
Le bon joueur, le mauvais joueur : au-delà des inconnues ?
“ Une batte et une balle de baseball valent au total \(1\) dollar et \(10\) cents.
La batte coûte un dollar de plus que la balle. Combien vaut la balle ? ”
Cette question classique a été posée à titre d’expérience à plusieurs centaines de personnes, pour discuter de ceux qui répondent \(5\) ou \(10\) cents [voir les références bibliographiques KF05, Kah16]. Ceux qui se trompent s’appuient souvent sur leur intuition, le système \(1\) selon le psychologue et économiste Daniel Kahneman, pour obtenir sans effort une réponse. Cela leur évite un pénible calcul rationnel, activant le système \(2\), par exemple en cherchant la solution du système linéaire nommé (Bat and Ball) :
| \(\mathsf{batte}+\mathsf{balle}\) | \(=\) | \(1.10\) |
| \(\mathsf{batte}-\mathsf{balle}\) | \(=\) | \(1\). |
Le système \(1\) n’est pourtant pas à jeter. En effet il nous permet, sous la forme de nos préjugés, de simplifier certains choix de notre existence. Par exemple, un enfant de quelques mois n’a en général pas besoin d’un doctorat en biomécanique et d’un ordinateur puissant pour savoir marcher. De plus, pour notre problème, dans tous les cas, le prix proposé pour la balle n’est pas si éloigné de la bonne valeur. Il peut donc y avoir un léger biais dans cette estimation intuitive. Nous pouvons évaluer ce biais car le prix est parfaitement défini par les équations. Plus généralement, étudier les biais auxquels nous sommes sensibles permet de mieux les connaître et parfois de les corriger.
Nous présentons ici une généralisation du type d’expérience discuté par Kahneman. Elle prend la forme d’un jeu comportant une répétition de décisions intuitives pour la joueuse, dont nous souhaitons étudier les éventuels biais. Ces biais sont évalués par rapport à des solutions optimales qui sont obtenues par des calculs sur un ordinateur. Dans ce jeu, une cycliste parcourt un itinéraire vallonné. Sur chaque tronçon d’un kilomètre, elle doit faire le choix binaire d’adopter un rythme soit rapide soit lent. Ce choix est l’analogue de l’estimation du prix de la balle. Le système linéaire (Bat and ball) devient un système d’équations de Bellman-Ford probabiliste, qui se résout bien informatiquement. Nous collectons les données correspondant aux choix des joueuses, et nous les intégrons à des modèles décrivant les biais suspectés.
Cet article s’organise en cinq sections, dont une en classe inversée. Dans la première section, nous présentons les règles de ce jeu de gestion de l’effort sportif. La seconde section est celle qui est participative : la lectrice fait plusieurs parties sur notre site web pour se construire une intuition des estimations à pratiquer dans le jeu. La troisième section donne une définition plus précise de la façon de calculer les scores, tentant de séparer au mieux les influences des choix de la joueuse et du hasard. Dans la quatrième section nous expliquons comment l’ordinateur peut calculer une solution optimale pour toutes les décisions de la joueuse. Et enfin dans la cinquième section, nous discutons des formes d’erreurs que nous observons jusque-là dans les parties jouées sur le site. Nous proposons des manières de les interpréter sous forme de biais, voire de les exploiter.
1. Un jeu solitaire d’optimisation avec de l’aléatoire
Règles du jeu
La joueuse incarne une cycliste se déplaçant le long d’un parcours découpé en tronçons d’un kilomètre. Elle connaît dès le départ le relief de chaque kilomètre, relief qui est soit plat, soit en montée, soit en descente (la borne kilométrique indique le début du kilomètre). Un exemple de parcours de longueur \(12\) est proposé sur la figure 1(a).

Figure 1 – Un exemple de partie du jeu de cyclisme.
Sur chaque kilomètre, la cycliste a le choix de faire des efforts supplémentaires qui lui permettent de gagner du temps par rapport à un rythme de base. Les réserves d’énergie de la cycliste sont constituées de boules rouges pour le choix d’efforts supplémentaires et vertes pour des efforts minimaux. Elle possède autant de boules que de kilomètres sur le parcours. Ces boules sont initialement placées dans une urne transparente. Par exemple, \(\mathsf{Urne} = \) [ 🟢 ,🟢 ,🟢 ,🟢 ,🟢 , 🔴,🔴,🔴,🔴,🔴,🔴,🔴 ], que l’on note [🟢 5 🔴7 ].
La joueuse n’a pas directement accès à ses réserves. Elle dispose uniquement d’un nombre \(M\) de ces boules en main (en général \(M = 5\)). Par exemple : \(\mathsf{Main} = \) {🟢 ,🟢 ,🟢 ,🔴,🔴}. Au début de la partie, sa main est vide. Au début du tour, elle la complète à \(M\) (autant que possible) en piochant dans l’urne. Chaque pioche correspond à ce que nous nommons un tirage. Bien que la cycliste connaisse la composition de l’urne, elle y pioche à l’aveugle ce qui donne autant de chance à chacune des boules d’être piochée.
Sur chaque kilomètre, la cycliste décide de son allure, en prenant de sa main une boule pour la placer sur le kilomètre parcouru. C’est ce que nous nommons une décision. Une allure rapide est représentée par le placement d’une boule rouge. A contrario, placer une boule verte représente une allure lente. Si toutes les boules de sa main sont de la même couleur, la cycliste n’a qu’une allure possible. La figure 1(b) présente les \(5\) premiers tours d’une partie. Sur chaque ligne, on indique la composition de l’urne au début du tour, les boules piochées, la composition de la main après la pioche, et la boule jouée sur le kilomètre.
Le score de la partie est compté de la manière suivante : une allure rapide rapporte deux minutes sur un kilomètre en montée, une seule minute sur un kilomètre plat. Dans tous les autres cas, aucune minute n’est gagnée. Nous rassemblons tous ces cas dans le tableau suivant :
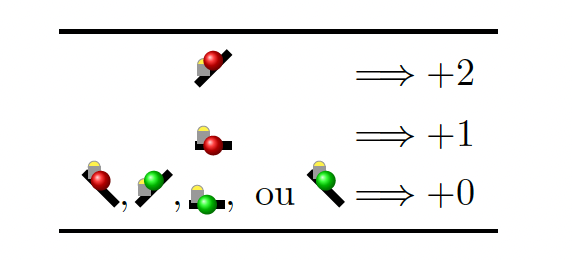
La figure 1(c) représente les scores intermédiaires d’une partie terminée, dont le score total est de \(6\).
Dans une partie standard, le parcours fait \(60\) kilomètres de long, les pentes des tronçons sont choisies aléatoirement uniformément, sauf le premier tronçon qui est forcément plat. Les urnes contiennent entre \(1/3\) et \(2/3\) de boules rouges (et donc les proportions sont les mêmes pour les boules vertes). La taille de la main est fixée à \(5\) boules.
2. Jouez !
Pour comprendre la suite de l’article, il nous semble nécessaire de jouer quelques parties sur notre site. Néanmoins, si vous vous sentez encore un peu perdu, un point de départ raisonnable peut être notre tutoriel.
Dans les deux cas, pour vous connecter, choisissez un login, par exemple anne, et un mot de passe, par exemple onyme. Si vous avez choisi la paire anne/onyme vous serez … anonyme, sinon votre login vous identifiera (et rien d’autre). Le choix du mot de passe initial pour le login est définitif.
Détails sur l’interface du jeu
Le jeu se présente comme dans la figure 2 ci-dessous.
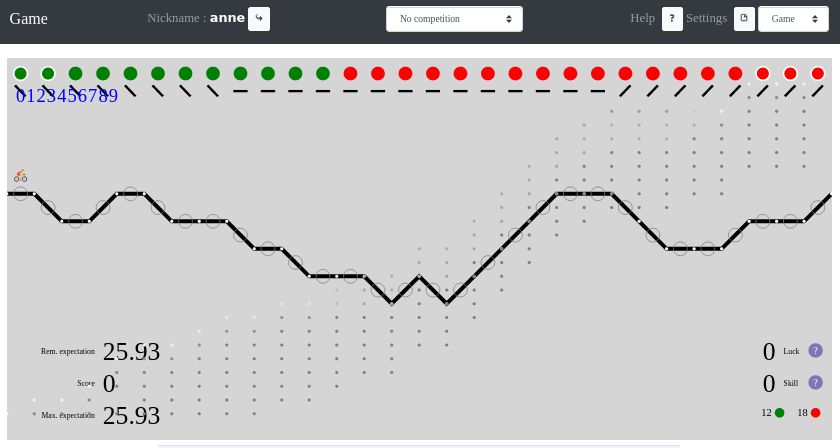
Figure 2 – L’interface de jeu.
Par défaut, une partie générée aléatoirement vous est proposée. Les boules qui ne sont pas encore posées sont alignées en haut de la fenêtre. Les boules cerclées de blanc aux extrémités de cet alignement sont celles dans la main de la joueuse. Les autres sont dans l’urne. Sous ces boules, il y a une aide de jeu sous la forme d’une copie triée des reliefs de tronçons restant à parcourir (à vous de l’interpréter !).
Pour jouer une boule rouge sur le prochain tronçon, appuyez sur la flèche droite. Pour jouer une boule verte, appuyez sur la flèche gauche. Les pioches dans l’urne sont automatiques. Votre score est indiqué en bas à gauche, et vaut initialement \(0\). À côté, il y a une estimation du score atteignable (discutée par la suite). Une fois la partie terminée, vous avez la possibilité de nous la transmettre en appuyant sur la touche ’\(\texttt{t}\)’. Cette partie est alors enregistrée avec les autres parties de la joueuse sur sa page personnelle, ainsi que dans la base de données publique.
Si vous êtes d’un naturel compétitif, il y a une vingtaine de parcours communs à tous les joueurs/joueuses sur notre épreuve par étapes. Cliquez sur le nom des étapes pour les jouer et comparez vos performances en consultant les résultats des autres joueurs/joueuses. Pour avoir les scores absolus, n’oubliez pas de mettre à \(0\) en bas de page la dégradation des performances au cours du temps.
Votre objectif est évidemment de réaliser le meilleur score possible, mais nous vous proposons quelque chose de plus fin. Votre score est pour partie le résultat de vos décisions, qui sont sous votre contrôle. Mais une autre part de ce score dépend de la qualité des tirages des boules dans l’urne. Imaginez si vous tiriez les boules vertes au départ ! Nous proposons deux indicateurs situés en bas à droite pour estimer la place prise par ces deux parts dans votre score final : la compétence (ou skill) représentant vos décisions, et la chance (ou luck) représentant vos tirages. La compétence (skill) est une valeur initialement nulle, qui décroît à chaque mauvaise décision, et reste constante sur les bonnes. Jouer de manière optimale, c’est maintenir sa compétence (skill) à \(0\) tout au long de la partie. La chance (luck), elle, fluctue à la hausse comme à la baisse, au gré des tirages, selon leur adéquation avec la position du jeu. Ces deux estimateurs sont mis à jour après chaque décision.
Tâchez de garder la compétence (skill) la plus proche de zéro possible !
3. Chance et compétence
Merci pour vos parties. La suite de notre exposé prend un tour plus technique (parties \(3\) et \(4\)). Si vous vous sentez perdus ou impatients, vous pouvez sauter ces paragraphes en allant à l’encart \(4\), puis reprendre la lecture à la partie \(5\) qui montre comment nous avons analysé les parties. Pour analyser notre jeu, nous proposons de le décomposer, à la manière de Marvin Minsky en 1961 [voir la référence Min61], en une série d’événements simples :
« Suppose that one million decisions are involved in a complex task (such as winning a chess game). Could we assign to each decision element one-million-th of the credit for the completed task? (Considérons une tâche complexe (comme par exemple gagner une partie d’échecs), qui requiert un million de décisions. Est-il possible d’attribuer à chaque décision un millionième du mérite pour la réalisation de la tâche complète ?) »
Une partie est alors un mélange de tirages et de décisions, et nous cherchons à attribuer la contribution de chacun de ces événements au score final. Le total des contributions des tirages correspond à ce que nous appelons la chance (luck), tandis que les décisions correspondent à la compétence (skill).
Du fait des tirages dans l’urne, notre jeu est fondamentalement probabiliste. Ainsi, sur un parcours donné, une joueuse pourra rencontrer des mains différentes, autorisant ou empêchant des coups particuliers. Par exemple, si elle commence par piocher \(5\) boules vertes, elle n’aura pas le choix sur son premier kilomètre. Il est donc nécessaire d’intégrer les tirages dans l’évaluation du score de la joueuse. Pour cela, nous allons considérer une partie comme une suite de positions de jeu \(\mathbf{P} = (P_0, \dots, P_{2n})\) représentant les états intermédiaires entre les actions élémentaires (tirage ou décision). Pour évaluer le score lorsque la partie \(\mathbf{P}\) a atteint la position \(P_k\), nous proposons la formule suivante nommée (Score) : \[\mathsf{Score}(\mathbf{P}, k) := \mathsf{ScoreDebut}(\mathbf{P}, k) + \mathsf{ScoreFin}(\mathbf{P}, k)\]
Dans cette formule, \(\mathsf{ScoreDebut}(\mathbf{P}, k)\) est un terme déterministe calculant le score des boules placées avant d’atteindre la position \(P_k\). Et \(\mathsf{ScoreFin}(\mathbf{P}, k)\) est un terme probabiliste représentant l’espérance de score maximal atteignable à partir de \(P_k\), sommant sur tous les tirages possibles après \(P_k\). Dans la partie 4, nous expliquons comment cette formule est calculée efficacement.
Reprenons le parcours présenté sur la figure 1. En fonction des tirages et des décisions possibles, il existe un nombre important de parties jouables sur ce parcours. Sur la figure 3, nous représentons certaines de ces parties par des courbes de différentes couleurs, représentant l’évolution de \(\mathsf{Score}(\mathbf{P}, k)\) en fonction de \(k\). Une colonne blanche correspond à un tirage, une colonne grise correspond à une décision.
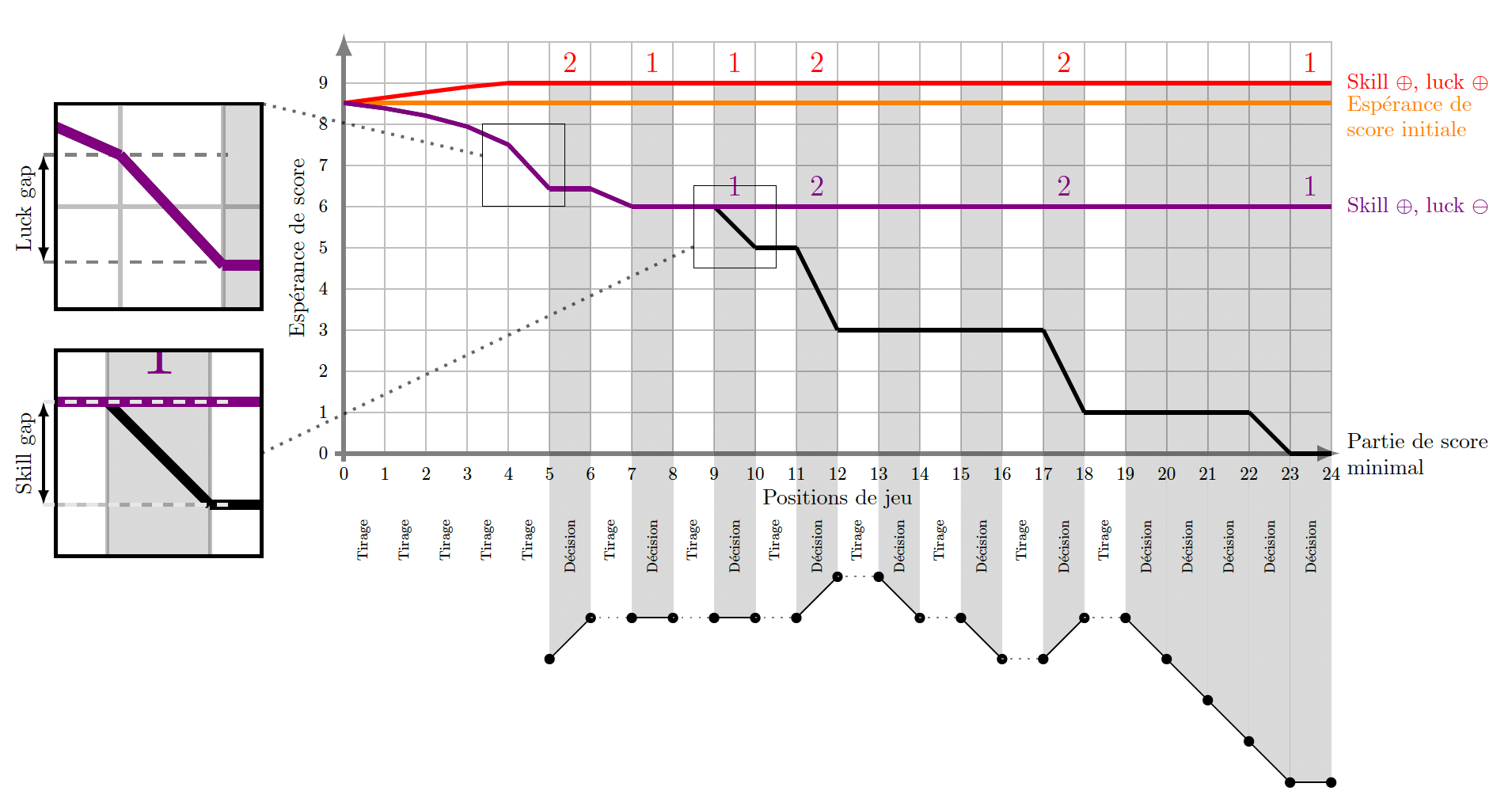
Figure 3 – Évolutions de l’espérance de score sur différentes parties jouées sur le parcours de la figure 1.
La partie rouge débute par \(5\) pioches de boules rouges et applique les bonnes décisions pour obtenir le score maximal de \(9\). Dans la partie violette, les \(6\) premières boules piochées sont vertes et la joueuse applique les bonnes décisions pour obtenir le score maximal alors atteignable de \(6\). Ceci montre que le score maximal atteignable peut dépendre fortement des tirages obtenus. La courbe orange ne correspond pas à une partie, mais indique \(\mathsf{Score}(\mathbf{P}, 0)\), l’espérance de score maximale atteignable sur ce parcours. La partie noire (parfois masquée par la partie violette) représente une partie avec des tirages défavorables et des décisions calamiteuses.
Le score final reflète à la fois la qualité des décisions de la joueuse et sa chance lors des tirages. Comme ces derniers ne sont pas sous sa responsabilité, nous allons voir comment séparer la chance de la compétence et calculer les deux contributions séparément. En cela, nous souhaitons mieux formaliser ce que signifie “bien jouer” à ce jeu.
Plutôt que de voir la partie comme une suite de tours, nous la regardons comme une suite d’actions élémentaires. L’action de piocher une boule dans l’urne correspond à un tirage. A contrario, l’action de jouer une boule sur un kilomètre correspond à une décision. Chacune de ces actions fait passer la partie de la position \(P_k\) à la position \(P_{k+1}\) et modifie le score de \(\mathsf{Score}(\mathbf{P}, k)\) à \(\mathsf{Score}(\mathbf{P}, k+1)\). Nous appelons écart (gap en anglais) au temps \(k\) la différence
\[\mathsf{Gap}(\mathbf{P}, k) := \mathsf{Score}(\mathbf{P}, k+1) – \mathsf{Score}(\mathbf{P}, k).\]
Partitionnons l’ensemble des actions de la partie en deux ensembles : \( \mathbf{D} := \{k, \) l’action entre \(P_k\) et \(P_{k+1}\) est une décision \(\}\) et \(\mathbf{T} := \{k, \) l’action entre \(P_k\) et \(P_{k+1}\) est un tirage\(\}\). La compétence (skill en anglais) est définie par la somme \[\mathsf{Skill}(\mathbf{P}) := \sum_{k\in\mathbf{D}} \mathsf{Gap}(\mathbf{P}, k)\] des gaps lors des décisions de la joueuse tandis que la chance (luck en anglais) est la somme \[\mathsf{Luck}(\mathbf{P}) := \sum_{k\in\mathbf{T}} \mathsf{Gap}(\mathbf{P}, k)\]
des gaps lors des tirages. Le score final, tel que défini dans les règles, se reformule en l’équation (SkillLuck): \[ \mathsf{Score}(\mathbf{P}) = \underbrace{\mathsf{Score}(\mathbf{P}, 0)}_{\textrm{Espérance initiale}} + \underbrace{\mathsf{Skill}(\mathbf{P})}_{\textrm{Compétence}} + \underbrace{\mathsf{Luck}(\mathbf{P})}_{\textrm{Chance}}.\] Dans cette formule, l’espérance initiale est une donnée constante, indépendante de la partie, et la chance (luck) n’est pas sous la responsabilité de la joueuse. Il est donc naturel de fixer comme objectif de jeu de maximiser la compétence (skill). On verra dans la partie 4 que cet objectif est identique à maximiser l’espérance du score. La compétence (skill) diminue au cours de la partie, quantifiant dans quelle mesure la joueuse s’éloigne de la solution optimale. Sur la figure 3 ci-dessous, cela se vérifie dans les colonnes grisées en constatant que le score ne peut y croître strictement.
Si jamais la compétence (skill) augmentait, la joueuse aurait trouvé une solution meilleure que l’optimale. A contrario, la chance (luck), elle, varie librement comme on peut le voir sur les 5 premières colonnes blanches selon que la joueuse est chanceuse (en rouge) ou malchanceuse (en violet). Une partie débute avec une compétence (skill) à \(0\). Si c’est encore le cas en fin de partie, cela signifie que la joueuse n’a fait aucune erreur. Nous appelons cela un perfect.
4. Calculer les espérances optimales
L’ambition de cette partie est de montrer comment calculer efficacement ces fameuses espérances \(\mathsf{ScoreFin}(P, k)\). Pour cela, nous introduisons progressivement les idées d’une technique classique d’optimisation : la programmation dynamique, au programme de la spécialité NSI pour la Terminale. Cette technique est due à Richard Bellman dans les années 1950, et mène à un type d’équation suffisamment générique pour être très fréquent en optimisation, ici sous la forme discrète. Mentionnons que l’optimisation est le thème mis en avant par le CNRS Sciences Informatiques en 2024.
Les (espérances de) scores : une trop grande somme à estimer
Ce jeu de cyclisme pourrait se jouer sans ordinateur, sur une table, avec des cartes représentant les kilomètres et les boules. Si le score d’une partie se calcule facilement, les mesures de compétence (skill) et de chance (luck) sont plus complexes à réaliser et à ce jour un ordinateur est indispensable pour les calculer. Les deux dépendent des écarts (gaps), eux-mêmes dépendant de \(\mathsf{ScoreFin}\) apparaissant dans l’équation (Score). C’est cette quantité que l’on cherche à déterminer.
Rappelons qu’une partie sur un parcours de \(n\) kilomètres \(\mathbf{P} = (P_0,\ldots, P_k,\ldots, P_{2n}) \) est décrite par les positions successives du jeu. Pour tout \(k\), \(\mathsf{ScoreFin}(\mathbf{P},k)\) est informellement défini comme l’espérance du score optimal atteignable entre \(P_k\) et la fin de la partie \(P_{2n}\). Cette espérance est obtenue comme une somme mettant en jeu tous les tirages possibles sur la fin de la partie \((P_k,\ldots,P_{2n})\) et des décisions optimales de la joueuse (cf. encart 1 ci-dessous pour plus de détails). C’est l’estimation de cette somme qui est le cœur du jeu : pour distinguer une « bonne » décision d’une « mauvaise » décision, la joueuse n’a qu’à comparer les espérances de score des deux positions atteignables. Nous allons présenter une méthode par laquelle un ordinateur peut efficacement calculer à la fois \(\mathsf{ScoreFin}(\mathbf{P},k)\) et un ensemble de décisions optimales pour toute position \(P_k\) du jeu.
Une stratégie \(\sigma\) est une fonction associant à un début de partie (\(P_0,\ldots, P_k)\) un choix \(\{🔴, 🟢 \: \}\). Partant d’une position \(P_k\), et connaissant la stratégie \(\sigma\) et les tirages \(\tau\) réalisés, on dispose alors d’une méthode pour jouer automatiquement une partie \(\mathbf{P}(k, \sigma,\tau) = (P_k, \ldots, P_{2n})\). En effet, partant de \(P_k\), les décisions sont déterminées par \(\sigma\) et les tirages par \(\tau\). L’espérance \(\mathsf{ScoreFin}(\mathbf{P},k,\sigma)\) est obtenue en sommant sur tous les tirages \(\tau\) possibles à partir de \(P_k\), et en appliquant les choix de la stratégie \(\sigma\) : \[ \mathsf{ScoreFin}(P,k,\sigma) = \sum_{\tau\in \textrm{Tirages} (P_k, \ldots, P_{2n})} \mathsf{Proba}(\tau) \mathsf{Score}(\mathbf{P}(k, \sigma,\tau)) \]
La fonction \(\mathsf{ScoreFin}\) est la fonction réalisant le score maximal atteint par une stratégie \(\sigma\) : \[\mathsf{ScoreFin}(P,k) = \max_{\sigma} \left( \mathsf{ScoreFin}(P,k,\sigma) \right) \]
Le calcul de \(\mathsf{ScoreFin}\) se heurte à deux difficultés : premièrement, le nombre de tirages possibles, exponentiel suivant la longueur de la partie \(n\), et ensuite le nombre de stratégies différentes possibles, qui est aussi exponentiel suivant le nombre de positions atteignables, un nombre qui est minoré par \(n\). La suite de cette partie montre que ces deux difficultés peuvent être traitées efficacement par un calcul de programmation dynamique.
Trop de parties mais heureusement peu de positions
Pour une partie de \(n\) kilomètres, on peut montrer que le nombre de fin de parties \((P_k,\ldots, P_{2n})\) est exponentiel en \(n\). En pratique ces ensembles sont inaccessibles pour un ordinateur dès \(n = 30\) kilomètres et nous voulons traiter \(n = 60\) kilomètres. La clé de l’efficacité est que le score final ne dépend pas de toutes les positions \((P_k,\ldots, P_{2n})\), mais seulement de \(P_k\) qui est une unique position de la partie. On peut voir les parties comme les mots d’une langue tandis que les positions seraient les lettres de l’alphabet composant ces mots, lui de taille bien plus petite. Le jeu a été conçu pour que ce nombre de positions soit à la fois important pour un humain et relativement faible pour un ordinateur, à savoir polynomial en \(n\). Nous affirmons qu’une position \(P_k\) est caractérisée par un triplet d’entiers : \[ P_k := (k,r_{\text{U}},r_{\text{M}}) \] où \(k\) est l’index de la position, \(r_{\text{U}}\) le nombre de boules rouges dans l’urne et \(r_{\text{M}}\) le nombres de boules rouges dans la main (cf. encart 2 ci-dessous pour plus de détails). Cette caractérisation permet de lister les positions accessibles sachant qu’elles sont en nombre borné par \(\mathcal{O}(n^2M)\) (en pratique environ \(4870\) positions pour les parties standards, à comparer aux \(979384303958308383376382900430926\) \( \approx 9.8 \ 10^{32}\) parties possibles avec autant de boules rouges que vertes).
Étudions les positions sur des parcours de \(n\) kilomètres, avec une main de taille \(M\). Une position \(P_k\) est l’état du jeu après \(k\) actions élémentaires à savoir la position de la cycliste sur le parcours ainsi que les compositions de l’urne et de la main. Supposons connaître le triplet (\(k, r_{\text{U}},r_{\text{M}})\) et reconstruisons la position \(P_k\). Ainsi :
- la cycliste a pris \(d\) décisions et fait \(t\) tirages dans l’urne où \[ \begin{cases} d=0 \mbox{ si } k\leq M \\ d=(k-M+1)/2 \mbox{ si } k=M+1\ldots 2n-M\\ d=k-n \mbox{ si } k=2n-M,\ldots,2n, \end{cases} \] et \(t = k-d\) puisque \(k=d+t\). .
- le nombre de boules dans l’urne est \(U(k) = n − t\),
- donc le nombre de boules vertes dans l’urne est \( U(k)- r_{\text{U}}\),
- le nombre de boules en main est \(M(k) = \min(t, M, n − d)\),
- donc le nombre de boules vertes en main est \(M(k)-r_{\text{M}}\).
Comme \(t\in [0;n]\), \(r_{\text{U}} \in [0;n] \) et \(r_{\text{M}} \in [0;M] \), il existe au plus \((n+1)^2 (M+1) = \mathcal{O}(n^2M)\) positions de jeu différentes. Pour les parties standards, cela donne en théorie au plus \(61^2 \times 6 = 22326\) positions différentes. En pratique, du fait des cas limites, ce nombre ne dépasse pas \(4870\) ce qui est très raisonnable pour être traité par un ordinateur.
Un calcul par récurrence pour l’étalage de confitures sur des tranches de pain de mie
Nous allons calculer par récurrence toutes les espérances \(\mathsf{ScoreFin}(\mathbf{P}, k) = \mathsf{ScoreFin}(k,r_{\text{U}}, r_{\text{M}} )\). Plaçons ces valeurs dans un tableau tridimensionnel. À l’heure du goûter, ce tableau nous apparaît comme un pain de mie découpé en tranches : la coordonnée \(k\) indique la \(k\)-ième tranche et les deux coordonnées restantes (\(r_{\text{U}}, r_{\text{M}})\) indiquent un petit carré à tartiner sur la face de Murphy de cette tranche. La tranche juste avant un tirage est une tranche de pain noir, tandis que celle juste avant une décision est une tranche de pain blanc. Nous allons beurrer de nombres, puis tartiner de confitures, les tranches de ce tableau par une récurrence qui les traitera de la dernière à la première.
La dernière tranche, traitant des fins de partie, est beurrée de zéros, ce qui se dit aussi \(\mathsf{ScoreFin}(2n,r_{\text{U}}, r_{\text{M}}) = 0 \) pour tout carré \((r_{\text{U}},r_{\text{M}})\) de la tranche \(2n\). Ensuite nous allons beurrer la tranche \(k\) en fonction des nombres beurrant la tranche \(k + 1\). Il y a deux cas à discuter selon l’action élémentaire qui apparaît entre les deux tranches décrivant des positions \(P_k\) et \(P_{k+1}\) :
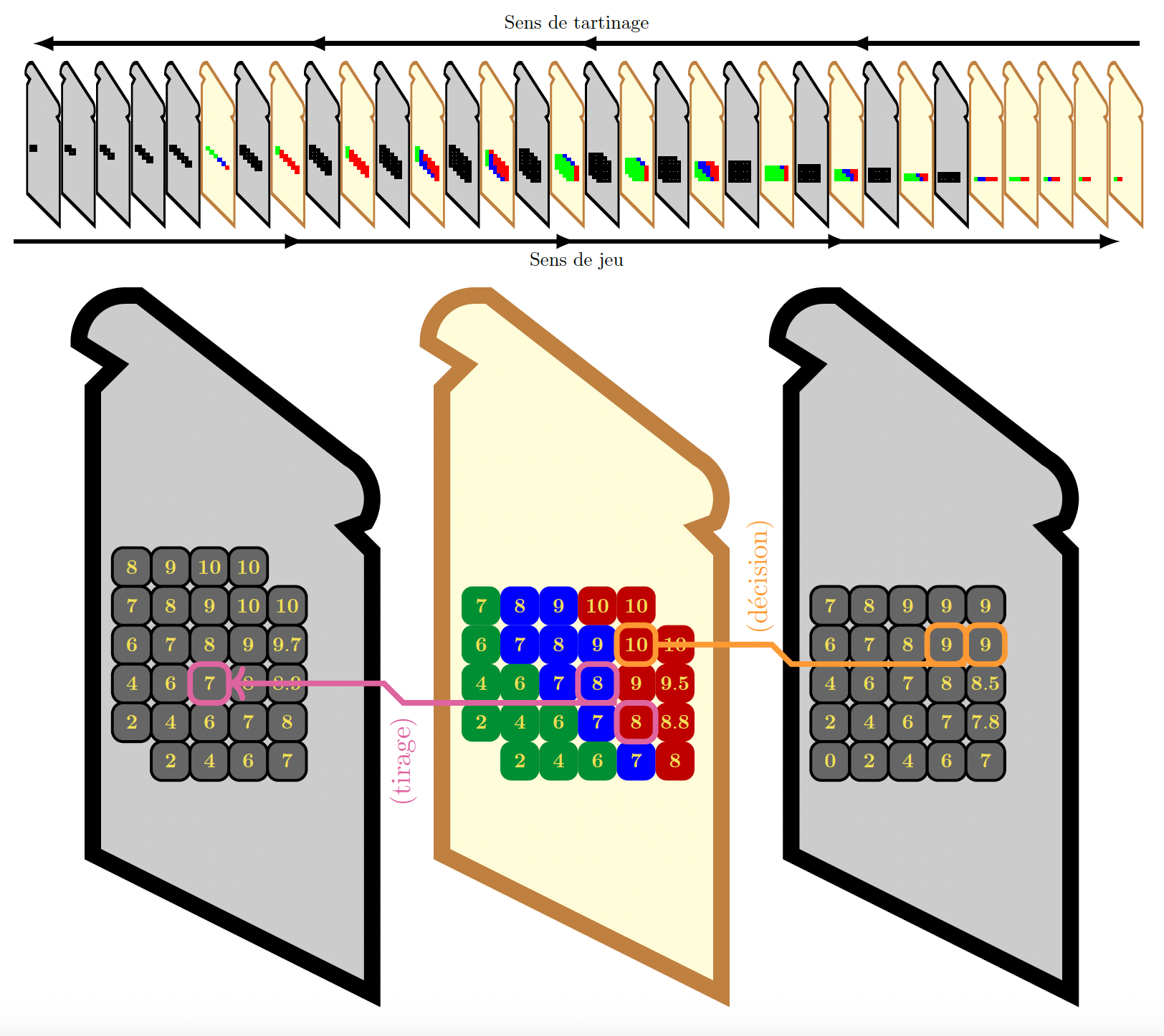
Figure 4 – Tranches de pain de mie beurrées puis tartinées de confiture.
- Si l’action est un tirage alors nous discutons les deux couleurs possibles, connaissant la composition de l’urne et donc les probabilités d’y tirer chacune des couleurs : \[ \mathsf{ScoreFin}(k,r_{\text{U}}, r_{\text{M}}) = \begin{array}{l} \overbrace{\frac{r_{\text{U}}}{r_{\text{U}}+v_{\text{U}}} \mathsf{ScoreFin}(k+1,r_{\text{U}}-1,r_{\text{M}}+1)}^{\textrm{Pioche }🔴} ~~ + \\ \underbrace{\frac{v_{\text{U}}}{r_{\text{U}}+v_{\text{U}}} \mathsf{ScoreFin}(k+1,r_{\text{U}},r_{\text{M}})}_{\textrm{Pioche }🟢 } \end{array} ~~ (\textrm{tirage}) \] où le nombre \(v_{\text{U}}\) de boules vertes dans l’urne est calculé comme dans l’encart 2.
- Si l’action est une décision, nous calculons le maximum des deux espérances de score selon la couleur de la boule jouée : \[ \mathsf{ScoreFin}(k,r_{\text{U}},r_{\text{M}}) = \max\left(\underbrace{S_k+\mathsf{ScoreFin}(k+1,r_{\text{U}},r_{\text{M}}-1)}_{\textrm{Joue }🔴}, \underbrace{\mathsf{ScoreFin}(k+1,r_{\text{U}},r_{\text{M}})}_{\textrm{Joue }🟢 } \right)~~ (\textrm{décision}) \] où \(S_k\) est le score sur le relief du kilomètre parcouru (pour rappel \(2\) en montée, \(1\) sur le plat, \(0\) en descente).
Parfois un des deux cas est exclu lorsque la main ou l’urne est monochrome.
La figure 4 montre comment le calcul se propage de la droite vers la gauche, en utilisant les deux formules ci-dessus. À partir des nombres dans les deux cases oranges sur la tranche de pain noir de droite, l’équation (décision) est utilisée pour calculer le nombre apparaissant sur la case orange de la tranche de pain blanc intermédiaire. De même avec les cases en rose, en utilisant l’équation (tirage).
Maintenant que nos tranches sont beurrées de nombres, passons aux confitures : une verte, de reine-claude, une rouge, de fraise, et une bleue, de myrtille. Nous tartinons uniquement les tranches de pain blanc associées aux décisions. Pour le carré \(r_{\text{U}}, r_{\text{M}})\) de la tranche \(k\), si le maximum calculé dans l’équation (décision) est atteint pour une seule boule nous tartinons de la confiture de la couleur de cette boule et sinon, les deux valeurs sont égales et nous tartinons en bleu. Au final, on n’a besoin de beurrer qu’un seul nombre par case de mie de pain, ce qui en fait un algorithme de complexité polynomiale (cubique). La partie supérieure de la figure 4 donne une idée globale du résultat.
Aussi les stratégies optimales se déduisent maintenant, de gauche à droite, de l’étalage des confitures uniquement sur les tranches où il a fallu…trancher : je commence ma partie en \(P_0=(0,r,0)\), où \(r\) est le nombre de boules rouges initialement dans l’urne, et je mange un carré de chaque tranche en jouant ma partie. Sur une tranche de pain noir, je suis le résultat du tirage. Sur une tranche de pain blanc, les carrés « confiturés » m’indiquent les décisions optimales.
L’équation (décision) contient l’essence de l’optimisation : la joueuse doit-elle s’assurer le score immédiat \(S_k\)k avec une boule rouge ou bien préserver cette boule dans sa main pour l’utiliser à meilleur escient plus tard ? La combinaison récurrente des équations (tirage) et (décision) induit une méthode de tartinage algorithmiquement simple mais complexe à calculer de tête. On pourrait espérer aller encore plus loin. La programmation dynamique est une méthode générale, que nous adaptons à notre jeu de cyclisme. Dans ce cas particulier, il pourrait exister, à l’instar du jeu de Nim, des règles plus simples que ces calculs d’espérance permettant de prendre des décisions optimales. Et en fait, il se trouve que sur les montées ou les descentes, les décisions sont simples :
Théorème 1 (Montées et descentes)
Sur un kilomètre en montée, jouer une boule rouge est toujours mieux (au sens large) qu’une boule verte.
Sur un kilomètre en descente, jouer une boule verte est toujours mieux (au sens large) qu’une boule rouge.
La preuve de ce théorème est laissée aux lectrices et lecteurs, mais intuitivement, on se rend bien compte qu’une boule rouge ne sera jamais mieux placée que sur une montée (et inversement pour une boule verte sur une descente). Reste le problème des kilomètres plats pour lesquels nous n’avons pas de règle aussi simple. Peut-être que les plus téméraires d’entre vous pourront en trouver ?
Exercice plus simple : sur la partie haute de la figure 4, pourriez-vous retrouver à partir des tartinages et du théorème 1 tout ou partie du relief du parcours ?
Nous utilisons ici l’optimisation de l’espérance du score comme but du jeu, mais ce n’est pas la seule possibilité. Par exemple, la joueuse pourrait s’élancer sur un contre-la-montre en connaissant le score d’un adversaire. Dans ce cas, son objectif serait de maximiser la probabilité de faire un score supérieur à ce score de référence. Et ce n’est pas forcément la même chose ! Autre exemple, la joueuse pourrait jouer en même temps que d’autres joueurs sur le même parcours, et chercher à maximiser la probabilité de terminer en première place (ou de ne pas terminer dernière). Dans ce cas, les tirages et les décisions de l’adversaire ont une influence sur les décisions de la joueuse. Cela transforme le jeu en un jeu à deux (ou plusieurs) joueurs, dans lequel il est envisageable d’appliquer des calculs de stratégie de type min-max. Le choix que nous avons fait de ne considérer que l’espérance du score n’est en fait qu’une goutte dans un océan de possibilités.
L’encart suivant résume ce qu’il y a à retenir des deux dernières parties.
Notre jeu de cyclisme tient dans une alternance de tirages et de décisions. Chaque décision influence le score, nous la capturons dans la compétence (skill). Chaque tirage influence aussi le score, capturé dans la chance (luck). Il y a au plus deux choix possibles à chaque décision. Lorsque les deux choix mènent à des scores différents, on dit qu’il y a un écart (gap), qui est justement cette différence, comptabilisée négativement. Plus la décision est mauvaise, plus l’écart est grand. La joueuse ne sait pas calculer ces écarts efficacement. Elle doit régulièrement choisir entre gagner des points immédiatement (cigale) ou investir sur le futur (fourmi). Mais l’influence de sa décision sur le score ne se voit pas instantanément. Un ordinateur peut calculer ces écarts, et distinguer une bonne et une mauvaise décision. La comparaison entre les deux est intéressante pour comprendre les limites humaines de calcul.
5. Analyse de données sur les parties jouées
Faisons un bilan intermédiaire optimiste de ce qui a été vu jusque-là. Dans la partie 1, nous avons présenté un jeu simple de gestion d’effort que la lectrice a pris en main en jouant durant la partie 2. La simplicité de ce jeu tient au fait que la joueuse doit trouver un équilibre entre deux contraintes opposées : un manque de boules rouges pour les montées et un manque de boules vertes pour les descentes. La partie 3 a proposé une définition pour séparer ce qui tenait de l’aléatoire, la chance de la joueuse, de ce qui était sous sa responsabilité, sa compétence. La partie 4 a montré que l’ordinateur avait un avantage calculatoire sur la joueuse, lui permettant de résoudre les problèmes induits par l’aléatoire. Cette partie se propose d’analyser et de mesurer comment la joueuse s’écarte de ces décisions optimales, du fait de ses limites calculatoires.
Intérêt aléatoire ?
L’aléatoire de ce jeu, c’est-à-dire les tirages dans l’urne, est très précieux pour plusieurs raisons. D’abord, il demande d’envisager un nombre bien trop grand d’éventualités pour la joueuse. Selon nous, cela la force à s’appuyer sur son intuition pour estimer la bonne décision et non sur son goût pour le calcul. Ce dilemme n’est pas sans rappeler l’exemple de la batte et la balle (cf. Bat and ball). À l’opposé, l’ordinateur peut traiter efficacement cette multitude de cas. Il peut détecter les bonnes et les mauvaises décisions, et même quantifier l’amplitude des erreurs via les écarts (gaps). Essayer de comprendre l’écart entre le modèle intuitif que la joueuse se construit et les décisions optimales est l’un des enjeux que nous voulons explorer.
Ensuite, l’aléatoire permet de répéter la même expérience un grand nombre de fois, offrant à la joueuse de multiples décisions à des petites perturbations d’un même problème. Au fil des répétitions, la joueuse affine son modèle intuitif, en particulier sa prise d’informations (relief, boules rouges en main… ). Nous espérons que ce jeu l’amène à se construire un modèle intuitif simple, stable et finalement observable à travers nos mesures.
Enfin, l’aléatoire invite la joueuse à rester attentive aux tirages récents, qui peuvent à tout instant remettre ses plans en cause. Toute forme de planification à long terme est vouée à l’échec, et il est nécessaire de pouvoir adapter sa stratégie en cas de tirage inattendu.
Notre Graal est ici un modèle descriptif voire prédictif pour les erreurs de la joueuse. Nous espérons qu’il révèlera des biais déjà répertoriés ou pourquoi pas nouveaux, dont nous pourrions quantifier les influences relatives. Nous ne présentons ici que les premières étapes de la construction de ce modèle.
Collecte de données
Un des objectifs de cet article est d’attirer des joueurs et joueuses sur notre site web afin de leur faire jouer des parties, et surtout collecter leurs erreurs. Ironiquement, les joueuses ou joueurs parfaits ne nous intéressent pas ! Nous aspirons à construire une base de données de parties afin de réaliser des statistiques sur les décisions. Cette base est librement accessible à tous et toutes à travers ce lien. Pour chaque partie jouée, la base stocke le parcours, les tirages dans l’urne, l’identité (login) et les décisions de la joueuse ainsi que la date de jeu et la durée en millisecondes entre chaque décision. Indépendamment de cette future collecte, nous disposons déjà d’un ensemble de parties permettant de faire quelques statistiques.
Indépendance de la chance et de la compétence ?
Le score final est la somme de deux termes : la chance (luck) et la compétence (skill) (cf. SkillLuck). Idéalement, ces deux variables seraient des variables indépendantes. Si c’est le cas, la chance n’a pas d’influence sur la compétence et donc cette dernière résume la qualité des décisions de la joueuse. Nous avons à notre disposition des outils statistiques. Qu’observons-nous dans nos parties collectées ?
|
skill de la partie |
skill de la partie |
| Figure 5 – Diagramme (skill, luck) sur la totalité des parties puis uniquement sur 484 les mieux jouées. | |
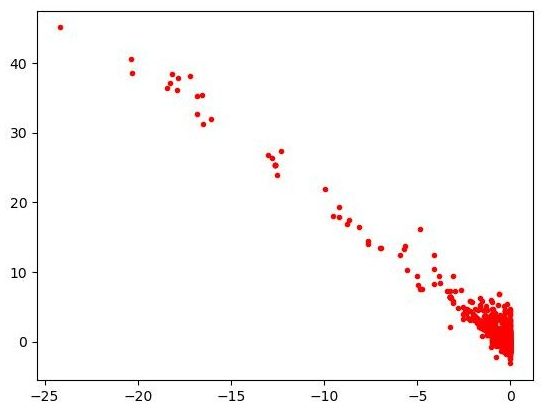
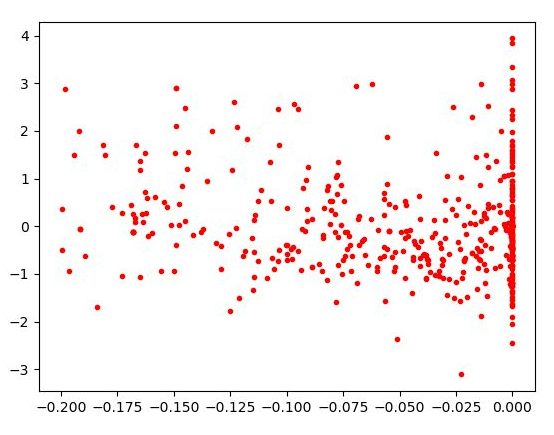
Sur la figure 5 (a), chaque partie jouée sur notre site est représentée par un point de coordonnées \((\mathsf{skill}, \mathsf{luck})\). Le nuage de points obtenu nous indique une forte dépendance, presque linéaire, entre les deux, ce qui ne va pas dans notre sens. Heureusement, si l’on se restreint à la moitié des parties les mieux jouées, qui correspondent à \(\mathsf{skill} \geq -0.2\), on obtient la figure 5 (b). Intuitivement, ce nuage de points est bien plus proche du cas où la chance et la compétence seraient indépendantes. Cette simple impression sur nos données actuelles pourrait être confirmée en appliquant des tests statistiques classiques.
Distiller la compétence
Sous cette hypothèse d’indépendance, nous pouvons observer le poids respectif des deux variables \(\mathsf{Skill}\) et \(\mathsf{Luck}\) sur le score final. Comme l’écart-type de la compétence est de \(0.0574\) tandis que celui de la chance est de \(1.157\), on en déduit que le score est influencé pour \(5\%\) par la compétence et pour \(95\%\) par la chance. La chance peut être vue comme un bruit que l’on cherche à éliminer. Ignorer la chance dans le score, c’est-à-dire la réduire à la compétence, élimine ce bruit et fournit une estimation \(20\) fois plus précise de la compétence de la joueuse. Sans ce calcul, pour arriver au même niveau de précision, il faudrait multiplier par quelques dizaines le nombre de parties réalisées par la joueuse.
Prédire l’erreur par l’écart (gap)
Nous souhaitons construire un modèle prédictif pour les erreurs des joueuses. Une idée serait d’exhiber un lien entre probabilité d’erreur et largeur de l’écart entre les deux décisions possibles. Commençons par faire le postulat de l’intuition suivante :
“L’erreur est d’autant plus probable que le gap associé à la décision est faible (mais non nul).”
Comment quantifier la pertinence d’une telle affirmation sur nos données ? Pour chaque partie, on s’intéresse aux décisions prises sur les kilomètres plats (les décisions sur les autres pentes entrent dans les hypothèses du théorème 1). Dans notre base actuelle, cela représente environ 17 000 décisions. Nous construisons une estimation empirique de la probabilité \(\mathsf{Proba}(g)\) de faire une erreur sachant que l’écart vaut \(g\). Nous considérons les 1 000 décisions les plus proches de cet écart \(g\), et nous calculons la fréquence des erreurs, que nous élevons au rang de probabilité. La figure 6(a) donne le résultat de notre estimation de \(\mathsf{Proba}(g)\) sur nos données, et va dans le sens de l’affirmation initiale. Nous obtenons un prédicteur d’erreur, à savoir une fonction qui étant donné ici l’écart d’une décision nous retourne la probabilité de faire une erreur sur celle-ci. Des informations plus fines que l’écart pourront être envisagées ultérieurement.
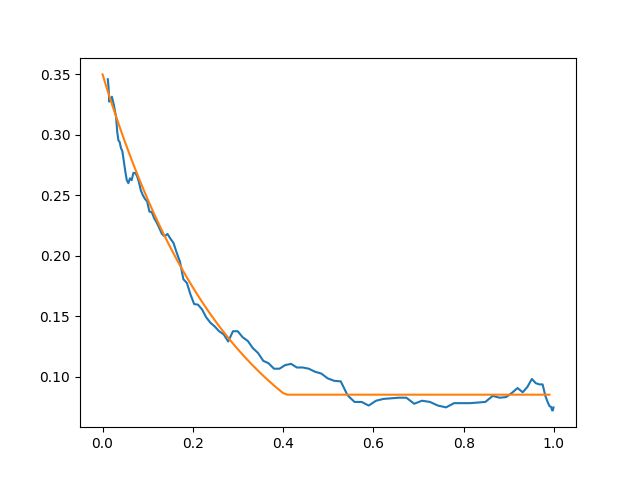 (a) Erreur en fonction de l’écart (gap) |
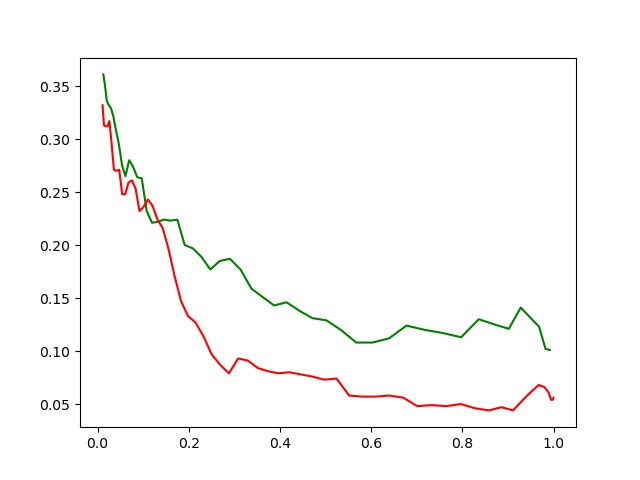 (b) Erreur en distinguant la couleur jouée |
|
Figure 6 – À gauche, estimation statistique (en bleu) de la probabilité d’erreur en fonction de l’écart de la décision et approximation numérique (en orange), à l’aide d’un max et d’une exponentielle. À droite, estimation empirique de |
|
Des parcours faciles et difficiles
Une application possible de ce prédicteur d’erreur, est de chercher à générer des parcours plus ou moins difficiles. Choisissons un parcours \(p\) au hasard. Grâce à notre modèle d’erreur nous avons une stratégie probabiliste pour jouer une partie : le choix de la joueuse (sur les kilomètres de plat) est aléatoire, jouant mal selon la probabilité \(\mathsf{Proba}(\mathsf{gap}(d))\) pour chaque décision \(d\). Ainsi, par la même technique de programmation dynamique vue en partie 4, nous pouvons estimer le nombre moyen d’erreurs \(\overline{\mathsf{err}}(p)\) sur ce parcours \(p\). Il devient alors possible de générer un parcours comportant en moyenne un nombre d’erreurs donné pour une joueuse donnée. Ainsi nous pouvons doser la difficulté d’un parcours.
Nous avons fait cette expérience et obtenu le résultat paradoxal suivant : plus les parcours étaient durs selon le modèle, moins nous faisions d’erreurs ! Nous nous sommes rendus compte de notre progression illusoire, en rejouant à nouveau sur des parcours totalement aléatoires, notre taux d’erreur retrouvant ses standards précédents. Une interprétation possible est la suivante : en augmentant la difficulté théorique des parcours, nous avons concentré la génération de parcours dans un sous-ensemble peu varié. En jouant sur ces parcours peu variés, nous avons ajusté rapidement notre intuition sur ces cas particuliers et obtenu de meilleurs résultats comme en jouant toujours la même gamme au piano. La leçon, qui reste à consolider, de cette application directe et naïve du modèle d’erreur, est qu’il faut aussi songer à la variété des parcours dans la génération pour que le modèle d’erreur reste pertinent.
Des symétries cachées
Revenons à l’analyse mathématique du jeu pour révéler une symétrie peut-être cachée à certains d’entre vous. Sur la figure 6, la courbe bleue montre le taux d’erreur en fonction de l’écart. Il est possible de distinguer les erreurs faites en posant une boule verte (courbe verte) ou une boule rouge (courbe rouge). On constate alors qu’il est plus fréquent de faire des erreurs sur les boules vertes. Plus précisément, nous observons sur les données collectées que pour les boules vertes jouées (sur des kilomètres plats) avec une possibilité d’erreur, une erreur est commise avec une probabilité de \(0.201\) alors que pour les boules rouges elle n’est que de \(0.147\). Cette dissymétrie est-elle le produit du jeu ou de la joueuse ?
Nous pouvons en fait mettre hors de cause le jeu. En effet, il existe une symétrie cachée dans le jeu échangeant les boules rouges et vertes (ainsi que les montées et les descentes), mais laissant les stratégies invariantes (cf. encart 5 pour les détails dans les coins). De plus, la génération aléatoire des parcours ne brise pas cette symétrie : la probabilité de générer un parcours est la même que celle de son symétrique. Donc cela implique que la joueuse fait des erreurs différentes en posant des boules rouges plutôt que des boules vertes. Notre interprétation est que nous sommes instinctivement plus sensibles à la contrainte sur le placement des boules rouges, qui font gagner du score, plutôt que celle des boules vertes, qui dans tous les cas n’en font jamais gagner. Cela signifie que la présentation du jeu biaise notre jugement. Maintenant que nous vous l’avons dit, êtes-vous sûre de pouvoir vous en affranchir ?
Changeons les règles de calcul du score : maintenant les deux seuls moyens de gagner du temps sont soit de jouer une boule rouge sur une montée, soit de jouer une boule verte sur une descente. Dans les deux cas, cela rapporte 1 :
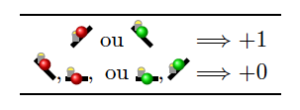
Nommons \(\mathsf{Score}_{\mathsf{sym}}\) le score selon cette convention à comparer au score usuel \(\mathsf{Score}\). Toute partie peut être évaluée selon l’un ou l’autre de ces critères de score. On peut montrer qu’ils ne diffèrent que d’une constante :
Théorème 2 (Transformation des scores)
Pour toute partie \(\mathbf{P}\) jouée sur un parcours \(p\) et une urne initiale \(U\) :
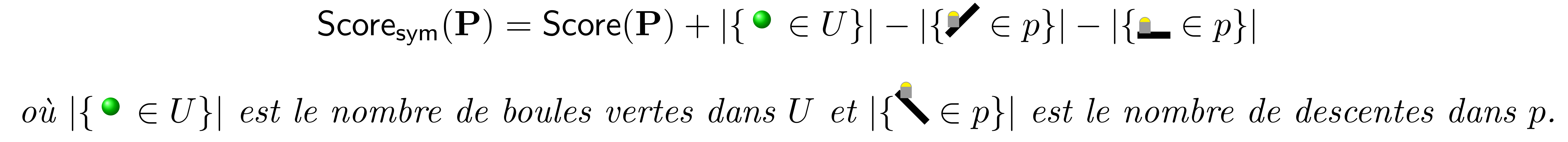
La différence entre les deux scores est indépendante des décisions prises pendant la partie. Ainsi, optimiser \(\mathsf{Score}_{\mathsf{sym}}\) est équivalent à optimiser \(\mathsf{Score}\), et les deux jeux sont équivalents. Partant de ces nouvelles règles, une autre symétrie apparaît. Pour un parcours \(p\) et une urne initiale \(U\), définissons leurs symétriques \(\overline{p}\) dans lequel les montées de \(p\) deviennent des descentes et vice versa, et \(\overline{U}\) dans laquelle les boules rouges deviennent vertes et réciproquement.
Théorème 3 (échange des couleurs et des pentes)
Une partie de score \(g \) sur \((p,U)\) correspond à une partie de score \(g\) sur \(( \overline{p}, \overline{U})\) dans laquelle on échange les décisions sur chaque kilomètre et les pioches dans l’urne.
Donc, optimiser \(\mathsf{Score}_{\mathsf{sym}}\) sur un parcours \((p, U )\) est équivalent à optimiser \(\mathsf{Score}_{\mathsf{sym}}\) sur \(( \overline{p}, \overline{U})\). Sans surprise, ce score respecte la symétrie !
Conclusions et perspectives
Nous vous avons présenté deux modèles pour une expérience. Le premier modèle est un jeu, dont nous proposons une analyse combinatoire, donnant un moyen de séparer l’aléatoire et la pertinence des décisions. L’expérience consiste à enregistrer des ensembles de décisions de joueuses humaines sur des parties pour évaluer leur pertinence comparée à des décisions optimales. Le second modèle porte sur la prédiction des erreurs humaines dans ce jeu. Nous avons besoin de données pour préciser, confirmer ou infirmer les choix faits dans ce second modèle. À vous de jouer !
- Noise : pourquoi nous faisons des erreurs de jugement et comment les éviter de Daniel Kahneman, Olivier Sibony, Cass R. Sunstein, 2021 [KSS21], qui est entre autre la rencontre des auteurs de Système 1/ Système 2 : Les deux vitesses de la pensée Daniel Kahneman, 2016 [Kah16] et Vous allez commettre une terrible erreur ! de Olivier Sibony, 2019 [Sib19]. Ces livres d’économistes présentent des études de cas et discutent d’expériences psychologiques.
- Théorie des jeux de Nicolas Eber, 2018, qui permet d’explorer d’autres façons de modéliser les jeux, plus particulièrement dans le cadre des jeux à deux joueurs, dans un contexte adversarial (avec l’exemple du dilemme du prisonnier) ou coopératif.
- Le cours de Processus stochastiques de Jean-François Marckert, plus particulièrement la partie 6 sur les processus de décisions markoviens, offre une présentation différente de la partie 4.
- Pour ceux qui penseraient que la conception de jeu de vélo est un art mineur ou récent, nous suggérons l’exploration du site cyclingboardgames.net pour un festival de modélisation ludique.
- [Kah16] Daniel Kahneman. Système 1, système 2 : les deux vitesses de la pensée. Flammarion, 2016.
- [KF05] Daniel Kahneman and Shane Frederick. A model of heuristic judgment. In K. Holyoak and B. Morrison, editors, The Cambridge Handbook of Thinking and Reasoning, pages 267–293. Cambridge University Press, 2005.
- [KSS21] Daniel Kahneman, Olivier Sibony, and Cass. R Sunstein. Noise : Pourquoi nous faisons des erreurs de jugement et comment les éviter. Odile Jacob, 2021.
- [Min61] Marvin Minsky. Steps toward artificial intelligence. Proceedings of the Institute of Radio Engineers (les prédécesseurs du fameux IEEE), 49(1):8–30, 1961.
- [Sib19] Olivier Sibony. Vous allez commettre une terrible erreur ! Flammarion, 2019.
Cet article est aussi disponible sur HAL.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Yvan Le Borgne
Chercheur CNRS, au sein de l'équipe Combinatoire et Algorithmique du LaBRI à l'Université de Bordeaux.
David Renault
Maître de conférences à l'ENSEIRB-MATMECA et chercheur au LaBRI sur les thèmes des graphes, de la logique et des groupes.