
Mémoire et unité centrale, un couple dédié à l’exécution des programmes
Dans les années 1945, John Von Neumann définit l’architecture des ordinateurs dits à programme enregistré. Ces ordinateurs se distinguent de leurs prédécesseurs par le fait qu’ils disposent d’un programme composé d’instructions qui doivent être placées dans une mémoire. Chaque instruction définit une action à réaliser sur des données, par exemple une addition entre deux nombres. Auparavant, les premiers ordinateurs n’étaient pas programmables. Ils n’exécutaient qu’un seul programme câblé dans l’ordinateur. Chaque exécution d’un nouveau programme nécessitait de recâbler l’ordinateur. L’ENIAC (Electronic Numerical Integrator and Computer), un des premiers ordinateurs électroniques achevé en 1946, est l’exemple type de ce genre de machine. Il occupait une surface de 167 m2 et consommait 150 Kilowatt. Sur cette machine, une multiplication était réalisée en 0,001 seconde ; de nos jours, une telle opération demande 30 nanosecondes.

Figure 1 : L’ENIAC (Electronic Numerical Integrator And Computer) à Philadelphie. Exemple d’un ordinateur câblé.
Crédits : U.S. Army Photo / Public Domain via Wikimedia
L’architecture des ordinateurs à programme enregistré comporte les éléments suivants :
- Une unité centrale chargée d’exécuter les instructions d’un programme ;
- Une mémoire centrale qui contient les instructions d’un programme ;
- Des unités d’entrées-sorties prenant en charge l’échange d’informations entre le couple unité centrale-mémoire centrale et l’extérieur de l’ordinateur, via des périphériques tels que le clavier, la souris, l’écran, etc.
Cette architecture est toujours celle mise en œuvre dans les ordinateurs actuels.
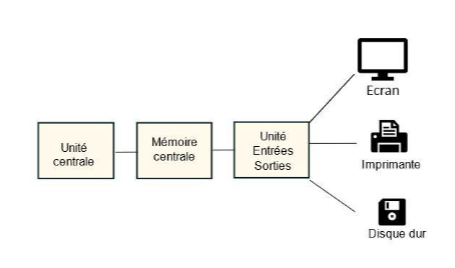
Figure 2 : Architecture de Von Neumann.
La mémoire centrale
La mémoire centrale contient le programme que le processeur doit exécuter ; ce programme est constitué d’un ensemble d’instructions et de données sur lesquelles les instructions vont agir.
Données et instructions sont codées sous forme de chaînes binaires et sont contenues dans des mots de la mémoire. Un mot est un emplacement de la mémoire, constitué d’un nombre fixe d’octets, typiquement 4 ou 8 ; il contient une information (instruction ou donnée) et il est identifié de façon unique par une adresse.
Cette adresse permet au processeur de nommer le mot qu’il souhaite utiliser. Ce nom est le rang du mot dans la mémoire ; ainsi le processeur désigne le mot 0, le mot 1, le mot 2, etc. Finalement, la mémoire centrale peut être vue comme un tableau de mots, chaque mot étant désigné par son rang dans le tableau.
Le processeur utilise cette adresse pour désigner le mot sur lequel il doit agir. Le processeur peut soit demander à lire un mot auquel cas il va obtenir comme information le contenu de ce mot, soit demander à écrire dans un mot auquel cas il va enregistrer une information dans ce mot.
Le processeur communique avec la mémoire centrale par l’intermédiaire d’un bus de communication. Un bus est un support de communication permettant l’échange d’informations entre deux composants. Par exemple, en se référant à la figure 3 ci-dessous, si le processeur désire lire un mot d’adresse 7, il va placer sur le bus l’adresse 7 et activer la commande « lecture » ; la mémoire en retour place sur le bus la donnée contenue dans le mot d’adresse 7, soit 128.
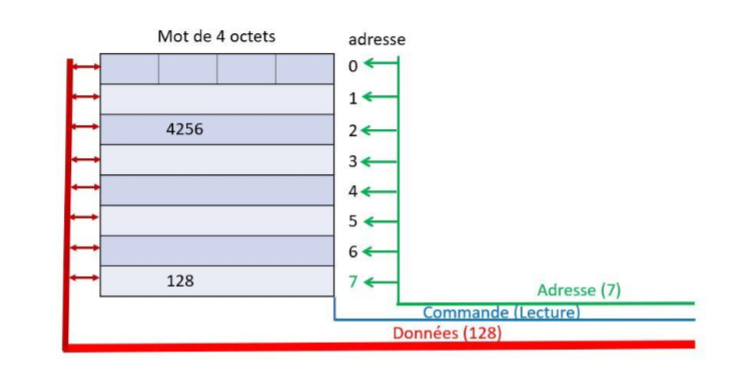
Figure 3 : Mots et adressage de la mémoire centrale avec des mots de 4 octets.
Cette mémoire centrale est aussi appelée mémoire vive, car c’est une mémoire volatile : le contenu des mots disparait s’il n’y a plus d’alimentation électrique de l’ordinateur. On la désigne aussi sous le nom de RAM pour Random Access Memory.
Elle est caractérisée notamment par un temps d’accès et une capacité.
- La capacité représente le volume global d’informations que la mémoire peut contenir, par exemple 1 gigaoctet (Go), soit 230 octets, soit 230 × 8 bits.
- Le temps d’accès correspond au temps que doit attendre le processeur pour obtenir une information délivrée par la mémoire centrale.
La capacité usuelle d’une mémoire centrale sur un ordinateur personnel actuel est de 4 à 8 Go.
La RAM se présente sous forme de barrettes, un circuit imprimé de forme rectangulaire enfichable sur la carte mère et qui comporte sur ses deux faces des puces mémoires.

Figure 4 : Barrette mémoire.
Le processeur
Le processeur (CPU, pour Central Processing Unit) est le cerveau de l’ordinateur. Il permet d’exécuter des instructions codées sous forme binaire.
Le processeur est un circuit électronique cadencé au rythme d’une horloge interne qui envoie des impulsions, appelées « top ». La fréquence d’horloge correspond au nombre d’impulsions par seconde. Elle s’exprime en Hertz (Hz). De nos jours, les processeurs possèdent par exemple une fréquence d’horloge de 2 GHz, ce qui correspond à 2 000 000 000 de battements par seconde. Le temps s’écoulant entre chaque battement constitue un cycle processeur, durant lequel le processeur exécute une action élémentaire permettant l’exécution d’une partie d’instruction.
Le processeur est composé de plusieurs éléments :
- Des unités de mémorisation appelées registres qui permettent la mémorisation d’informations au sein du processeur. Leur accès est très rapide. Parmi ces registres, certains sont spécialisés, c’est-à-dire qu’ils ont un rôle précis au sein du processeur et ils ne peuvent pas être utilisés pour une autre tâche. D’autres registres, au contraire, sont des registres banalisés ; ils servent notamment à stocker au niveau du processeur des résultats de calculs intermédiaires. Ces registres banalisés sont classiquement désignés par un numéro ; ainsi le registre banalisé 1 s’appelle R1, le registre banalisé 2 s’appelle R2, etc.
- Une unité d’exécution qui permet au processeur de réaliser des calculs ; elle comprend notamment un circuit appelé Unité Arithmétique et Logique (UAL) qui est constitué de l’ensemble des circuits arithmétiques et logiques permettant au processeur d’effectuer les opérations élémentaires telles que des additions, des soustractions, des multiplications ou des comparaisons, etc.
- Une unité de commande qui cadence et pilote le travail du processeur ; ce pilotage s’effectue au rythme du signal d’horloge délivré à celle-ci et qui définit les cycles du processeur.
- Des unités de communication qui permettent à l’information de circuler entre les différents composants du processeur.
Il se présente sous la forme d’une puce électronique reliée à la carte mère de l’ordinateur grâce à un socle appelé « socket » et il est surmonté d’un dispositif dissipant la chaleur produite lors de son fonctionnement.

Figure 5 : Processeur surmonté de son refroidisseur.
Exécuter un programme
Le rôle du processeur est donc d’exécuter les instructions d’un programme placé dans la mémoire centrale. Au sein du processeur, c’est l’unité de commande qui a la charge de piloter les actions menant à l’exécution d’une instruction. Le processeur agit ici comme un automate ; il exécute chaque instruction les unes à la suite des autres.
À ce niveau, une instruction est une chaîne binaire qui comprend deux grandes parties. La première partie de cette chaîne indique quelle est l’opération à réaliser, par exemple une addition, une lecture de la mémoire, le chargement du registre banalisé avec une valeur. Elle constitue le code opération de l’instruction. La seconde partie précise quelles sont les données sur lesquelles l’action indiquée par le code opération doit être réalisée. Cette seconde partie constitue les opérandes de l’instruction. Les opérandes de l’instruction peuvent être de différentes natures. Cela peut être une valeur, une donnée contenue dans un registre banalisé du processeur ou une donnée stockée dans un mot de la mémoire centrale. Par exemple, l’instruction indique qu’il faut faire une addition entre la valeur contenue dans le registre R1 du processeur et une valeur 10. Ou l’instruction indique qu’il faut placer la valeur se trouvant dans un mot mémoire d’adresse 100 dans le registre banalisé R1.
Pour chaque instruction à exécuter, le processeur réalise les trois étapes suivantes :
- Lecture de l’instruction,
- reconnaissance de l’instruction et recherche des opérandes,
- réalisation de l’opération reconnue.
Lors de la première étape, l’unité de commande lit l’instruction du programme à exécuter en mémoire centrale. Cette phase est appelée « FETCH ». Pour cela, l’unité de commandes utilise deux registres dédiés du processeur :
- Le Compteur Ordinal (CO) : ce registre contient toujours l’adresse en mémoire centrale de la prochaine instruction du programme à exécuter ;
- Le Registre Instruction (RI) : ce registre contient l’instruction en cours d’exécution par le processeur.
Cette phase consiste donc pour l’unité de commande à opérer une lecture en mémoire centrale du mot dont l’adresse se trouve dans le registre CO et à stocker le contenu de ce mot dans le registre RI. Puis elle modifie le contenu du CO pour qu’il contienne maintenant l’adresse de l’instruction qui suit celle qui vient d’être placée dans le registre RI.
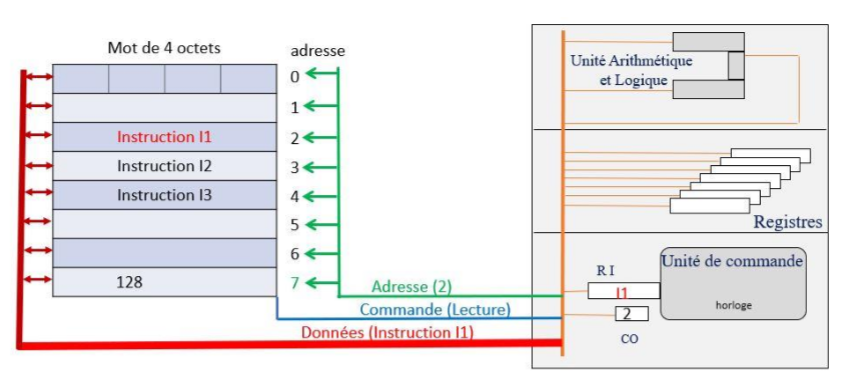
Figure 6 : Phase FETCH : Le processeur place par exemple l’adresse 2 contenue dans le registre CO sur le bus à destination de la mémoire centrale et commande une lecture. Le contenu du mot d’adresse 2, qui est l’instruction I1, est lu et copié dans le registre RI.
Une fois l’instruction lue et placée dans le registre RI, l’unité de commande reconnaît le code opération de cette instruction, puis elle se charge de placer dans les registres banalisés du processeur les opérandes sur lesquels l’action indiquée par le code opération devra se faire. En effet, les calculs réalisés par le processeur ne peuvent se faire que sur des données mémorisées au sein de celui-ci. Ceci implique donc que si les opérandes sont des données enregistrées en mémoire centrale, à cette étape, l’unité de commande se charge de les lire et de les placer dans des registres banalisés.
Une fois les opérandes lus, l’unité de commande entame la troisième étape. Elle déclenche les actions utiles au sein du processeur pour réaliser l’opération indiquée par le code opération sur les opérandes concernés. Notamment s’il s’agit d’une opération arithmétique, elle va solliciter l’unité arithmétique et logique (UAL). Cette dernière comporte deux entrées sur lesquelles sont positionnés les opérandes, une ligne opération qui permet de choisir le circuit à activer et une sortie sur laquelle est positionné le résultat de l’opération réalisée.
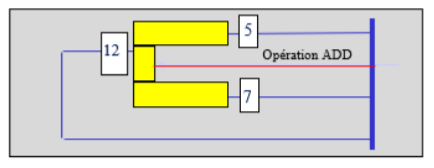
Figure 7 : L’unité arithmétique et logique, addition de deux opérandes 5 et 7
Résumons les étapes de la réalisation d’une instruction qui, par exemple, demande l’addition du registre R1 avec l’opérande contenu dans le mot d’adresse 7 et le stockage du résultat dans le registre R2 en nous référant à la mémoire centrale telle qu’elle est représentée sur la figure 4.
Nous pouvons écrire :
FETCH : CO → bus ; lecture ; bus → RI ; Incrément CO
Recherche des opérandes : 7 → bus ; lecture ; 128 –> bus
Réalisation : Bus → entrée UAL ; R1 → entrée UAL ; addition ; Sortie UAL → R2
Ces différentes étapes constituent le chemin d’exécution de l’instruction. Pour se réaliser, il nécessite l’activation au sein du processeur de micro-commandes. Ces signaux activés au sein du processeur sous le contrôle de l’unité de commande permettent notamment de :
- demander une lecture ou une écriture de la mémoire centrale ;
- activer les circuits de l’UAL ;
- ouvrir et fermer les registres afin de faire circuler les données.
Ainsi CO → bus nécessite d’ouvrir le registre CO afin que le contenu de CO puisse en sortir et être placé sur le bus. Chaque instruction correspond à un ensemble de micro-commandes, regroupées dans des micro-instructions. Chaque micro-instruction est exécutée durant un cycle de processeur. L’ensemble des micro-instructions correspondant à une instruction donnée forme un micro-programme.
Ces micro-programmes sont écrits par le concepteur de processeur. Ils sont stockés dans un circuit appelé séquenceur qui fait partie de l’unité de commande. Un second circuit de l’unité de commande, le circuit décodeur, en reconnaissant l’instruction placée dans le registre RI, active le micro-programme qui doit être exécuté.
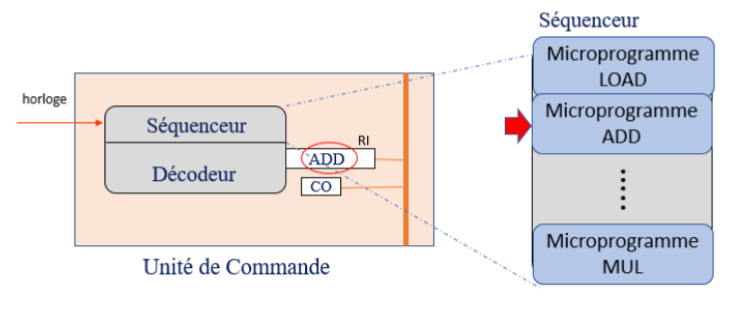
Figure 8 : Décodeur et séquenceur. Le séquenceur contient les micro-programmes des différentes instructions (exemple ADD pour addition, LOAD pour chargement d’un registre, MUL pour multiplication). Le registre RI contient une instruction ADD ; l’unité de commande active le micro-programme correspondant.
Performances : cache et pipeline
Lorsqu’il exécute une instruction, le processeur est amené à réaliser plusieurs accès à la mémoire centrale, pour lire l’instruction, tout d’abord lors de la phase FETCH puis éventuellement pour lire les opérandes qui se trouvent dans la mémoire centrale.
Ces accès sont des opérations pénalisantes pour le processeur, car la mémoire centrale est un circuit plus lent que le processeur. Autrement dit, lorsque le processeur interroge la mémoire centrale, il doit attendre sa réponse et passer des cycles à ne rien faire.
Pour pallier ces problèmes et améliorer les performances du processeur, deux techniques sont mises en œuvre. La première consiste à réduire le nombre d’accès du processeur à la mémoire centrale. Pour cela, de petites unités de mémorisation très rapides appelées mémoires caches sont placées entre le processeur et la mémoire centrale. Ces mémoires caches sont gérées de façon à contenir les informations, instructions ou données, dont le processeur a couramment besoin ou dont il aura besoin dans un futur proche. Ainsi, lorsque le processeur interroge la mémoire centrale pour lire un mot dans celle-ci, le mécanisme associé à la mémoire cache fait que l’information est tout d’abord recherchée dans le cache. Si l’information est présente, on parle de succès. Dans ce cas, le processeur y accède très rapidement. Par contre, si l’information est absente de la mémoire cache, on parle de défaut. La mémoire centrale est alors interrogée et le mot contenant l’information est lu et délivré au processeur. Cependant, pour que les accès ultérieurs à cette même information soient plus rapides par la suite, le mot est aussi copié dans la mémoire cache.
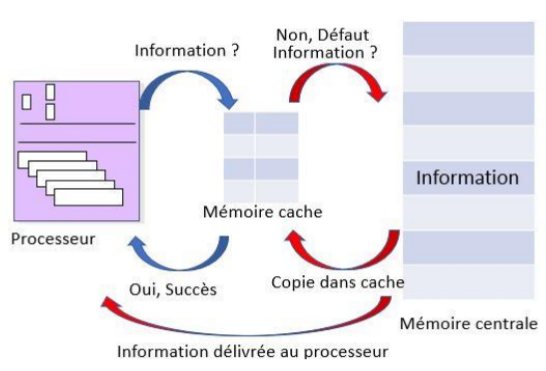
Figure 9 : Principe des mémoires caches.
La seconde technique consiste à paralléliser l’exécution des instructions d’un programme en permettant un chevauchement dans la réalisation des trois étapes FETCH (F), Décodage-Recherche des opérandes (DR), Exécution (E).
Ainsi, plutôt que de réaliser le chemin suivant pour l’instruction I1, I2, I3, I4, I5 :

on effectue un chevauchement des étapes : pendant que l’étape de décodage est lancée pour l’instruction I1, l’unité de commande exécute la phase de FETCH pour l’instruction I2. Puis, lorsque l’instruction I1 passe dans la phase d’exécution, l’unité de commandes commence le décodage de l’instruction I2 et en parallèle le FETCH de l’instruction I3.
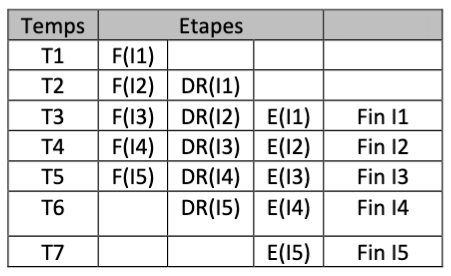
Cette technique est celle du pipeline. Elle permet d’augmenter le débit d’exécution des instructions par le processeur, c’est-à-dire le nombre d’instructions exécutées par unité de temps. En effet, dans le premier cas, il y a toujours un intervalle de trois espaces de temps avant que l’exécution d’une instruction ne soit achevée. Avec le pipeline, une instruction s’achève à chaque nouvel intervalle de temps, une fois la première instruction entièrement traitée. Le nombre d’instructions exécutées par unité de temps est multiplié par le nombre d’instructions exécutées simultanément, ici 3.
Toujours plus vite…
Pipeline et cache équipent tous les processeurs actuels et contribuent grandement à l’amélioration des performances, c’est-à-dire à l’augmentation du nombre d’instructions exécutées par seconde par le processeur.
Cependant, les demandes en capacité de calcul sont toujours plus grandes, par exemple afin de traiter de gros volumes de données, traiter des flux vidéo importants ou exécuter plus de tâches simultanément.
Une autre façon d’améliorer les performances d’un processeur consiste à augmenter la fréquence d’horloge qui lui est associée. En effet, plus la fréquence de l’horloge du processeur est élevée, plus les cycles processeur se succèdent rapidement, permettant ainsi d’exécuter plus vite les actions élémentaires constituant une instruction. Depuis les premiers processeurs jusqu’aux processeurs actuels, en l’espace de 50 ans, la fréquence a été multipliée par un facteur 106.
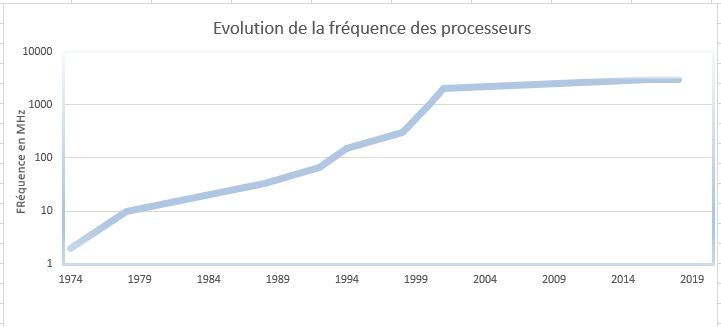
Figure 10 : Évolution de la fréquence des processeurs en 50 ans.
Cependant, cette méthode atteint sa limite. Lorsque l’unité centrale fonctionne, elle dégage de la chaleur qu’il faut dissiper, car une surchauffe des composants peut entrainer des dysfonctionnements tels que des erreurs de calcul ou des arrêts intempestifs. Les systèmes de ventilation actuels s’avèreraient insuffisants pour réguler la température de processeurs de fréquence supérieure aux fréquences actuelles et il faudrait leur substituer des dispositifs beaucoup plus couteux ou bruyants.
Une autre approche a vu le jour dans les années 2000. Elle consiste à placer plusieurs cœurs physiques de processeur au sein d’une même puce. Un cœur physique ou « core » est constitué de l’ensemble des circuits nécessaires à l’exécution des instructions-machine telles que nous les avons vus : registres, unité de commande et unité d’exécution. On parle alors d’architecture « multi-core » de processeur. Ainsi, une architecture dual-core comprend deux cœurs au sein du processeur qui travaillent de façon parallèle.
En multipliant de cette façon les cœurs au sein de la puce du processeur, la puissance de calcul est augmentée sans que la fréquence ne soit modifiée. En effet, chaque cœur peut exécuter de façon indépendante des flux d’instructions et ces exécutions parallèles permettent ainsi de gagner en vitesse d’exécution.
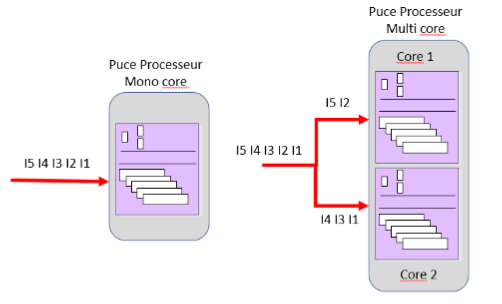
Figure 11 : Architecture mono-core versus multi-core : le flux d’instructions est reparti entre les cœurs.
Conclusion
Comme nous l’avons vu, l’unité centrale et la mémoire centrale sont les deux composants ayant un rôle fondamental dans le processus d’exécution des programmes. La mémoire centrale contient les instructions et données des programmes dans les mots adressables qui la composent. L’unité centrale ou processeur exécute ces instructions les unes à la suite des autres, à la façon d’un automate qui enchaine les étapes de FETCH, recherche des opérandes et réalisation de l’opération.
En 50 ans, la puissance des processeurs et sa capacité à exécuter toujours plus d’instructions dans un temps réduit n’a cessé d’augmenter et continue de constituer un enjeu important compte-tenu des volumes de données toujours plus grands à traiter et de l’expansion de l’automatisation des traitements. Mémoire cache, pipeline, augmentation de la fréquence du processeur, architecture multi-core contribuent à remplir cet objectif en agissant selon trois principes :
- augmenter la puissance du processeur même
- paralléliser le travail d’exécution des instructions
- pallier les performances moindres d’autres composants de la machine sollicités par le processeur tels que la mémoire ou les dispositifs d’entrées-sorties.
- Joëlle Delacroix and co, Fluoressciences, les Manuels visuels pour la licence, Informatique, Dunod, 2017
- Les microprocesseurs, comment ça marche, Gregg Wyant, Tucker Hammerstrom, Dunod, 1995
- Architecture des ordinateurs, Nicholas P. Carter, Ediscience, 2002
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
