
Synthèse d’images
L’homme a toujours cherché à représenter visuellement tant son environnement réel que son monde imaginaire. Depuis les fresques des hommes préhistoriques dans des grottes jusqu’aux œuvres des artistes contemporains, en passant par les tableaux des peintres de la Renaissance ou les estampes des illustrateurs chinois, la représentation visuelle a connu de très nombreuses évolutions. Ces variations sont souvent liées à l’apparition de nouveaux outils (pinceau, bambou, spatule, aérographe…) et de nouvelles techniques (soufflage de pigment, empreinte positive/négative, perspective, pointillisme, cubisme…).
Il n’est donc pas surprenant que l’apparition de l’ordinateur ait aussi suscité des réflexions débouchant sur l’utilisation de ce nouvel outil pour créer des images. Là encore, ce sont des évolutions matérielles qui ont induit une évolution des modes de représentation.
Un peu d’histoire…
L’ordinateur ayant été inventé pour réaliser rapidement des calculs numériques, les premiers objets visualisés furent des courbes mathématiques. Elles étaient affichées à l’aide de caractères sur les terminaux alphanumériques utilisés pour tous les traitements. Au fil du temps, ce principe fut réutilisé dans les premiers jeux vidéo, dans des signatures de messages électroniques ou bien, plus récemment, dans des émoticons.
 |
 |
| Quelques exemples de représentations alphanumériques. Source : Images d’art Ascii | |

Système DAC-1 développé par General Motors et IBM à partir de 1959. C’est le premier système de CAO qui fut commercialisé en 1964. Source : Wayne Carlson
Le premier écran dédié aux images, nommé TX-1, fut mis au point au MIT en 1955. Il s’agissait d’un tube cathodique piloté par un ordinateur. À cette époque, l’opération de base consistait à tracer un segment de droite sur l’écran, qu’on appelle alors terminal vectoriel.
Malheureusement, ce tracé étant de nature fugace, il fallait le réitérer en permanence pour que l’œil humain le perçoive. Ce modèle d’écran resta d’actualité une quinzaine d’années et fut commercialisé au milieu des années 1960 par DEC, IBM, Tektronix… Les premiers systèmes de CAO, conception assistée par ordinateur, qui utilisaient ce mode d’affichage, ont alors vu le jour.
En 1963, Ivan Sutherland, un des pionniers de l’informatique graphique, imagina puis réalisa pendant sa thèse, qu’il effectuait au MIT, le premier logiciel d’édition interactive, Sketchpad (voir une vidéo de démonstration, en anglais). Le logiciel Sketchpad permettait à la fois la création, la manipulation et l’animation de figures géométriques simples. L’utilisation d’un stylet contribuait à l’originalité de cette interface.
 |
 |
| Ivan Sutherland à la console du TX-2, travaillant sur Sketchpad (MIT, 1963). Source : Biography of Ivan Sutherland | Démonstration de Sketchpad. Utilisation simultanée d’un clavier et d’un stylet. Source : Vision and Reality of Hypertext and Graphical User Interfaces |
On trouvera plus de détails sur l’histoire de l’interaction homme – machine dans l’article de Michel Beaudoin Lafon.
Avec l’abaissement du prix de la mémoire apparurent, au début des années 1970, les premiers écrans matriciels permanents, ne nécessitant pas de retraçage. L’opération de base consistait à allumer un point que l’on appelle pixel (contraction de picture element, en anglais). Ces écrans ont fourni le modèle de ceux que nous utilisons encore aujourd’hui et ce malgré plusieurs évolutions technologiques : des écrans cathodiques au LCD, puis au plasma… C’est notamment grâce à l’apparition des micro-ordinateurs, tous pourvus d’un tel écran, que ce modèle s’imposa très rapidement.
Les tracés
Cette nature matricielle de l’écran va entraîner de nombreuses propriétés pour les images que l’on y visualise. Par exemple, sur un écran matriciel, deux segments de droite non parallèles peuvent avoir 0, 1 ou n > 1 points communs. Avouez que cela bouleverse quelque peu ce que nous avons appris de la géométrie ! L’explication est simple : sur l’écran n’apparaît pas la droite elle-même, mais seulement sa représentation, qui est fortement dépendante de la nature de l’écran. En fait, il ne s’agit que d’une approximation du tracé idéal.

À gauche, des motifs crénelés (aliased); à droite, des motifs traités (anti-aliased).
La nature non continue de l’écran se manifeste également au travers de la qualité visuelle d’un tracé. Prenons encore l’exemple d’un segment de droite : s’il est horizontal ou vertical, le tracé est idéal, parce que la forme et la disposition des pixels forment un rectangle quasi-parfait. Si l’on considère maintenant un segment oblique, le tracé correspond à une suite de carrés adjacents, ce qui produit un effet de crénelage (aliasing en anglais) qui peut visuellement être très désagréable. Deux paramètres influencent ce défaut : la pente du segment et la résolution de l’écran. Un grand nombre de techniques regroupées sous le terme d’anti-aliasing ont été développées pour atténuer ce défaut.
On voit apparaître là une première contrainte forte du processus de synthèse : la qualité de l’image. Ce critère ne dépend pas uniquement des formes et des couleurs, mais est fortement influencé par les propriétés de la perception humaine. En d’autres termes, ce n’est pas l’œil qu’il faut charmer mais bien le cerveau !
On définit la résolution spatiale comme le nombre de pixels disponibles (correspondant au nombre de lignes multiplié par le nombre de colonnes) et la résolution colorimétrique comme le nombre de couleurs que peut afficher un pixel d’un écran matriciel.
La deuxième contrainte du processus est le temps de calcul : allumer les pixels qui composent le segment de droite n’est pas chose triviale. Au préalable, il est nécessaire de choisir les « meilleurs » pixels pour cela. Ce choix résulte de calculs faits par l’ordinateur ; notons au passage que l’algorithme le plus célèbre pour résoudre ce problème, l’algorithme de Bresenham, a été inventé en 1965 par Jack E. Bresenham et qu’il est toujours utilisé aujourd’hui.
Qualité et temps de calcul, voilà les deux contraintes auxquelles est confrontée la synthèse d’images depuis sa naissance. Soulignons leur caractère antagoniste : si l’on veut améliorer la qualité d’une image, il est en général nécessaire d’augmenter la complexité des traitements et donc d’augmenter le temps de calcul. Les informaticiens jouent avec ces deux critères et, le plus souvent, mettent au point des compromis en fonction du contexte d’utilisation des logiciels qu’ils développent.
Les applications
Pourquoi calcule-t-on des images de synthèse aujourd’hui ? Pour un nombre croissant de domaines d’application, que l’on peut essayer de regrouper autour de quelques objectifs principaux :
- la conception : grâce à l’image, les concepteurs ont une meilleure perception d’un objet en cours de définition donc encore inexistant,
- la compréhension : une image permet de mieux comprendre certains phénomènes complexes, qu’ils soient scientifiques, médicaux, financiers…
- la formation : les apprenants appréhendent plus facilement un objet ou un environnement qu’ils devront manipuler (simulateur de conduite, atlas anatomique…),
- l’information et le divertissement : l’image de synthèse autorise à s’abstraire de certaines contraintes du monde réel.
Bien qu’il soit impossible d’en dresser la liste de façon exhaustive, voici quelques exemples d’applications.
La visualisation scientifique est à l’origine de la synthèse d’images. Aujourd’hui, on utilise des images pour visualiser des résultats de calculs de simulation complexe (résistance des matériaux, dynamique des fluides, aérodynamique…) par exemple pour concevoir de nouveaux avions, de nouvelles voitures ou de nouveaux bâtiments. L’image de synthèse est également prépondérante dans la détermination de la forme de ces objets très complexes. On désigne ce processus global par l’expression Conception Assistée par Ordinateur (CAO ou en anglais CAD, Computer Aided Design).
Le monde médical fait également appel de plus en plus souvent aux images de synthèse, pour visualiser en 3D une partie de l’anatomie humaine par exemple, que ce soit pour la formation des étudiants, la simulation de gestes chirurgicaux ou encore l’aide à la compréhension d’une pathologie et in fine du diagnostic.
Bien entendu, et c’est loin d’être le moins important, l’image de synthèse a envahi nos écrans au quotidien. On en trouve dans les effets spéciaux des films et des publicités, et aussi dans les jeux vidéo, qui ont été et sont encore un formidable accélérateur du domaine de la synthèse d’images, notamment grâce aux progrès réalisés par les fabricants de cartes vidéo pour nos ordinateurs.
Le processus
Comment obtient-on une image de synthèse d’un objet ? La première étape, dite de modélisation, consiste à décrire cet objet à l’aide d’une représentation non ambigüe, que l’ordinateur pourra utiliser pour effectuer ses calculs. Par exemple, si l’on veut visualiser un carré, il peut être représenté par les coordonnées de deux de ses sommets opposés. Comme cette représentation doit être parfaitement compréhensible par l’ordinateur, elle est composée de valeurs numériques et on la qualifie de modèle numérique. La deuxième étape, dite de synthèse (ou rendu), consiste à calculer l’image de l’objet à partir de son modèle, en exécutant un logiciel spécialisé. Par exemple, on obtient un carré en traçant avec l’algorithme de Bresenham 4 segments de droite qui relient les sommets du carré.
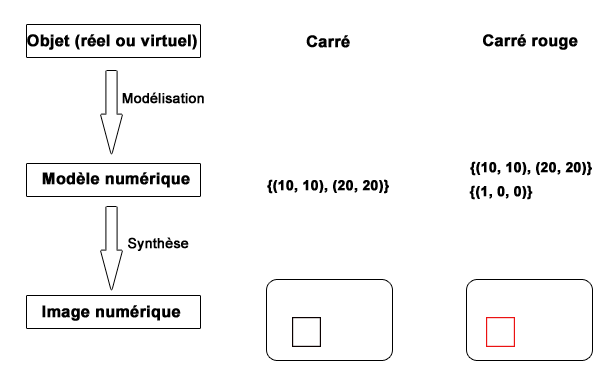
Notions d’objet, de modèle et d’image : exemples du carré.
Si l’on considère un environnement réel, il faut alors exprimer les coordonnées des sommets dans un espace 3D ; on parle ainsi d’objet ou de scène 3D et par extension, de synthèse 3D. Mais notons au passage que la notion d’image 3D n’a pas de sens : en effet, une image est affichée sur un support plan (la matrice de pixels de l’écran) et est donc toujours en deux dimensions.
Et puisque nous en sommes à considérer des expressions erronées, il en est une autre tout autant utilisée et tout aussi fausse : celle d’image virtuelle. En fait, une image numérique peut être vue comme une combinaison de pixels affichant une certaine couleur. Que l’on considère cette image avec un œil d’informaticien, d’électronicien ou d’opticien, on y verra respectivement des valeurs numériques, des potentiels électriques ou des signaux visuels, bref, des données parfaitement mesurables et réelles. Absolument aucune virtualité dans tout cela (voir l’idée reçue « Les ordinateurs produisent des images virtuelles »).
La modélisation
La plupart des objets ne sont malheureusement pas aussi faciles à décrire qu’un carré. On adopte alors souvent une démarche reposant sur la description de leur enveloppe extérieure. La plus courante consiste à produire une approximation de cette surface extérieure en la décomposant en un ensemble de petits polygones connectés par leurs sommets. Par commodité, on utilise des triangles.
La couleur de l’objet est une autre propriété qu’il faut prendre en compte pour obtenir des images de bonne qualité. De la même façon que la modélisation géométrique a permis de décrire sa forme, la modélisation colorimétrique va permettre de spécifier sa couleur. La représentation la plus utilisée repose sur le modèle RVB, qui associe à une couleur un triplet donnant les proportions de 3 couleurs : le rouge, le vert et le bleu.
L’étape de modélisation, tant géométrique que colorimétrique, est très longue dès lors que l’on veut représenter un objet ou un ensemble d’objets complexes. Concrètement, cette phase requiert des logiciels spécialisés appelés modeleurs (3D Studio Max, Maya, Blender, etc.), et surtout la compétence ainsi que le talent de spécialistes, parfois baptisés infosculpteurs. La qualité de l’image dépend donc en tout premier lieu de la qualité du modèle construit : si celui-ci est pauvre ou de mauvaise qualité, il sera impossible d’en obtenir une bonne image quelles que soient les performances du logiciel de rendu. C’est pour cette raison que les sociétés utilisant intensivement des images de synthèse investissent beaucoup de temps et donc d’argent dans cette étape de modélisation.
La synthèse
Pour visualiser un objet, il faut d’abord projeter les sommets de ses facettes sur la fenêtre plane de l’écran. Pour cela, on commence par effectuer un changement de repère : depuis le repère 3D dit réel, dans lequel ont été exprimées les coordonnées des sommets lors de l’étape de modélisation, jusqu’au repère 2D associé à la fenêtre de l’écran. C’est également dans cette phase que sont intégrées les règles de calcul de perspective. Rappelons que ces règles, édictées à la Renaissance, sont culturelles, elles dépendent de la civilisation occidentale et ne sont donc pas le seul mode de représentation de la réalité.
 |
 |
| À gauche, image en fil de fer ; à droite, la même image avec élimination des lignes cachées. Images : Vincent Lebret-Solet et Romain Vergne, équipe IPARLA (INRIA & Université de Bordeaux 1). |
|
Pour éviter des calculs inutiles, il est indispensable de vérifier que les points projetés sont bien inclus dans les limites de la fenêtre de l’écran. On réalise ainsi une opération de découpage éliminant les points extérieurs (clipping en anglais). Cette première phase permet d’obtenir des images en « fil de fer » (wireframe en anglais) qui furent longtemps produites avec les écrans vectoriels et qui sont encore parfois utilisées pour une visualisation préliminaire rapide d’une scène complexe.
La deuxième étape traite les occultations. En effet, dans le monde réel, nous ne percevons pas toutes les parties d’un objet : certaines sont masquées par l’objet lui-même ou par d’autres objets. Les techniques d’élimination de parties cachées ont pour objectif de simuler ces occultations. Parmi les plus célèbres, citons le Z-buffer ou l’algorithme du peintre.
Enfin, la troisième étape concerne le remplissage des facettes projetées. La première solution consiste à employer une couleur uniforme par facette (flat shading en anglais). Cette approche produit des images pauvres mettant en avant la décomposition en facettes, ce qui est rarement recherché. Cette mauvaise qualité est amplifiée par une propriété de notre système de perception que l’on appelle effet Mach. Ce défaut fut gommé par Henri Gouraud, un chercheur français, qui, pendant sa thèse avec Ivan Sutherland, développa une méthode publiée en 1971 et encore largement utilisée aujourd’hui : l’ombrage de Gouraud. Cette méthode est basée sur des calculs d’interpolation entre facettes voisines, de façon à ne pas créer de discontinuités visuelles.
 |
 |
| À gauche, éclairement constant ; à droite, éclairement avec ombrage de Gouraud. Images : Vincent Lebret-Solet et Romain Vergne, équipe IPARLA (INRIA & Université de Bordeaux 1). |
|
Une autre solution consiste à simuler l’éclairement réel des objets en prenant en compte les sources de lumière, les propriétés de réflexion des objets et les interactions locales entre lumière et matière. Bui Tuong Phong, un chercheur français lui aussi, publia en 1973 un modèle de calcul d’éclairement également encore très répandu aujourd’hui. Compte-tenu de la faible puissance des ordinateurs de cette époque, ce modèle n’était pas parfaitement exact du point de vue de la théorie physique mais, grâce à la créativité de son auteur, il produit une bonne impression visuelle.
C’est la succession de ces différentes étapes qui conduit aux images de synthèse que nous connaissons aujourd’hui. En franglais, on désigne par pipe (pour pipe-line) graphique cet enchaînement algorithmique.
Les animations
Jusqu’à présent, seuls les cas d’images fixes ont été évoqués. Pour les séquences animées, le principe est très simple : notre mécanisme de vision inclut un principe de persistance rétinienne. En effet, la perception d’une image reste présente dans notre cerveau pendant une durée courte. Si durant ce laps de temps, on peut lui afficher d’autres images, notre cerveau aura la sensation de percevoir un mouvement. C’est exactement sur ce principe que reposent le dessin animé et le cinéma.
Pour créer cette sensation de persistance rétinienne, la fréquence minimum d’affichage, mais surtout de calcul des images, est de l’ordre de 25 images par seconde. Mais pour des raisons de stabilité d’image et donc de confort pour l’utilisateur, on vise souvent des fréquences plus élevées, de l’ordre de 50 à 80 Hz. Par conséquent, l’ordinateur dispose au plus de 1/25e de seconde (souvent moins) pour calculer et afficher une image. Très courte, cette durée influe directement sur la complexité de la simulation du rendu et constitue le goulet d’étranglement le plus important des systèmes de rendu.
C’est pour cette raison que de nombreux travaux de recherche ont été entrepris afin de diminuer le temps de calcul d’une image. Dans le même ordre d’idée, on cherche à augmenter, à temps de calcul constant, la complexité de la modélisation, soit géométriquement, en augmentant le nombre de polygones traités par image, soit optiquement, en améliorant la complexité du modèle de rendu. Parallèlement à ces recherches algorithmiques, les performances ont évolué en bénéficiant des augmentations de puissance des processeurs et surtout des architectures graphiques spécialisées (cartes 3D), conçues principalement pour l’industrie du jeu vidéo.
 |
 |
 |
| À gauche, lancer de rayons ; au milieu, radiosité ; à droite, lancer de photons. | ||
Grâce à l’augmentation de la puissance de traitement et à la demande croissante de réalisme des utilisateurs, les chercheurs ont inventé de nouvelles méthodes de rendu, de plus en plus proches des modèles physiques. De façon non exhaustive, citons le lancer de rayons de Turner Whitted dès 1980, la radiosité de Michaël Cohen en 1985, le lancer de photons d’Henrik Jensen en 1996… On parle alors de photo-réalisme pour désigner des images qu’il est quasiment impossible de distinguer de photographies d’objets réels.
Le rendu crédible
Plus récemment, une autre voie de recherche s’est ouverte : puisque le cerveau demeure l’ultime « décideur », essayons de comprendre ce qu’il est vraiment capable de distinguer. Informaticiens et spécialistes des sciences cognitives se sont alors rencontrés pour étudier les relations entre rendu et perception. En d’autres termes, si une méthode de rendu consomme une grande partie du temps processeur pour calculer une contribution infinitésimale (la couleur de quelques pixels par exemple) dont le détail ne sera pas perçu par l’utilisateur, alors la méthode n’est sans doute pas adaptée. On est donc passé d’un unique critère de photo-réalisme à un nouveau critère de crédibilité.
Établissons une analogie avec un voyageur qui doit se déplacer entre deux villes distantes d’une centaine de kilomètres. S’il utilise un avion de tourisme, alors une photographie aérienne lui sera certainement très utile. S’il roule en voiture, alors une carte routière (au 200 000e) sera la plus adaptée pour la réalisation de sa tâche. Enfin, s’il se déplace en VTT en passant par de petits sentiers et en minimisant les dénivelés à affronter, une carte géographique précise (au 25 000e) lui permettra d’économiser ses efforts. Dans cet exemple, la photographie aérienne joue le rôle de l’image photo-réaliste, les cartes le rôle de l’image crédible. Il apparaît ainsi clairement qu’il n’existe pas une représentation meilleure que les autres, mais des supports mieux adaptés à certains contextes de réalisation de tâche.
Il existe de nombreux principes de rendu crédible dont certains sont très anciens. À travers les âges, les peintres ont inventé des styles de représentation autres que réalistes en jouant sur les motifs de base (pointillisme théorisé par Seurat), sur l’abandon des détails de contour, couleur ou contraste (impressionnisme de Monet ou Renoir) ou sur la symbolique (cubisme dont les initiateurs sont Picasso et Braque, abandonnant notamment les règles de la perspective issues de la Renaissance). Plus récemment, les dessinateurs de bande dessinée ont inventé leurs propres styles. Toutes ces écoles ont influencé les informaticiens qui en ont tiré des méthodes de rendu non photo-réalistes (NPR en anglais) dit aussi rendu expressif.

Le caméléon dans un style non photo-réaliste.
Image : Vincent Lebret-Solet et Romain Vergne, équipe IPARLA (INRIA & Université de Bordeaux 1).
Perspectives
En plus de cinquante ans, les images de synthèse ont beaucoup évolué, depuis les premières courbes alphanumériques jusqu’aux derniers effets spéciaux réalisés pour le cinéma. Grâce aux progrès réalisés, que ce soit dans les machines, les algorithmes, ou encore les usages, ces images se sont aujourd’hui infiltrées dans de nombreux secteurs. Il est donc important de connaître les principes de base de leur production pour mieux les appréhender, de se demander vers quelles nouvelles directions elles se dirigent et grâce à quelles nouvelles innovations elles seront produites.
D’un point de vue matériel, l’évolution des cartes graphiques (GPU en anglais) va-t-elle se poursuivre pour intégrer dans le silicium toujours plus de puissance de traitement et de possibilités de programmation ? Ou bien va-t-on revenir à des approches plus classiques, où les traitements sont réalisés dans des unités centrales (CPU en anglais) de plus en plus nombreuses dans des architectures multi-cœurs ?
D’un point de vue algorithmique, que va-t-il se passer après les formidables progrès des années 1990 aboutissant à un grand photo-réalisme dans les images ? Allons-nous continuer dans cette voie pour traquer les derniers bastions que sont les scènes naturelles (végétation, milieux aquatiques, ciel…) ? Ou bien allons-nous renforcer la démarche visant à traiter des scènes de plus en plus complexes, et donc volumineuses, notamment en prenant en compte les gigantesques masses d’information que produisent les procédés d’acquisition comme les scanners 3D ? Ou bien, l’alternative procurée par les méthodes de rendu expressif va-t-elle s’imposer dans un nombre croissant d’applications ?
Il y a là matière à grand nombre d’interrogations et ne doutons pas que de nombreux chercheurs vont continuer à se passionner et à s’impliquer dans ce domaine. Sutherland, Bresenham, Gouraud, Whitted… toute une série de pionniers de l’informatique graphique, qui ont révolutionné la synthèse d’images. Quels seront les noms suivants dans cette liste prestigieuse ? Il faudra patienter quelques années pour le savoir !
- J.E. Bresenham, Algorithm for Computer Control of a Digital Plotter, IBM Systems Journal, 4(1), 1965, 25-30
- M. Cohen & D.P. Greenberg, The Hemi-cube: A Radiosity Solution for Complex Environments, SIGGRAPH 1985, 31-40
- J. Foley, A. Van Dam, S.K. Feiner, J.F. Hughes, R.L. Philips, Introduction à l’infographie, Addison Wesley, 2000
- B. Gooch & A. Gooch, Non-PhotoRealistic rendering, A.K. Peters, 2001
- H. Gouraud, Continuous Shading of Curved Surfaces, IEEE Trabs. on Computers, C-20(6), June 1971, 623-629
- H.W. Jensen & N.J. Christensen, Photon Maps in Bidirectional Monte Carlo Ray Tracing of Complex Objects, Computers & Graphics, 19(2), March 1995, 215-224
- B. Peroche & al., Informatique graphique et rendu, Hermès, 2007
- B.T. Phong, Illumination for Computer Generated Pictures, CACM, 18(6), June 1975, 311-317
- T. Whitted, An Improved Illumination Model for Shaded Display, CACM, 23(6), June 1980, 48-65
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
