
Sciences sociales et apprentissage machine pour l’interaction
Il vous est sûrement déjà arrivé de croiser une personne dans la rue qui va vous demander un renseignement. Dans cette situation, avant même qu’elle ne vous parle, son comportement, ses déplacements, son langage corporel, son regard et votre expérience personnelle ont fait que vous saviez déjà qu’elle allait s’adresser à vous, et parfois même de ce qu’elle allait vous demander. C’est de cette capacité de perception, de compréhension des comportements des personnes et d’anticipation que les chercheurs en interaction Homme-machine souhaiteraient doter les systèmes interactifs, c’est-à-dire les systèmes informatiques et/ou robotiques qui interagissent avec des humains.
Prenons l’exemple du maintien à domicile de personnes âgées ou fragiles. Dans ce contexte, des recherches sont menées pour mettre au point des robots compagnons d’assistance destinés à permettre à ces personnes de rester le plus longtemps possible en autonomie à domicile. Pour rendre ce service, ce compagnon de tous les instants ne doit donc pas s’avérer dérangeant en s’adressant à la personne assistée à chaque fois que celle-ci est dans son champ de vision ou est simplement proche de lui. Ce comportement, déplacé, serait perçu comme inacceptable et conduirait à un rejet du robot compagnon, et donc de son assistance. Le robot doit donc détecter les personnes autour de lui avec ses différents capteurs, les identifier, analyser leurs comportements et « comprendre » leurs intentions, c’est-à-dire calculer des informations pertinentes pour décider de la meilleure action à réaliser. C’est ce que l’on nomme la boucle d’interaction : percevoir l’environnement, décider de la meilleure action à réaliser et agir, c’est-à-dire effectuer l’action choisie. Dans notre exemple, la tâche d’interaction du robot est de pouvoir différencier que quelqu’un s’approche de lui avec l’intention d’interagir (l’engagement) ou simplement que cette personne s’approche pour passer près de lui. Dans le premier cas, il doit commencer à interagir avec la personne pour répondre à son engagement, dans le second cas, il ne doit rien faire de particulier.
L’apprentissage automatique et ses biais
Ce besoin de calculer des informations pertinentes est soutenu aujourd’hui par l’intelligence artificielle, avec des avancées majeures en apprentissage machine (machine learning) notamment en apprentissage dit profond à l’aide de réseaux de neurones (deep learning). Les algorithmes d’apprentissage profond nécessitent de grandes quantités de données pour leur entraînement. Si l’on s’intéresse à un « simple » système de classification d’images (voiture, chien, cheval, avion, personne, vélo…), celui-ci peut utiliser un ensemble d’images comme ImageNet1 comme base d’entraînement. Cette collection de données disponible pour la communauté scientifique contient plus de 14 millions d’images annotées, c’est-à-dire avec un label associé décrivant ce que contient l’image. Ces collections de données de grande taille sont ce que l’on nomme des mégadonnées (big data). Malgré leur performance indéniable et les progrès qu’ils ont permis dans de nombreux domaines, ces algorithmes utilisant de grandes masses de données ne sont pas exempts de défauts. Tout d’abord, il existe un problème éthique à l’usage des mégadonnées. Celles-ci n’ont pas toujours été collectées en ayant un consentement parfaitement éclairé de la part des personnes concernées : combien de ces personnes savent qu’elles sont présentes dans ces corpus collectés sur Internet qui sont distribués à l’échelle planétaire ? Elles ont accepté, généralement sans en comprendre la portée, le partage de ces données sur un réseau social par exemple mais ont-elles accepté tous les usages qui sont faits de celles-ci (reconnaissance faciale, identification de personne, etc.) ? L’éthique se télescope donc avec le besoin massif de données pour l’apprentissage des réseaux de neurones. Des approches utilisant des réseaux antagonistes génératifs (Generative adversarial networks ou GAN) sont étudiés pour la génération automatique de données, permettant d’éviter les écueils concernant le respect de la vie privée. Par exemple, le site ThisPersonDoesNotExist utilise cette technique pour générer des visages (parfois imparfaits) aléatoirement. Cependant, des recherches sont encore nécessaires pour qu’ils puissent remplacer les données massives. Une autre problématique liée à l’usage de ces algorithmes d’apprentissage profond réside dans leur inexplicabilité. Il est pour l’instant quasiment impossible d’expliquer précisément ce qu’apprend un réseau de neurones. Sa performance est mesurée sur des données connues, c’est-à-dire des images dont on sait ce qu’elles représentent, mais ne peut en rien certifier son fonctionnement dans des conditions réelles. Cette problématique a d’ailleurs donné naissance à un nouveau domaine de recherche, l’intelligence artificielle explicable (explainable AI), s’intéressant à ces problématiques complexes notamment en termes de crédibilité de l’explication fournie à l’utilisateur2. En complément de ces problématiques théoriques, un dernier écueil plus pragmatique concerne l’existence même de données pour apprendre certaines tâches à réaliser par nos systèmes. Pour de très nombreuses applications en lien avec les interactions avec des humains, les données ne sont pas disponibles ou en quantité trop faible pour que les algorithmes d’apprentissage (profond) puissent être utilisables.
Apport des connaissances issues des recherches en sciences sociales
À partir de ce constat, comment apprendre aux algorithmes des tâches d’interaction avec pas ou peu de données et en les rendant explicables si possible ? L’une des réponses possibles à cette question pour les tâches impliquant des humains est de compulser la littérature scientifique et d’intégrer des connaissances venues des recherches en sciences sociales (sociologie, psychologie…) pour avoir une vision interdisciplinaire des systèmes interactifs. L’apprentissage profond garde son intérêt pour la perception de bas niveau, mais pour l’interprétation de plus haut niveau de l’interaction, les sciences sociales apportent des éléments d’analyse tangibles et perceptibles. Reprenons notre exemple de robot compagnon d’assistance aux personnes âgées. Il n’y a pas de données massives pour l’apprentissage de la détection d’engagement. Il faudrait recueillir des centaines ou des milliers d’heures d’exemples, les visionner et les annoter pour entraîner un tel système. Collecter ces données demanderait un effort logistique conséquent, sans même mentionner la prise en compte de considérations médicales et éthiques concernant l’enregistrement de personnes âgées ou fragiles.
Le langage corporel pour les interactions humain-robot
La littérature scientifique en sociologie peut nous apporter des clés pour résoudre ce problème. Par exemple, Emanuel A. Schegloff, un sociologue, a étudié le langage corporel de personnes engagées dans des interactions3. Parmi les résultats intéressants de ses recherches, il a montré que dans ces interactions, l’un des indices pour repérer le début d’une interaction (l’engagement) est de scruter l’orientation des épaules d’une personne en direction de son interlocuteur, indice plus important que l’orientation de la tête, même si c’est contre-intuitif. Ce résultat de recherche est très intéressant pour plusieurs raisons. La première est que si l’humain se comporte avec le robot comme il le fait avec ses congénères, alors cet indice peut se révéler extrêmement utile. La seconde raison est que l’orientation des épaules est calculable par un robot équipé d’une caméra standard. En utilisant l’apprentissage profond et les mégadonnées disponibles, il est possible de détecter efficacement les personnes et les mouvements de leur corps4. À partir de ces informations, extraire l’orientation des épaules des personnes pour déterminer l’intention d’interagir avec le robot se résout par un calcul géométrique. Sur un jeu de données expérimentales, en utilisant cette technique, nous avons corroboré que l’orientation des épaules était primordiale pour détecter l’intention d’interagir des personnes avec un robot. En la couplant avec d’autres informations standard en interaction (position/vitesse des personnes, détection de voix par exemple), il est possible de détecter l’engagement avec plus de 90% de précision, autrement dit, la décision du robot d’interagir, ou pas, est correcte5 plus de 9 fois sur 10.
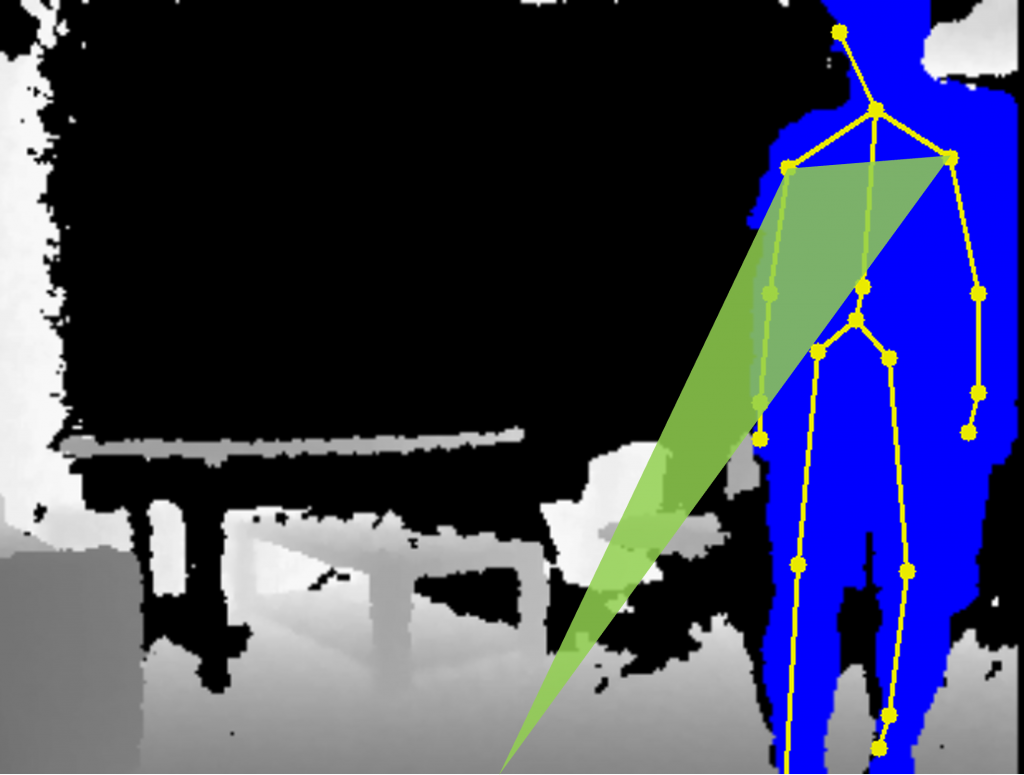
Détection de l’orientation des épaules d’un humain envers un robot après détection des différentes articulations par Machine Learning.
En ajoutant sciemment une information de langage corporel étudiée en sociologie, le système de perception de l’engagement s’en trouve amélioré. De plus, cette information ayant une sémantique forte, elle apporte une part d’explicabilité au système de détection : « Comment le robot a-t-il décidé que vous souhaitiez interagir avec lui ? Il a analysé votre langage corporel comme vous le faites en permanence avec vos interlocuteurs ». Le même résultat aurait potentiellement pu être obtenu en n’utilisant que l’apprentissage profond directement à partir de vidéos si l’on avait eu assez de données d’apprentissage. Mais, avec les connaissances actuelles, il aurait été difficile voire impossible d’expliciter ce sur quoi se base le réseau de neurones pour prendre ses décisions.
Les comportements des piétons pour la navigation des véhicules autonomes
Les approches interdisciplinaires intégrant des sciences sociales montrent une pertinence pour les systèmes interactifs dans d’autres applications. À une échelle plus grande, on peut s’intéresser aux problématiques de déplacement des véhicules autonomes dans les centres urbains. Ceux-ci doivent décider de la trajectoire idéale à suivre pour qu’elle soit sûre, tout d’abord, mais également acceptable par les piétons : prédictible, pas trop proche ni trop agressive, etc. Pour cela, les véhicules autonomes doivent percevoir l’environnement pour anticiper les comportements des piétons présents autour d’eux. Ces comportements sont dépendants d’un grand nombre de facteurs dont la topologie des lieux et les interactions sociales entre les piétons. Il est utopique de vouloir obtenir des données représentatives de tous les environnements possibles pour l’apprentissage d’un tel système de prédiction du comportement des piétons.
Une approche possible est alors de s’inspirer encore une fois de modèles issus des sciences sociales comme les travaux du psychologue James Jerome Gibson sur la « natural vision ». Dans ces travaux6, l’auteur décrit la perception visuelle comme basée sur des « affordances » de l’environnement, c’est-à-dire la perception d’informations d’intérêt, positives ou négatives, guidant le comportement de la personne, cette perception variant selon les individus. Par exemple, les zones dans lesquelles il est facile de marcher sans risque sont perçues comme des affordances positives et attractives par tout le monde. Un chemin escarpé sera perçu par certains comme une affordance positive, et pour d’autres comme négative car celui-ci est trop périlleux. Dans leur théorie de « natural movement »7, l’urbaniste Bill Hillier et ses coauteurs déclinent ce concept en s’intéressant aux comportements des piétons en environnement urbain, les décrivant à l’aide d’attracteurs (entrées de magasin, passages piétons par exemple) et de répulseurs (voies de circulation, véhicules…), respectivement équivalents à des affordances positives et négatives.
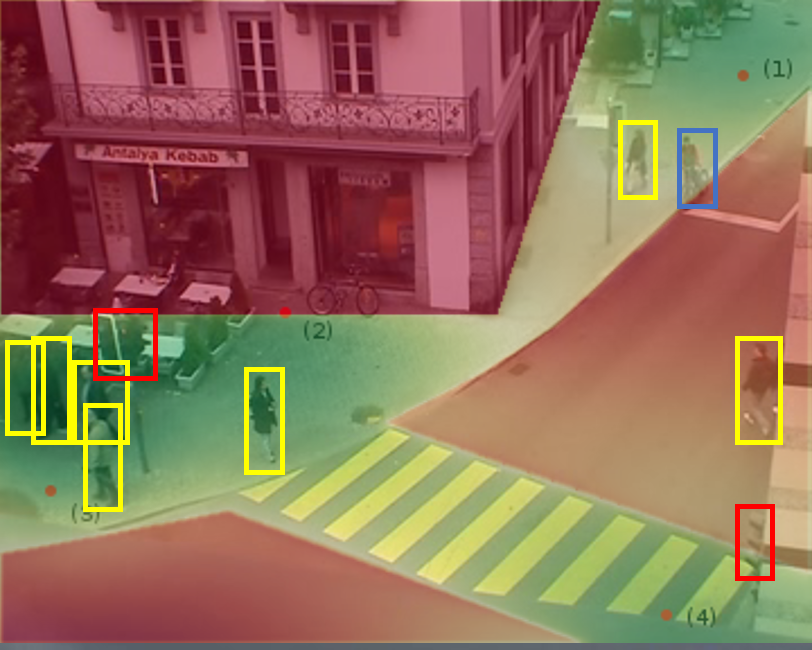
Modélisation statistique des déplacements des piétons dans un centre urbain. Les différents espaces (trottoirs, bâtiments, routes, passages piétons, feux tricolores, entrées de magasin) sont modélisés. Les comportements des piétons (en jaune sur l’image) peuvent ensuite être anticipés par un véhicule autonome.
Les points d’intérêt mentionnés précédemment, les piétons et les autres usagers de la route sont aujourd’hui détectables avec une précision suffisante en utilisant les techniques d’apprentissage profond pour les environnements urbains8. À partir de cette détection, l’environnement autour du véhicule autonome, avec ses attracteurs et ses répulseurs, peut se représenter sous une forme mathématique permettant d’anticiper les déplacements des piétons présents autour du véhicule autonome9. Les résultats que nous avons obtenus montrent de nouveau que, par rapport à d’autres approches de pur apprentissage machine, l’approche interdisciplinaire est digne d’intérêt et permet d’améliorer les performances. À l’instar de la conduite humaine, cette approche se base sur une perception des éléments présents autour du véhicule autonome et construit un modèle lui permettant d’anticiper les déplacements futurs des piétons. Son intérêt réside dans l’adaptation dont elle est capable pour les environnements inconnus rencontrés par le véhicule autonome, la condition sine qua non étant de pouvoir y percevoir les affordances.
L’interdisciplinarité, une voie de recherche
Les deux exemples précédents illustrent ce que peut apporter l’interdisciplinarité entre les sciences sociales et l’apprentissage machine pour les systèmes interactifs. Cette interdisciplinarité est à contre-courant de l’idée tendant à se répandre que nous n’aurions plus besoin d’analyser ou de théoriser les concepts mais qu’il suffirait d’avoir suffisamment d’exemples pour apprendre n’importe quelle tâche d’intelligence artificielle10. Même si cela est potentiellement vrai, cela se ferait aux dépens de l’explicabilité du système, explicabilité qui est l’un des leviers d’acceptation de l’intelligence artificielle par le grand public. Il faut donc cultiver les approches interdisciplinaires et sensibiliser les (jeunes) chercheurs des « sciences dures » à s’intéresser aux bénéfices tirés des autres domaines scientifiques s’intéressant à l’humain. Les potentialités pour les systèmes interactifs sont extraordinaires si l’on considère les humains dans toute leur complexité. Soutenue par les progrès encore à venir en apprentissage machine et en sciences sociales, l’interdisciplinarité bénéficiera à de nombreux autres domaines d’application avec un impact sociétal fort, pour l’éducation avec le développement de salles de classes sensibles aux interactions enseignants/étudiants permettant d’étudier et d’améliorer les pratiques pédagogiques, et en santé avec de nombreuses applications dans l’assistance et le maintien de personnes fragiles à domicile.
Références
- Deng, W. Dong, R. Socher, L.-J. Li, K. Li and L. Fei-Fei, ImageNet: A Large-Scale Hierarchical Image Database, IEEE Computer Vision and Pattern Recognition (CVPR), 2009.
- Erwan Le Merrer, Gilles Trédan. Le problème du videur : la crédibilité des explications de l’IA en question. Interstices, INRIA, 2021.
- A. Schegloff. Body Torque. Social Research, 65(3):535–596, 1998
- shu Fang, S. Xie, Y.W. Tai, and C. Lu. RMPE: Regional multi-person pose estimation. IEEE International Conference on Computer Vision (ICCV), pages 2353–2362, 2017.
- Vaufreydaz, W. Johal, C. Combe. Starting engagement detection towards a companion robot using multimodal features. Robotics and Autonomous Systems, Elsevier, 2015, Robotics and Autonomous Systems, pp.25.
- J Gibson, The Ecological Approach to Visual Perception, 1979
- B Hillier, A Penn, J Hanson, T Grajewski, J Xu, Natural movement: or, configuration and attraction in urban pedestrian movement, Environment and Planning B: planning and design, 1993
- Qiao, S., Zhu, Y., Adam, H., Yuille, A., & Chen, L. C. (2021). Vip-deeplab: Learning visual perception with depth-aware video panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition(pp. 3997-4008).
- Vasishta, D. Vaufreydaz, A. Spalanzani. Building Prior Knowledge: A Markov Based Pedestrian Prediction Model Using Urban Environmental Data. ICARCV 2018 – 15th International Conference on Control, Automation, Robotics and Vision, Nov 2018, Singapore, Singapore. pp.1-12.
- Calude, and G. Longo, The Deluge of Spurious Correlations in Big Data, Opening Lecture, Colloque Lois des dieux, des hommes et de la nature, published inFoundations of Science, 1-18, March, 2016.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Dominique Vaufreydaz
Dominique Vaudreydaz est maître de conférence en science informatique à l'Université Grenoble Alpes, et chercheur au sein du Laboratoire Informatique de Grenoble.