
La naissance des systèmes d’exploitation
“An operating system is a collection of things that don’t fit into a language.
There shouldn’t be one.”
« Un système d’exploitation est une collection de choses qui ne tiennent pas dans un langage.
Ça ne devrait pas exister. »
Dan Ingalls, Design Principles Behind Smalltalk, Byte Magazine, August 1981.
La conception des systèmes d’exploitation des ordinateurs est soumise à une tension entre deux objectifs contradictoires : améliorer le confort des utilisateurs ; exploiter efficacement les ressources physiques des machines. Le début de l’histoire de ces systèmes traduit bien le va-et-vient entre ces objectifs.
1. Une double fonction
Dans un monde idéal, tel que le souhaite l’auteur de la citation ci-dessus, les constructions d’un langage de programmation pourraient être directement mises en œuvre sur un ordinateur, grâce à une couche appropriée de logiciel. En réalité, on constate qu’un certain nombre de services (gestion de fichiers, entrées-sorties, interfaces graphiques, sécurité, etc.), ne sont pas du ressort d’un langage mais relèvent plutôt d’une intendance commune à divers langages. Pour combler l’écart entre les constructions d’un langage et l’interface de la machine physique, il faut donc non pas une, mais deux couches intermédiaires de logiciel. Le système d’exploitation, au contact de la machine physique, transforme celle-ci en une machine idéale (virtuelle) fournissant à la couche supérieure les services d’intendance jugés adéquats ; cette dernière couche utilise ces services pour permettre aux utilisateurs de mettre en œuvre les langages dont ils ont besoin. Ces langages, à leur tour, servent à réaliser les applications. C’est ce que résume la figure ci-dessous.
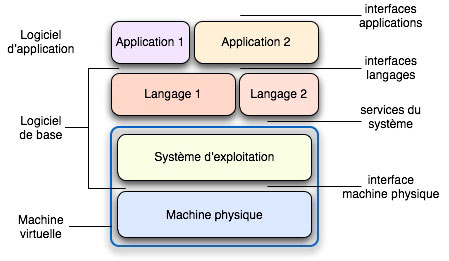
Organisation d’un système informatique.
La réalité est toutefois plus complexe. D’une part, le nombre de couches est plus grand et la séparation entre elles souvent moins nette ; il peut aussi être plus réduit, avec une ou des applications s’exécutant directement en lieu et place du système. D’autre part, le schéma décrit est celui d’un utilisateur unique. L’ordinateur peut aussi être partagé entre plusieurs utilisateurs, et c’est au système d’exploitation de créer pour chacun d’eux sa propre machine virtuelle, indépendante de celles des autres mais pouvant partager des informations avec elles.
Le rôle du système d’exploitation comme transformateur d’interface en implique un autre : celui de gérant des ressources de la machine physique : processeurs, mémoires, organes de communication. Gérer les ressources consiste à les attribuer à tout moment aux activités qui en ont besoin, en prévenant ou en résolvant les conflits éventuels et en respectant les priorités imposées. Il faut également gérer les ressources immatérielles (programmes et données) en permettant si nécessaire leur partage entre utilisateurs et en assurant leur pérennité et leur sécurité.
Cette double fonction — fournir une interface « commode », allouer les ressources — fait que la conception d’un système d’exploitation est soumise à deux exigences : la première fonction privilégie le confort des utilisateurs (on peut parler d’ergonomie) ; la seconde met l’accent sur l’efficacité, l’emploi optimal des ressources (il s’agit là d’économie). L’histoire des débuts des systèmes d’exploitation montre que, dans le contexte technique de l’époque, ces exigences étaient contradictoires et que la tension entre elles était une source majeure de difficulté, l’autre source étant la complexité des ressources gérées et la distance entre la machine physique existante et la machine idéale. La suite de ce document illustre le mouvement de balancier entre les objectifs d’économie et d’ergonomie, privilégiant successivement l’un et l’autre, avant l’arbitrage final, permis par l’évolution technique, en faveur de l’ergonomie.
On peut très schématiquement distinguer trois phases dans l’histoire des débuts des systèmes d’exploitation, avec des recouvrements dans le temps. Les premiers ordinateurs étaient des instruments d’expérimentation pour des chercheurs ; la question de l’efficacité ne se posait guère et les utilisateurs devaient apprendre à mettre au point leurs programmes, au contact direct de la machine. C’est la phase que nous appelons « préhistoire ». La phase suivante correspond à des ordinateurs qui sont à la fois rares et chers, et utilisés pour de vraies applications. Nous décrivons successivement la course à l’efficacité avec le traitement par lots et la recherche d’une utilisation conviviale avec le temps partagé. Enfin, la troisième phase (non approfondie ici) correspond à la banalisation d’ordinateurs personnels de moins en moins coûteux. L’ergonomie triomphe et l’économie passe au second plan, l’ordinateur étant devenu un produit consommable. Alors que prédomine l’utilisation individuelle de l’ordinateur, nous montrons en conclusion que les systèmes actuels sont directement issus des grands systèmes en temps partagé des années 1970.
La figure ci-après schématise quelques étapes marquantes des débuts des systèmes [1].
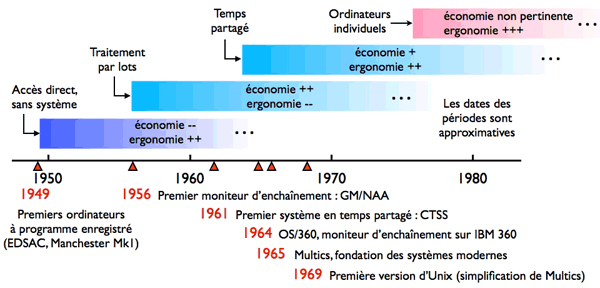
Chronologie simplifiée des premiers systèmes.
La place des systèmes d’exploitation entre la machine physique et les applications fait que leur évolution est intimement liée d’une part à celle de la technologie des ordinateurs et d’autre part, à celle des usages de l’informatique.
La préhistoire
Les premiers ordinateurs n’avaient pas à proprement parler de système d’exploitation, et cette situation dura de 1949 avec les premières machines à programme enregistré jusqu’en 1956, année du premier moniteur de traitement par lots. En effet, les langages initialement utilisés étaient très proches de la machine physique : code binaire, assembleurs primitifs, collections de sous-programmes. D’autre part, le partage de la machine se faisait simplement par réservation : chaque utilisateur avait la machine pour lui seul pendant une tranche de temps déterminée. En ce sens, l’exploitation des ordinateurs privilégiait le confort des utilisateurs, donc le côté « ergonomie ».
On peut néanmoins noter les premiers embryons de mécanismes d’assistance à l’utilisation des ordinateurs. L’EDSAC de Cambridge, première machine à programme enregistré, avec le Manchester Mark-1, utilisait une forme rudimentaire de langage assembleur, où les instructions étaient écrites sous forme symbolique et les adresses (absolues) sous forme décimale. Les programmes, enregistrés sur ruban perforé, étaient traduits en binaire et placés en mémoire par un mécanisme appelé « ordres initiaux », lui-même enregistré sur une mémoire externe en lecture seule. Plus tard furent introduits les sous-programmes, conservés dans une bibliothèque sous forme de rubans ; ceux-ci devaient être physiquement copiés avant exécution, sur le ruban contenant le programme principal. Les ordres initiaux devaient donc assurer ce qu’on appelle aujourd’hui l’édition de liens, c’est-à-dire fixer les adresses d’appel et de retour des sous-programmes pour garantir leur exécution correcte. D’autres langages primitifs utilisant des sous-programmes furent développés plus tard, notamment sur UNIVAC par Grace Hopper. Leur traduction en langage machine était cette fois à la charge d’un programme enregistré, mais l’exploitation de l’ordinateur restait sous contrôle manuel.
Compte-tenu de l’important investissement que représentait à l’époque l’achat d’un ordinateur, il n’est pas étonnant que l’on ait recherché les moyens de rendre son exploitation plus efficace. Les programmes des utilisateurs furent ainsi regroupés en lots ou fournées (en anglais batch), pour les traiter en série, sans transitions. Une nouvelle fonction apparut, celle d’opérateur, un technicien chargé de préparer les lots d’entrée à partir des programmes fournis par les utilisateurs, de surveiller l’exécution des travaux, et de distribuer les résultats de sortie. L’enchaînement des travaux était réalisé par un programme appelé moniteur, ou système de traitement par lots, qui fut la première forme de système d’exploitation. L’économie prit alors le pas sur l’ergonomie, les usagers étant désormais privés de l’accès libre à la machine et de la mise au point interactive.
Le traitement par lots et la course à l’efficacité
L’évolution des moniteurs de traitement par lots est dominée par la recherche de l’efficacité, au sens de l’utilisation optimale des ressources. Les innovations architecturales et matérielles (couplage de machines, multiprogrammation, canaux d’entrée-sortie) viseront cet objectif, sans grande considération pour le confort des utilisateurs.
Principes de fonctionnement
Les principaux périphériques des ordinateurs des années 1950 étaient les lecteurs de cartes perforées, les imprimantes et les dérouleurs de bandes magnétiques. Dans le schéma initial, les travaux à exécuter avaient la forme d’un paquet de cartes, préparé par l’utilisateur ou par un atelier de perforation. Un programme résidant en permanence en mémoire, le moniteur d’enchaînement, avait pour rôle de lire les cartes, de lancer l’exécution des programmes et d’imprimer les résultats.
//fortran
<cartes constituant un programme en Fortran>
//run
//data
<données pour le programme Fortran>
//job
<le travail suivant>
…
Des cartes particulières, les cartes de commande, s’adressaient au moniteur en lui spécifiant quel programme il devait lancer. Ainsi, dans le petit exemple ci-contre, les lignes commençant par // représentent le contenu des cartes de commande. La ligne //fortran indique au moniteur qu’il doit lancer le compilateur Fortran pour traduire le texte qui suit ; la ligne //run demande l’exécution du résultat de la compilation, en utilisant les données qui suivent la ligne //data.
Il est intéressant de noter que le premier système d’exploitation fonctionnant sur ce principe, GM-NAA I/O a été développé sur IBM 704 par des entreprises utilisatrices, General Motors et North American Aviation, et non par IBM, le constructeur de la machine. IBM devait fournir plus tard un système comparable, IBSYS, pour les ordinateurs de la série 7000.
Aussi simple soit-il, un tel système pose deux problèmes de sécurité :
- si un programme d’utilisateur tourne en boucle infinie, par suite d’une faute de programmation, l’exécution du lot est bloquée indéfiniment (l’opérateur peut certes intervenir, mais il doit alors avoir une idée de la durée maximale du travail) ;
- toujours à la suite d’une faute de programmation, un programme d’utilisateur peut écrire « n’importe où » dans la mémoire, et en particulier dans la zone réservée au moniteur. Il y a de nouveau un risque de blocage ou de dysfonctionnement de l’ensemble.
Deux innovations matérielles permirent de remédier à ces problèmes.
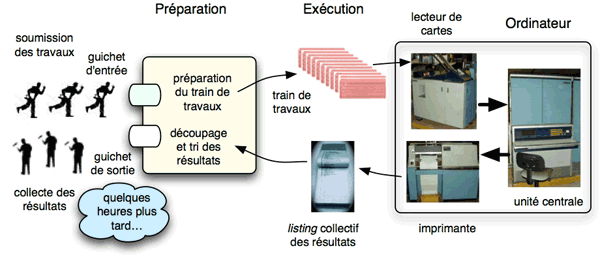
Fonctionnement du traitement par lots. Crédit photos : © Aconit
En premier lieu, une horloge programmable, pouvant interrompre l’unité centrale après écoulement d’un délai spécifié. L’utilisateur devait alors préciser sur une carte de commande une durée maximale pour son travail, dans des limites fixées. Si ce temps d’exécution était dépassé, le moniteur interrompait le travail et passait au travail suivant. En second lieu, un dispositif permettant de protéger une zone de mémoire contre l’écriture. Le programme du moniteur était placé dans une zone ainsi protégée.
Couplage de deux machines
Le schéma précédent souffre d’un défaut d’efficacité, dû à la différence de vitesse entre les périphériques électromécaniques et l’unité de calcul. Pendant le temps de lecture d’une carte ou d’impression d’une ligne, l’unité centrale était oisive, car les ordinateurs de l’époque ne pouvaient faire qu’une chose à la fois.
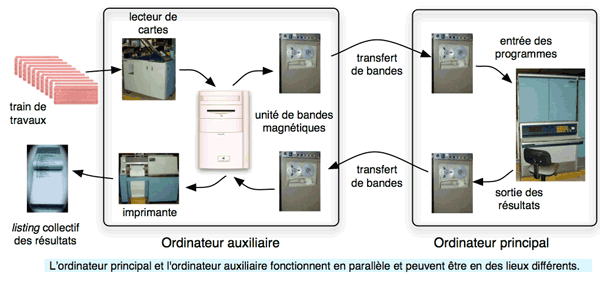
Couplage de machines. Crédit photos : © Aconit
Pour augmenter le taux d’utilisation de l’unité centrale, on a l’idée de remplacer le lecteur de cartes et l’imprimante par des bandes magnétiques, organes beaucoup plus rapides. Un calculateur, auxiliaire, beaucoup plus simple que le calculateur principal, est utilisé pour constituer une bande d’entrée à partir des cartes soumises par les utilisateurs et pour imprimer le contenu de la bande de sortie. La fonction d’opérateur évolue pour prendre en compte ces changements. La figure ci-dessus schématise ce mode d’exploitation (la phase de préparation est inchangée par rapport à la figure précédente). Notons que la recherche de l’efficacité conduit à augmenter le nombre de travaux dans un lot, ce qui accroît encore le temps d’attente des utilisateurs.
À cette époque de quasi monopole d’IBM, une association classique consistait à utiliser un ordinateur 1401 pour traiter les bandes et un ordinateur de la série 7000, par exemple un 7094, pour les calculs.
Systèmes à entrées-sorties simultanées
Deux évolutions matérielles ont permis de simplifier le schéma précédent et d’améliorer encore son efficacité : l’invention des canaux d’entrée-sortie, permettant d’exécuter en parallèle des entrées-sorties et des opérations de calcul, et la généralisation des disques magnétiques, organes d’accès rapide, pour le stockage des données. Le système d’exploitation peut alors coordonner trois activités simultanées, la lecture des travaux à exécuter, l’exécution proprement dite et l’impression des résultats. Ces trois activités communiquent par l’intermédiaire de zones de mémoire intermédiaire, ou tampons, stockées sur disque pour avoir une taille suffisante. Ce dispositif, schématisé sur la figure ci-dessous, portait le nom de SPOOL (Simultaneous Peripherals Operation On Line). Il est toujours utilisé aujourd’hui pour gérer les impressions sur les ordinateurs personnels.
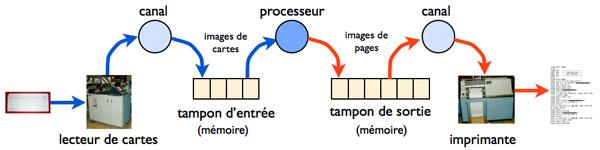
Principe de fonctionnement du SPOOL.
Une famille d’ordinateurs représentatifs de ce fonctionnement est la série IBM 360, annoncée en 1964 et effectivement disponible à partir de 1965. Son système d’exploitation, l’OS/360, a existé en différentes versions. Dans la plus simple, ou PCP, un seul programme utilisateur était chargé en mémoire à un instant donné. Les versions ultérieures permettaient à plusieurs programmes d’utilisateurs d’être simultanément présents en mémoire, mode d’exploitation appelé multi-programmation. Lorsqu’un programme utilisateur est en attente d’entrée-sortie, on peut lancer l’exécution d’un autre programme utilisateur prêt à s’exécuter, s’il en existe un. On augmente donc encore le taux d’utilisation de l’unité centrale.
Un autre système d’exploitation notable du début des années 1960 est le MCP (Master Control Program) de la société Burroughs. C’est le premier système écrit dans un langage de haut niveau (un dérivé d’Algol) et également le premier système gérant des multiprocesseurs.
Dans les premiers systèmes multiprogrammés, la mémoire était divisée en zones de taille fixe, dans lesquelles étaient chargés les programmes des utilisateurs. Plus tard, les limites de ces zones, en nombre devenu variable, furent ajustables dynamiquement, ce qui permit une meilleure utilisation de la mémoire [2]. Ainsi, à la fin des années 1960, le système d’exploitation utilisait de façon quasi-optimale les ressources coûteuses de l’ordinateur, mémoire et unité centrale, au prix d’une grande complexité, et donc d’une maintenance et d’une mise au point délicates [3].
Un autre domaine d’application commençait à émerger dans les années 1960, celui de la commande de procédés industriels. Les qualités requises étaient ici la réactivité, la sécurité et la tolérance aux fautes. Les systèmes d’exploitation pour ces applications reposaient sur un noyau assurant la gestion et la synchronisation d’activités parallèles et la communication avec les organes externes, capteurs et actionneurs. On peut citer ici le système conçu et réalisé en 1969 sur la machine Regnecentralen RC 4000 par Per Brinch Hansen. Bien que ce système ait eu une diffusion restreinte, il est connu pour avoir fourni un modèle clair pour la gestion d’activités parallèles avec des contraintes de temps réel.
La convivialité perdue…
Lorsque l’ordinateur fonctionnait sans système d’exploitation sous le contrôle direct de l’utilisateur, ce dernier pouvait intervenir pendant l’exécution de ses programmes. Il pouvait par exemple arrêter l’exécution pour visualiser ou modifier au pupitre le contenu des cases de mémoire ; il avait en général la possibilité d’exécuter son programme en mode pas à pas, c’est-à-dire une instruction à la fois. En bref, il disposait d’une ébauche d’outils d’aide à la mise au point de ses programmes, mais les ressources de l’ordinateur étaient largement sous-utilisées.
Avec le traitement par lots, l’exploitation devient de plus en plus efficace, mais l’utilisateur a perdu tout contrôle sur l’exécution de ses programmes. Il se contente de déposer son travail au guichet du centre de calcul pour y récupérer les résultats quelques heures plus tard. Et tant pis pour lui si une erreur typographique mineure a arrêté la compilation : il va devoir corriger et recommencer. La hausse de l’efficacité étant, de ce fait, pour une part illusoire, on s’est attaché à améliorer le confort (et donc la productivité) de l’utilisateur. Dans le contexte d’ordinateurs relativement puissants, mais en petit nombre, la solution passait par le partage d’un ordinateur entre une communauté d’utilisateurs simultanés. Le temps partagé allait naître.
Notes
[1] Nous utilisons souvent le terme de « système » à la place de « système d’exploitation », lorsqu’il n’y a pas d’ambiguïté.
[2] La gestion de zones de taille variable impliquait de déplacer des programmes en mémoire, ce qui nécessita l’invention de nouveaux dispositifs techniques (registres de base).
[3] On estimait que le programme de l’OS/360 contenait environ un millier de fautes, et on considérait comme un exploit le fait de garder ce nombre stable à la sortie de chaque nouvelle version.
2. Le temps partagé
Dès 1961, on trouvait sous la plume de John McCarthy, le créateur du langage LISP et le fondateur de l’intelligence artificielle, ces lignes prophétiques : “ … computing may someday be organized as a public utility just as the telephone system is a public utility” (« … le calcul pourrait un jour être organisé comme un service public, exactement comme l’est le réseau téléphonique »). Au MIT (Massachusetts Institute of Technology), au début des années 1960, Fernando Corbatό lança un projet inspiré par cette idée, CTSS (Compatible Time-Sharing System), décrit plus loin.
Le principe du temps partagé est simple : il s’agit de tirer parti des différences de vitesse entre un ordinateur, cadencé alors à la microseconde, et un humain dont le temps d’interaction incluant réflexion et frappe de commande est de plusieurs secondes. L’ordinateur fonctionne alors comme un grand maître d’échecs jouant des parties simultanées. Lorsqu’il a traité la requête d’un utilisateur, il passe au traitement de celle d’un autre utilisateur, puis à un autre et ainsi de suite. Si les requêtes soumises demandent un temps de traitement court par rapport au temps humain, un fonctionnement équilibré est possible avec un temps de réponse acceptable, même avec des centaines voire des milliers d’utilisateurs (voir la figure ci-dessous).
Si le principe est simple, la mise en œuvre est délicate. La multiprogrammation permet bien d’avoir plusieurs programmes en mémoire, mais pas des dizaines dans des mémoires de quelques centaines de kilooctets. Des techniques matérielles ont été introduites pour ne charger en mémoire que les parties utiles des programmes (la pagination) ou pour partager des programmes entre plusieurs utilisateurs avec une copie unique en mémoire (la segmentation). Chaque utilisateur possède ainsi une mémoire virtuelle, qui lui donne l’illusion de disposer seul d’un grand espace adressable, isolé de celui des autres utilisateurs. Ces techniques, dont la maîtrise s’est révélée difficile, sont décrites dans un autre article, « Les débuts d’une approche scientifique des systèmes d’exploitation ».
La conservation des programmes et des données de nombreux utilisateurs impose de disposer de systèmes de gestion de fichiers sur disque et d’utilitaires permettant de constituer ou modifier ces fichiers, les éditeurs.
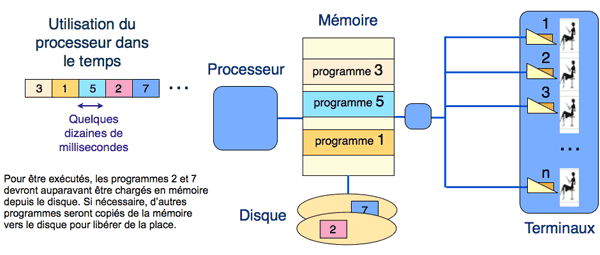
Organisation d’un système en temps partagé.
Des outils interactifs de mise au point de programme redonnaient à l’utilisateur les mêmes possibilités que lorsqu’il était seul au pupitre de l’ordinateur. L’utilisateur pouvait déclencher des travaux par la frappe de commandes élémentaires — construire un fichier, compiler un programme contenu dans un fichier donné, exécuter le contenu d’un fichier, etc. — mais aussi combiner ces commandes dans un vrai langage de programmation (shellscript) comprenant en particulier des procédures avec des paramètres. On est loin du jeu de commandes rudimentaire des premiers systèmes de traitement par lots.
Les précurseurs
Les premiers systèmes en temps partagé furent développés au début des années 1960. Le pionnier fut CTSS, qui fonctionnait en 1961 au MIT sur un ordinateur IBM 7094, modifié par IBM à la demande du MIT : taille de mémoire doublée, horloge programmable, dispositif de « trappe » (déroutement programmé lors de l’exécution de certaines instructions). CTSS était compatible avec le moniteur standard du 7094, qui pouvait s’exécuter en travail de fond (d’où le nom de Compatible Time-Sharing System).
En novembre 1961, lors de sa première démonstration, CTSS pouvait servir quatre utilisateurs, connectés via des terminaux mécaniques Flexowriter. Il fut mis en service effectif en 1963 et servait alors une trentaine d’utilisateurs, dont certains à distance, connectés par des lignes téléphoniques.
Les utilisateurs de CTSS disposaient de quelques outils, nouveaux pour l’époque, qui devaient devenir standard dans les systèmes futurs : éditeur de texte interactif, langage de commande évolué, exécutable au clavier ou à partir d’un fichier, messagerie permettant la communication entre utilisateurs, outil de formatage de texte pour l’impression.
Le principal apport de CTSS fut de montrer que l’idée du temps partagé était réalisable. Le MIT entreprit en 1963-64 un projet de plus grande ampleur, le projet MAC, qui devait donner naissance à Multics (voir plus loin).
Citons, sans être exhaustifs, quelques autres projets notables du début des années 1960.
- Le projet Genie fut mené à Berkeley sur un ordinateur SDS 930 de 1963 à 1967. Après une tentative manquée d’industrialisation des résultats de Genie, la plupart des membres de l’équipe (dont Butler Lampson et Chuck Thacker) rejoignirent le centre Xerox PARC où ils contribuèrent à la naissance de l’ordinateur personnel moderne (voir Xerox PARC et la naissance de l’informatique contemporaine).
- Le Dartmouth Time-Sharing System (DTSS) fut réalisé en 1963-64, initialement sur un General Electric GE-200. Il est connu pour avoir servi de support à BASIC, un langage de programmation simple spécialement dédié à un usage conversationnel. En 1970, le système, porté sur un GE-635, servait jusqu’à 300 terminaux.
- John McCarthy, qui avait quitté le MIT pour Stanford, réalisa en 1964-65 un système expérimental en temps partagé, Thor, qui fut le premier à utiliser des terminaux à écran.
De Multics à Unix
Multics. Le projet MAC (Man And Computer) débuta au MIT en 1963-64, sur la lancée du succès de CTSS. C’était un projet de grande envergure, largement financé par l’ARPA (organisme américain de financement militaire de la recherche). L’objectif principal était de réaliser un système en temps partagé capable de servir une très large communauté d’utilisateurs. Ce système fut appelé Multics (Multiplexed Information and Computing Service).
L’expérience de CTSS avait montré la faisabilité du projet, mais aussi le rôle crucial de dispositifs matériels spécialement adaptés au fonctionnement en temps partagé. Aussi fut-il décidé d’associer au projet deux entreprises industrielles : General Electric, qui devait concevoir et réaliser la machine support, et les Bell Labs, qui devaient participer à la conception du logiciel et notamment aux aspects liés à l’accès à distance. La réalisation de cet ambitieux projet se révéla plus difficile que prévu. Le système commença à fonctionner en 1969, sur l’ordinateur GE-645 conçu par General Electric, mais ses performances étaient alors très loin des objectifs fixés. Les Bell Labs se retirèrent du projet cette même année. En 1970, la division informatique de General Electric fut rachetée par Honeywell, qui poursuivit le développement de Multics comme produit commercial (voir plus loin). Le MIT continua, pour sa part, la réalisation de Multics comme projet de recherche et support de services.
Multics a été le lieu de nombreuses avancées conceptuelles et techniques, qui font de ce projet un des éléments fondateurs de la discipline des systèmes d’exploitation. En premier lieu, il a utilisé et perfectionné l’ensemble des concepts scientifiques de base : processus et synchronisation, segmentation et liaison dynamique, mémoire virtuelle paginée, système de gestion de fichiers, sécurité et protection, structuration, etc. En second lieu, c’est un système qui a été utilisé pendant plusieurs décennies, le dernier site Multics ayant été arrêté en 2000. Enfin, Multics est à l’origine d’Unix (voir ci-après), qui vit toujours aujourd’hui sous des formes diverses.
Du point de vue de l’utilisateur, Multics a mis en évidence l’importance de l’organisation structurée et du partage de l’information, via le système de gestion de fichiers. Le modèle de catalogues hiérarchiques, de protection sélective et de liens, établi par Multics, est toujours à la base des systèmes actuels.
Unix. Après le retrait des Bell Labs du projet Multics, quelques ingénieurs des Bell Labs ayant travaillé sur ce projet, emmenés par Ken Thompson et Dennis Ritchie, décidèrent de prendre le contrepied de ce système qu’ils jugeaient lourd et complexe, en utilisant leur expérience pour réaliser un système minimal sur une petite machine. Ayant accès à un DEC PDP-7 peu utilisé, ils commencèrent en 1969, pour leur propre compte et sans aucun soutien des Bell Labs, le développement d’un système conversationnel mono-utilisateur qu’ils baptisèrent Unics (jeu de mots sur Multics).
Devenu multi-utilisateurs, le système prit le nom d’Unix, fut porté sur PDP-11/20 et commença en 1970 à être soutenu et utilisé par les Bell Labs. La première installation commerciale eut lieu en 1972. Cette même année, Unix fut réécrit dans un nouveau langage de programmation, C, créé par Dennis Ritchie. Ce langage, proche de la machine physique — il permettait notamment de manipuler des adresses — présentait des constructions de haut niveau et son compilateur produisait un code efficace. Il devait devenir le langage privilégié pour l’écriture du logiciel de base.
Unix, devenu portable, commença alors à se diffuser rapidement dans les universités et centres de recherche, créant une communauté très active qui contribua à l’évolution du système. Diverses versions virent le jour, notamment chez plusieurs constructeurs de machines. Les tentatives d’unification n’aboutirent pas, et Unix, sous différentes variantes, est toujours en usage aujourd’hui.
Unix est organisé autour d’un noyau de base conçu pour être efficace, au détriment d’une structuration claire. Ce noyau sert de support à un interprète de langage de commande, le shell, dont il existe de nombreuses versions. Pour l’utilisateur, le langage de commande du shell permet de réaliser des tâches complexes par assemblage d’actions élémentaires, en séquence ou en parallèle. Le mécanisme des tubes (pipes) est particulièrement commode pour transmettre des informations entre des commandes successives. Le système de fichiers est dérivé de celui de Multics, avec un mécanisme de protection moins élaboré. De nombreuses « bibliothèques » (collections de sous-programmes) aident à la réalisation de programmes dans des domaines divers : calcul, manipulation de texte, interfaces graphiques, etc.
Les premiers systèmes commerciaux
Les premiers systèmes commerciaux en temps partagé ont suivi de près les prototypes de recherche. Ainsi, le PDP-10 de DEC, sorti en 1967, fut équipé du système TOPS-10. En 1969, les machines DEC PDP-10 et PDP-20 adoptèrent le système TENEX développé par Bolt, Beranek and Newman (BBN), qui devint très populaire notamment grâce à son efficacité et à la richesse de son langage de commande. Plus tard, vers 1976, DEC commença la production du VAX, famille d’ordinateurs de milieu de gamme dont le système d’exploitation, VMS, eut un succès considérable.
La série 360 d’IBM était orientée vers le traitement par lots. En 1966-67, IBM réalisa le 360-67, dont l’architecture était adaptée au temps partagé (mémoire virtuelle paginée, mécanismes de protection). Néanmoins, son système d’exploitation TSS (Time-Sharing System), échoua à fournir les performances requises. La solution vint du centre scientifique IBM de Cambridge (USA), qui réalisa sur le 360-67 un générateur de machines virtuelles, CP-67 (voir l’article à venir « Les débuts d’une approche scientifique des systèmes d’exploitation »). En combinant CP avec un système conversationnel mono-usager, CMS, on obtenait un système en temps partagé, CP/CMS [4], commode et efficace. Ce système devait fournir la base de la série suivante d’IBM, VM/370.
Honeywell dont la division informatique devint Honeywell-Bull en 1970, poursuivit le développement de Multics jusqu’en 1985. Le système fut implanté sur environ quatre-vingts sites. Après la fusion d’Honeywell-Bull avec la CII, Multics fut distribué par CII-HB, puis par le groupe Bull, et fut notamment acquis par plusieurs universités et centres de recherche français.
Vers la fin des années 1960, diverses sociétés de service utilisaient les systèmes en temps partagé pour fournir à leurs clients un service bureau, comprenant un accès à distance par terminal et une assistance technique.
Les débuts français du temps partagé
Les équipes de recherche françaises ont commencé à s’intéresser aux systèmes en temps partagé au milieu des années 1960. Deux colloques eurent lieu à Grenoble sur ce sujet, en 1966 et 1968. Des prototypes de systèmes en temps partagé étaient développés à cette époque à Grenoble (IMAG), ainsi qu’à l’Institut de programmation de Paris (université Pierre et Marie Curie).
Deux projets expérimentaux de systèmes en temps partagé sur la machine CII 10070 furent lancés un peu plus tard : Sam, en 1967, au Centre d’Études et de Recherche en Automatique (dépendant de Sup’Aéro), et Ésope [5], en 1968, à l’IRIA. Des Écoles furent organisées à partir de 1969 sous l’égide conjointe du CEA, de l’EDF et de l’IRIA, puis par l’AFCET, l’IRIA et le CNAM, pour diffuser les concepts et techniques des systèmes d’exploitation.
Sur le plan industriel, il faut noter la création en 1967, à Grenoble, d’un centre scientifique IBM sur le thème de l’utilisation conversationnelle des ordinateurs. Associant des chercheurs et ingénieurs de l’IMAG et d’IBM, ce centre apporta une contribution notable au développement de CP/CMS. Au début des années 1970, la CII réalisa les systèmes Siris 7 et Siris 8, respectivement pour ses ordinateurs CII 1070 et Iris 80. À la même époque, Bull General Electric devenu Honeywell-Bull, réalisait le système GCOS-64, inspiré de Multics, pour la famille de machines HB 64.
Où en est-on aujourd’hui ?
Avec l’apparition de la micro-informatique et la banalisation d’ordinateurs de plus en plus puissants, avec les changements d’ordres de grandeur des vitesses des processeurs, des tailles de mémoire et des disques, on pourrait penser que les systèmes modernes n’ont plus rien à voir avec les systèmes historiques. Il n’en est rien, et tous les concepts des systèmes actuels étaient bien connus au début des années 1970. L’un des systèmes phares, MacOS X [6], est directement construit sur une version d’Unix. Linux, une version open source d’Unix, équipe de nombreuses installations, tant dans les universités et centres de recherche que dans l’administration et l’industrie. La complexité des systèmes d’exploitation explique sans doute ce conservatisme, dont le résultat est de fait la normalisation autour d’un très petit nombre de systèmes.
Plutôt que sur une redéfinition de la structure de base des systèmes, l’accent a été mis sur l’interaction avec l’utilisateur (écrans graphiques et fenêtres, clavier, souris). Après leur introduction dans le Perq et l’Apple Lisa, c’est le Macintosh qui a popularisé ces idées qui sont maintenant reprises par l’ensemble des systèmes pour ordinateur individuel (voir à ce propos l’article « Xerox PARC et la naissance de l’informatique contemporaine »).
Les données ne sont plus de simples textes, mais des structures complexes comprenant des textes associés à des images, des sons et des films. La conservation fiable et à long terme de ces données fait largement appel à la virtualisation à grande échelle s’appuyant sur d’abondantes ressources réparties (cloud computing). Le souci d’économie revient sous une nouvelle forme : plutôt que le coût du matériel, c’est l’énergie consommée par ces concentrations de machines qu’il s’agit maintenant de réduire.
La vision centralisatrice du système telle qu’on la concevait au début des années 1970 est définitivement abandonnée au profit d’une structure répartie. Mais les questions éthiques posées par cette structure centralisée (ordinateur Big Brother) sont toujours présentes, avec la difficulté d’assurer confidentialité et sécurité dans un environnement où tout est en ligne.
Même si les ordinateurs individuels sont la plupart du temps oisifs, la course à la puissance de calcul se poursuit, tirée par les applications (images animées, simulation de systèmes complexes, jeux vidéo). Elle repose sur le parallélisme, soit à l’intérieur d’un processeur (structure multicœur), soit à l’aide de calculateurs interconnectés (grappes de milliers de machines ).
Enfin, la généralisation de l’informatique enfouie (embedded systems) dans presque tous les appareils de la vie courante a donné lieu au développement à la carte de systèmes adaptés à des appareils et à des applications spécifiques : téléphonie mobile (smartphones), réseaux de capteurs, automobile, avionique, etc. Ces systèmes étant en général plus petits et plus simples que les systèmes à usage général, on peut prévoir qu’il sera possible à terme de les certifier, c’est-à-dire d’établir rigoureusement leur conformité à leurs spécifications. Des avancées spectaculaires ont récemment eu lieu dans ce sens (voir l’article Les débuts d’une approche scientifique des systèmes d’exploitation).
Ce document fait partie d’une série consacrée à divers aspects de l’histoire de l’informatique, réalisée en conjonction avec un projet de musée virtuel sur ce thème, porté par l’association ACONIT.
Notes
[4] Un autre système notoire pour l’IBM 360-67 fut MTS (Michigan Terminal System), réalisé à partir de 1967 par un consortium de huit universités des États-Unis et du Canada. Distribué sur une quinzaine de sites, il devait fonctionner en production jusqu’en 1997.
[5] Voir l’article (PDF) « Ésope : une étape de la recherche française en systèmes d’exploitation », 7e Colloque sur l’Histoire de l’Informatique et des Télécommunications, Rennes, 2004.
[6] Notons toutefois que la première version du système d’exploitation du Macintosh avait une structure radicalement différente de l’organisation classique en processus. La structure de base était une « boucle d’événements », un événement étant déclenché soit par une interruption, soit par le traitement d’un autre événement. Le système traitait successivement les événements présents dans la boucle.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

