
Ma randonnée informatique
Je suis en retraite depuis 23 ans, j’ai toujours souffert d’une mauvaise mémoire, et lorsque je songe au temps écoulé depuis mon entrée dans le domaine de ce qui ne s’appelait pas encore l’informatique, j’ai l’impression de voir depuis une montgolfière (spatio-temporelle) mon long cheminement pas à pas dans la montagne. J’aime la montagne.

Marion Créhange au début de sa randonnée informatique © Colpart
Je pars pour une randonnée de plusieurs jours. Je suis sur un sentier, le jour n’est pas encore levé, je démarre d’un joli petit hameau de quelques vieilles cabanes, et, pas à pas, je monte, heureuse de l’effort intense que je fournis, sans bien savoir quel est mon but mais certaine que le panorama y sera beau. À chaque tournant du sentier, je découvre de nouvelles et belles perspectives, des pentes plus ou moins raides, et, ce qui est à noter, c’est que je ne vois que le paysage directement visible, sans réellement me rendre compte de l’immensité et de la beauté de l’espace dans lequel je progresse. Pendant la plupart des étapes, je ne suis pas seule, je mène un petit groupe, dans le cadre d’une organisation d’ensemble ; à chaque pause, je fais le point, dois choisir une direction, le rythme à adopter, la façon de franchir un obstacle… Le soir, au refuge, j’ai l’occasion d’enrichir mon expérience par des échanges avec les autres randonneurs. Et de plus en plus souvent au fur et à mesure de la longue progression, j’ai des échappées sur les sommets enneigés qui dominent mon parcours de moyenne montagne.
Chaque étape de ma « randonnée informatique » peut se décrire en quatre phases : 1 CHEMINER – la marche elle-même, avec ses événements, ses incidents, ses diversions ; 2 OBSERVER – amasser l’expérience ; 3 INTÉGRER – améliorer la vision d’ensemble du tronçon et du parcours, et, progressivement, de la montagne ; 4 ÉLARGIR – élaborer des décisions sur la direction à prendre et le but à poursuivre pour le parcours suivant et l’ensemble de la randonnée.
Le démarrage

Jean Legras © Bernard Legras, CC BY-SA 4.0, via Wikimedia Commons
{kind=link}
Tout a commencé au terme de l’année 1956-57. Jean Legras, professeur de mécanique rationnelle, m’a proposé de profiter de ma dernière année de licence, où je préparerais le certificat de physique générale (certificat-épouvantail pour les non-physiciens), pour expérimenter avec lui la calculatrice électronique IBM 604 à laquelle IBM lui donnait accès quelques heures par semaine. Pour l’IBM 604, un programme se matérialisait en reliant des trous d’un tableau de connexion par des fils munis de fiches. Fils très nombreux car il fallait désigner opérateurs et opérandes ; nombreux… même si la machine possédait environ 10 mots de mémoire et autorisait 70 pas de programme, dont seuls les 20 derniers étaient répétitifs ! Comme nous utilisions la machine qui nous était prêtée d’une manière détournée de son usage original, ses fiches devaient percer une feuille de papier qui était appliquée sur le tableau de connexion pour indiquer l’affectation des trous spécifique à notre usage. Un souvenir cuisant est resté gravé dans mes doigts : pour préparer un nouveau programme, il fallait commencer par enlever toutes les fiches du programme précédent, coincées par des confettis, en tirant si fort que la fin du démontage nous laissait les doigts en sang.

Les cartes perforées de l’IBM 650
À la rentrée 1958, Jean Legras a obtenu que le 3e cycle de Maths devienne de Maths pures et appliquées en accueillant l’option Analyse et Calcul Numériques ; ceci malgré une certaine hostilité des mathématiciens, en particulier Jean Dieudonné et Jean Delsarte, tous deux membres éminents du groupe Bourbaki. C’est alors que Jean Legras obtient la venue d’un IBM 650, qui permet la naissance, place Carnot, du Centre de calcul automatique qui deviendra l’Institut universitaire de calcul automatique (IUCA), ancêtre du CRIN puis du LORIA1. La première promotion de l’option a accueilli quatre étudiants dont moi ; mais, dès le début, responsable des TP, j’ai joué le rôle d’assistante, pour lequel j’ai été formellement nommée en février 1959. J’ai passé l’examen final avec mes amis

Les cartes perforées de l’IBM 650
Découverte d’un terrain fertile
![]()
Dès ma nomination comme assistante (1959), j’ai eu l’occasion d’apporter mes service à des universitaires variés : le cristallographe Raymond Kern, la physicienne S. Roizen, qui dès cette première étape m’ont permis de mesurer la difficulté de bien calibrer les recours à l’informatique, le premier par témérité, la seconde par prudence excessive. Ensuite des chimistes et des physiciens (J-L. Rivail, A. Pentenero, J. Villermaux, D. Paulmier, M. Felden) ont apprécié la facilité que leur apportait le code de programmation, objet de ma thèse de 3e cycle, pour programmer eux-mêmes leurs applications, avec mon aide éventuelle. Ont suivi des coopérations diverses et toujours enrichissantes, en particulier avec Pont-à-Mousson SA et des universitaires, surtout à la Faculté des Lettres. Les paquets de cartes perforées fleurissaient allègrement.
![]()
C’est ainsi qu’a émergé le sujet de ma thèse de 3e cycle, soutenue en mars 1961. L’idée est de créer un langage de programmation (CDP pour code de programmation), plus synthétique que le langage machine, un « langage d’assemblage ». Il est beaucoup moins évolué que Fortran qui vient de naître mais que nous n’avons pas ; mais il est simple à utiliser et apporte une réflexion sur des questions de fond : il permet à un même programme d’être interprété ou compilé, introduit les concepts de sous-programmes, d’indexation des opérandes, d’optimisation du rangement sur le tambour, de modularité et de paramétrage permettant des extensions du CDP vers des utilisations spécialisées. Le CDP a fait l’objet du Cahier n° 1 du Groupement des utilisateurs scientifiques des ordinateurs IBM 650, en octobre 19602.
![]()
Est-ce de la recherche ou du service ? Un peu les deux. Cette réalisation est dictée par le besoin d’utilisateurs mais existe la volonté de dépasser la simple fabrication d’un outil pour en tirer des concepts et des mécanismes. Elle m’a aussi amenée à réfléchir par exemple aux erreurs de chute et à la sensibilité de certains calculs à de très petites variations des données. C’est ainsi que j’ai l’honneur d’être quelquefois citée comme ayant anticipé, dans ma thèse de 3e cycle en 1961, sur la théorie du chaos : « Lorenz venait de mettre en exergue la sensibilité aux conditions initiales (déjà observée en analyse numérique dans des résolutions d’équations différentielles sur ordinateur, entre autres par Marion Créhange à l’Université de Nancy)… ». Les deux premiers problèmes qui m’ont été confiés, l’un trop ambitieux, l’autre trop étroit, auraient pu m’amener à réfléchir à la question de la complexité des programmes, ce qui n’a pas été le cas. Par ailleurs, j’ai remarqué bien plus tard, avec étonnement, qu’il n’y a aucune bibliographie dans ma thèse !
![]()

Claude Pair © Interstices
Il est certain qu’à l’époque je n’ai pas eu suffisamment d’ouverture vers ce qui se faisait ailleurs. De même, je n’ai sans doute pas beaucoup réfléchi à la nature des langages de programmation, à leur grammaire, à leur analyse, à la compilation, que je n’ai découvertes qu’en revenant à l’informatique après deux ans d’une parenthèse consacrée à l’étude et à l’application de la formation des adultes, au CUCES (Centre universitaire de coopération économique et sociale). Je les ai abordées en faisant partie de l’équipe de recherche de Claude Pair pour la construction d’un compilateur ALGOL 60, en 1965. À cette époque, Claude Pair termine sa thèse d’État « Étude de la notion de pile, application à l’analyse syntaxique ». Il a constitué une petite équipe pour mettre à l’épreuve ses idées et progresser dans la conception des compilateurs. Notre compilateur, en l’occurrence, est basé sur une analyse ascendante de la chaîne de caractères composant le programme pour construire de façon déterministe un arbre syntaxique permettant de produire le programme objet. Cet algorithme est basé sur l’utilisation d’une matrice de précédence exprimant l’ordre de priorité sur les caractères ; les piles y jouent un rôle primordial. J’ai rejoint cette équipe très soudée comme responsable du traitement des procédures récursives.
Ce travail d’équipe passionnant a abouti à plusieurs thèses de 3e cycle ; le compilateur a été construit mais n’a jamais pu être exploité. Il faut dire qu’à cette époque, le manque de capacité des ordinateurs et de moyens humains de développement interrompait de nombreux projets avant qu’ils soient effectivement appliqués. En tout cas, ce projet a jeté des bases essentielles du laboratoire qui a été créé par Claude Pair pour regrouper tous les chercheurs en informatique de Nancy quel que soit leur rattachement universitaire, et qui deviendra le CRIN. Lire à ce sujet L’informatique de Claude Pair3.

Jean-Claude Gardin © Colpart Laetitia Gardin
En ce qui me concerne, j’avais déjà passé ma thèse de 3e cycle et, après cette entrée en matière formatrice et exaltante, j’ai eu la chance en 1966 d’aller faire un stage des plus intéressants et marquants au Centre d’analyse documentaire pour l’archéologie (CNRS) de l’archéologue Jean-Claude Gardin à Marseille. C’est ce stage, la puissance intellectuelle de J.-C. Gardin et de son équipe, qui m’ont déterminée à m’orienter vers les questions de recherche d’informations. Leurs idées ont continué longtemps à enrichir mon horizon dans ce domaine, particulièrement sur le plan sémantique. Et cet intérêt ne m’a pas quittée.
NDLR : Plus précisément sur ce sujet, lire « Apports réciproques entre informatique et sciences humaines« de Marion Créhange4.
Le bel étage de la forêt : l’information, comment s’y retrouver ?
![]()
C’est pas à pas, par diverses applications variées et très riches que j’ai approfondi ma recherche sur la recherche d’information, dans le laboratoire créé par Claude Pair. Chemin caillouteux mais combien passionnant ! J’ai ainsi, par exemple, participé à la conception d’une base de données d’informations multimédia sur les rues et carrefours de la ville de Nancy (avec Marc Gabriel), à la gestion de dossiers médicaux (j’y ai eu plusieurs coopérations successives, difficiles et enrichissantes), à la gestion d’une base de coupes géologiques (avec le CRPG). J’avais, bien longtemps auparavant, mis un premier pas dans ce domaine lorsque le doyen Aubry de la faculté des sciences avait demandé à Jean Legras si je pouvais l’aider en créant une gestion des étudiants de la faculté. Prévu pour… quinze jours par J. Aubry, ce fut un véritable fardeau pendant dix mois, tant étaient nombreuses et insoupçonnées les exceptions aux caractéristiques simples des étudiants « standard ». Cette expérience aurait pu m’ôter à jamais le goût de la gestion et de la recherche d’information ! Fermons cette parenthèse.

Lucie Fossier © UPFH
Ces applications se sont déroulées sous l’égide du CRAL (Centre de recherche et d’applications linguistiques) dont j’ai fait partie de l’équipe de direction de 1966 à 1970. C’est ainsi que, vers 1966, l’historienne Lucie Fossier a sollicité ma coopération pour traiter des actes diplomatiques du Moyen-Âge 5, pas tellement du point de vue juridique mais surtout pour exploiter leur richesse de description des lieux et sociétés. Nous avons créé un système assez riche, avec des mots-clés et des relations, un thesaurus, et des questions modulables ; peut-être trop riche car ce système n’a jamais été exploité, suite au départ de Lucie Fossier, avec qui j’ai cependant continué à entretenir des relations scientifiques et amicales.
Mais une première version du système avait été réalisée de façon intéressante : j’avais découpé le problème en sept parties, chacune donnée comme sujet de long TP à une équipe d’étudiants de 2nde année du département informatique de l’IUT ; un des étudiants a été chargé, à la fin, de réunir ces sept morceaux. Travaux pratiques très motivants pour les étudiants, mais résultat final peu exploitable !
![]()
Ces applications m’ont fait acquérir une bonne connaissance de la problématique. Petit à petit, grandement aidée par Claude Pair, est née l’idée de ma thèse d’État que j’ai soutenue en 1975, avec comme titre : Description formelle, représentation, interrogation des informations complexes : système PIVOINES6.
Les premières lignes de celle-ci donnent le ton :
« PERMETTRE UNE ÉCONOMIE D’EXPRESSION ET MÊME DE PENSÉE : n’écrire que ce qui est pleinement significatif, tel est le rêve de nombreux auteurs de programmes. En effet, contrairement à la communication humaine qui heureusement laisse une place au superflu, vecteur de chaleur et de poésie, la communication entre l’Homme et l’ordinateur est en général d’autant plus satisfaisante qu’elle est plus dépouillée. »
![]()
L’objet de la thèse est de n’avoir à décrire, pour un système complexe d’interrogation de base de données, que la structure logique de la base et l’expression, logique aussi, des questions ; c’est le système qui, étant donnée une description des choix d’implantation de la structure de données, fera les traductions nécessaires.
Ainsi, le système PIVOINES (langage pivot pour l’interrogation d’ensembles structurés) est un métasystème qui comporte d’une part un formalisme de description de structures de données et d’autre part un langage d’accès, descriptif et non actif. Une demande d’accès peut être modélisée par un pochoir à appliquer sur l’information. Ses parties pleines représentent celles dont la présence est imposée, et les parties creuses représentent les parties objets de la recherche : elles sont spécifiées par leurs liens, éventuellement très complexes, avec les parties pleines et transparaîtront à chaque application du pochoir. J’ai défini une syntaxe et une sémantique des motifs qui servent à représenter les pochoirs et introduit des niveaux intermédiaires dans les concepts et structures afin de gérer l’indépendance. Le compilateur principal est proche de ce que nous avions utilisé en construisant le compilateur Algol 60 en 1965. Le système donne la possibilité de partager la responsabilité de la stratégie de recherche entre lui-même et l’utilisateur.
Ma thèse contient une analyse fine des traitements ainsi que certains programmes mais, faute de moyens efficaces de développement, le système PIVOINES n’a jamais réellement tourné !
![]()
Pendant cette période, ce sujet a fait l’objet de plusieurs publications diversement centrées sur la thèse et à des degrés divers d’abstraction, dans la RAIRO (Revue française d’automatique, informatique, recherche opérationnelle)7 ; pour l’AFCET (Association française pour la cybernétique économique et technique)8 notamment dans le cadre de l’École d’été de Grenade en 1973 ; dans un colloque sur les bases de données sous l’égide de l’ACM, d’EDF, de l’Institut de programmation et de l’IRIA (maintenant Inria)9 ; à l’issue d’une convention du BNIST (Bureau national de l’information scientifique et technique) ; etc. Plusieurs DEA et une thèse de 3e cycle ont également porté sur la réalisation de certains modules de PIVOINES.

Colette Raffoux © Colpart
Très enrichissante et enthousiaste a été la coopération avec Colette Raffoux, du Centre de transfusion sanguine, pour une application de PIVOINES à propos du système HLA (antigènes des leucocytes humains). Amorce prometteuse mais sans suite, comme souvent à cette époque, Colette Raffoux a quitté Nancy de façon imprévue, appelée par le Prix Nobel Jean Daussé pour rejoindre son équipe à France Transplant pour créer et diriger France Greffe de Mœlle. Ce travail en commun nous a cependant permis de mettre en valeur le très grand intérêt de l’indépendance des niveaux physique et logique de la description des documents et des requêtes. En plus de l’utilité pratique de ce dispositif, ce fut un moyen d’étude scientifique et de manipulation des différents constituants d’un système d’information et de leurs corrélations.
Une étape d’exploration
![]()
Continuant à réfléchir au traitement des « grands » ensembles de données, j’ai participé à divers projets, principalement dans le cadre des PRC (Projets de recherche coordonnée) « Ateliers flexibles » et « BD3 » (Bases de données de 3e génération).
![]()
Si ces actions m’ont intéressée et ont complété ma formation dans ces domaines, je n’y ai pas vraiment trouvé l’envie de les choisir comme champ de recherche durable.
![]()

Roger Mohr © Inria / Photo G. Huet
Petit à petit, a mûri l’idée que ce qui m’intéressait le plus se trouvait dans le domaine « Informatique et Science de l’Homme », comme ébauché dans l’article « Un système de gestion de base de données évolutif à interrogation déclarative : PIVOINES »10. Mais c’est vers 1981 que j’ai vraiment pris le tournant de ce qui allait me passionner désormais. Ceci grâce à Roger Mohr, spécialiste des images dans notre laboratoire à l’époque, qui venait de recevoir une proposition de coopération d’Henri Hudrisier pour travailler sur l’utilisation de son imageur documentaire en mosaïque et l’interrogation de bases de données d’images et de texte ; Roger a proposé que ce soit moi qui réponde à cette sollicitation.
EXPRIM, la dernière étape, à l’approche de la haute montagne
![]()

Henri Hudrisier © DR Collection Hudrisier
En 1983, j’ai constitué la petite équipe EXPRIM (expert pour la recherche d’images) autour de la coopération avec Henri Hudrisier et, rapidement, dans le cadre d’un projet européen ESPRIT 1 : passionnant et formateur, avec quelques nuits blanches. À ce projet coopèrent également la Société européenne de propulsion (SEP) , le Bureau Marcel Van Dijk et le Service des archives photographiques (Direction du patrimoine) du ministère de la Culture et de la Communication. Il s’agissait d’une étude de faisabilité d’un système intégré de recherche d’images associant approches visuelle et textuelle dans la continuité de l’expérience déjà acquise avec l’imageur documentaire.
Nous avons conçu le système EXPRIM, pour l’interrogation souple et interactive de bases de données d’images et de texte. Quel en est le principe ? Les données de base sont une base d’images accompagnées de descriptions. L’utilisateur U exprime une requête, traitée par l’interrogation de la base de descriptions. Jusque là, rien d’original. Le résultat de cette première recherche est un ensemble d’images, qui sont alors présentées à U. Et c’est à ce moment qu’entre en jeu un bouclage de pertinence (relevance feedback) : U est prié d’indiquer les images lui convenant et celles qui ne lui conviennent pas. Le système cherche alors, d’après les descriptions (sans traiter les images elles-mêmes), les raisons pouvant expliquer le choix de U. Cette étape a comme résultats pour le système de mieux connaître le besoin de U, mais aussi pour U lui-même de faire naître une meilleure conception de son besoin réel ou de le faire évoluer11. Exemple significatif : un journaliste souhaitant illustrer de façon originale un article. On peut aussi penser à un professeur, à un publicitaire… Nous sommes ici dans le domaine de la Communication Homme-machine et, plus généralement, de l’intelligence artificielle12.
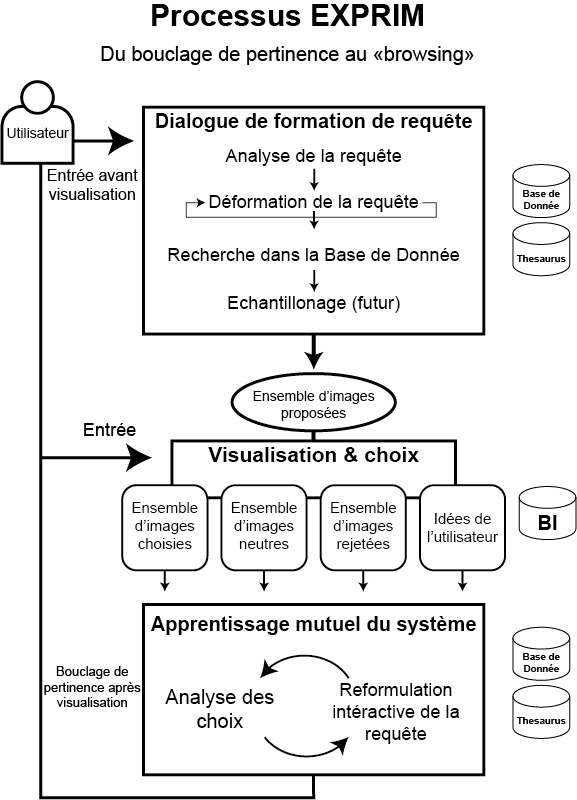
La réalisation du système – sous forme de la maquette RIVAGE – a été réalisée par Gilles Halin et appliquée à une collection de photos d’Eugène Atget appartenant au Service des archives photographiques du ministère de la Culture ; ceci en lien étroit avec Henri Hudrisier et son imageur. Auparavant, Mekki Boukakiou avait soutenu une thèse sur la spécification du protocole et de ses composants à base de types abstraits de données.
![]()

Gilles Halin © CNRS
De nombreuses idées sont nées autour de ce projet initial et ont au fil du temps constitué la raison d’être de l’équipe EXPRIM jusqu’à mon départ en retraite en 1997. Rapidement, nous avons rapproché ce processus d’un processus d’apprentissage (mutuel) du système et de l’utilisateur. Nous avons utilisé l’approche « apprentissage symbolique par exemples et contre-exemples ». Dans ce cadre, le concept à apprendre est représenté dans le thesaurus en attachant à chaque terme un poids mesurant la capacité de celui-ci à exprimer le besoin de l’utilisateur. Nous l’avons appelé « apprentissage à court terme » car à l’échelle de l’interrogation en cours. C’est sur ce sujet que Gilles Halin a soutenu sa thèse : « Apprentissage pour la recherche interactive et progressive d’images : processus EXPRIM et prototype RIVAGE ».
![]()

Malika Smail © A. Tabbone
De là est venue l’envie d’élargir ce concept, passant de l’acquisition d’aptitude au cours d’une session à cette acquisition au fur et à mesure de la vie du système. C’est sur ce thème que Malika Smaïl a soutenu sa thèse intitulée Raisonnement à base de cas pour une recherche évolutive d’information : prototype Cabri-n : vers la définition d’un cadre d’acquisition de connaissances. Le sujet de cet « apprentissage à long terme » est le système lui-même, essentiellement sa stratégie mais aussi les diverses connaissances qu’il met en œuvre13.

Brigitte Simonnot © Colpart
Dans la plupart des recherches en informatique – et même des applications –, une phase essentielle est la modélisation. C’est sur ce thème que porte la thèse de Brigitte Simonnot, intitulée Modélisation multiagent d’un système de recherche d’information multimédia à forte composante vidéo. Une tout autre modélisation a ensuite fait l’objet de la thèse de Jean-Charles Lamirel intitulée Application d’une approche symbolico-connexionniste pour la conception d’un système documentaire hautement interactif : le prototype NOMAD.

Jean-Charles Lamirel © Colpart
Grâce à une intense coopération avec l’équipe grenobloise d’Yves Chiaramella, nous avons participé à divers groupes de travail européens, sources d’énormément de progrès et d’amitiés, et en particulier MIRO autour de la Recherche multimédia d’information et MIRA, autour des systèmes interactifs d’informations multimédia et de leur évaluation.
Lors du départ pour Paris de Colette Rolland, l’équipe EXPRIM s’est élargie avec l’arrivée d’Odile Foucaut et Odile Thiéry, qui ont amené leurs compétences et leur intérêt pour développer le thème « traitement d’informations complexes, nuancées et/ou imparfaites ». D’ailleurs, j’étais depuis longtemps consciente de la difficulté et de l’intérêt des « défauts » des informations et des besoins : incertitude, incomplétude, variabilité, diversité des média, besoins mal définis et évolutifs… Les applications médicales rendaient flagrants ce besoin et sa richesse.

Odile Thiéry © Inria

Odile Foucaut © Colpart
La fusion s’est très bien déroulée et des applications des principes d’EXPRIM se sont développées dans divers domaines : économie, identification de champignons, etc. Nous avons ainsi mis en évidence un double intérêt de la recherche interactive d’informations multimédia14 :
-
La documentation iconographique en elle-même (recherche iconographique comme but) : postes d’interrogation dans les agences de presse et photothèques, les journaux, les agences de publicité, les musées, les laboratoires, les hôpitaux (bases de données d’images médicales). La plupart des études menées sur l’apprentissage à différentes échelles et sur les diverses améliorations du processus EXPRIM et du prototype RIVAGE se situent dans cette voie ;
-
Les diverses applications de la démarche cognitive de la recherche interactive (recherche iconographique comme moyen) : diagnostic (ou identification) aidé par l’image, en médecine, mais aussi en maintenance industrielle ou en agriculture (identification d’espèces naturelles par exemple, comme dans le système MYCOMATIC, crée par Odile Foucaut et Noureddine Mouaddib)… ; aide, par l’image, à la vente par correspondance ; aide à la découverte ou à la création, grâce à l’alliance de l’apprentissage réciproque et du pouvoir d’évocation qu’apporte la visualisation d’une image ou d’une mosaïque d’images. Un intérêt particulier a été porté au fait qu’un processus d’apprentissage à court terme comme EXPRIM peut avoir un très grand intérêt pédagogique. Cette idée a été développée par Odile Thiéry et Amos David autour de la gestion, au cours d’une session d’enseignement personnalisée, d’un modèle de l’apprenant.
![]()
Le processus EXPRIM donne un rôle important à la vision des images. Lorsque l’utilisateur se voit proposer un ensemble d’images répondant plus ou moins à sa requête, il peut avoir un raisonnement plutôt restreignant, l’amenant à préciser son besoin. Mais il peut aussi avoir une démarche d’élargissement, d’inspiration, la vision de certaines images lui donnant des idées de champs d’intérêt qu’il ne soupçonnait pas. C’est la combinaison de ces deux tendances qui fait tout l’intérêt du processus, dans la satisfaction du demandeur, dans l’aide à la découverte, dans la démarche de structuration de la connaissance et donc dans l’enseignement.
Inutile de préciser que mon domaine de recherche ne relève pas stricto sensu de la recherche en intelligence artificielle, mais en est un champ d’application et donc d’expérimentation très sensible et riche. C’est aussi dans cet esprit que j’ai participé aux diverses réunions et rédactions du pôle Grand-Est de recherche cognitive « Cognisciences ».
Peu d’années avant ma retraite, en 1995, j’ai eu la chance d’être professeure invitée à l’Université Laval, où j’ai été chargée d’un cours de DEA sur la recherche d’information iconographique. À cette occasion, j’ai été sollicitée pour écrire un article dans la revue L’Expertise Informatique15. Lors de mon départ en retraite, l’équipe EXPRIM s’est dispersée, avec des départs dus à une promotion et des accueils dans d’autres équipes. Mais l’esprit EXPRIM a subsisté chez la plupart des membres de l’équipe.

Dessin réalisé par un ami chercheur nancéien et offert à Marion lors de la dernière réunion du groupe MIRO à laquelle elle participait, organisée à Nancy en 1997.
En conclusion
Je suis consciente de la chance que j’ai eue d’être très jeune et très tôt happée par le domaine passionnant de l’informatique. Ce métier m’a apporté un grand lot de satisfactions – et aussi quelques regrets.
D’abord, de ne pas avoir eu une culture suffisante en mathématiques, pour des raisons diverses indépendantes de ma volonté, en particulier un problème de santé. Ensuite, de ne pas avoir assez lu de publications scientifiques. Il faut dire que les moyens de diffusion étaient beaucoup moins riches que maintenant ; et d’ailleurs, pour la raison miroir, je n’ai pas assez écrit ! Beaucoup d’idées développées n’ont pas pu avoir de réalisation et, encore moins, de mise en application : lacune due au manque de temps d’un enseignant-chercheur très attaché aux différents volets de sa mission, manque de moyens et de structures de développement, jeunes chercheurs manquant de temps également, etc.
Un autre regret que j’ai éprouvé presque tout au long de ma carrière est d’être venue trop tôt ! C’est particulièrement flagrant dans le domaine de la recherche d’information, domaine où, à l’époque, l’information à fouiller manquait cruellement, tout particulièrement lorsque j’ai travaillé sur des bases de données d’images indexées ! Alors qu’avec Internet… Internet a aussi ouvert l’horizon des chercheurs et a facilité les contacts et la communication. Je ne parle pas de la puissance des ordinateurs. D’ailleurs, le manque de puissance nous a obligés à certaines réflexions que nous n’aurions pas eues sinon. Ainsi, maintenant, certains problèmes sont traités avec des algorithmes moins subtils qu’avant, car le temps et le volume d’information ont moins besoin d’être économisés, contrairement au temps humain.
Je regrette aussi de ne pas vivre en acteur les actuels progrès théoriques mais surtout certaines applications extraordinaires. Je suis très impressionnée, maintenant, d’avoir participé à une évolution historique… et de ne m’en être pas complètement rendu compte !
Après mon départ en retraite, j’ai complètement abandonné la recherche, mais j’ai pu témoigner de mon expérience et de mon enthousiasme dans de nombreux cadres, en particulier l’Académie de Stanislas qui m’a accueillie16. Et la dynamique de ma carrière s’est également prolongée par une intense vie associative.
J’ai été une enseignante-chercheuse heureuse. Très accaparée par la recherche et l’animation scientifique, administrative et humaine de mon équipe, je n’ai pas du tout négligé l’enseignement et les tâches de gestion universitaire. J’ai eu des coopérations passionnantes avec des partenaires de tous horizons et de toutes spécialités, médecins, géologues chimistes, historiens, ingénieurs, et j’ai gardé et développé un goût prononcé pour l’interdisciplinarité. J’ai aussi mis en œuvre un mécanisme qui nous est cher : l’appui réciproque puissant entre théorie et pratique. Enfin, j’ai essayé d’appliquer les bons principes que Claude Pair nous avait inculqués, en particulier un esprit critique qui, respectant les idées de mes chercheurs ou de mes partenaires, cherche à en promouvoir la qualité scientifique.
Bibliographie
- Créhange M., Haton M.-C. : « L’informatique universitaire à Nancy : un demi-siècle de développement » (incluant entretiens avec Claude Pair et Jean-Pierre Finance), Technique et Science Informatiques, RSTI série TSI, vol.33, n° 1-2/2014, Hermès-Lavoisier. Repris dans 1024 – Bulletin de la société informatique de France, SIF, n° 3, mai 2014.
- Cahier n° 1 du groupement des utilisateurs scientifiques des ordinateurs IBM 650, en octobre 1960.
- Créhange M., Lescanne P., Quéré A. : « L’informatique de Claude Pair », à paraître dans 1024 – Bulletin de la SIF, numéro 18, novembre 2021, pp. 3-27.
- Créhange M. « Apports réciproques entre informatique et sciences humaines ». Académie de Stanislas, 17 juin 2005.
- Fossier L., Créhange M. : « Un essai de traitement sur ordinateur des documents diplomatiques du Moyen Âge », ANNALES (Économies, Sociétés, Civilisations), n° 1, janvier-février 1970.
- Créhange M. : « Description formelle, représentation, interrogation des informations complexes : système PIVOINES », thèse d’État en Sciences Mathématiques, 2 décembre 1975.
- Créhange M. : « Description, représentation, interrogation, traitement des informations structurées. Langage PIVOINES », RAIRO, série bleue, septembre 1974.
- Créhange M. : « Description, représentation, interrogation des informations structurées », 3e École d’été de l’AFCET, Grenade, 13 juillet 1973. – Créhange M. : « Interrogation de données à structure complexe – Système PIVOINES », AFCET Panorama de la nouveauté informatique en France, Gif-sur-Yvette, 3-4-5 novembre 1976.
- Lonchamp J., Créhange M. : « Indépendance des niveaux de structure, langage déclaratif d’accès et automatisation des choix de stratégie dans le SGBD PIVOINES », Institut de Programmation, Colloque sur les bases de données, modèles, mise en œuvre, évaluation, Chapitre français de l’ACM, EDF, IRIA, juin 1979.
- Créhange M., Meyer F. : « Un système de gestion de base de données évolutif à interrogation déclarative : PIVOINES », Cahier n° 5 du groupe de travail « Informatique et Sciences de l’Homme » de l’AFCET, avril 1979.
- Halin G., Créhange M., Kerekes P. : « Machine learning and vectorial matching for an image retrieval model, EXPRIM, and the system RIVAGE », ACM SIGIR 90, 13th international conference on research and development in Information Retrieval, JL Vidick (réd), Presses universitaires de Bruxelles, septembre 1990 (pp. 99-114).
- Créhange M. : « Bases d’images et Intelligence Artificielle », in Image et vidéodisque, sous la direction de Serge Cacaly, La Documentation Française, septembre 1988.
- Smaïl M., Créhange M. : « Case-based reasoning meets Information Retrieval », Proceedings RIAO’94 on Intelligent Multimedia Information Retrieval Systems and Management, New York, octobre 1994 (pp. 172-184).
- Créhange M. : « Par et pour la recherche d’images, EXPRIM », Le Médiéviste et l’Ordinateur, vol.19, 1988 (pp. 15-21 et éditorial).
- Créhange M. : « Recherche d’information et apprentissage : interrogation interactive de bases d’images », L’Expertise Informatique, vol. 1 n° 3, Association Professionnelle des Informaticiens du Québec, Québec, automne 1995.
- Créhange M. « Instruire par la pratique. L’apprentissage, des premiers Hommes à l’apprentissage des ordinateurs ». Discours de réception. Académie de Stanislas, 25 juin 2019.
Certains ayant-droits n’ayant pu être contactés, les illustrations de cet article ne sont pas libres de droit, sauf mention contraire. Si vous souhaitez réutiliser certaines d’entre elles, ou si vous êtes un ayant-droit, merci de contacter l’équipe d’Interstices à interstices@inria.fr
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Marion Créhange
Marion Créhange était l'une des pionnières de l'informatique à l'Université de Nancy où elle a soutenu la première thèse informatique de France en 1961. Elle a ensuite rejoint le Centre de Recherche en Informatique de Nancy (CRIN) où elle s'est spécialisée dans les systèmes d'information. En 1983, elle a fondé l'équipe de recherche EXPRIM (Experts pour la Recherche d'Image). Elle était également professeure émérite de l'université de Lorraine, laboratoire LORIA, jusqu'à son décès en mars 2022.