Interactions en temps réel entre un acteur humain et un acteur virtuel
Les effets spéciaux sont des éléments récurrents de nombreux spectacles. Ces techniques créent l’illusion de la présence d’objets ou de personnages qui n’existent pas dans la réalité, mais avec lesquels les acteurs réels interagissent. Le film Avatar de James Cameron, grosse production cinématographique hollywoodienne, en est une parfaite illustration. Si ces effets sont abondamment exploités au cinéma, il n’en est pas de même au théâtre, où les contraintes d’interaction avec l’environnement sont plus importantes. D’une part, les spectateurs sont présents face à la scène et aux acteurs. Chacun d’eux a un point de vue différent de la même scène, selon la place où il est assis. D’autre part, la performance s’exécute en direct, dans un espace limité. Il ne peut donc pas y avoir de changement d’échelle. Interagir avec un objet, a fortiori un acteur « virtuel », pose alors divers problèmes : la représentation de l’objet — l’acteur virtuel — sur la scène ; la perception par l’acteur virtuel de son environnement et des actions des acteurs réels ; ses interactions en « temps réel » avec l’environnement et les utilisateurs.
Application du modèle de reconnaissance. Mise en scène d’un « combat » de capoeira entre un utilisateur doté d’une combinaison de capture de mouvement (moven Xsens) et un acteur virtuel, lors du Festival annuel des arts indisciplinaires du centre culturel de Brest en 2008.
Visionner la vidéo (film muet) – Durée : 1 min 40 s.
Dans un contexte où le « théâtre virtuel » n’a de cesse de se développer, l’équipe de recherche ARéVi (Ateliers de Réalité Virtuelle) du Centre européen de réalité virtuelle (CERV) de l’École nationale d’ingénieurs de Brest (ENIB) a créé un système de reconnaissance gestuelle en temps réel qui permet des interactions entre un acteur humain et un acteur virtuel. L’objectif ? Permettre à un utilisateur, acteur réel, d’interagir avec un humanoïde de synthèse, acteur virtuel. La gestuelle étant le type de communication visuelle le plus exploité au théâtre, elle constitue le premier mode de communication mis en œuvre pour « dialoguer » avec l’acteur virtuel. Le système de reconnaissance de gestes que nous avons développé est principalement fondé sur la capacité d’un acteur virtuel à percevoir et différencier en « temps réel » les gestes successifs accomplis par un acteur réel.
Comme pour une pièce de théâtre traditionnelle, un spectacle mêlant réel et virtuel est monté en deux phases : d’abord les répétitions, durant lesquelles les gestes seront enregistrés, puis les représentations, où les gestes seront reconnus en « temps réel ». Nous avons donc développé une méthode de reconnaissance de gestes pré-enregistrés, pour qu’un utilisateur doté de divers équipements (manettes wii-mote, système de capture de mouvement…) puisse interagir en « temps réel » avec un acteur virtuel, en exécutant les gestes que ce dernier peut reconnaître. L’application que nous avons développée pour tester notre système repose sur un « combat » de capoeira entre un utilisateur doté d’un équipement de capture de mouvement (moven Xsens) et un acteur virtuel. La démonstration a été présentée lors du Festival annuel des arts indisciplinaires du centre culturel de Brest en 2008.
Systèmes de capture de mouvement
Les systèmes de capture de mouvement génèrent, en temps réel, une grande quantité de données représentatives du mouvement humain. Chaque type de capteurs a ses propres caractéristiques et produit des données de différente nature : accélération, position, orientation… Nous avons donc décidé de mettre en place une méthode de reconnaissance gestuelle qui soit suffisamment générique pour être utilisable quelle que soit la technologie inhérente aux capteurs utilisés par le système de capture de mouvement. Notre seule hypothèse est que, à chaque pas de temps, le système sera capable de produire la même quantité de données. Nous utilisons les données brutes issues des capteurs. Ainsi, nous sommes capables d’évaluer notre système de reconnaissance avec différents types de capteurs, classés ici selon le type de données qu’ils génèrent, du plus simple au plus complexe :
- position absolue en coordonnées 3D, par suivi de marqueurs (gants colorés, système Vicon) ;
- hiérarchie des orientations des données issues de formats de fichiers BVH ou de combinaisons de capture de mouvement ;
- liste des valeurs d’accélération issues des manettes wii-mote.
Représentation du geste
Notre idée est que, pour obtenir une représentation spécifique d’un geste particulier, l’ensemble des données issues de tout équipement de capture de mouvement peut être réduit à une signature artificielle unique, spécifique à chaque geste. Pour générer cette signature, nous utilisons les propriétés d’une méthode de compression de signal, appelée ACP (Analyse en Composante Principale), basée sur l’analyse de données, pour transformer les données dans un espace 2D dédié à chaque geste. Cette signature sera représentée par une matrice de projection (MdP) et une courbe 2D associée, chaque point de la courbe représentant une pose dans l’animation gestuelle.
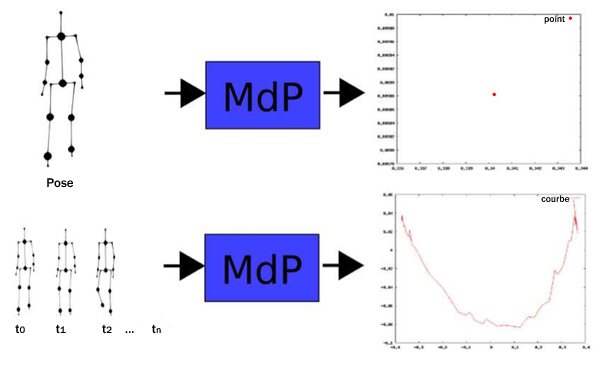
Matrice de projection et signature de geste.
À chaque pose correspond un point ; la courbe représente la succession des poses.
Reconnaissance du geste
L’étape de reconnaissance utilise cette signature pour produire un événement dans l’environnement virtuel qui permettra à l’acteur virtuel de déclencher une action sous forme d’animation gestuelle. La difficulté principale réside dans le fait que nous avons à faire face à un flux de données continu en temps réel. Nous devons être capables, au préalable, de segmenter ce flux et de déterminer le début et la fin du geste, pour pouvoir ensuite calculer la fidélité d’observation de ce geste par rapport aux gestes pré-enregistrés.
La méthode classique pour faire de la reconnaissance est de créer un corpus de données à partir des sessions d’enregistrement, puis de réduire ces données à l’aide d’opérateurs mathématiques, de manière à faciliter la mise en correspondance d’un geste parmi un ensemble de gestes lors de la reconnaissance. Notre approche est tout à fait différente, car chaque geste est indépendant des autres. Au lieu d’essayer de trouver un geste parmi un ensemble, c’est le geste lui-même qui signale quand il se reconnaît dans le flux. Nous utilisons le paradigme de la programmation orientée agent, tel qu’il est utilisé dans les systèmes multi-agents, à ceci près que les agents ne communiqueront pas entre eux. Nous avons mis en place deux types d’agents, l’agent « Gestuel » et l’agent « Observateur ».
La figure suivante représente l’algorithme que nous avons développé pour mettre en œuvre notre système de reconnaissance.
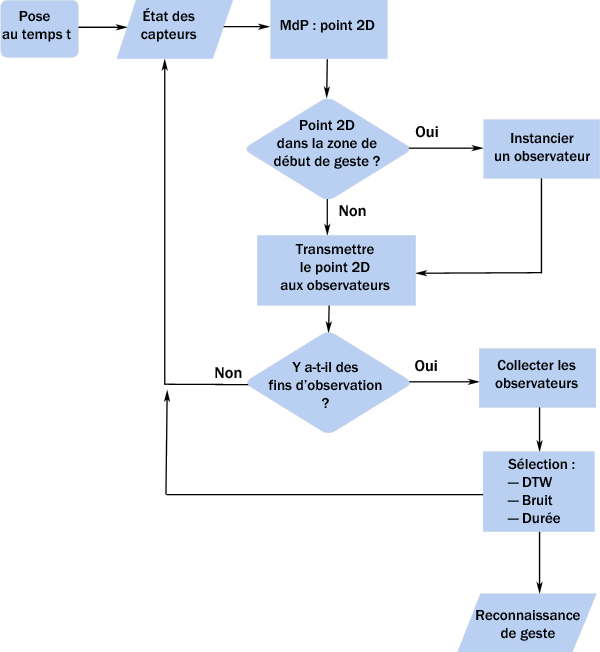
Algorithme de reconnaissance de geste.
Lorsque l’état des capteurs (une pose) correspond, après projection, à un point dans la zone de début de geste, l’agent Gestuel génère un nouvel agent Observateur. Dans le cas contraire, il transmet le point projeté aux autres observateurs. Lorsqu’une fin de geste est perçue, tous les observateurs concernés sont consultés pour trouver celui qui se rapproche le plus du geste pré-enregistré selon trois critères de « fidélité » :
- différence non-linéaire entre les deux signaux (Dynamic Time Warping) ;
- différence de points caractéristiques, nombre de zones validées (début, geste, fin) ;
- différence temporelle d’exécution du geste.
Un événement de reconnaissance de geste, récapitulant les informations sur le geste en question, est alors transmis à l’acteur virtuel qui décide de l’action, du geste, à exécuter en réponse au geste reconnu.
Résultats

Enregistrement de gestes.
Pour tester notre système de reconnaissance, nous avons utilisé un corpus de gestes (vingt-deux gestes de pointage) que nous avons pré-enregistrés dans notre laboratoire avec un système de capture de mouvement. Ces gestes sollicitent les mêmes articulations, et présentent peu de variations. De ce fait, les gestes sont très similaires entre eux, même un humain pourrait s’y tromper. L’analyse des résultats montre que notre système reconnaît la totalité des gestes du corpus. Tous ces gestes ont une durée limitée de 2,5 secondes et ont été totalement reconnus en moyenne 0,5 seconde avant la fin d’exécution du geste.
À la suite de cette validation de notre système de reconnaissance, nous avons mis en place une courte démonstration, présentée au centre culturel de la ville de Brest, le Quartz, lors du Festival annuel des arts indisciplinaires (voir la vidéo ci-dessus). Cette démonstration utilisait des gestes en nombre plus limité, mais plus complexes à réaliser et donc à reproduire. Un acteur virtuel, la marionnette de Pinocchio, joue une animation gestuelle pré-enregistrée différente suivant les gestes réalisés par l’acteur humain doté d’une combinaison de capture de mouvement. L’enchaînement des gestes entre les deux acteurs correspond à une « chorégraphie » de capoeira.
Conclusion

Démonstration de capoeira.
Notre système de reconnaissance nous permet donc d’enregistrer dynamiquement les gestes et d’associer à chaque geste enregistré une signature. Ce module nous permet de reconnaître les gestes en temps réel dans un flux de données brutes provenant de différents dispositifs (gants de couleur, wii-mote, équipement de capture de mouvement…). Actuellement, notre acteur virtuel est donc capable de reconnaître les gestes de l’utilisateur et d’agir en conséquence, répondre par une animation gestuelle, en « temps réel ». Un utilisateur, doté d’un équipement de capture de mouvement, peut donc communiquer avec notre humanoïde de synthèse, comme nous l’avons montré avec l’application mise en œuvre et testée devant un public.
Cependant, si nous sommes capables de reconnaître, en principe, n’importe quel type de gestes, les limites de notre système se situent au niveau du modèle de comportement de notre acteur virtuel qui, pour l’instant, réagit de la même façon prédéfinie lorsqu’il reconnaît un même geste. Nous travaillons donc sur la partie décisionnelle de notre acteur virtuel, pour renforcer la crédibilité d’interaction en intégrant un modèle d’animation comportementale qui permettrait d’enrichir la palette d’actions possibles de l’acteur virtuel.
Par ailleurs, le fait que notre système arrive à reconnaître un geste avant la fin de son exécution ouvre la perspective d’un modèle d’« anticipation » des gestes possibles de l’acteur réel. Nous envisageons d’intégrer une « sémantique » de reconnaissance associée à une séquence de gestes, ce qui nous permettra de reconnaître des « phrases gestuelles » afin d’élaborer un véritable dialogue entre acteur réel et virtuel.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Jacques Tisseau
Ronan Billon