Génération automatique de textes
Visualisation de données météo qui se prêtent bien à la génération automatique d’un commentaire.
© Météo-France
Domaine de recherche qui s’occupe de la production de textes par la machine, la génération automatique de textes (GAT) fait partie du traitement automatique des langues (TAL). Elle forme le pendant de la compréhension automatique de textes, qui simule l’autre activité langagière des humains.
Un système de génération automatique de textes peut constituer une application autonome, comme nous l’illustrerons ci-dessous. Ou bien, il peut s’intégrer dans une application de dialogue homme-machine, de résumé de textes (après une phase de compréhension) ou encore de traduction automatique (pour générer le texte dans la langue choisie).
Des messages pré-enregistrés à la génération automatique de textes
Depuis qu’ils existent, les ordinateurs communiquent avec les utilisateurs. Et quoi de plus efficace que de parler à ces utilisateurs dans leur propre langue (pour nous, le français), que l’on appelle langue naturelle ? Pour cela, les ordinateurs disposent de messages pré-enregistrés qui sont affichés aux moments opportuns. Ils produisent ainsi des textes comme « Votre imprimante n’a plus de papier » qui s’affiche à l’écran après une commande d’impression.
Un exemple plus dynamique serait le message de votre banque, envoyé par courrier postal ou électronique, qui vous annoncerait : « Nous avons le regret de vous informer que votre compte est débiteur de 144 € et vous prions de l’approvisionner au plus tôt. » Ce message est produit automatiquement en complétant une « phrase à trou » par le nombre 144 extrait d’une base de données.
Les grandes entreprises ou administrations, qui envoient régulièrement des messages à leurs clients ou administrés – ainsi, La Redoute répond à plus de 10 000 lettres de réclamation par jour – personnalisent de tels messages. Pour cela, elles utilisent la fonction de publipostage proposée dans certains traitements de textes. Cette fonction fusionne un tableau construit avec un tableur et une lettre-type : les lignes du tableau correspondent aux différents clients, les colonnes enregistrent des informations sur ces clients, la lettre-type contient des variables et des conditionnelles. Voici une lettre-type correspondant à l’exemple du compte bancaire. Les variables sont introduites par le signe $ et les conditionnelles par %SI.
%SI $SEXE=F Chère/Cher $PRÉNOM $NOM, ¶
Nous avons le %SI $SOLDE<0 regret/plaisir de vous informer que votre compte est %SI $SOLDE<0 débiteur/créditeur de $SOLDE et…
Dans cet exemple, si le sexe est féminin, l’accord en genre sera réalisé sur chère. Le texte sera également adapté en fonction du solde. Si ce dernier est supérieur à zéro, le message contiendra « plaisir » et « créditeur », dans le cas contraire « regret » et « débiteur ».
Si le publipostage est beaucoup utilisé, ses limites sont évidentes. Tout d’abord, la lettre-type devient vite impossible à maintenir lorsque le tableau contient un grand nombre de colonnes correspondant à une multitude de cas. Ensuite, la technique du publipostage est inopérante dès qu’il s’agit, par exemple, de commenter intelligemment un tableau de chiffres, c’est-à-dire en évitant de produire un texte qui soit une simple concaténation de paragraphes, où chacun d’entre eux commente une ligne du tableau. Il faut alors faire appel à un système de GAT. La figure ci-dessous illustre un exemple de texte produit par le système EasyText qui commente les données numériques sur les investissements publicitaires des clients de la société Kantar Media. Pour commenter ce tableau dont les informations les plus pertinentes ne sautent pas aux yeux, utiliser une stratégie basée sur des textes à trous ne serait pas suffisant.
| EVOLUTION DES INVESTISSEMENTS PAR SECTEUR / VARIETE |
||||||||||||
| ANALYSE | Dans le secteur TELEPHONIE MOBILE, les investissements enregistrent une baisse respective de 22% et 31% pour les variétés OFFRES PREPAYEES et OFFRES ABONN.GRAND PUBLIC en mars 2009 par rapport à mars 2008. Par ailleurs, depuis le début de l’année, pour la variété OFFRES ABONN.GRAND PUBLIC, ils enregistrent une baisse de 10%. Toutefois, sur la même période, la variété OFFRES PREPAYEES a triplé ses investissements ( 198%). | |||||||||||
| Mars 2008 | SOV | Mars 2009 | SOV | Evol % | Cumul Janvier à Mars 2008 | SOV | Cumul Janvier à Mars 2009 | SOV | Evol % | |||
| TELEPHONIE MOBILE | 60 747 | 100,0% | 64 893 | 100,0% | 7% | 107 341 | 100,0% | 131 134 | 100,0% | 22% | ||
| OFFRES GRAND PUBLIC | 37 819 | 62,3% | 26 266 | 40,5% | -31% | 54 231 | 50,5% | 48 604 | 37,1% | -10% | ||
| OFFRES PREPAYEES | 1 952 | 3,2% | 1 519 | 2,3% | -22% | 4 979 | 4,6% | 14 857 | 11,3% | 198% | ||
| INTERNET | 3 331 | 5,5% | 9 775 | 15,1% | 193% | 8 570 | 8,0% | 14 575 | 11,1% | 70% | ||
| OFFRES PRO | 34 | 0,1% | 5 266 | 8,1% | 15 189% | 88 | 0,1% | 11 286 | 8,6% | 12 768% | ||
| MARQUE | 11 190 | 18,4% | 4 521 | 7,0% | -60% | 20 685 | 19,3% | 10 602 | 8,1% | -49% | ||
| FORFAITS BLOQUES | 745 | 1,2% | 6 592 | 10,2% | 785% | 995 | 0,9% | 9 258 | 7,1% | 831% | ||
| OFFRES ENTREPRISE | 931 | 1,5% | 8 638 | 13,3% | 828% | 5 678 | 5,3% | 8 907 | 6,8% | 57% | ||
| INSTITUTIONNEL | 2 467 | 4,1% | 1 212 | 1,9% | -51% | 9 320 | 8,7% | 7 455 | 5,7% | -20% | ||
| OFFRES SERVICE DE CONTENU | 2 277 | 3,7% | 1 078 | 1,7% | -53% | 2 440 | 2,3% | 5 041 | 3,8% | 107% | ||
| GAMME | 26 | . | 355 | 0,3% | 549 | 0,4% | 55% | |||||
De tels systèmes de génération ont été développés dans les domaines de la biologie, de l’aide en ligne, de descriptions d’itinéraires, de la météo, de la bourse, etc. Les textes générés sont principalement, mais non exclusivement, en anglais. Il existe de nombreux prototypes développés en milieu académique, beaucoup moins de systèmes opérationnels.
Comment fonctionne un système de génération automatique de textes ?
Son entrée (input) est un ensemble de données dont la forme est étroitement dépendante de l’application. Supposons, pour l’instant, que l’input soit un tableau de chiffres comme celui de l’exemple précédent. La première opération à effectuer consiste à répondre à la question « Quoi dire ? ». Il s’agit d’extraire du tableau de chiffres les faits saillants, par exemple les évolutions dépassant un seuil fixé. À ce stade, il est primordial d’écarter des informations non essentielles. Qui n’a jamais été importuné par une personne incapable de raconter une histoire de façon concise ? Cette opération, déterminante pour la qualité du texte généré, relève plutôt du domaine de l’Intelligence Artificielle et peut être réalisée par un système expert. Elle débouche sur un « message » représenté généralement sous forme logique.
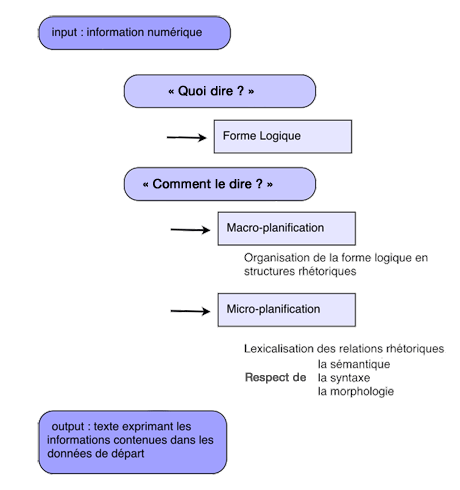
Représentation schématique d’un système de génération automatique de textes.
Il faut ensuite passer de cette forme logique à un texte rédigé dans la langue de l’usager (ou à plusieurs textes, rédigés en différentes langues). Autrement dit, il s’agit de passer de « Quoi dire ? » à « Comment le dire ? ». Ce passage en langue naturelle s’effectue en deux étapes : la macro-planification et la micro-planification.
Macro-planification
La forme logique est souvent une conjonction de nombreuses formules.
La macro-planification consiste à la rendre linéaire, de façon à former une séquence de phrases cohérente. On apprend à l’école qu’un texte, pour être compris, doit être bien structuré, enchaîner les idées de façon rationnelle et suivre une progression thématique. La modélisation de ces bons principes s’appuie sur des connaissances rhétoriques et pragmatiques qui ont été en partie formalisées ces dernières années. La macro-planification peut aussi s’appuyer sur des « schémas de textes ». Ces schémas sont établis en étudiant un corpus de textes écrits manuellement dans un but de communication similaire à celui du système de génération. Enfin, cette opération s’appuie sur des connaissances linguistiques qui émergent peu à peu, au fur et à mesure que les efforts de recherche sortent du cadre de la phrase pour aborder celui du texte.
Traditionnellement, le principal objet d’étude de la linguistique est la phrase. De ce fait, depuis des décennies, les linguistes ont développé des lexiques et des grammaires qui décrivent les contraintes observées au sein du domaine phrastique. Cependant, d’autres contraintes surgissent dès que l’on passe à l’enchaînement de plusieurs phrases en un texte cohérent.
Ainsi, considérons la distribution d’un adverbe temporel (à midi) dans un discours causal composé de deux phrases, l’une décrivant la cause, notée Pc, l’autre le résultat, notée Pr. Il s’avère que cette information temporelle peut figurer dans l’une ou l’autre phrase si l’ordre des informations est Pr Pc :
- Luc a fêlé la carafe à midi. Il l’a cognée contre l’évier.
- Luc a fêlé la carafe. Il l’a cognée contre l’évier à midi.
En revanche, elle ne peut figurer que dans la phrase de la cause si l’ordre des informations est Pc Pr :
- Luc a cogné la carafe contre l’évier à midi. Il l’a fêlée.
- Luc a cogné la carafe contre l’évier. Il l’a fêlée à midi.
En effet, le dernier énoncé a perdu toute interprétation causale (et devient même difficilement interprétable). Il faut donc établir des règles pour éviter de le générer.
Le résultat de la macro-planification est une suite de « schémas de phrase » reliés par des relations de discours. Les relations de discours (Explication, Résultat, Narration, Contraste, etc.) matérialisent le lien qui existe entre deux phrases successives, ou deux groupes de phrases. Ainsi, dans l’énoncé « Luc a quitté le 16e arrondissement. Son loyer était trop cher. » , les deux phrases sont reliées implicitement par Explication (la seconde décrit une explication à la première), tandis que dans l’énoncé « Luc est parti vivre à Barbès. Son loyer est moins cher. », elles sont reliées implicitement par Résultat (la seconde décrit un résultat de la première).
Micro-planification
La micro-planification commence par déterminer, pour chaque relation de discours, s’il est possible et nécessaire de la lexicaliser par un connecteur de discours, c’est-à-dire de lui associer un mot dans la phrase, qui peut être de type adverbial comme de ce fait ou ensuite ou bien de type conjonction comme parce que ou mais.
Ensuite, pour chaque schéma de phrase, il faut choisir les items lexicaux qui le composent, les constructions syntaxiques des verbes, les déterminants préfixant les noms, les positions respectives des compléments et adjoints, etc. Le but est d’aboutir à une phrase bien formée de la langue choisie. Il est donc primordial qu’un système de GAT repose sur des connaissances approfondies et précises en sémantique, syntaxe et morphologie. Même si on peut se contenter de générer des textes qui n’offrent pas toute la richesse de la langue (par exemple, exclure des textes générés des constructions impersonnelles passives comme Il s’est formé une congère), il est indispensable que les textes générés respectent toutes les règles linguistiques, jusque dans le moindre détail. Par exemple, la conjonction si est élidée uniquement devant les pronoms il et ils (s’il) et non pas devant tout mot commençant par une voyelle (s’elle est incorrect).
De plus, l’algorithme de micro-planification est complexe, car les décisions ne sont pas indépendantes d’une phrase à l’autre, entre autres pour respecter les contraintes de parallélisme entre phrases. Il est ainsi stylistiquement plus agréable d’enchaîner deux phrases dont les sujets sont les mêmes (coréférents), par exemple la phrase « Après le tirage au sort, Pete Sampras a choisi de recevoir » plutôt que « Après le tirage au sort, Pete Sampras a choisi que son adversaire serve ».
Peut-on parler de journalisme artificiel ?
Récemment a surgi aux États-Unis un système opérationnel, appelé Stats Monkey, mis au point par des chercheurs de NorthWestern University et commercialisé par la société Statsheet.
Ce système décrit en temps réel les événements marquants d’un match de baseball avec diffusion sur Twitter ou Facebook. Il s’appuie pour le « Comment le dire ? » sur des méthodes statistiques exploitant l’énorme masse de corpus décrivant des matchs de baseball.
Si cette méthode a certainement de l’avenir – comme en témoigne la transformation de Statsheet en une nouvelle compagnie, Automated Insights avec une levée de fonds de 4 millions de dollars – elle présente la restriction suivante : il faut qu’il existe au préalable des corpus de textes portant sur le même sujet (ici, un match de baseball). Elle est inopérante pour des applications de génération automatique de textes où aucun texte similaire n’existe car il aurait été trop coûteux d’en produire manuellement. C’est le cas notamment pour l’application EasyText présentée plus haut, où seule une méthode symbolique suivant l’architecture décrite ci-dessus est envisageable.
Ce système a fait grand bruit dans les médias, avec des titres comme : « L’ère des robots-journalistes » (Le Monde, 9/3/2010) ou encore « Who Needs Reporters When There’s Monkeys? » (NBC Chicago, 14/10/2009).
Ces titres ne sont pas sans rappeler « Naissance du journalisme artificiel », article paru dans Le Figaro dès 1985. Pourtant, en 25 ans, force est de constater que malgré tous les progrès technologiques, aucun journaliste ne s’est retrouvé au chômage à cause de la génération de textes ! Les systèmes de génération automatique parviennent à mettre en avant des informations pertinentes issues de grandes masses de données, qui seraient trop fastidieuses à étudier, mais ils ne remplacent pas le travail d’analyse économique ou politique qu’effectuent les humains. D’où viendrait l’input du système de génération capable de produire ce type d’analyse ?
Une première version de cet article est parue sous le titre « Écriture automatique » dans les Cahiers de l’Inria en partenariat avec la revue La Recherche, n°443, juillet-août 2010.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Laurence Danlos
Professeur émérite de linguistique informatique à l'Université Paris Cité jusqu'à son décès en 2024.