
La révolution de l’apprentissage profond
Une première version de cet article est parue dans la revue Pour la Science, n°465, en juillet 2016.
L'essentiel
L’intelligence artificielle telle qu’on l’imaginait dans les années cinquante a été plus difficile à développer que prévu.
Depuis quelques années, le domaine a connu un grand renouveau avec les techniques de l’apprentissage profond, inspirées des réseaux de neurones du cerveau.
Un réseau de neurones artificiels à apprentissage profond acquiert sans cesse de l’expertise à partir de nouvelles données.
Un tel réseau a déjà battu un joueur de go professionnel, d’autres reconnaissent des images ou la parole...
Les ordinateurs ont suscité beaucoup d’enthousiasme et d’attentes dans les années cinquante, quand ils ont commencé à battre au jeu de dames certains amateurs de bon niveau. Dans les années soixante, les chercheurs espéraient reproduire les fonctions du cerveau humain avec un ordinateur et des programmes informatiques. L’ « intelligence artificielle » égalerait alors les performances humaines pour tous les types de tâches. En 1967, le spécialiste Marvin Minsky, du MIT (l’institut de technologie du Massachusetts), affirmait que les défis de l’intelligence artificielle seraient résolus en une génération.
Cet optimisme était prématuré. Les logiciels de l’époque visant à aider les médecins à établir de meilleurs diagnostics et les réseaux modélisés d’après le cerveau humain pour reconnaître le contenu de photographies n’ont pas tenu les promesses de l’engouement initial. Les algorithmes étaient trop simples et manquaient de données, nécessaires pour parfaire leur apprentissage. La puissance de traitement informatique était également insuffisante pour faire tourner des machines capables de mener à bien les calculs complexes nécessaires à l’imitation, même approximative, des subtilités de la pensée humaine.
Au milieu des années 2000, le rêve de construire des machines aussi intelligentes que des humains avait presque été abandonné par la communauté scientifique. À cette époque, même le terme d’« intelligence artificielle » semblait avoir déserté le domaine de la science sérieuse. Les chercheurs décrivent la période allant des années soixante-dix au milieu des années 2000 par l’expression « AI winters », une sorte de long hiver glaciaire de l’intelligence artificielle où tous les espoirs avaient été brisés.
Les choses ont commencé à basculer en 2005. Les perspectives dans le domaine de l’intelligence artificielle ont radicalement changé avec l’apprentissage automatique et l’émergence de l’« apprentissage profond », qui revisite le connexionnisme des années 1960 et s’inspire des neurosciences. Les réalisations actuelles de l’apprentissage profond sont à la hauteur des promesses d’antan, et les grandes entreprises des technologies de l’information consacrent désormais des milliards de dollars ou d’euros à son développement.
Par apprentissage profond, on entend un traitement effectué par un grand nombre de neurones artificiels (imitant de façon très simplifiée les neurones biologiques) qui, par leurs interactions, permettent au système d’apprendre progressivement à partir d’images, de textes ou d’autres données. L’apprentissage repose sur des principes mathématiques généraux. Le résultat de l’apprentissage est une représentation (par exemple, « Cette image contient des éléments différents »), une décision (par exemple « Cette image représente Jeanne Dupont ») ou une transformation (par exemple la traduction d’un texte dans une autre langue).
La technique de l’apprentissage profond a transformé la recherche en intelligence artificielle, ranimant des ambitions oubliées pour la vision par ordinateur, la reconnaissance automatique de la parole et la robotique. Les premières applications ont vu le jour en 2012 pour la compréhension de la parole (vous avez certainement entendu parler de Siri, qui équipe les iPhone). Et peu après sont arrivés des logiciels qui identifient le contenu d’une image, une fonctionnalité qu’intègre maintenant le moteur de recherche Google Photos.
Tous ceux qui sont frustrés par les menus malcommodes de leur téléphone peuvent apprécier les avantages d’utiliser Siri ou un autre « assistant personnel » sur leur appareil. Et pour ceux qui se rappellent combien la reconnaissance d’objets était mauvaise il y a quelques années seulement (les logiciels confondaient un aspirateur et un tatou, par exemple), les avancées dans le domaine de la vision artificielle ont été phénoménales : aujourd’hui, moyennant certaines conditions, les ordinateurs savent reconnaître sur des images un chat, une pierre ou des visages presque aussi bien que les humains. Les logiciels d’intelligence artificielle font désormais partie du quotidien de millions d’utilisateurs de téléphones. Personnellement, je n’écris plus de messages : je parle simplement à mon téléphone, et parfois il lui arrive même de me répondre.
Ces progrès ont ouvert la voie à de nouvelles réalisations de ces techniques, à des applications commercialisées, et l’intérêt ne cesse de croître. La concurrence fait rage entre les entreprises pour attirer les jeunes talents ; les titulaires d’un doctorat en apprentissage profond sont une denrée rare très convoitée. De nombreux professeurs d’université spécialistes du domaine (la majorité, d’après certaines estimations) sont passés du milieu académique à l’industrie, séduits par des équipements de pointe et par de généreux salaires.
Les efforts déployés pour répondre aux défis de l’apprentissage profond ont débouché sur des réussites époustouflantes. La très récente victoire au go d’un réseau neuronal sur le joueur professionnel Lee Sedol a fait la une de nombreux journaux. Les applications vont s’étendre à d’autres domaines de l’expertise humaine, et pas seulement aux jeux. Par exemple, un algorithme d’apprentissage profond nouvellement développé serait capable de diagnostiquer des insuffisances cardiaques sur des images d’IRM aussi bien qu’un cardiologue. Ce succès récent de l’apprentissage profond a de quoi surprendre quand on se penche sur l’histoire de l’intelligence artificielle. Pourquoi celle-ci a-t-elle buté sur tant d’obstacles dans les décennies précédentes ? Parce qu’apprendre des choses nouvelles est, pour une machine, difficile. L’essentiel de la connaissance que nous avons du monde autour de nous n’est pas formalisé dans un langage écrit sous forme d’un ensemble de tâches explicites, ce qui est indispensable pour écrire un programme informatique. C’est pourquoi nous n’avons pas pu directement programmer un ordinateur pour effectuer la plupart des tâches qui nous sont évidentes ou faciles, qu’il s’agisse de comprendre la parole, d’interpréter des images ou de conduire une automobile. Les tentatives en ce sens (organiser des ensembles de faits en bases de données élaborées afin de doter les ordinateurs d’un fac similé d’intelligence) ont rencontré peu de succès.

En mars 2016, le logiciel AlphaGo a affronté le joueur coréen, Lee Sedol, considéré comme l’un des meilleurs du monde (ci-dessus au milieu, avec Sergei Brin, cofondateur de Google, et Demis Hassabis, cofondateur de Google DeepMind qui a développé AlphaGo). Fondé sur l’apprentissage profond, AlphaGo a battu l’humain quatre manches à une. Photo © Google / DeepMind.
C’est là qu’entre en scène l’apprentissage automatique – le cadre général de l’apprentissage profond. Il se fonde sur des principes généraux, permettant aux systèmes d’utiliser les données disponibles pour apprendre à bien décider, à acquérir de bonnes connaissances et, in fine, à rechercher de nouvelles données pour apprendre mieux. Mais qu’est-ce qu’une « bonne » décision ? Pour les animaux, au regard des principes de l’évolution, les décisions qui sont prises devraient être celles qui optimisent les chances de survie et de reproduction. Dans les sociétés humaines, une bonne décision est plus subtile à définir et peut inclure des interactions sociales qui confèrent un statut élevé ou une sensation de bien-être. Pour une voiture autonome, qui se conduit toute seule, la qualité de la prise de décision sera d’autant meilleure que le véhicule reproduira avec fidélité les comportements de bons conducteurs humains.
Les connaissances nécessaires pour prendre une bonne décision dans un contexte particulier ne sont pas nécessairement évidentes et faciles à traduire en langage informatique. Une souris, par exemple, connaît bien son environnement et a un sens inné des endroits où elle doit flairer, sait instinctivement comment bouger ses pattes, trouver de la nourriture, éviter les prédateurs… Aucun informaticien ne serait capable de spécifier un programme étape par étape pour produire ces comportements. Et pourtant, ces connaissances sont « codées » dans le cerveau du rongeur.
Apprendre à partir de nombreux exemples
Avant de créer des ordinateurs capables d’apprendre, les scientifiques doivent répondre à des questions fondamentales, concernant en particulier le partage entre l’inné (ce qui fait partie du système dès le départ) et l’acquis (ce que le système apprend à partir de son expérience). Depuis les années cinquante, les chercheurs ont étudié et tenté d’affiner les principes généraux qui permettent aux animaux et aux humains (ainsi que, en l’occurrence, aux machines) d’acquérir des connaissances par expérience. L’apprentissage automatique vise à établir des procédures, nommées algorithmes d’apprentissage, qui confèrent à une machine la capacité d’apprendre à partir d’exemples qu’on lui présente.
La science de l’apprentissage automatique fait face à un résultat négatif formel surnommé No free lunch (« Rien n’est gratuit ») : si tous les problèmes sont équiprobables, il n’existe pas d’algorithme universel, c’est-à-dire meilleur que tous les autres sur l’ensemble des problèmes. Il faut donc élaborer des algorithmes différents pour s’attaquer à différentes catégories de problèmes (par exemple reconnaître un coucher de soleil ou traduire un texte en ourdou). L’apprentissage automatique repose ainsi sur deux piliers, théorique et expérimental : un problème réel ne satisfait pas toujours les hypothèses théoriques de l’algorithme, et la validation de l’algorithme sur des données réelles est toujours nécessaire.
Or, il semble que notre cerveau incorpore des algorithmes généraux qui nous permettent d’apprendre une multitude de tâches auxquelles l’évolution n’avait pas préparé nos ancêtres : jouer aux échecs, construire des ponts ou faire de la recherche en intelligence artificielle.
Ces compétences supplémentaires suggèrent que l’intelligence humaine pourrait encore être source d’inspiration pour créer des machines dotées d’une forme d’intelligence générale. C’est exactement pourquoi les développeurs de réseaux de neurones ont adopté le modèle du cerveau comme guide pour concevoir des systèmes intelligents.
Les principales unités de calcul du cerveau sont des cellules nommées neurones. Un neurone transmet un signal sous la forme d’une impulsion électrique qui se propage jusqu’à la synapse, la zone de contact avec un autre neurone. Des molécules nommées neurotransmetteurs sont libérées, puis réabsorbées par le neurone cible, ce qui permet à ce dernier de prendre le relais. La propension d’un neurone à transmettre un signal vers un autre neurone est nommée force synaptique. À mesure qu’un neurone « apprend », sa force synaptique augmente, et il a plus de chances d’envoyer des signaux à ses voisins quand il est stimulé par une impulsion électrique.
Les neurosciences ont influencé l’émergence des réseaux de neurones artificiels, où ces éléments sont connectés de façon matérielle ou logicielle. Les premiers programmeurs de cette sous-discipline de l’intelligence artificielle, connue sous le nom de connexionnisme, postulaient que les réseaux neuronaux seraient capables d’apprendre des tâches complexes en modifiant progressivement les connexions entre neurones, de telle façon que les schémas d’activité neuronale coderaient le contenu des données – livrées sous forme d’images, de sons ou autres. À chaque exemple soumis au réseau, le processus d’apprentissage se poursuivrait en modifiant les forces synaptiques entre les neurones connectés. Ces valeurs convergeraient petit à petit vers la configuration du réseau qui représente le mieux, par exemple, le contenu d’images d’un coucher de soleil.
Du cerveau aux réseaux virtuels
Les réseaux de neurones actuels sont des versions améliorées des travaux pionniers issus du connexionnisme. Cependant, les algorithmes d’apprentissage correspondants requièrent une participation active de l’Homme. La plupart d’entre eux utilisent une technique, nommée apprentissage supervisé, où chaque exemple d’apprentissage est accompagné d’une étiquette indiquant ce qui fait le sujet de l’apprentissage (une image de coucher de soleil, par exemple, est associée à l’étiquette « coucher de soleil »).
Dans ce cas, l’objectif de l’algorithme d’apprentissage supervisé est, à partir d’une donnée d’entrée constituée par une photographie, de produire comme sortie le nom de l’objet central de l’image. L’opération mathématique qui transforme une entrée en une sortie est une fonction. Les valeurs numériques qui définissent cette fonction, telles que les forces synaptiques, correspondent à une solution de la tâche d’apprentissage.
Il serait facile pour un système d’apprendre par cœur les réponses correctes sur les exemples connus (il suffit d’une mémoire de capacité suffisante). Mais cela n’a pas grand intérêt. Même si on accumule des millions d’images de coucher de soleil, le nombre d’images possibles d’une telle scène est infini. Ainsi, l’objectif de l’apprentissage est d’être capable de donner de bonnes réponses sur de nouveaux exemples, inconnus du système, en généralisant les exemples connus. Le bon niveau de généralisation dépend du contexte. Ainsi, on peut vouloir reconnaître la notion d’arbre en général, mais on peut aussi vouloir distinguer les chênes des hêtres, ou vouloir reconnaître le hêtre d’un jardin donné…
Une structure faite de couches multiples
Un tel algorithme doit aussi s’appuyer sur certaines hypothèses relatives aux données et à ce que pourrait être une solution possible à un problème donné. Par exemple, le logiciel doit intégrer comme principe que si des données d’entrée d’une fonction particulière sont semblables, leur sortie ne devrait pas être radicalement différente : modifier quelques pixels sur une image de chat ne devrait pas transformer l’animal en chien.
De telles hypothèses faites sur des images sont utilisées par les réseaux de neurones dits convolutifs. Ces programmes sont à l’origine du renouveau de l’intelligence artificielle. Les réseaux neuronaux convolutifs utilisés dans l’apprentissage profond comprennent de nombreuses couches de neurones organisées de telle manière que le logiciel sera robuste vis-à-vis des changements dans l’objet qu’il tente d’analyser. Il sera capable de reconnaître l’élément même s’il a un peu bougé par exemple. Ainsi, un réseau bien entraîné sera capable de reconnaître un visage que les photographies représentent sous des angles variés.
La configuration d’un réseau convolutif s’inspire de la structure en couches multiples du cortex visuel, c’est-à-dire la partie de notre cerveau qui reçoit les signaux des yeux. Ces nombreuses couches de neurones virtuels justifient le qualificatif de « profond » donné à ces réseaux et confèrent à ces derniers une meilleure capacité à appréhender le monde environnant.
L’apprentissage profond est devenu envisageable il y a une dizaine d’années grâce à certaines innovations, alors que l’intérêt pour l’intelligence artificielle était au plus bas. Un organisme canadien financé par le gouvernement et par des fonds privés, l’ICRA (Institut canadien de recherches avancées), a contribué à ranimer la flamme en soutenant un programme dirigé par Geoffrey Hinton, de l’université de Toronto, et dont faisaient partie Yann LeCun de l’université de New York et du centre de recherche de Facebook à Paris, Andrew Ng de l’université de Stanford, Bruno Olshausen de l’université de Californie à Berkeley, moi-même et plusieurs autres. En raison du scepticisme ambiant, il était difficile à cette époque de publier des articles sur le sujet et même de persuader des étudiants de faire leur thèse dans ce domaine. Mais nous étions convaincus qu’il fallait persévérer dans cette voie.
La réticence vis-à-vis de l’intelligence artificielle découlait initialement de l’idée que la création de réseaux neuronaux était sans espoir à cause de la difficulté à optimiser leur performance pour apprendre efficacement.
L’optimisation est une branche des mathématiques qui vise à trouver la meilleure combinaison de paramètres, ici les poids synaptiques des neurones virtuels, pour atteindre un certain objectif. Lorsque la relation qui lie les paramètres et l’objectif est assez simple — plus précisément lorsque l’objectif est une « fonction convexe » des paramètres — alors on peut améliorer progressivement les paramètres et l’on parle d’optimisation convexe. La procédure d’entraînement est répétée jusqu’à ce que les paramètres s’approchent aussi près que possible des valeurs qui produisent le meilleur résultat. On cherche en fait un minimum global, à savoir le jeu de paramètres qui permet d’atteindre la valeur la plus basse (et la meilleure) de l’écart à l’optimum.
Des obstacles surmontés peu à peu
En général, la situation n’est pas aussi simple, la fonction reliant les paramètres à l’objectif qu’ils atteignent n’étant pas convexe. Or l’optimisation non convexe représente un défi bien plus difficile. De nombreux chercheurs pensaient qu’il n’était pas possible de le relever. L’algorithme d’apprentissage pourrait en effet se retrouver coincé dans un minimum local, d’où il ne pourrait sortir s’il ajuste les paramètres par petites touches.
Or, mes collègues et moi avons montré que si le réseau de neurones est assez grand, le problème des minimums locaux est fortement réduit. Dans un tel réseau, la plupart des minimums locaux correspondent à un niveau d’apprentissage quasi équivalent à celui du minimum global.
Bien que les problèmes théoriques de l’optimisation soient, en principe, résolubles, la construction de grands réseaux comportant plus de deux ou trois couches avait souvent échoué. À partir de 2005, les recherches financées par l’ICRA ont commencé à porter leurs fruits et les obstacles ont été surmontés progressivement. En 2006, nous sommes parvenus à entraîner des réseaux neuronaux plus profonds en utilisant une technique qui opérait couche par couche.
Du bruit pour un meilleur apprentissage
Par la suite, en 2011, nous avons trouvé un moyen d’entraîner des réseaux encore plus profonds (avec davantage de couches de neurones virtuels) en modifiant les opérations effectuées par chacun des neurones, ce qui les rapprochait davantage des neurones biologiques dans leur façon de traiter l’information. Nous avons aussi découvert qu’en injectant du bruit aléatoire dans les signaux transmis entre les neurones au cours de l’apprentissage — comme ce qui a cours dans le cerveau —, les réseaux apprenaient mieux à identifier correctement une image ou un son.
Par ailleurs, deux facteurs essentiels ont contribué au succès des techniques d’apprentissage profond. Le premier est l’augmentation d’un facteur 10 de la puissance de calcul des ordinateurs grâce aux processeurs dédiés au traitement d’image (conçus initialement pour les jeux vidéo !), ce qui a permis d’entraîner des réseaux plus grands en un temps raisonnable. Le second facteur est que l’on avait désormais accès à d’énormes bases de données étiquetées, avec lesquelles les algorithmes d’apprentissage ont pu s’exercer à reconnaître un « chat », par exemple, dans des images qui comportaient un chat parmi d’autres éléments.
Une autre raison aux récents succès de l’apprentissage profond est que le réseau est capable d’apprendre à effectuer un ensemble de calculs qui construisent ou analysent pas à pas une image, un son ou un autre type de donnée. Avec une profondeur suffisante, ces dispositifs excellent dans beaucoup de tâches de reconnaissance visuelle ou auditive. Des travaux théoriques et expérimentaux récents ont d’ailleurs montré qu’il est impossible d’effectuer efficacement certaines de ces opérations mathématiques sans un réseau assez profond.
Mais que se passe-t-il au cœur du réseau de neurones profond ? Chaque couche transforme son entrée et produit une sortie qui est envoyée à la couche suivante. Les premières couches se concentrent sur les détails aux échelles les plus petites, puis les couches suivantes agrandissent les échelles considérées. Plus les couches sont profondes, plus elles vont représenter des concepts abstraits. Par exemple, les premières couches pourraient isoler des éléments caractéristiques d’une chaise et l’image de la chaise pourrait émerger du traitement de neurones d’une couche plus profonde, même si le concept de « chaise » ne faisait pas partie des étiquettes de catégorie sur lesquelles le réseau s’est entraîné. Et le concept de chaise pourrait lui-même n’être qu’une étape intermédiaire vers la création d’un concept encore plus abstrait au niveau d’une couche plus profonde, que le réseau pourrait catégoriser comme une « scène de bureau ».
Les connexions entre neurones dans le cortex cérébral ont inspiré la création d’algorithmes d’apprentissage qui imitent ces liens complexes. On peut apprendre à un tel réseau de neurones artificiels à reconnaître un visage en l’entraînant avec un très grand nombre d’images. Le réseau détermine les traits qui lui permettent de distinguer un visage d’une main, par exemple, et reconnaît la présence de visages dans une image. Il utilise ensuite cette connaissance pour identifier des visages qu’il a déjà vus, même si l’image de la personne est un peu différente de celle sur laquelle il s’est entraîné.
Pour reconnaître un visage dans une image, le réseau commence par analyser les pixels d’une image qui lui est présentée au niveau de la couche d’entrée. Puis il discerne les formes géométriques caractéristiques du visage au niveau de la couche suivante. En remontant la hiérarchie, des yeux, une bouche et d’autres traits du visage apparaissent. Enfin, une forme composite émerge et le réseau tente de « deviner » au niveau de la couche de sortie s’il s’agit du visage de Joe, Chris ou Lee.
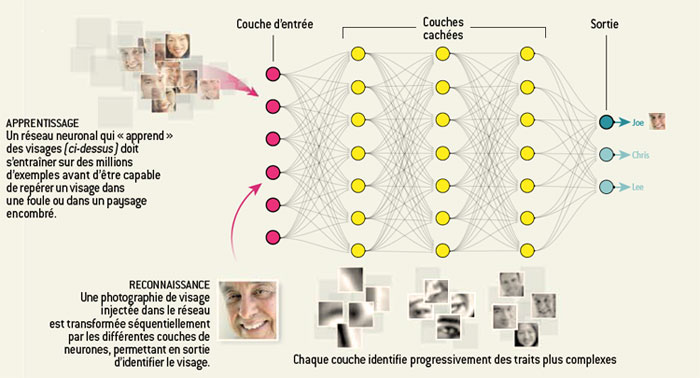
© Graphisme Jen Christiansen – Punchstock (visages)
Jusqu’à récemment, les réseaux de neurones artificiels se distinguaient en grande partie par leur capacité à effectuer des tâches telles que la reconnaissance de motifs dans des images statiques. Mais d’autres types de réseaux neuronaux affichent des résultats intéressants sur des événements dynamiques. Les « réseaux neuronaux récurrents », par exemple, ont démontré leur capacité à effectuer une séquence de calculs pour traiter la parole ou de la vidéo. Les données séquentielles sont constituées d’unités (phonèmes ou mots dans le cas de la parole) qui se suivent. La façon dont les réseaux neuronaux récurrents traitent leurs entrées présente une certaine ressemblance avec la façon de fonctionner du cerveau. Les signaux qui se propagent parmi les neurones changent constamment à mesure que les entrées sensorielles sont traitées.
Un traitement dynamique
Les réseaux récurrents parviennent à prédire quel sera le mot suivant dans une phrase et peuvent ainsi produire une nouvelle séquence de mots, l’un après l’autre. Ils peuvent aussi s’atteler à des tâches plus complexes. Après avoir « lu » tous les mots d’une phrase, le réseau est à même de deviner le sens de la phrase entière. Un réseau récurrent distinct peut alors utiliser le traitement sémantique du premier réseau pour traduire la phrase dans une autre langue.
La recherche sur les réseaux neuronaux récurrents a connu sa propre période de stagnation à la fin des années quatre-vingt-dix et au début des années 2000. Mes propres travaux théoriques suggéraient qu’ils rencontreraient des difficultés à apprendre à récupérer de l’information du passé lointain, à savoir les premiers éléments de la séquence en cours de traitement (un peu comme si vous essayiez de réciter les premières phrases d’un livre alors que vous venez d’atteindre la dernière page). Mais certains de ces problèmes ont été résolus grâce à des techniques
consistant à stocker l’information de façon qu’elle persiste durablement. Ces réseaux neuronaux utilisent la mémoire temporaire (mémoire cache) d’un ordinateur pour traiter des informations multiples et dispersées, comme des idées contenues dans différentes phrases réparties au fil d’un document.
Le retour en force des réseaux neuronaux à apprentissage profond après le long sommeil de l’intelligence artificielle n’est pas uniquement un triomphe technique. C’est aussi une leçon de sociologie des sciences. En particulier, il souligne la nécessité de soutenir des idées qui font fi du statu quo technologique et d’encourager la tenue d’un portefeuille de recherches diversifié, laissant de la place à des champs provisoirement passés de mode.

À gauche, photo Ilona via Pixabay, CC0. À droite © Deepdreamgenerator.com.
L’apprentissage profond est performant pour la reconnaissance d’objets dans une image, mais il est en réalité assez difficile de comprendre ce qui se passe au cours de l’analyse à chaque niveau du réseau de neurones. La société Google a développé le logiciel DeepDream qui utilise l’apprentissage profond. Les chercheurs peuvent analyser le résultat à différentes étapes du processus en demandant au logiciel de faire ressortir ce qu’il « voit » dans l’image. Ainsi, telles des paréidolies – l’illusion de voir, par exemple, un chien dans un nuage qui en a vaguement la forme –, le logiciel, qui s’est, par exemple, entraîné à reconnaître des images d’animaux, verra des oiseaux et des rongeurs dans une photographie d’un champ de maïs. Chacun peut créer ses propres images psychédéliques sur le site Deepdreamgenerator.com.
Bibliographie
- Y. LeCun et al., Deep learning, Nature, vol. 521, pp. 436-444, 2015.
- Y. Bengio et al., Representation learning : A review and new perspectives, IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35(8), pp. 1798-1828, 2013.
- A. Krizhevsky et al., ImageNet classification with deep convolutional neural networks, 26th Annual Conference on Neural Information Processing Systems (NIPS 2012), 2012.
Sur le Web
- Cours de Yann LeCun au Collège de France, 2015-2016.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
