Idée reçue : La traduction automatique, on n’y arrivera jamais ?
Comment ça, on n’y arrivera jamais ? Mais ça marche déjà ! Des millions d’internautes demandent chaque jour la traduction de millions de pages à des « serveurs de traduction automatique » gratuits, comme ceux de Systran, Reverso, Google, ou au Japon Fujitsu, Toshiba, Nec, Oki…
Oui, bien sûr… mais ce n’est pas ce que je veux dire ! En fait, ça traduit n’importe comment !
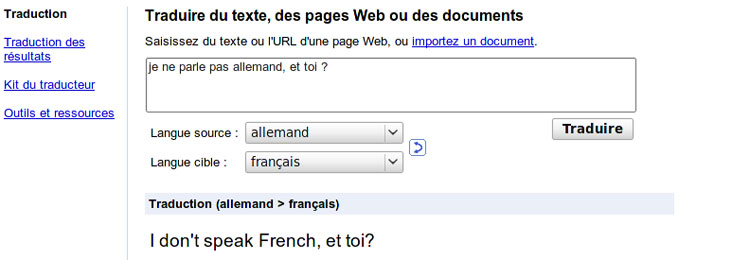
Eh bien, oui… mais que peut-on espérer ? Si on doit traduire de l’anglais vers le français « they saw many arms », comment savoir si c’est « ils scient de nombreux bras » ou « ils ont vu de nombreuses armes » ou « elles ont vu de nombreux bras », « elles [scient / ont vu] de nombreuses armoiries », etc. ? Bien des traducteurs humains, professionnels, font ainsi des contresens graves. En général, les textes qu’ils produisent respectent la grammaire, mais, au fond, cela contribue à « cacher » les contresens et faux sens ou omissions.
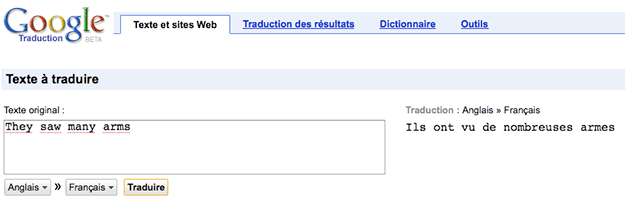
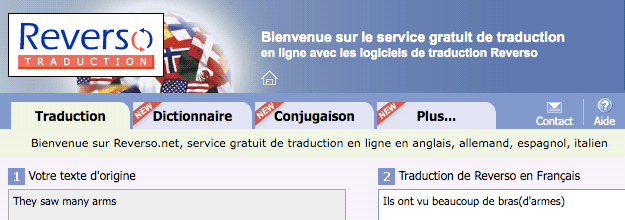
D’autre part, il s’agit de serveurs Web gratuits, dont le but est d’aider à comprendre « le mieux possible » des textes très divers dans des langues inconnues. Ils ne prétendent pas fournir des traductions parfaites, ni remplacer des traducteurs humains. Ce que ces serveurs fournissent peut cependant être considéré comme des « premiers jets », des « prétraductions », utilisables par des réviseurs plus experts pour produire des traductions finales de qualité professionnelle.
Mais il existe aussi des systèmes spécialisés, inconnus du grand public, qui traduisent extrêmement bien, et même mieux, et pas seulement beaucoup plus vite, que des traducteurs humains.
Vraiment ? Alors il s’agit de progrès récents, je n’en ai pas entendu parler !
En fait, ça date déjà de 30 ans. À Environnement Canada, le système TAUM-météo, qui devint METEO en 1985, fut lancé de façon opérationnelle le 24 mai 1977. Il a toujours été dédié au « sous-langage » des bulletins météo. Vers 1990, METEO traduisait 30 millions de mots par an, l’équivalent de 120 000 pages « standard ». La révision d’un bulletin traduit automatiquement prend moins d’une minute, environ 7 fois moins de temps qu’auparavant, lorsqu’il était traduit par un traducteur « junior ». C’est d’ailleurs l’un de ces traducteurs « juniors » qui était allé supplier le groupe TAUM (Traduction Automatique à l’Université de Montréal) de les délivrer de cette tâche ingrate. Cet exemple illustre aussi le fait que la traduction professionnelle est non seulement difficile, mais souvent pénible psychologiquement. Bref, ce système est équivalent à 17 traducteurs à plein temps depuis au moins 25 ans.
D’autres exemples peuvent être cités, dans le domaine des cours de la bourse, ou pour la traduction de documentations techniques.
Donc, les traducteurs humains peuvent effectivement être remplacés ! Ils ont raison d’avoir peur…
C’est vrai que beaucoup sont très réticents. Mais ils n’ont pas de quoi avoir peur, car en général ils ne sont pas en concurrence.
D’abord, aucun traducteur humain ne serait en mesure de produire en une seconde la traduction d’une page Web, même pas une traduction mot à mot…
Ensuite, bien des traducteurs professionnels utilisent en fait les systèmes de traduction automatique du commerce « configurables » (par choix des priorités de dictionnaires, insertion d’un « dictionnaire utilisateur »…) pour produire des prétraductions qu’ils peuvent ensuite post-éditer.
L’exemple de TAUM-météo montre d’ailleurs que, parfois, ce sont des traducteurs qui poussent à la construction d’un système de traduction automatique. Bien sûr, il faut ensuite les laisser utiliser ou non le système selon qu’ils décident qu’ils vont ou non gagner du temps avec lui.
Selon le niveau de qualité du premier jet, une simple révision suffit parfois, mais le plus souvent une post-édition est nécessaire. Il faut alors commencer par lire et comprendre la phrase à traduire avant de regarder la prétraduction proposée, afin de trouver comment la modifier pour obtenir le sens désiré.
Mais alors, s’il faut connaître la langue source, ça ne peut servir qu’aux bilingues !
Eh bien… oui et non ! Il y a plusieurs sortes de « traduction automatique », ou plus généralement de « traduction automatisée » ou « traduction assistée par ordinateur » (TAO), avec des buts bien différents. Classons-les par ordre de difficulté croissante pour les développeurs de systèmes :
- aider un vrai bilingue à produire des traductions de haute qualité en lui fournissant des « prétraductions » les plus utiles possibles, ainsi que des aides sous forme de dictionnaires ;
- aider quelqu’un à accéder à une information dans une langue qu’il ne connaît pas ;
- aider deux personnes n’ayant pas de langue commune à communiquer (par oral, ou par écrit, en tchat) ;
- aider une personne monolingue, ne connaissant pas ou très peu une langue étrangère, mais très bien le domaine en cause, à produire des traductions de qualité dans sa langue ;
- aider quelqu’un à produire des traductions de haute qualité dans une langue qu’il ne connait pas, en le « consultant » (dans sa langue) en cas de doute.
- aider une machine (eh oui!) à « comprendre » un texte : une façon de « porter » au français un système gérant des petites annonces SMS en arabe (CAT, à Amman, déployé sur Fastlink) est de « prétraduire » les SMS en arabe. 95% du contenu est récupéré.
Et qu’en est-il de l’aspect technique ? Comment fait-on pour construire de tels systèmes ?
Vous voulez donc savoir « comment ça marche » ? Allons-y. D’abord, il faut voir que, pour traduire par un programme une « unité de traduction », de quelque taille qu’elle soit (phrase, paragraphe, section, chapitre, document), on le fait en général en plusieurs étapes successives, chacune transformant une « représentation intermédiaire » en une autre.
La suite des représentations intermédiaires par lesquelles on passe, et leur détail, constitue l’architecture linguistique d’un système de traduction automatique.
Par exemple, voici schématiquement comment fonctionne l’« approche transfert multiniveau ».
Chaque segment source est d’abord lu et normalisé. L’étape suivante, de segmentation, produit une liste de mots orthographiques. Puis, l’analyse morphologique donne la structure morphosyntaxique de chaque mot, en indiquant les différentes possibilités. Ainsi, le mot « avions » donnerait [avoir, verbe, indicatif, imparfait, première personne, pluriel] et aussi [avion, nom, pluriel]. L’analyse grammaticale produit alors un arbre source « multiniveau concret ». Il peut contenir des fonctions syntaxiques, des relations logiques et sémantiques, des traits sémantiques… Sa correspondance avec la phrase est simple, en particulier l’ordre est respecté. Une étape d’abstraction le transforme ensuite en arbre ou graphe « abstrait » source. Il ne contient plus de « nœuds » correspondant aux auxiliaires, aux articles, aux balises de relief (italique, gras…), qui sont transformés en attributs), ni certaines ponctuations (parenthèses), représentées de façon structurale. L’ordre ne correspond plus forcément à celui de la phrase : par exemple, la particule séparable d’un verbe allemand le rejoint.
Vient à présent l’étape du transfert, qui produit un arbre ou graphe « abstrait » cible. La génération syntaxique le transforme en arbre cible « concret », de même nature qu’un arbre source concret. Dernière étape, la génération morphologique donne la suite de mots, séparateurs et ponctuations formant le segment cible.
Il est aussi possible de produire des traductions contenant des propositions multiples, ce qui revient à écrire un graphe avec des alternants, par exemple « [ils | elles] [ont vu | scient] de [nombreux bras | nombreuses armes]. »
On distingue ainsi les systèmes « directs », « semi-directs », « à transfert » (syntaxique de surface, profond, multiniveau, sémantique), et « à pivot » (hybride ou interlingue). Dans le cas d’un système à pivot interlingue, deux transferts sont nécessaires, de la langue d’origine vers le pivot, puis du pivot vers la langue de destination. Le pivot peut être basé soit sur une langue, par exemple l’anglais, soit sur un domaine restreint et un petit nombre de tâches.
Les techniques et ressources utilisées pour programmer les étapes réalisant le passage d’une représentation à une autre constituent l’architecture computationnelle d’un système de traduction automatique.
Une étape peut être réalisée avec une approche experte (par programmation directe, par automates, par règles de réécriture, par règles « statiques » de bonne formation, ou par programmation par contraintes), ou bien une approche empirique (statistique, ou par l’exemple). Ces approches empiriques sont les plus récentes.
Disons quelques mots des approches les plus récentes, dites empiriques. L’approche statistique consiste à supposer l’existence d’un espace probabilisable, et à calculer la sortie « la plus probable » correspondant à l’entrée à transformer. Les premiers systèmes de traduction automatique statistique fonctionnaient avec une architecture directe (au niveau des mots typographiques) ou semi-directe (en utilisant les mots et leurs catégories comme verbe, nom, adjectif, adverbe…). Actuellement, on passe par des représentations hiérarchiques en « fragments » (« chunks ») souvent appelés « groupes » (« phrases ») sans en avoir vraiment le statut linguistique.
Il est cependant tout à fait possible, comme l’a fait Microsoft Research entre 1997 et 2002, de construire un transfert complet à un niveau de syntaxe profonde en alignant 150 000 paires d’arbres (produits par analyse « experte » de segments source et cible provenant de documents techniques déjà traduits).
L’approche « par l’exemple » utilise directement les bi-segments d’un grand corpus bilingue. La taille des corpus nécessaires diminue avec la « préparation » associée. Pour la traduction automatique statistique destinée aux pages Web, comme GoogleTranslate, il faut au moins 50 millions de mots (dans chaque langue), soit environ 200 000 pages — qui ont nécessité autant d’heures de travail.
Enfin, on peut définir l’architecture opérationnelle d’un système de traduction automatique comme l’ensemble des conditions de sa construction, de son utilisation, de sa maintenance et de son évolution. Autant les deux architectures précédentes sont indépendantes l’une de l’autre, autant l’architecture opérationnelle peut influencer les deux autres. Les techniques et méthodes à employer peuvent donc largement dépendre du contexte de traduction. Par exemple, on peut avoir à traduire d’une seule langue dans beaucoup d’autres (cas de la traduction de documents techniques), ou bien depuis beaucoup de langues vers une seule (cas des militaires américains).
Les approches statistiques récentes ont-elles permis beaucoup de progrès ?
Il faut y regarder de plus près, et préciser ce qu’on entend par « progrès ». On peut maintenant « générer » un système de traduction automatique à partir d’un très grand corpus parallèle bilingue, formés de segments source et de leurs traductions (« segments cible »). Les systèmes de Google sont de ce genre, et ce sont pour l’instant les seuls utilisables pour aider quelqu’un à accéder à une information dans une langue qu’il ne connaît pas.
Tout le monde peut constater que GoogleTranslate fournit des traductions apparemment « fluides », mais, au moins à 30%, incompréhensibles, ou fausses, et surtout où des parties d’information ont disparu, alors que d’autres ont été introduites de nulle part. Des évaluations montrent qu’au contraire, les résultats de Systran et de Reverso (appelés un peu rapidement systèmes « à règles ») sont nettement plus « adéquats », en moyenne.
Oui, mais cela peut aussi être un bien. Ainsi, si un portier d’hôtel voit arriver un bon client, disons Monsieur Fischer, il lui dira en français :« Bonjour Monsieur », et pas : « Bonjour Monsieur Fischer », et encore moins : « Bonjour Monsieur Pêcheur ». Mais, en allemand, il devrait dire : « Guten Tag Herr Fischer », car « Guten Tag, mein Herr » serait plutôt impoli de sa part. Un système de traduction automatique, comme un traducteur humain, doit donc parfois utiliser de l’information absente du texte mais présente dans le contexte.
Pour traduire du japonais vers le français « Tanaka-san » pouvant signifier soit Monsieur Tanaka, soit Madame, il faut être capable de choisir entre les deux.
Du français vers le japonais, on aurait non seulement le même problème que vers l’allemand (insérer le nom de famille correct), mais il faudrait utiliser le bon niveau de politesse.
C’est vrai que la quasi-totalité des systèmes de traduction automatique opérationnels segmentent le texte source (ou la transcription obtenue par reconnaissance vocale) en « segments » correspondant idéalement à une phrase ou à un titre, puis les traduisent séparément. Certains systèmes font cependant un traitement global d’un document à traduire, par exemple pour essayer de déterminer le sens de certains mots ambigus en fonction de tous leurs contextes d’apparition.
Ainsi, si notre premier exemple (« they saw many arms ») parle aussi beaucoup de tanks, et d’observateurs, diverses techniques de « désambiguïsation lexicale » permettront de conclure qu’il y a beaucoup plus de chances qu’il s’agisse de voir des armes que de scier des bras. Mais si le contexte est de la médecine médicolégale, la décision sera inverse.
Finalement, qu’est-ce qui va marcher ?
À mon avis, le futur est lié à l’architecture opérationnelle. La voie à suivre, dès qu’on désire de la traduction de qualité, et qu’on ne peut à l’évidence pas payer des professionnels pour la faire, dans l’ensemble des couples de langues visés, est la TAO contributive externe. On entend par là qu’on remplacera le problème insoluble de la diffusion de traductions de qualité, très rapidement, et pour de nombreuses langues, par le problème soluble de la TAO pour l’accès multilingue. En profitant du contexte du Web, il s’agit de réaliser une « passerelle de traduction » fonctionnant presque comme celle de Google ou de Systran, mais :
- dédiée au sous-langage associé à un site ou à un ensemble de pages utilisé par une communauté donnée ;
- munie d’une mémoire de traduction et d’un lexique de termes et de locutions, tous deux multilingues et spécialisés au sous-langage en question ;
- offrant, depuis l’environnement de lecture d’un navigateur tout simple, l’accès « sans couture » à un environnement de post-édition muni d’aides « proactives » à la traduction ;
- associant différents « niveaux de qualité » et des « scores par défaut » aux producteurs de traductions.
Les contributeurs se voient attribuer un niveau en fonction de leur profil, et un score par défaut. Mais ils peuvent modifier le score qu’ils se donnent à eux-mêmes pour la traduction d’un segment.
Dans un premier temps, on peut utiliser des systèmes existants pour proposer des « prétraductions », ensuite révisées dans le contexte de lecture sur le Web par les lecteurs, transformés en contributeurs bénévoles. On peut aussi, quand rien n’existe pour un couple de langues, demander à des humains de traduire.
Dans un second temps, on pourra utiliser les données collectées à l’occasion des post-éditions pour construire des systèmes de traduction automatique, en choisissant leur architecture linguistique et leur architecture computationnelle en fonction de la situation et des ressources disponibles.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Christian Boitet