questions restent ouvertes. Les bugs des systèmes informatiques continuent de défrayer la chronique…
En 1995, Fred Brooks publiait une nouvelle édition de son livre The Mythical Man-Month, augmentée de quatre chapitres dans lesquels il analysait l’évolution du domaine dans les vingt ans écoulés. Même si l’apparition d’ordinateurs individuels puissants et l’extension des réseaux amélioraient beaucoup les conditions de travail, et si le cycle de vie était mieux maîtrisé, aucune percée décisive n’était notée. Reprenant le titre d’un article de 1986 (No Silver Bullet), Brooks estimait peu probable qu’un remède magique (une balle en argent, silver bullet) révolutionne le domaine du génie logiciel comme l’invention du transistor et celle des circuits intégrés l’avaient fait pour le matériel. En attendant la diffusion massive, à échéance lointaine, des méthodes reposant sur les avancées de la théorie, cette conclusion semble toujours être d’actualité.
La conférence fondatrice et sa suite (textes complets disponibles ici)
- Naur, P. and Randell, B., (Ed.). Software Engineering: Report on a Conference sponsored by the NATO Science Committee, Garmisch, Germany, 7th to 11th October 1968, Brussels, Scientific Affairs Division, NATO, January 1969, 231 p.
- Buxton, J.N. and Randell, B., (Ed.). Software Engineering Techniques: Report on a Conference sponsored by the NATO Science Committee, Rome, Italy, 27th to 31st October 1969, Brussels, Scientific Affairs Division, NATO, April 1970, 164 p.
Mythes et réalités
- Brooks, F. P. The Mythical Man Month, Addison-Wesley (1975). Anniversary Edition, 1995.
Cycle de vie
- Royce, W. Managing the development of large software systems, Proceedings of IEEE WESCON 26 (August 1970) : 1–9.
Ouvrages généraux sur la conception
- Alexander, C. Notes on the Synthesis of Form, Harvard University Press (1964).
- Simon H.A. The Sciences of the Artificial, MIT Press (1969 ; rééditions : 1981, 1996).
Architecture du logiciel, modularité
- Dijkstra, E. W. The structure of the THE multiprogramming system, Communications of the ACM 11 (5): 341–346 (1968).
- McIlroy, M. D. Mass produced software components, in [SE’68].
- Parnas, D. L. On the criteria to be used in decomposing a system into modules, Communications of the ACM 15 (12): 1053–58 (December 1972).
- Liskov, B. and Zilles, S. Programming with abstract data types, Proc. ACM SIGPLAN Symposium on Very High Level Languages, Santa Monica, pp. 50-59 (1974).
- DeRemer, F. and Kron, H. Programming-in-the large versus programming-in-the-small. Proceedings of the International Conference on Reliable Software (ACM), Los Angeles, pp. 114—121 (1975).
Les premiers articles sur la « bonne programmation »
- Dijkstra, E. W. Go to statement considered harmful, Communications of the ACM, 11 (3): 147–148.
- Dijkstra, E. W. Notes on structured programming, in Dahl, O.J., Dijkstra, E.W. and Hoare, C.A.R. Structured Programming, Academic Press (1972).
- Wirth, N. Program development by stepwise refinement, Communications of the ACM, 14, 4, (Apr 1971) 221-227 (1971).
Les premiers articles sur la sémantique des programmes
- Floyd, R. W. Assigning meaning to programs, Proceedings of Symposia in Applied Mathematics, American Mathematical Society, Vol. 19, pp. 19-32 (1967).
- Hoare, C. A. R. An axiomatic basis for computer programming. Communications of the ACM, 12(10):576–580 (1969).
Spécifications, méthodes formelles
- Abrial, J. R. Data semantics, IFIP Working Conference on Database Management, Klimbie; Koffeman, ed., North Holland, pp. 1-60 (1974). [NB : les bases du langage Z]
- Bjørner, D. and Jones C. B. (1978). The Vienna Development Method: The Meta- Language, Lecture Notes in Computer Science 61. Springer (1978).
La programmation comme activité humaine
- Sackman, H., Erikson W. J., Grant E. E. Exploratory experimentation studies comparing on-line and off line programming performance, Communications of the ACM, 11(1): 3-11 (1968).
- Weinberg, G. M., The Psychology of Computer Programming, Van Nostrand Reinhold, 1971. Silver Anniversary Edition: Dorset House Publishing, 1998.
Newsletter
Le responsable de ce traitement est Inria. En saisissant votre adresse mail, vous consentez à recevoir chaque mois une sélection d'articles et à ce que vos données soient collectées et stockées comme décrit dans notre politique de confidentialité
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
