Reconnaissance de tracés manuscrits
Par rapport à l’utilisation d’un clavier et d’une souris, l’interaction stylo présente plusieurs avantages. Ce mode d’interaction utilise un matériel moins encombrant et plus mobile qu’un ordinateur classique. Il est donc adapté aux besoins des utilisateurs éloignés de leur poste de travail ou plongés dans des milieux où les outils informatiques habituels ne sont pas utilisables. De plus, l’interaction stylo permet un dialogue bien plus naturel, intuitif et convivial entre l’utilisateur et le système informatique. En effet, le stylo électronique et la surface tactile reproduisent la métaphore du « papier-stylo », dont chacun sait se servir. Ceci facilite la prise en main des systèmes informatiques, offrant à un public très large un accès à ces technologies.
1. Des approches génériques
Différents types de matériels basés sur une interaction stylo ont émergé ces dix dernières années : certains de grande taille comme les tablettes graphiques, les ordinateurs portables de type « Tablet PC », d’autres plus petits, comme les assistants personnels numériques (PDA) ou les « smartphones ».
Les tablettes graphiques sont des périphériques que l’on branche directement sur un ordinateur de bureau au même titre que le clavier et la souris. L’utilisateur écrit sur une surface tactile avec un stylo dédié et son tracé est reproduit sur l’écran de l’ordinateur. Leur taille est très variable, allant du format A5 au format A3. Selon les modèles de tablettes graphiques, il est possible d’avoir un retour visuel, c’est-à-dire de voir le résultat des tracés directement sur la tablette. Ceci évite à l’utilisateur de partager son attention entre la surface de la tablette graphique, pour contrôler le mouvement du stylo, et l’écran de l’ordinateur, pour voir le résultat.
Les « Tablet PC » sont des ordinateurs portables munis d’un écran tactile sur lequel l’utilisateur peut interagir avec un stylo. Selon les modèles, leur taille varie entre le format A5 et le format A4. Leurs capacités sont en tous points comparables avec les ordinateurs portables standards, mis à part leur mode d’interaction. Cependant, l’interaction stylo leur confère l’avantage d’être utilisables dans de vraies situations de mobilité, c’est-à-dire debout, sans surface d’appui, sur le terrain.
Les assistants personnels numériques (PDA) sont des ordinateurs de poche, qui ont pour utilité principale la gestion d’un agenda, la prise de notes, la consultation et la rédaction de son courrier électronique lorsque l’utilisateur n’est pas à son bureau. Leur qualité d’ordinateur de poche nécessite donc qu’ils aient une taille réduite (de l’ordre de 10 à 12 cm de hauteur sur 7 à 8 cm de large).
Les smartphones (téléphones intelligents) sont des téléphones portables évolués proposant des fonctionnalités basiques d’agenda ou de consultation et rédaction de courrier électronique. Là encore, la nécessité d’un encombrement réduit et la navigation dans les menus justifient l’utilisation de l’interaction stylo.
À l’heure actuelle, la convergence entre PDA et smartphones donne naissance aux assistants personnels numériques communicants, réunissant les fonctionnalités des deux types d’appareils.
 |
 |
| Tablette graphique avec retour visuel | Tablet PC |
 |
 |
| PDA | Smartphone |
Ces différents matériels nécessitent des logiciels adaptés. L’équipe IMADOC de l’IRISA privilégie le développement d’approches génériques, pouvant être adaptées aux différentes applications.
L’équipe IMADOC existe depuis le début des années 1990. Ses thèmes de recherche concernent l’écrit et le document sous toutes leurs formes (manuscrit, imprimé, graphique, images, documents composites…) ainsi que les activités qui y sont liées. La recherche s’effectue selon quatre thèmes principaux :
- traitement d’image, vision précoce : amélioration de la qualité d’une image en vue de son analyse ;
- écriture manuscrite : étude des systèmes de reconnaissance de documents manuscrits, soit pendant leur phase de création (reconnaissance d’écriture en-ligne), soit après coup (reconnaissance d’écriture hors-ligne) ;
- structure de documents : reconnaissance de la structure de documents en vue par exemple de transformer les images de documents papier existants en documents numériques structurés ;
- interaction homme-machine : étude de nouvelles interfaces homme-machine orientées stylo.
Grâce au caractère générique des approches et à la maîtrise des axes de recherche cités ci-dessus, il est possible de faire face à des problèmes très divers. Les travaux effectués depuis près de 15 ans ont abouti à un ensemble de technologies mûres et plusieurs collaborations ont permis de valider ces technologies dans un contexte industriel.
Ainsi, depuis l’année 2000, plusieurs contrats ont été signés pour collaborer avec des entreprises ou des administrations. Ces collaborations concernent notamment :
- le traitement de documents d’archive avec les Archives et le Conseil Général des Yvelines, les Archives de la Mayenne et le Ministère de la culture ;
- la reconnaissance d’écriture manuscrite, avec des transferts technologiques avec la société PurpleLabs et France Telecom R&D ;
- les interfaces stylo avec France Telecom (étude des possibilités de modélisation automatique de contexte et son impact sur la reconnaissance), avec le centre de recherche en psychologie, cognition et communication et le centre de recherche en art, sciences humaines et communication de l’université de Rennes 2 (évaluation de l’ergonomie des interfaces orientées stylo et mise au point d’un éditeur musical orienté stylo).
Les résultats de recherche présentés ici concernent deux types de méthodes : méthodes de saisie d’écriture manuscrite et méthodes de composition de documents structurés.
Méthodes de saisie d’écriture manuscrite
Les logiciels qui utilisent le plus couramment l’interaction stylo sont les méthodes de saisie d’écriture manuscrite. En effet, ces méthodes sont indispensables pour entrer du texte sur les périphériques complètement dépourvus de clavier et de souris. Sur ce type de périphérique, deux méthodes de saisie sont en général disponibles : un clavier virtuel et une méthode de saisie d’écriture manuscrite.
Le clavier virtuel correspond à l’affichage d’un clavier à l’écran. L’utilisateur saisit des caractères en appuyant avec le stylo sur les touches virtuelles affichées. Bien qu’un utilisateur expert soit capable de saisir ainsi un grand nombre de caractères par minute, cette technique est peu adaptée aux exigences de mobilité et n’exploite pas toutes les possibilités ergonomiques offertes par l’interaction stylo.
L’interaction proposée par les méthodes de saisie d’écriture manuscrite est beaucoup plus intuitive : l’utilisateur écrit son texte dans une zone de l’écran dédiée à cette tâche. Ces méthodes se divisent à l’heure actuelle en deux grandes familles : celles basées sur une reconnaissance de caractères manuscrits isolés et celles basées sur une reconnaissance de mots cursifs liés. La première famille, la plus ancienne des deux, est principalement utilisée sur des périphériques à faible puissance de calcul et faible ressource mémoire comme les PDA ou les smartphones. La seconde famille est utilisée sur les « Tablet PC », qui disposent de ressources matérielles nettement supérieures, permettant aux systèmes de reconnaissance de mots manuscrits cursifs de fonctionner avec des temps de réponse acceptables par l’utilisateur.
Une méthode de saisie d’écriture manuscrite est architecturée autour de deux composants principaux : un système de reconnaissance des tracés manuscrits et une interface homme-machine orientée stylo. Les travaux de recherche de l’équipe IMADOC ont porté tout d’abord sur le système de reconnaissance. Elles ont abouti à la conception du système de reconnaissance de caractères manuscrits isolés RESIFCar. Ce système peut être embarqué sur des périphériques mobiles de petite taille disposant de faibles ressources de calcul et de mémoire. Afin de proposer une méthode de saisie complète pour ces périphériques, des travaux de recherche ont été menés en collaboration avec le Centre de Recherche en Psychologie, Communication et Cognition de l’Université de Rennes 2 (CRPCC) sur la conception et l’évaluation d’interfaces homme-machine adaptées à l’interaction stylo et à la contrainte de taille des écrans de ce type de matériel. Ces travaux ont abouti à la conception de l’interface orientée stylo DIGIME.
Méthodes de composition de documents structurés
Un autre pan des recherches concerne la composition de documents structurés. Ce terme désigne les documents qui possèdent une structure prédéfinie, pour lesquels il est donc possible d’énoncer des règles de structuration. Les exemples sont multiples : des partitions musicales, des diagrammes, des plans, des schémas électriques, des formules de mathématiques…
Il existe aujourd’hui de nombreux logiciels pour réaliser différents types de documents structurés à l’aide d’un clavier et d’une souris. Cependant, ces systèmes sont souvent peu intuitifs et peu naturels. Par exemple, les logiciels permettant la réalisation de partitions musicales exigent souvent de l’utilisateur qu’il choisisse d’abord à la souris dans une barre d’outils le symbole qu’il souhaite insérer, puis qu’il déplace sa souris jusqu’à la portée, et enfin qu’il clique sur l’emplacement où il souhaite déposer ce symbole. La réalisation d’un document complexe devient donc rapidement fastidieuse et demande souvent beaucoup plus de temps que sa réalisation sur une feuille de papier.
L’interaction stylo est alors une alternative pertinente pour la réalisation de tels documents, puisqu’elle permet de cumuler les avantages du papier et du crayon et les fonctionnalités de l’informatique. L’utilisateur dessine les symboles de son document directement sur la surface tactile : il compose des documents d’une manière tout à fait comparable à celle qu’il utilise avec du papier. Mais il bénéficie également des avantages de l’informatique, notamment une plus grande facilité d’édition des documents.
Plusieurs applications basées sur une interaction stylo pour la composition de documents structurés ont été développées, notamment un éditeur de partitions musicales et un éditeur de diagrammes.
Les fonctionnalités de ces différentes technologies sont détaillées dans la suite de ce document.
2. Saisie d’écriture manuscrite
La méthode de saisie d’écriture manuscrite dont le fonctionnement est détaillé ici se compose d’un système de reconnaissance de caractères isolés, baptisé RESIFCar, et d’une interface homme-machine orientée stylo, appelée DIGIME.
Le système de reconnaissance de caractères manuscrits isolés RESIFCar
RESIFCar est un système de reconnaissance d’écriture manuscrite en-ligne spécialisé pour la reconnaissance de caractères et de symboles isolés. Cette reconnaissance est dite en-ligne car elle s’appuie sur un signal possédant des informations sur la dynamique du tracé manuscrit : sens et ordre chronologique des tracés.
L’originalité du système repose sur une modélisation explicite des caractères manuscrits formalisée par des systèmes d’inférence floue (SIF). Les SIF sont formalisés dans les modèles de caractères. Ils sont ensuite exploités lors du processus de reconnaissance pour identifier le caractère. Chaque classe de caractères est modélisée intrinsèquement et automatiquement par apprentissage sur une base d’exemples. La phase d’apprentissage est réalisée avant l’embarquement du système. La base d’exemples utilisée pour cet apprentissage est composée d’échantillons de chacune des classes à modéliser.

Différentes façons de tracer le même caractère sont répertoriées.
Ces échantillons ont été saisis par de multiples scripteurs différents afin d’avoir une bonne représentation de la variabilité des styles d’écriture. Il est nécessaire pour construire un modèle de caractère de disposer au minimum d’une soixantaine d’échantillons différents. On utilise généralement en moyenne entre cent et trois cents échantillons par classe pour obtenir des modèles représentatifs.
Pour chaque classe, les connaissances modélisées sont hiérarchisées sur trois niveaux de représentation organisés selon leur robustesse.
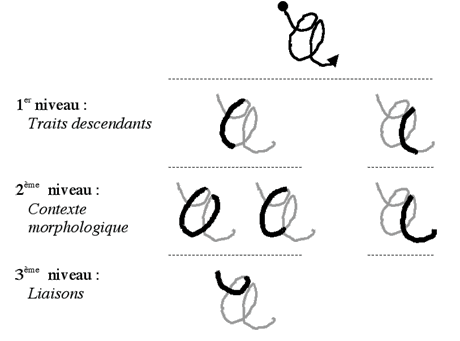
Connaissances extraites pour chacun des trois niveaux de modélisation.
Le premier niveau modélise l’ossature du caractère ; cette information très stable par rapport aux styles d’écriture est essentiellement basée sur les traits descendants du tracé. Le second niveau élargit la modélisation au contexte morphologique des traits formant l’ossature du caractère, il inclut des traits dans le prolongement de ceux du premier niveau. Le dernier niveau modélise les zones de liaison inter ou intra-caractères.
Cette structuration explicite, inspirée d’une étude approfondie de l’écriture manuscrite, a permis de mettre en œuvre une reconnaissance robuste, rapide et compacte des caractères et des symboles manuscrits. Lors de la phase de reconnaissance, le processus de décision a été optimisé en s’appuyant sur l’architecture des modèles et donc sur la robustesse des connaissances modélisées.
Ces caractéristiques font de RESIFCar un système de reconnaissance d’écriture manuscrite multi-traits et multi-styles. Il est donc modulable a priori ou a posteriori en ce qui concerne le choix du jeu de caractères ou de symboles à reconnaître. Ceci permet notamment de répondre au mieux à l’ensemble des contraintes spécifiques associées à une application embarquée : mémoire disponible, puissance du processeur, étendue des styles et des classes de symboles à reconnaître.
L’interface homme-machine orientée stylo DIGIME : un micro éditeur d’encre électronique
L’interface DIGIME permet la saisie de lettres dans un contexte de mots complets, avec un retour visuel immédiat.
Démonstration vidéo – Durée : 44 s.
Réalisation : Jonathan Dumont.
La zone d’écriture est située dans le bas de l’écran. Elle peut être cachée lorsque l’utilisateur n’a pas besoin de saisir de texte, la totalité de son écran sert alors pour afficher l’application en cours. La saisie du texte s’effectue en écrivant les lettres et symboles nécessaires dans le sens de l’écriture latine. La seule contrainte imposée à l’utilisateur est de lever son stylo de l’écran entre chaque caractère, puisque cette interface est couplée à un système de reconnaissance de caractères isolés.
Cependant, les caractères peuvent être écrits en plusieurs traits, permettant ainsi à l’utilisateur de conserver son style d’écriture. Cette possibilité est indispensable pour ne pas contraindre l’écriture de certains caractères comme le « i », le « t » ou encore le « x ». Il est de ce fait nécessaire de segmenter les différents tracés, c’est-à-dire de retrouver quels sont les tracés qui composent un même caractère. La segmentation automatique est basée sur le repérage de chaque poser et lever de crayon ainsi que sur la position spatiale des tracés les uns par rapport aux autres.
Une fois qu’un groupe de tracés a été identifié comme composant un même caractère, il est envoyé au système RESIFCar qui retourne en réponse le caractère reconnu. Si le caractère est identifié comme pouvant être incomplet, c’est-à-dire que le groupe de tracés a été identifié comme le début d’un caractère, les tracés restent affichés sous forme d’encre électronique. En revanche, si un groupe de tracés est identifié comme un caractère définitif, il est remplacé dans la zone de saisie par le caractère d’imprimerie qui correspond à la réponse de RESIFCar.
Comme la saisie et l’affichage du caractère reconnu s’effectuent dans la même zone de l’écran, l’utilisateur peut continuer sa saisie sans s’interrompre pour vérifier que ses tracés ont été correctement reconnus.

Saisie de plusieurs caractères consécutifs.
Réalisation : Jonathan Dumont.
Les accents sont tracés soit sur l’encre électronique si elle est encore affichée, soit directement sur les caractères d’imprimerie.

Saisie d’accents.
Réalisation : Jonathan Dumont.
Pour compenser la taille réduite de la zone de saisie, l’éditeur est doté d’un mécanisme de défilement automatique, une fenêtre glissante : la zone de saisie est donc considérée comme une feuille de papier virtuelle. Ce défilement est automatiquement déclenché lorsque l’utilisateur termine un tracé près du bord droit de la zone de saisie. Il peut naviguer dans le contenu de la feuille de papier virtuelle à l’aide de boutons de navigation, afin de revoir ce qu’il a saisi et d’y appliquer des commandes d’édition.
Mais pour éviter l’utilisation de menus et de boutons, un ensemble de commandes d’édition est disponible au travers de gestes graphiques effectués directement sur l’encre électronique ou sur les caractères d’imprimerie.

Suppression et remplacement de caractères.
Réalisation : Jonathan Dumont.
Ainsi, il est possible de supprimer un ou plusieurs caractères en les rayant d’un trait de la droite vers la gauche, d’insérer un espace entre deux caractères, de changer la casse d’un caractère, ou de remplacer un caractère en écrivant directement sur celui-ci le caractère de remplacement.
3. Composition de documents structurés
Deux applications illustrant la composition de documents structurés mettent en évidence le problème principal rencontré : reconnaître des tracés à la volée, et la solution générique proposée pour y remédier.
Éditeur de partitions musicales
Ce prototype d’éditeur de partitions musicales permet à un utilisateur de dessiner des symboles musicaux directement sur l’écran tactile et de les modifier de façon tout aussi naturelle.
Le principe est de reconnaître les tracés de l’utilisateur directement pendant la réalisation du document : chaque tracé est remplacé par le symbole musical reconnu correspondant. L’utilisateur visualise immédiatement l’interprétation par le système du document qu’il est en train de composer. On parle alors d’interprétation à la volée.
L’utilisateur peut dessiner les symboles musicaux majeurs, comme les clés, les têtes de notes, les hampes, les croches, les altérations, les silences, les points de prolongement, les barres de mesure, etc.
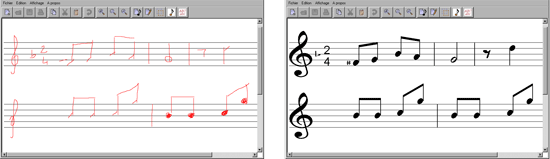
Éditeur de partitions musicales.
À gauche les tracés manuscrits, à droite le document reconnu. Notez qu’en réalité, les tracés manuscrits sont remplacés au fur et à mesure par les symboles musicaux leur correspondant.
Réalisation : Jonathan Dumont.
L’interaction stylo propose également des solutions d’édition plus simples et plus intuitives que celles basées sur l’utilisation d’un clavier et d’une souris. Par exemple, le logiciel permet de sélectionner un ou plusieurs éléments en vue de les déplacer. Un élément déplacé à l’extérieur de la fenêtre de l’application est supprimé du document.
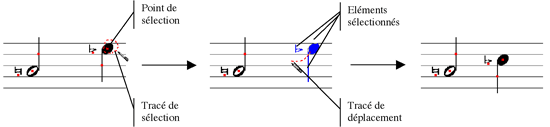
Mécanismes de sélection et de déplacement d’éléments d’une partition.
À gauche, l’utilisateur entoure le point de sélection d’une noire ; au milieu, cette noire est sélectionnée, avec les éléments qui lui sont associés, et l’utilisateur dessine un tracé pour les déplacer ; enfin à droite, l’utilisateur lève le stylo : les éléments sont placés à l’emplacement correspondant.
Éditeur de diagrammes
Dessiner des rectangles et des connexions entre ces rectangles : c’est le principe de l’éditeur de diagrammes. Il est également possible d’écrire des informations à l’intérieur de chacun des rectangles. Comme pour l’éditeur de partitions musicales, les tracés manuscrits sont remplacés par le symbole correspondant au fur et à mesure de la composition du document. De plus, les fonctions d’édition sont les mêmes dans ces deux logiciels.
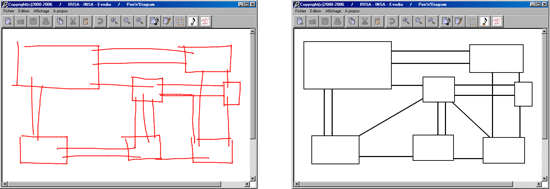
Éditeur de diagrammes.
À gauche les tracés manuscrits, à droite le document reconnu.
Réalisation : Jonathan Dumont.
Cet éditeur de diagrammes présente l’avantage de pouvoir être facilement adapté à différents types de diagrammes, tels que des arbres généalogiques, des organigrammes, des diagrammes UML, etc. Il a ainsi été adapté pour la réalisation de schémas électriques. Des études expérimentales ont mis en évidence un gain de temps de l’ordre de 40 % lors de l’utilisation d’un tel éditeur orienté stylo en comparaison d’un éditeur basé sur des boutons.
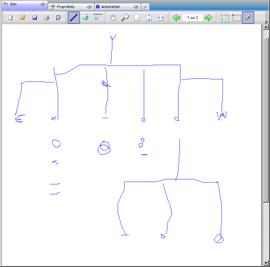 |
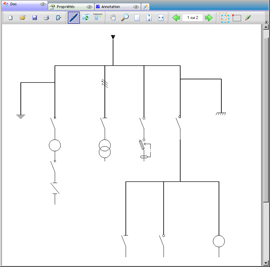 |
| Éditeur de schémas électriques. À gauche les tracés manuscrits, à droite le document reconnu. |
|
Réalisation : Jonathan Dumont.
Reconnaître des tracés à la volée : un problème difficile
L’interprétation à la volée des tracés manuscrits d’un document structuré est un problème complexe de reconnaissance de formes, et ce pour différentes raisons. Tout d’abord, un document structuré est constitué de symboles de nature différente. Par exemple, dans l’éditeur de partitions musicales, il est possible de dessiner des clés, des têtes de notes, des hampes, des altérations, des chiffres, du texte, etc. Du fait de la quantité importante de ces symboles, il est très difficile de réaliser un reconnaisseur unique capable d’identifier sans erreur un tracé. De plus, certains de ces symboles ont la même forme, comme par exemple la lettre « b » et le bémol d’une part, et la lettre « o », le chiffre « 0 » ou la tête de note ronde ou blanche d’autre part. Il est alors nécessaire de prendre en compte un certain nombre d’informations concernant la nature du document analysé, afin de choisir l’un de ces symboles. Un second problème vient de l’analyse à la volée des tracés manuscrits. Comme il faut afficher l’interprétation des tracés au fur et à mesure de leur réalisation, il est parfois nécessaire de prendre une décision malgré le manque d’information. Par exemple, il faut décider si un tracé donné correspond à un symbole ou bien au premier tracé d’un symbole, dont le dessin sera continué à l’aide d’autre tracés. Un nouvelle fois, il est nécessaire de prendre en compte la nature du document structuré analysé, et d’exploiter des informations les concernant afin de prendre une décision cohérente.
Les solutions proposées pour reconnaître à la volée des tracés de documents structurés sont basées sur deux principes majeurs : il faut prendre en compte, d’une part, la nature du document analysé, afin de reconnaître ses éléments et, d’autre part, le contexte dans lequel un tracé a été réalisé, qui aide à le reconnaître.
Trois composants indépendants
L’équipe IMADOC cherche à définir une approche générique pour le développement de telles applications, c’est-à-dire une méthode qui pourrait s’appliquer à tous les types de documents structurés. L’approche proposée est basée sur un système formé de trois composants principaux qui sont indépendants et peuvent donc être modifiés sans avoir à modifier les autres.
Tout d’abord, un ensemble de fonctions graphiques permet l’affichage des différents éléments du document (il exploite des informations graphiques, qui sont par exemple des images des symboles reconnus du document), et un ensemble de fonctions d’édition permet la modification de ces éléments par l’utilisateur (par exemple leur sélection, leur déplacement ou leur suppression, comme présenté précédemment pour les éditeurs de partitions musicales et de diagrammes).
Comme le processus d’analyse des tracés manuscrits se fait à la volée, à chaque fois que l’utilisateur dessine un tracé, celui-ci est analysé par le second composant, dont le but est de comprendre de quel symbole il s’agit. Cet analyseur exploite des connaissances concernant la nature du document en cours de réalisation afin de déterminer sa signification.
Ces informations sont représentées sous la forme de règles d’interprétation, à l’aide d’un langage spécifique. Ces règles consituent le troisième composant du système. Elles modélisent tout d’abord une vision globale du document, afin de déterminer dans quel contexte spatial un tracé a été dessiné. Il est ensuite possible, en fonction de ce contexte, d’avoir une vision locale de l’élément à reconnaître, et donc d’en analyser la forme. Ainsi, ces règles d’interprétation modélisent le pilotage de systèmes de reconnaissance dédiés à des sous-familles de symboles du document. Le but est de modéliser par exemple que dans une partition musicale, un cercle réalisé sur une partition a de plus fortes probabilités d’être une tête de note qu’un chiffre ou une lettre, ou bien qu’un tracé ressemblant à fois à un bémol et à la lettre « b » a de plus fortes chances d’être un bémol s’il se situe à gauche d’une tête de note. Pour finir, ces règles d’interprétation permettent également de modéliser si un symbole peut être dessiné à l’aide de plusieurs tracés manuscrits.
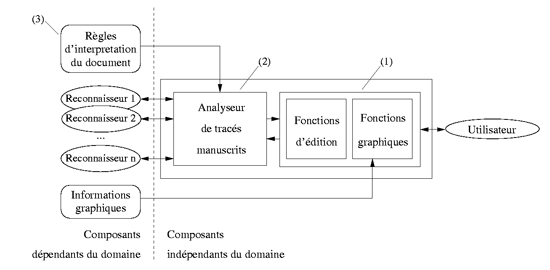
Architecture du système développé.
Un des avantages de ce système est sa généricité, qui facilite le développement d’éditeurs de documents structurés basés sur une interaction stylo. En effet, les fonctions graphiques, les fonctions d’édition et l’analyseur de tracés manuscrits sont des composants indépendants de la nature du document analysé, et ne nécessitent pas d’être recodés pour chaque nouveau logiciel. Par conséquent, le développement d’un tel système ne nécessite que la réalisation des composants dépendant du domaine, c’est-à-dire la description du document analysé à l’aide de règles d’interprétations, les reconnaisseurs des familles de symboles contenus dans le document, et enfin les informations graphiques, correspondant par exemple aux images des symboles reconnus du document.
Toutes les technologies présentées ici, issues de nombreuses années de recherche, ont été validées dans un contexte industriel. Elles sont à présent suffisamment évoluées pour envisager leur valorisation et leur industrialisation. C’est dans ce but qu’a été récemment créée la société Evodia.
Face à l’accroissement des possibilités de transferts industriels, des chercheurs de l’équipe IMADOC ont décidé de créer une entreprise en 2005 : la société Evodia. Cette société est spécialisée dans le développement de logiciels innovants pour la composition, l’analyse et l’accès aux documents manuscrits. Elle a pour mission la valorisation et l’industrialisation des travaux de recherche de l’équipe IMADOC.
Lauréate en 2005 et 2006 du Concours d’aide à la création d’entreprises innovantes du Ministère de la Recherche, l’entreprise bénéficie de conseils dans les domaines juridiques, comptables et stratégiques. Elle est composée aujourd’hui de quatre personnes épaulées par quatre permanents de l’équipe IMADOC.
- E. Anquetil, Modélisation et reconnaissance par la logique floue : application à la lecture automatique en-ligne de l’écriture manuscrite omni-scripteur, Thèse de l’université de Rennes 1, Janvier 1997.
- E. Anquetil, H. Bouchereau, Integration of an On-line Handwriting Recognition System in a Smart Phone Device, in Proceedings of the 16th IAPR International Conference on Pattern Recognition (ICPR 2002), Pages 192-195, 2002.
- Eric Anquetil, François Bouteruche, Conception d’un micro éditeur d’encre électronique et embarquement d’un système de reconnaissance d’écriture manuscrite sur téléphone mobile, in Conférence Francophone : Mobilité & Ubiquité’04, Pages 151-157, 2004.
- François Bouteruche, Guillaume Deconde, Eric Anquetil, Eric Jamet, Design and evaluation of handwriting input interfaces for small-size mobile devices, in Proceedings of the 1st Workshop on Improving and Assessing Pen-Based Input Techniques, Pages 49-56, 2005, téléchargeable en PDF (300 Ko).
- Sébastien Macé, Eric Anquetil, A Generic Approach for Eager Interpretation of On-line Handwritten Structured Documents, in Proceedings of the International Conference on Pattern Recognition (ICPR’06), Pages 1106-1109, 2006.
- Sébastien Macé, Eric Anquetil, Design of a Pen-Based Electric Diagram Editor Based on Context-Driven Constraint Multiset Grammars, in Proceedings of the International Conference on Human-Computer Interfaces (HCII’07), 2007, à paraître.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
