

sous licence Creative Commons
Reconnaître les noms binomiaux des espèces biologiques dans un corpus ancien
Malheureusement, les scans de ces collections sont parfois des supports de piètre qualité. Cela peut tenir à une définition trop faible, qui permet tout juste la lecture, à une indexation trop rudimentaire, qui ne permet pas de s’y retrouver dans la collection. La distance temporelle, l’hétérogénéité des sujets traités et des façons de les traiter sont aussi des difficultés.
De plus, même si l’indexation avait été bien faite, elle l’aurait été pour l’intention première, pas pour les analyses indirectes qu’on peut vouloir conduire a posteriori. Par exemple, les sciences de la nature ont beaucoup bénéficié de la constitution des empires coloniaux. On peut même y lire une histoire de la colonisation en creux, alors que ce n’était évidemment pas l’objectif initial des publications naturalistes. L’exploitation de ces collections à des fins pour lesquelles elles n’ont pas été prévues demande donc un travail d’analyse qui doit chercher d’autres indices que les classifications a priori de l’époque de la publication.
C’est ce que nous montrons ici sur un tout petit exemple, celui de l’identification de termes de la nomenclature scientifique des espèces biologiques dans les archives des presque 100 ans de publication de la revue La Nature.
Contexte
Le corpus ancien

Figure 1 : Frontispice d’un numéro de la revue La Nature.
La Nature est une revue hebdomadaire de vulgarisation scientifique fondée par le scientifique Gaston Tissandier en 1873 et qui a paru sous ce nom jusqu’en 1960. Les sujets traités appartiennent essentiellement au domaine des sciences naturelles (géologie, botanique, etc.), des sciences humaines et sociales (ethnologie, médecine, etc.), ou des technologies (appareillage scientifique, transports, etc.). On y trouve aussi des résumés de communications à l’Académie des sciences ou dans d’autres revues. Elle présente des articles de fond, par exemple sur la formation des orages, et des articles plus anecdotiques, par exemple le récit d’un orage particulièrement spectaculaire.
La période de publication de La Nature contient l’essentiel du développement de plusieurs champs de la science et de la technologie moderne, ainsi que des pans entiers de l’histoire politique et sociale du monde (la colonisation, les deux guerres mondiales, la décolonisation, la crise du phylloxéra dans les vignobles…). À ses débuts, ni la génétique — et donc la théorie moderne de l’évolution, ni la tectonique des plaques — et donc l’appréciation des changements qui animent notre planète, ni la physique moderne ne sont connues. De même, l’électromagnétisme n’est encore qu’un phénomène de laboratoire, et il n’est pas question de distribuer de l’électricité à grande échelle. L’exploitation du pétrole et ses applications n’en sont qu’à leur début, et le poids du charbon dans la fourniture d’énergie vient juste de dépasser celui de la biomasse. La santé publique en est à ses débuts, et l’Institut Pasteur n’a pas encore été créé. La géographie du globe n’est pas encore bien connue, et par exemple, l’exploration des Pôles, tout juste balbutiante, est largement fondée sur l’hypothèse fausse d’une mer libre au-delà de la banquise. Ce ne sont que des exemples en vrac, mais ils montrent combien il est important de pouvoir consulter ces archives pour quiconque veut observer cette dynamique.

Figure 2 : Frontispice d’un volume des archives de la revue La Nature.
Les archives de La Nature forment un corpus de plus de 150 volumes et plus de 80 000 pages au total. Elles contiennent à peu près 1 article par page, mais dans une distribution bimodale : environ 50 % d’articles courts (une dizaine de lignes) et 50 % d’articles longs (environ 5-10 pages). Il n’est pas facile d’accéder à des collections papier complètes, et même quand une telle collection est disponible, cela représente plus de 6 mètres de rayonnage, et il n’est pas faisable de la lire en entier, ou même de la balayer à la recherche des réponses à une question, puis à une autre question, etc. Des scans de ces archives ont été réalisés par le Conservatoire numérique des Arts et Métiers (Cnum), et sont disponibles sur le Web, mais ils sont de mauvaise qualité. D’autres dépôts existent, comme Google Books et HathiTrust, mais ils sont moins bien administrés que celui du Cnum, et semblent surtout n’en être qu’une copie partielle. Notre objectif est de rendre accessibles les archives numériques de La Nature en réalisant l’enrichissement sémantique qui permet de naviguer arbitrairement dans la collection en allant au-delà de la structure originelle. Par exemple, la biodiversité n’est pas un sujet explicite de La Nature, mais on souhaiterait pouvoir l’explorer sous cet angle en y cherchant des indices indirects.
L’enrichissement sémantique a pour objectif de retrouver dans un texte brut les éléments d’information qu’un lecteur compétent identifierait sans y penser mais qui ne sont pas formellement représentés. Une des tâches de l’enrichissement sémantique est donc de retrouver, dans le texte, les mentions de certaines entités dites nommées comme par exemple les personnes (Carl Von Linné) ou les localisations géographiques (Berlin). Plus généralement, les entités nommées sont des entités qui ont une existence en dehors du texte. Elles font partie du référentiel du lecteur ou de l’époque.
Parcourir à la main toutes les données est une tâche titanesque, c’est la raison pour laquelle on cherche à l’automatiser. La tâche consistant à retrouver automatiquement dans du texte toutes les mentions d’éléments d’une certaine classe se nomme l’extraction d’entités nommées. Elle est réalisée grâce à un outil automatique appelé classifieur. Dans le travail présenté ici, nous nous intéressons à la création d’un classifieur pour la reconnaissance de noms de la classification binomiale du vivant, ou taxons, c’est-à-dire les noms scientifiques des espèces biologiques.
La classification binomiale du vivant
Un exemple très connu de nom issu de la classification binomiale du vivant est Homo sapiens pour l’espèce humaine. Les noms de la classification binomiale obéissent à certaines règles qui se sont consolidées au cours du temps. Un résumé simplifié de cet ensemble de conventions peut être le suivant :
- Les noms de la classification binomiale sont écrits en italique.
- Ils sont composés de deux parties. La première désigne un genre, et est écrite avec une majuscule. La seconde, appelée épithète, désigne une espèce au sein de ce genre, et est écrite avec une minuscule. Un même épithète peut apparaître derrière des noms de genre différents et chaque nom de genre peut être associé à un nombre arbitraire d’épithètes (de 1 à vraiment beaucoup).
- On peut ajouter la mention abrégée du découvreur d’une espèce à la suite de l’épithète. Par exemple Bombyx neustria Linn est composé du nom de genre Bombyx, de l’épithète neustria suivi du nom du découvreur, ici Linné qui a systématisé cette nomenclature.
- Les taxons doivent être écrits en « latin » avec un accord en genre (grammatical, pour le latin on a le masculin, le féminin et le neutre) de l’épithète avec le nom de genre (biologique). Toutefois, c’est surtout une teinte de latin, ainsi il existe le palmier Washingtonia robusta dont le nom de genre a été donné en l’honneur du premier président des États-Unis.
- Grammaticalement, les binômes genre-épithète peuvent se décliner en nominatif-adjectif (Helleborus niger, hellébore noire, ou rose de Noël), nominatif-nominatif (Panthera leo, le lion) et nominatif-génitif (Trachycarpus fortunei, en l’honneur du botaniste Robert Fortune).
- Le nom de genre d’un taxon peut être abrégé (ex. H. niger) à condition que ce nom de genre ait été présenté en entier à proximité de l’occurrence abrégée.
En réalité, les choses sont beaucoup plus complexes. Par exemple, des règles différentes s’appliquent en botanique, en zoologie, en virologie ou pour les plantes cultivées, et elles sont régulièrement mises à jour. Ce résumé simplifié laisse penser que détecter les noms binomiaux est assez simple, mais c’est sans compter avec les caractéristiques du corpus étudié.
Difficultés rencontrées

Figure 3 : Fragment d’un article de la revue La Nature.
Le format des données sur lesquelles nous travaillons pose plusieurs problèmes :
- Les archives de La Nature sont accessibles sous forme de scans d’assez mauvaise qualité qui doivent être océrisés (c’est-à-dire soumis à une procédure d’OCR, optical character recognition, qui va extraire le texte des scans) avant tout traitement. Cela induit deux principales difficultés. Premièrement, la mise en forme du texte a disparu, en particulier les italiques, qui sont pourtant un indice très fort d’un nom scientifique d’espèce. Deuxièmement, il y a un très grand nombre d’erreurs d’océrisation avec des mots coupés par un espace, des « t » transformés en « l », des « m » en « rn », etc.
- Les conventions de la nomenclature binominale ne sont pas respectées dans tous les articles. Par exemple, on ne peut pas exclure qu’un nom de genre commence par une minuscule ou qu’un épithète commence par une majuscule. L’exemple de la figure 4 ci-dessous montre un nom, « Chamaerops humilis » qui respecte les conventions modernes, et un autre, « Hyphœne thebaïca » qui cumule les anomalies : une ligature, un tréma, et aujourd’hui on dit Hyphaene.
- Enfin, la nomenclature binomiale évolue avec le progrès des connaissances. Par exemple, certaines espèces du genre Trachycarpus ont d’abord été classées dans le genre Chamaerops. Ces mouvements taxinomiques sont très fréquents, et parfois de très grande ampleur.

Figure 4 : Exemple d’occurrences de noms binomiaux.
Les règles encadrant la formation des noms binomiaux, ainsi que toutes les anomalies qui s’y rapportent guident le choix des approches qui peuvent être employées.
Méthodes employées
Plusieurs approches sont possibles en général pour réaliser un classifieur d’entités nommées. L’approche par apprentissage neuronal est aujourd’hui la plus souvent étudiée. Elle consiste à présenter à un réseau de neurones des exemples et des contre-exemples des formes recherchées, mais elle nécessite d’avoir une grande quantité de données annotées, ce dont nous ne disposons pas. De plus, nous nous sommes fixés un objectif de sobriété numérique qu’on peut expliquer de la manière suivante. Au-delà de l’enrichissement sémantique de la revue LA NATURE, nous souhaitons à terme proposer une plateforme d’enrichissement d’archives à des utilisateurs non informaticiens, et peu dotés en moyens informatiques. Ceux-ci devraient pouvoir choisir leurs archives et leurs domaines d’enrichissement, et exécuter le tout sur leur ordinateur.
D’autres approches moins étudiées maintenant restent applicables. On les appelle collectivement des approches symboliques. L’approche par dictionnaire consiste à utiliser un référentiel en plus du corpus. Le référentiel consiste en une liste de dénominations d’entités. Elle marche bien pour des corpus modernes, mais elle est mal adaptée au corpus de La Nature à cause de la présence de nombreuses erreurs dans le texte et du fait que les noms de la classification actuelle sont souvent différents de ceux qui étaient utilisés il y a 100 ans. Cependant, nous l’explorerons quand même, ne serait-ce que pour savoir à quel point elle est mal adaptée.
Une autre approche consiste à repérer des mots déclencheurs (trigger words) dont on sait qu’ils introduisent souvent des noms de la classe d’entités recherchées. Cependant, on observe que les mots « genre » et « espèce », qui devraient être des déclencheurs, ont trop d’autres usages qui n’ont rien à voir. Nous avons même pu montrer que la distribution de ces mots est statistiquement indépendante de celle des occurrences de taxons.
Nous avons aussi essayé une approche par motif, c’est-à-dire, qui consiste à décrire des règles morphologiques permettant de reconnaître des dénominations d’entités. Les taxons obéissent bien à des règles morphologiques (voir plus haut), et nous tenterons donc cette approche.
Aux deux approches retenues, par dictionnaire et par motif, nous apporterons des variations, par exemple un critère fréquentiel que nous expliquerons plus loin. En effet, une approche opérationnelle est rarement la mise en œuvre d’une seule approche théorique, et encore moins la mise en œuvre littérale des approches théoriques. Le contexte opérationnel vient toujours apporter son grain de sel.
Approche par dictionnaire
Des naturalistes ont publié des référentiels taxinomiques qui contiennent en général plus que des noms binomiaux. Le plus souvent ils contiennent aussi des noms vernaculaires des espèces (ex. cocotier pour Cocos nucifera) dans une ou plusieurs langues, et leur position dans la taxonomie linnéenne (ex. bovidé=>artiodactyle=>mammifère=>vertébré=>chordés=>animal pour Bison bison, le bison d’Amérique du Nord). En particulier, le Muséum national d’histoire naturelle (MNHN) publie et maintient à jour le référentiel taxonomique pour la France : TAXREF. Le Catalogue of Life fait de même au niveau mondial.
L’approche par dictionnaire consiste alors à rechercher dans le texte des occurrences de noms binomiaux qui appartiennent au dictionnaire. Appelons ce classifieur « TAXREF strict » puisqu’il s’appuie sur le référentiel du MNHN sans aménagement aucun (avant de proposer plus loin un classifieur « TAXREF abstrait »). La même approche permettrait de retrouver des occurrences de noms vernaculaires, mais avec une difficulté supplémentaire. Les noms binomiaux ne s’emploient que littéralement, alors que les noms vernaculaires se déclinent parfois en genre (ex. un chat, une chatte, mais aussi un cheval, une jument) ou en nombre (ex. un chat, des chats, mais aussi un cheval, des chevaux), sans parler des noms dérivés (ex. palmeraie, porcherie, thonier).
Approche par motif
Les motifs recherchés sont par exemple le fait que le premier mot commence par une majuscule et que le second n’en comporte pas. Ce critère n’est à lui seul pas suffisant car il représente trop de situations n’ayant rien à voir avec les noms binomiaux. En effet, presque tous les débuts de phrases valident ce critère, ainsi que beaucoup de mentions de noms propres. En plus, il exclut un très grand nombre de taxons légitimes, mais qui ne respectent pas ce critère. Un autre critère que nous avons utilisé est le fait que les mots doivent s’apparenter à du latin. Nous vérifions ce critère en regardant la fin de chaque mot du groupe pour voir si elle correspond à une terminaison latine et si la terminaison suivante est bien accordée. Ce critère est aussi trop large, car il y a de nombreuses terminaisons d’apparence latine qui sont très courantes en français comme le fait de terminer par un ‘a’ (ex. Messi buta) ou un ‘e’ (ex. Zidane tire). Enfin, le troisième critère que nous avons utilisé est le fait que le groupe de mots se situe devant le nom d’un biologiste célèbre. En effet, les noms binomiaux sont parfois suivis du nom du découvreur. C’est le seul usage que nous faisons de l’approche par mot déclencheur. Nous appellerons ce classifieur LATIN.
Expérimentations
Afin de tester l’efficacité d’un classifieur, quelle que soit sa nature (test PCR, test logiciel, réactif chimique, etc.), nous avons besoin de comparer les résultats produits par le classifieur à des résultats attendus. On mesure la qualité des résultats en termes de précision et de rappel. Sans entrer dans les détails (voir l’encart « Évaluation d’un classifieur ci-dessous), ces indicateurs mesurent les éléments suivants :
- la précision mesure à quel point ce qui est classifié comme taxon est bien un taxon,
- le rappel mesure à quel point ce qui est un taxon est bien classifié comme tel. Les deux sont présentés par des pourcentages.
Il est très facile d’avoir une bonne précision (ex. ne reconnaître que des taxons qu’on aurait repérés en feuilletant les archives) ou un bon rappel (ex. prétendre que tout est taxon) ; c’est avoir les deux qui est difficile. La f-mesure combine précision et rappel dans une sorte de moyenne qui pénalise les grands écarts. Une f-mesure de 80 % est jugée bonne, mais il est reconnu que ça dépend beaucoup de la tâche à réaliser. Nous reviendrons sur ce point dans la conclusion.
Il est fréquent de disposer d’un classifieur lent, coûteux, intrusif, destructif, mais de très grande qualité (ex. une autopsie ou l’examen par un expert très pointu ou attendre que quelque chose se produise dans un certain délai), et de voir se présenter un nouveau classifieur rapide, bon marché, non-intrusif ou non-destructif. Faut-il adopter le nouveau classifieur ? Il faut d’abord en évaluer la qualité de la classification, et éventuellement pondérer par la vitesse, le coût, etc. On ne s’intéresse ici qu’à la qualité seule.
Afin de tester la qualité du nouveau classifieur, quelle que soit sa nature (test PCR, test logiciel, réactif chimique, etc.), nous avons besoin de comparer ses résultats à des résultats attendus. On se dote pour ce faire d’une population test pour laquelle la propriété recherchée a pu être établie par d’autres moyens que le moyen évalué, par exemple l’ancien classifieur.
Dans ces conditions, on mesure la qualité du résultat en termes de précision, de rappel et de f-mesure, et parfois aussi d’exactitude. Expliquons ces termes.
|
MATRICE DE CONFUSION |
Le classifieur voit la propriété recherchée |
Le classifieur ne voit pas la propriété recherchée |
|
La réalité a la propriété recherchée |
vrais positifs (VP) |
faux négatifs (FN) |
|
La réalité n’a pas la propriété recherchée |
faux positifs (FP) |
vrais négatifs (VN) |
Le modèle qui les explique ensemble s’appelle la matrice de confusion. Il s’agit d’un tableau à 2 lignes et 2 colonnes, donc 4 cases. Imaginons une tâche de reconnaissance d’une certaine propriété. Les lignes représentent alors Avoir ou Ne pas avoir la propriété (de haut en bas), et les colonnes Avoir détecté ou Ne pas avoir détecté la propriété (de gauche à droite). Les 4 cases représentent donc les 4 combinaisons d’avoir la propriété ou non, et de l’avoir détectée ou non. Ces quatre cases ont les noms conventionnels suivants :
- Vrais positifs (en haut à gauche) ou VP : on y note le nombre de fois où la propriété était avérée et où elle a été détectée ;
- Vrais négatifs (en bas à droite) ou VN : on y note le nombre de fois où la propriété était fausse et où elle n’a pas été détectée ;
- Faux positifs (en bas à gauche) ou FP : on y note le nombre de fois où la propriété était fausse mais où elle a été détectée ; VN + FP représente tous les cas où la propriété est vraiment fausse ;
- Faux négatifs (en haut à droite) ou FN : on y note le nombre de fois où la propriété était avérée mais où elle n’a pas été détectée ; VP + FN représente tous les cas où la propriété est avérée.
La somme des cases « vrais X » mesure donc le nombre de fois où la détection s’est bien passée, et la somme des cases « faux X » le nombre de fois où elle s’est mal passée. Les indicateurs de qualité s’expriment en fonction de la matrice de confusion de la façon suivante :
- Précision = VP / (VP + FP) : c’est-à-dire la proportion de reconnaissances correctes sur le total des reconnaissances ;
- Rappel = VP / (VP + FN) : c’est-à-dire la proportion de situations correctement reconnues sur les situations à reconnaître ;
- Exactitude = (VP + VN) / (VP + FN + VN + FP) : c’est-à-dire la proportion de bonnes décisions.
Tous ces indicateurs prennent des valeurs entre 0 et 1, mais on les exprime souvent en pourcentage de 1.
La précision et le rappel sont antagonistes, car faire croître l’un fait souvent décroître l’autre. On pondère précision et rappel dans la f-mesure qui est une sorte de moyenne qui pénalise les excès d’un côté ou de l’autre. La f-mesure est la moyenne harmonique (ni moyenne arithmétique usuelle, ni moyenne géométrique, encore une autre !) de la précision et du rappel : 2 x Précision x Rappel / (Précision + Rappel). C’est en fait l’inverse de la moyenne arithmétique des inverses. Cette moyenne est plus sensible aux grands écarts que la moyenne arithmétique classique. Par exemple, la moyenne arithmétique de 0 et 10 est 5, mais la moyenne harmonique de ces nombres donne 0. Ainsi, si le rappel ou la précision est faible alors, même si l’autre est très élevée, leur moyenne harmonique sera plus faible que leur moyenne arithmétique. Une f-mesure de 80 % est considérée comme indiquant une bonne qualité du classifieur, mais il est reconnu que c’est très dépendant de la tâche.
On devrait éviter d’utiliser l’exactitude quand la quantité d’occurrences à reconnaître est très petite vis-à-vis du nombre total d’occurrences. En effet, VP et FN deviennent mécaniquement très petits et on ne mesure plus qu’une sorte d’anti-rappel, borné par VN / (VN + FP + epsilon) et (VN + epsilon) / (VN + FP + epsilon). Par exemple, si une propriété ne se présente qu’une fois sur cent, ne jamais la reconnaître se traduit par un rappel de 0 (donc une f-mesure de 0 aussi), mais une exactitude de 99 %. Observons enfin que tout cela suppose qu’il existe bien des vrais positifs dans l’échantillon de test !
Évaluation par rapport à des annotions préalables
Pour évaluer nos propositions, nous avons manuellement annoté quatre volumes de La Nature (environ 2200 pages au total), en y répertoriant tous les noms binomiaux, y compris ceux qui ne respectent pas strictement les règles de la nomenclature binominale ou qui ont été incorrectement océrisés (671 occurrences, dans 182 articles, sur plus de 2000 articles). Nous avons choisi ces quatre volumes espacés dans le temps afin d’éviter les artefacts d’évaluation : 1879, 1912, 1934 et 1960.
| Précision (%) | Rappel (%) | F-mesure (%) | |
| TAXREF strict sans abréviation | 100 | 33.8 | 50.6 |
| TAXREF strict avec abréviation | 100 | 37.1 | 54.1 |
TABLE 1 : Performances de TAXREF strict avec et sans reconnaissance des binômes abrégés. |
|||
Sans surprise, le classifieur TAXREF strict donne une précision de 100 %. Par contre, le rappel est seulement de 30 à 40 %, selon qu’on ignore les abréviations ou non. Ce n’est pas une surprise non plus puisqu’on sait que la classification du vivant change tout le temps et que le corpus est bruité. L’annotation signale un nom binomial partout où un lecteur compétent en verrait un, même s’il est obsolète (la taxonomie a changé), mal composé (ex. des majuscules là où il ne faudrait pas), ou mal océrisé (ex. Wus pour Mus, le genre de la souris). Ce rappel de 30 à 40 % n’est que la mesure en creux du poids de ces anomalies. 100 % de précision et moins de 40 % de rappel : est-ce un bon compromis ? La f-mesure d’environ 50 % laisse penser qu’on pourrait faire mieux.
On peut imaginer une variante de cette approche dans laquelle le dictionnaire ne sert pas de référentiel des noms binomiaux autorisés, mais juste de référentiel des paires de terminaisons autorisées. Cette variante est donc une approche par motif inspirée des régularités d’un dictionnaire. Par exemple, du binôme Chamaerops humulis on ne retiendrait que les terminaisons : rops-ulis ou ops-lis ou ps-is ou s-s. On appellera cette approche « TAXREF abstrait ». L’intérêt de cette approche est qu’elle apprend du dictionnaire l’air latin qu’ont tous les noms binomiaux, mais qu’elle ne se limite pas aux mots effectivement contenus dans le dictionnaire. En particulier, cette approche permet de s’affranchir des erreurs d’océrisation. Par exemple, Zosterops laleralis est reconnu à partir des terminaisons ops-lis alors que ce binôme est le résultat d’une erreur d’océrisation, laleralis pour lateralis, et ne figure pas tel quel dans le référentiel. Et ça marche aussi pour des erreurs plus brutales comme des mots coupés.
Appelons « rang » la longueur des terminaisons retenues. On observe que pour des rangs ≥ 4, la qualité de reconnaissance est similaire à celle de TAXREF strict : presque 100 % de précision et 30 à 50 % de rappel. Pour des rangs ≤ 2, la précision s’effondre et le rappel grimpe en flèche. Malheureusement, la f-mesure chute aussi. On observe que le rang = 3 est un point de bascule qui donne une précision de 32 % et un rappel de 62 %, pour une f-mesure de 42 %.
Comment se comporte LATIN ? Il donne un assez bon rappel, presque 70 %, mais une précision très mauvaise, à peine plus de 20 %, pour une f-mesure d’à peine plus de 30 % ; c’est-à-dire pas très différents de TAXREF abstrait. Mais une observation simple permet d’envisager une amélioration.
Améliorer les classifieurs en se basant sur la fréquence d’apparition des binômes
Utilisés naïvement, les critères de l’approche par motif (LATIN ou TAXREF abstrait) sont très peu discriminants à eux seuls. En effet, ils engendrent de très nombreux « faux positifs » ; c’est-à-dire des signalements de noms binomiaux qui n’en sont pas. Cependant, on peut observer que les noms « latins » de genre et d’espèces sont des mots plutôt rares dans la distribution statistique de tous les mots du corpus. Ça se voyait par exemple dans l’annotation à la main de 4 volumes : seulement 671 occurrences positives sur des millions d’occurrences. On peut alors penser que si on n’applique le classifieur LATIN qu’à des mots suffisamment rares, les motifs morphologiques initialement trop peu discriminants pourraient devenir pertinents. Appelons ces nouveaux classifieurs « avec seuil » et essayons-les.
On observe alors que le nombre de faux positifs diminue considérablement, même si le nombre de faux négatifs (des vrais noms binomiaux qui sont refusés) augmente légèrement. Évidemment, tout dépend du seuil de rareté choisi. Le seuil de rareté a été déterminé automatiquement par rapport à deux des volumes que nous avons annotés à la main. Une procédure automatique d’exploration a permis de déterminer quel seuil de rareté donnait la meilleure f-mesure pour ces deux volumes.
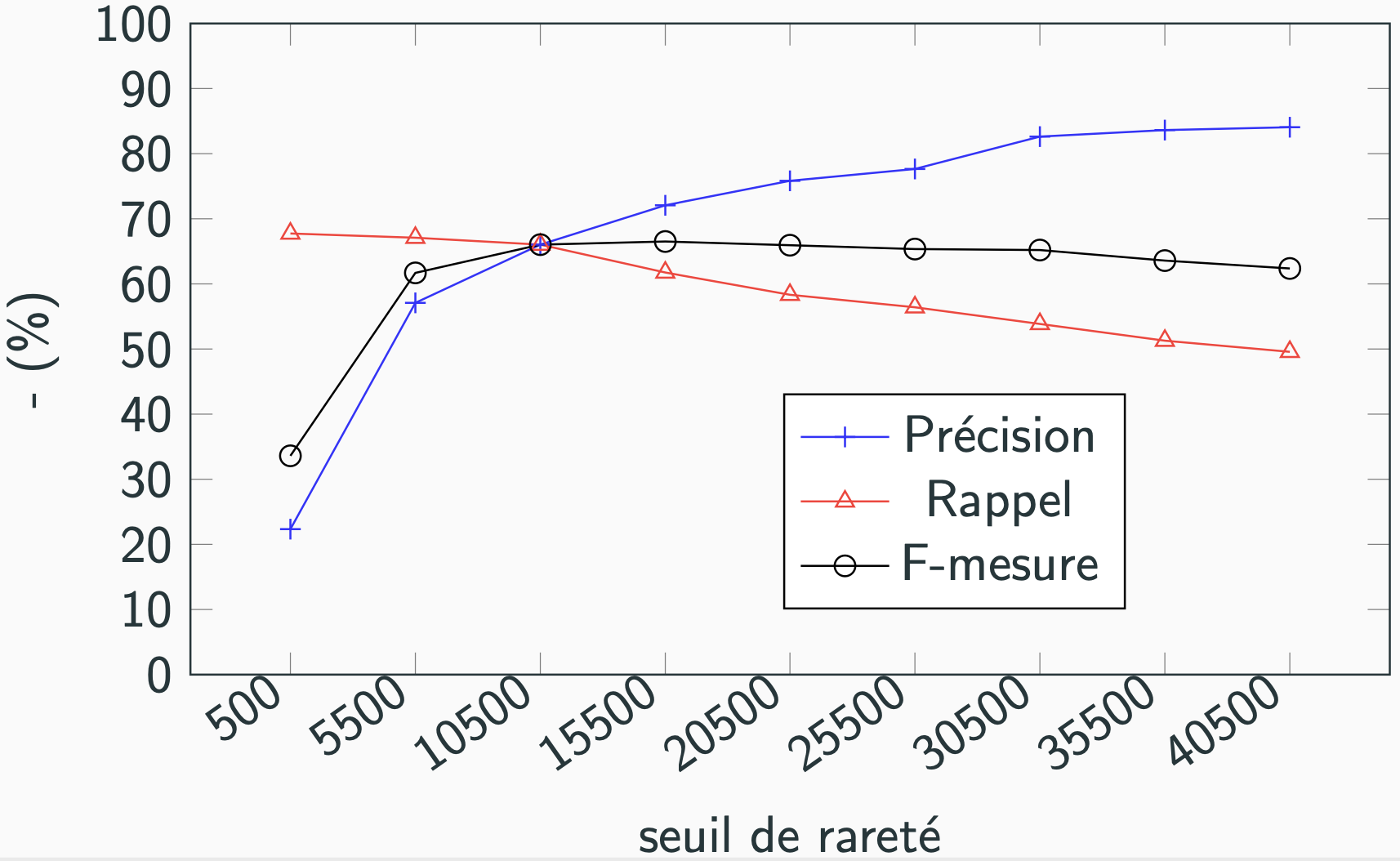
Figure 5 : Évolution des indicateurs de performance en fonction du seuil de rareté.
La figure 5 ci-dessus montre l’évolution des différents indicateurs de performance avec le seuil de rareté choisi pour LATIN. On peut voir que lorsque le seuil de rareté est faible, les critères utilisés sont très peu efficaces car, bien que nous répertoriions bien presque tous les noms binomiaux du corpus (indiqué par un rappel très élevé), la précision est quant à elle très faible, signe qu’on accepte énormément de couples qui ne sont pas de noms binomiaux. À l’inverse, quand on augmente le seuil de rareté, la précision augmente d’abord plus vite que le rappel ne baisse, et la f-mesure augmente alors. Le seuil retenu correspond au maximum de la f-mesure. Il est d’environ 15 000 ; c’est-à-dire que le classifieur avec seuil ignore les 15 000 mots les plus fréquents.
Les deux volumes n’ayant pas servi à l’étalonnage du seuil de rareté servent alors à évaluer les classifieurs avec seuil. On trouve pour les classifieurs TAXREF abstrait et LATIN, tous deux avec seuil de 15 000, une f-mesure de 70 %. Du coup, les classifieurs TAXREF abstrait et LATIN avec seuil sont renvoyés dos-à-dos en termes de qualité de reconnaissance. Une autre dimension d’évaluation est la vitesse de calcul et là on observe que LATIN avec seuil est significativement plus rapide que TAXREF abstrait avec seuil.
Évaluation sans annotation préalable
Les mesures de précision et de rappel sont évaluées par rapport à des volumes annotés. Cependant, on souhaite également évaluer la qualité d’un classifieur pour des volumes qui ne sont pas annotés. Pour cela, nous avons aussi pratiqué des évaluations sur des échantillons en utilisant ce qu’on appelle un « concordancier ». Le principe est d’afficher dans leur contexte des séquences reconnues comme noms binomiaux par le classifieur. Cela permet d’évaluer la précision du classifieur sur l’ensemble du corpus, mais pas le rappel. Par exemple, le concordancier montre les échantillons suivants, qu’il est assez facile de valider ou non :
- « tares envahie par les mulots (Wus sylvaticus) et par les campagnols (Arvic » montre un binôme reconnu malgré une erreur d’océrisation (Wus pour Mus), donc un vrai positif ;
- « s secteurs déterminés : ainsi Suæda frulicosa, espèce méditerranéenne, ne s » montre un binôme reconnu malgré une infraction à la règle qui interdit les ligatures (on voit aussi une erreur d’océrisation, frulicosa pour fruticosa — en fait il y en a vraiment beaucoup), encore un vrai positif ;
- « es Canards sauvages colverts (Anas boschas) et même les Oies sauvages de » montre un binôme obsolète qui est reconnu (on dit maintenant Anas platyrhynchos), encore un vrai positif ;
- « Crescens, en 1474, publia un Opus ruralium commodorum plein de renseigne » montre un faux positif qui est du vrai latin (un titre d’ouvrage) ;
- « . ..,..,….. posssnsrssse 46 Arkllerie prussienne. ……..4……sssses es » H » montre jusqu’où peut se fourvoyer l’océrisation, encore un faux positif ;
- « lations. – On connait, dit la Gazelle hebdo madaire de médecine, les lois » montre un gag involontaire, puisque Gazelle est ici une erreur d’océrisation de Gazette, et donc encore un faux positif.
Cette évaluation confirme une précision d’environ 70 %.
Genre espece, Genre espèce, G. espece, Genre Espece ou genre espece ?
Nous avons vu que l’une des règles de formation d’un nom binomial est que le genre comporte une majuscule et l’épithète n’en comporte pas. Dans les tables 2 et 3 ci-dessous on appelle cette forme \(Mm\). Les rédacteurs de La Nature font constamment des entorses à cette règle, surtout lorsque l’épithète est dérivée d’un nom propre : par exemple Trachycarpus Fortunei pour le Trachycarpus de M. Robert Fortune. On appellera cette forme \(MM\). Une autre règle peu respectée est celle qui interdit les accents et les ligatures dans les noms binomiaux : on devrait par exemple écrire Chamaerops plutôt que Chamærops. Notez qu’avec toutes ces relaxations Léo Messi et L. Messi peuvent facilement passer pour des noms binomiaux.
| Précision (%) | Rappel (%) | F-mesure (%) | |
| TAXREF abstrait \(Mm\) \(A\) \(+\) seuil | 90.32 | 65.2 | 75.73 |
| TAXREF abstrait \(Mm\) \(MM\) \(A\) \(+\) seuil | 42.81 | 70.73 | 53.34 |
| TAXREF abstrait \(Mm\) \(MM\) \(mm\) \(A\) \(+\) seuil | 38.12 | 74.63 | 50.47 |
TABLE 2 : Performances de TAXREF abstrait (rang 3) avec seuil (15 000) selon le niveau de relaxation des règles de base. |
|||
| Précision (%) | Rappel (%) | F-mesure (%) | |
| LATIN \(Mm\) \(A\) \(+\) seuil | 70.10 | 69.76 | 69.93 |
| LATIN \(Mm\) \(MM\) \(A\) \(+\) seuil | 63.49 | 75.77 | 69.09 |
| LATIN \(Mm\) \(MM\) \(mm\) \(A\) \(+\) seuil | 60.97 | 79.51 | 69.02 |
TABLE 3 : Performances de LATIN avec seuil (15 000) selon le niveau de relaxation des règles de base. |
|||
Ces relaxations sont si fréquentes que nous avons choisi d’étudier leur impact sur les classifieurs TAXREF abstrait (au rang 3) et LATIN, tous deux avec seuil de 15 000. Dans les deux cas, la possibilité d’abréger les noms de genre par leur initiale est intégrée dans les règles de base. On s’aperçoit alors que chaque entorse prise en compte fait augmenter le rappel de plusieurs points, mais fait perdre en précision. Perd-on plus ou moins que ce qu’on gagne ? On observe que la f-mesure du classifieur TAXREF abstrait se dégrade significativement quand on ajoute des relaxations, mais que le classifieur LATIN a une f-mesure qui est très stable. Nous pensons que cela fournit un critère de choix entre TAXREF et LATIN. En effet, entre une étude de principe et sa mise en œuvre réelle, il y a la place pour l’ingénierie avec de multiples réglages pour tenir compte des circonstances. Une approche qui se montre trop sensible aux réglages fins semble donc moins défendable qu’une approche qui y est moins sensible.
Conclusion
Nous avons présenté des approches symboliques classiques de la reconnaissance d’entités nommées appliquées au cas des noms binomiaux d’espèces. Nous avons exclu les approches par apprentissage neuronal, pourtant jugées plus modernes que les approches symboliques, par souci de sobriété dans les moyens mis en œuvre pour le développement des solutions proposées.
Par rapport à d’autres types de noms d’entités, comme les désignations de lieux ou de personnes, les noms binomiaux ont ceci de particulier qu’ils obéissent à des lois morphologiques, celles des codes de nomenclature (typographie spéciale et pseudo-latin), et qu’il existe des référentiels. Cela conduit respectivement à deux propositions de classifieurs que nous avons appelés LATIN et TAXREF. Malheureusement, le critère de ressembler à du latin est trop tolérant et celui d’être présent dans un référentiel est trop exigeant. Nous avons donc développé des variantes pour modérer ces inconvénients. D’abord, TAXREF abstrait, qui utilise un référentiel taxinomique comme générateur de motif, et fournit des résultats proches de ceux de LATIN. Ensuite, LATIN ou TAXREF abstrait, avec seuil de fréquence, et qui obtiennent des résultats équivalents mais bien meilleurs. Nous avons ensuite départagé ces deux classifieurs en observant que LATIN avec seuil semble plus robuste aux variantes que TAXREF abstrait avec seuil. On aboutit de cette façon là à une proposition qui semble robuste et dont la f-mesure est d’environ 70 %. Nous n’avons donc pas présenté d’approches fondées sur l’apprentissage, même si on peut penser que TAXREF abstrait et l’étalonnage du seuil constituent une forme d’apprentissage pas neuronal.
Le mode de validation présenté ici s’appelle une validation intrinsèque. C’est le seul possible en absence d’une application qui exploite ces classifieurs. Dès qu’une telle application sera disponible, nous pourrons procéder à une validation extrinsèque, c’est-à-dire une mesure de comment l’application en aval est affectée par les imperfections des classifieurs. Nous pensons que même si une amélioration des performances intrinsèques ne peut sans doute jamais nuire, elle peut être vaine si les performances extrinsèques viennent d’ailleurs. Une telle application est en cours de développement. Elle consiste en une interface de navigation « conceptuelle », c’est-à-dire qui permet à un utilisateur de formuler progressivement une requête en dialoguant avec l’application. Elle devra utiliser des critères de navigation variés, qui seront combinés dans des formules logiques (c’est-à-dire avec des ET, des OU et des NON), et nous comptons sur cette variété pour combler les défauts de tel ou tel classifieur. La navigation aura aussi pour but de sélectionner des articles selon ces critères, ce qui est une tâche plus simple que de reconnaître toutes les occurrences où les critères s’appliquent. Le rappel devrait s’en trouver amélioré. Ce sont bien sûr des hypothèses qui demandent validation.
Même en l’absence de cette application, il est déjà possible de tirer quelques enseignements des termes extraits. On voit par exemple l’essor de la paléontologie ou celui de l’étude des « microbes » invisibles à l’œil nu comme les virus et les bactéries et dont le rôle venait juste d’être identifié dans les désordres dont souffrent les humains, mais aussi les cultures ou les aliments. On peut observer aussi qu’un très grand nombre des taxons extraits ne sont plus usités aujourd’hui, montrant par là combien les connaissances ont évolué.
Les noms scientifiques de la classification du vivant constituent une catégorie d’entités nommées beaucoup moins fréquemment traitée que celles des personnes, des lieux ou des institutions. Elle est néanmoins particulièrement adaptée à l’exploration d’une revue de vulgarisation scientifique. En plus, cela permettra d’analyser en quoi La Nature a reflété l’évolution de cette classification. C’est ce genre d’analyse que nous voulons favoriser dans le cadre de nos travaux sur les archives de La Nature.
Les stratégies utilisées ici pourraient servir à d’autres catégories d’entités nommées encore peu explorées. Nous pensons ici aux dénominations d’espèces chimiques ou aux noms d’innovations technologiques. Les premières sont encadrées par des codes de nomenclature dont le premier date de 1890, par exemple en chimie organique avec des séries comme éthyl, méthylhexane, méthylheptane, dyméthylnonane… Nous pensons retrouver ici une situation proche de celles des nomenclatures du vivant. Au contraire, les noms d’innovations technologiques ne sont pas encadrés par des nomenclatures, mais ils utilisent de façon récurrente des préfixes ou des suffixes comme télé- ou -scope.
Nous avons vu en amont que les référentiels taxonomiques fournissent des noms vernaculaires et la position de chaque entrée dans la taxonomie du vivant. Le travail présenté ici pourrait donc être étendu dans ces directions. Notons que le même référentiel produira alors trois flux d’information très différents : les binômes taxonomiques, invariables (grammaticalement), fortement structurés, mais évolutifs, les positions dans l’arbre du vivant, très conventionnelles et très évolutives, et les noms vernaculaires, variables (grammaticalement), plutôt stables dans le temps, pas structurés du tout, et pas du tout alignés sur la taxonomie scientifique.
- Une version plus technique de l’article avec des références plus complètes :
- Les scans de LA NATURE par le CNUM
- Panorama sur l’extraction de binômes :
Ehrmann, M., Hamdi, A., Pontes, E. L., Romanello, M., & Doucet, A. Named entity recognition and classification in historical documents: A survey, ACM Computing Surveys, 2021.
- Binomiale ou binominale :
Aubert, Damien. Doit-on parler de « nomenclature binomiale » ou bien de « nomenclature binominale » ?. La banque des mots, 2016, 91, pp.7-14.
- Sur l’essor de la vulgarisation scientifique au XIXe siècle :
Vautrin, Guy. Histoire de la vulgarisation scientifique avant 1900. EDP Sciences, 2018.
Newsletter
Le responsable de ce traitement est Inria. En saisissant votre adresse mail, vous consentez à recevoir chaque mois une sélection d'articles et à ce que vos données soient collectées et stockées comme décrit dans notre politique de confidentialité
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Clément Morand
Ancien élève à l'École normale supérieure de Rennes de 2021 à 2023. Actuellement doctorant au Laboratoire Interdisciplinaire des Sciences du Numérique (Université Paris-Saclay, CNRS).

Olivier Ridoux
Professeur d'informatique à l'Université de Rennes, chercheur à l'IRISA.