La traduction automatique statistique, comment ça marche ?
Le nombre de visiteurs uniques sur le Web a dépassé le milliard, la plupart d’entre eux étant chinois ou américains. Le volume des contenus publiés est lui aussi en forte augmentation. Pas étonnant, donc, que les internautes se trouvent souvent confrontés au besoin d’accéder à des informations non disponibles dans leur langue maternelle ! Le français, par exemple, est une langue bien moins représentée sur le Web que l’anglais. De nombreux contenus textuels sur le Web ne sont ainsi jamais traduits en français, principalement pour des raisons de coût humain et de temps. Avec un système de traduction automatique, l’accès à des traductions produites à la volée devient « gratuit » et instantané du point de vue de l’utilisateur. Pour les documents professionnels, les traducteurs humains peuvent également utiliser efficacement des systèmes de traduction automatique. La production du système est modifiée et corrigée par le traducteur humain. On parle alors de traduction assistée par ordinateur ou TAO.
Comment traduire ?
La traduction automatique utilise un dispositif informatique pour transcrire un texte d’une langue dite « source », dans laquelle est écrit le texte d’origine, vers une langue dite « cible », dans laquelle on souhaite obtenir une traduction. Pour traduire un texte d’une langue vers une autre, il faut avoir dans ces deux langues une très bonne connaissance de la grammaire, en particulier de la syntaxe, c’est-à-dire la structure des phrases, ainsi que de la sémantique, le sens des mots. Mais il est aussi nécessaire de connaître la culture implicite, les connotations, etc. L’objectif des systèmes de traduction automatique n’est pas de fournir une seule « bonne réponse », mais plutôt de produire des traductions compréhensibles et conservant le sens du texte d’origine.
Différentes approches ont été proposées, comme les systèmes de traduction fondés sur des règles ou sur des exemples. Actuellement, les méthodes les plus fréquemment utilisées pour la traduction automatique sur le Web sont les méthodes statistiques, les seules détaillées ici.
Traduction automatique statistique

La pierre de Rosette, conservée au British Museum. 3 écritures y figurent : en haut, des hiéroglyphes égyptiens, au centre, un texte en écriture démotique et en bas du grec ancien. Photo : Hans Hillewaert, Wikimedia Commons.
La traduction automatique statistique repose sur un corpus parallèle, c’est-à-dire un ensemble de textes en plusieurs langues, en relation de traduction mutuelle.
Historiquement, le corpus parallèle le plus connu est la pierre de Rosette. Cette pierre a été découverte en juillet 1799 par les soldats de l’armée de Napoléon Bonaparte, à côté de la ville de Rosette en Égypte. Il s’agit de l’une des plus célèbres stèles de l’Antiquité. Les textes qui y figurent racontent les honneurs du roi Ptolémée V sous la forme d’un « texte parallèle » en deux langues (le grec et l’égyptien) et trois écritures (égyptien en hiéroglyphes, égyptien en écriture démotique et alphabet grec). C’est l’étude de la pierre de Rosette qui permit à Jean-François Champollion d’apporter en 1822 la clé du déchiffrement de l’écriture hiéroglyphique, dont la connaissance était perdue depuis environ 400 après J.-C.
Dans un corpus parallèle, les alignements entre les textes mettent en relation différentes unités, qui sont des traductions mutuelles de différents niveaux : paragraphes, phrases, expressions et mots, l’alignement mot-à-mot étant le plus informatif. La figure ci-dessous est un exemple de corpus bilingue parallèle, qui contient des bi-phrases, c’est-à-dire des phrases en relation de traduction mutuelle, françaises et anglaises. Pour chaque bi-phrase, des alignements mot-à-mot indiquent la traduction des mots.
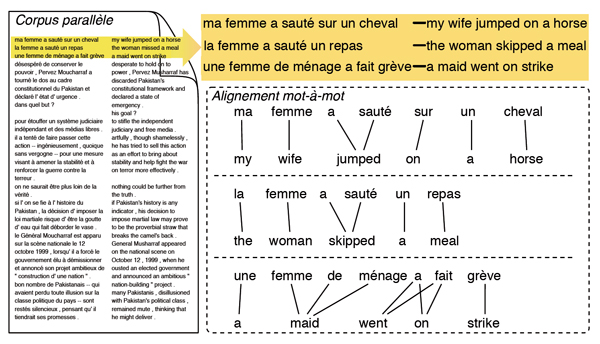
Corpus bilingue parallèle et quelques alignements mot-à-mot.
Un dictionnaire bilingue généralisé et probabilisé, qui contient des règles de traduction, est construit automatiquement à partir de ces bi-phrases. Le tableau ci-dessous est un tel dictionnaire pour traduire du français vers l’anglais.
| la | ||| | the | ||| | 0.6 | . . . |
| la | ||| | this | ||| | 0.4 | . . . |
| femme | ||| | woman | ||| | 0.5 | . . . |
| femme | ||| | wife | ||| | 0.5 | . . . |
| la femme | ||| | the woman | ||| | 0.6 | . . . |
| a femme | ||| | this woman | ||| | 0.4 | . . . |
| de | ||| | of | ||| | 0.6 | . . . |
| ménage | ||| | household | ||| | 0.8 | . . . |
| femme de ménage | ||| | maid | ||| | 1.0 | . . . |
| a sauté | ||| | jumped | ||| | 0.85 | . . . |
| a sauté | ||| | skipped | ||| | 0.15 | . . . |
| un repas | ||| | a meal | ||| | 1.0 | . . . |
| sauté un repas | ||| | skipped a meal | ||| | 1.0 | . . . |
| . . . | . . . | . . . | . . . |
Dictionnaire bilingue généralisé et probabilisé, construit automatiquement à partir d’un corpus bilingue parallèle.
Chaque ligne de ce tableau représente une règle de traduction, dont les éléments sont séparés par le symbole « ||| ». La première colonne correspond à un mot ou une séquence de mots en langue source (une unité source), la deuxième correspond à une séquence de mots en langue cible (une unité cible). Enfin, la dernière colonne est une série de modèles statistiques. En réalité, un système contient une série de scores. Notre exemple n’illustre qu’un seul de ces scores : le modèle de traduction. Ce score est utilisé pour évaluer les différentes traductions possibles d’une même unité source. Un score plus grand signifie que la traduction est plus probable. Par exemple, « la » a une probabilité de 0.6 (60% des cas) d’être traduit en the, alors que ce mot a une plus faible probabilité, de 0.4 (40% des cas), d’être traduit par this. La manière dont ces scores sont calculés sera décrite plus bas.
Lorsqu’une phrase est donnée à traduire à un système de traduction automatique statistique, elle est tout d’abord segmentée en unités telles que mots, séquences de mots et signes de ponctuation. Le système produit ensuite un ensemble d’hypothèses de traduction exploitant l’ensemble des règles présentes dans le dictionnaire bilingue pour traduire les unités reconnues. Sachant qu’il y a de nombreuses manières de découper la phrase source en segments (différentes segmentations), ainsi que de traduire chaque segment connu (différentes traductions), la procédure de construction des hypothèses produit une longue liste d’hypothèses de traduction (les candidats de traduction). Chaque candidat de traduction est associé à un score calculé à partir des scores du modèle de traduction et des autres modèles utilisés dans le système. L’hypothèse de traduction finalement retournée par le système est celle qui obtient le score maximal.
Traduction automatique fondée sur des mots
La première génération de systèmes de traduction automatique statistique utilisait une approche fondée sur des mots. Avec une telle approche, chaque mot reconnu dans une phrase à traduire est considéré comme une unité de traduction isolée et traduit seul. Cette approche pose plusieurs problèmes :
- Certains mots dans la phrase source ne peuvent pas être traduits seuls, il faut traduire tout le groupe. Par exemple, les mots composés et termes français suivants ne peuvent pas être traduits mot-à-mot en anglais : femme de ménage (traduit par maid en anglais), pomme de terre (potato), ordinateur portable (laptop), grand écran (widescreen), etc.
- La traduction obtenant le meilleur score n’est pas toujours la bonne. Ce problème est illustré par des mots français qui ont plusieurs sens comme sauter, qui désigne à la fois franchir par un saut et omettre quelque chose, qui selon le contexte se traduira donc en anglais par jump ou skip ; ou comme voler, dont le sens peut-être dérober ou se déplacer dans l’air. Ceci montre qu’il est nécessaire de prendre en compte le contexte pour traduire correctement des mots.
C’est en réponse à certaines de ces difficultés liées aux modèles fondés sur des mots que les modèles fondés sur des segments ont récemment été introduits.
Les modèles fondés sur des segments
Les unités de traduction considérées par ces modèles sont des segments de taille variable. Un segment peut être soit un mot, soit une séquence de mots contigus dans une phrase. La phrase en langue source est traduite segment par segment. Cette méthode possède de nombreux avantages :
- Elle permet de réduire les ambiguïtés lexicales. Par exemple, le mot anglais small est ambigu et peut se traduire par les mots français petit ou petite, mais small car ne l’est plus et a pour seule traduction petite voiture.
- Elle permet aussi de réduire les ambiguïtés sémantiques. Comme vu précédemment, le mot français voler est un mot polysémique et peut se traduire par le mot anglais fly ou steal, mais lorsqu’il est dans le segment voler de l’argent, cette ambiguïté disparaît.
- En autorisant des appariements entre groupes de mots, il permet de traduire les expressions idiomatiques très facilement.
En conséquence, le segment est l’unité de traduction utilisée dans les systèmes actuels. L’association entre un segment source et une traduction possible en cible forme un bi-segment. Notons qu’il est possible qu’un segment admette plusieurs traductions alternatives, donnant lieu à plusieurs bi-segments partageant le même segment source. Afin de distinguer les différentes traductions d’un segment source, il reste nécessaire d’associer des scores (des modèles statistiques) à chaque bi-segment. Dans le tableau présenté plus haut, chaque ligne présente un bi-segment avec son score associé, plusieurs segments cible peuvent partager le même segment source. Le modèle de traduction rassemble l’ensemble de ces informations.
Le problème qui se pose à présent est d’estimer ce modèle à partir d’un texte bilingue parallèle.
L’estimation des modèles
Disposant d’un corpus bilingue parallèle et des alignements mot-à-mot, il devient possible d’aborder les questions liées à la segmentation en unités de traduction et à l’estimation de chaque unité. Cette méthode se décompose en plusieurs étapes. Elle fait appel à des heuristiques, c’est-à-dire des démarches de résolution qui ne garantissent pas l’obtention d’une solution, ni son optimalité.
Heuristique de segmentation
Dans les systèmes de traduction actuels, on ne fait pas de segmentation préalable. Le système évalue en parallèle tous les segments possibles existant dans la phrase à traduire, qu’ils forment ou non une unité de sens. Dans les systèmes actuels, l’extraction des segments est limitée à une longueur maximale, en général égale à 7. Seront extraits les segments qui comportent un élément (uni-grammes), deux éléments (bi-grammes), trois éléments (tri-grammes)…, jusqu’à 7 éléments. Supposons qu’il faille traduire vers l’anglais la phrase suivante :
La femme de ménage a sauté, encore une fois, un repas.
Le système va considérer tous les segments possibles dans la phrase :
- uni-grammes : « La », « femme », « de », « ménage », …, « repas », « . »
- bi-grammes : « La femme », « femme de », « de ménage », …, « repas . »
- tri-grammes : « La femme de », « femme de ménage », …, « un repas . »
- etc.
Ensuite, pour chaque segment, le système cherche ses occurrences d’apparition dans un corpus parallèle français-anglais, et extrait la traduction à l’aide d’alignements mot-à-mot.
Heuristique d’extraction des bi-segments
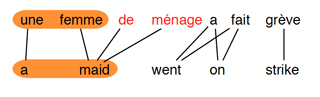
Extraction de bi-segments à partir des alignements mot-à-mot.
Un bi-segment peut être extrait si et seulement si tous les mots du segment source sont alignés avec ceux du segment cible, et vice versa. Par exemple, le bi-segment (une femme, a maid) ne peut pas être extrait, à cause du mot maid dans le segment cible, qui est aussi aligné avec de ménage qui ne figure pas dans le segment source. Par contre, le bi-segment (une femme de ménage, a maid) est cohérent.
À partir de cet alignement mot-à-mot, on peut aussi extraire d’autres bi-segments cohérents :
- femme de ménage → maid
- a fait → went on
- grève → strike
- a fait grève → went on strike
- …
Estimation du modèle de traduction
Après l’extraction des bi-segments, un segment est souvent associé à plusieurs traductions possibles (jusqu’à une vingtaine), donc chaque bi-segment doit être évalué par un score. En pratique, pour traduire une unité source, on préfère utiliser les traductions les plus souvent utilisées. Cela signifie que, plus souvent on voit une traduction, plus on tend à lui faire confiance. On utilise donc la fréquence relative comme score associé à chaque bi-segment. Par exemple, dans un corpus parallèle, on trouve 100 occurrences du segment source a sauté, dont 85 fois avec la traduction jumped (donc son score du modèle de traduction est 0.85) et 15 fois avec la traduction skipped (donc son score du modèle de traduction est 0.15).
Plus formellement, soit (s, t) un bi-segment extrait du corpus parallèle, où s représente le segment source et t le segment cible. On définit le modèle de traduction ainsi :
\[ \text{score de traduction} = \frac{C(s, t)}{\sum_{t’}C(s, t’)} \]
où \({C(s, t)}\) est le nombre de fois où le segment source s et le segment cible t sont extraits du corpus parallèle comme un bi-segment ;
\({\sum_{t’}C(s, t’)}\) est le nombre de fois où le segment source s est extrait du corpus parallèle avec tous les segments cibles.
Les bi-segments avec leurs scores de modèle de traduction et des autres modèles associés composent le dictionnaire généré pour cette phrase. Le système utilise ce dictionnaire pour traduire chaque unité dans cette phrase. Ensuite, comme il existe plusieurs possibilités de segmentation et de possibilités de traduction pour chaque segment, le système génère une liste de candidats de traduction. Chaque candidat de traduction est associé à un score qui est une combinaison du score du modèle de traduction et des nombreux autres modèles. Finalement, le candidat ayant le meilleur score est choisi comme la traduction de la phrase à traduire.
Les limites de la méthode
La figure ci-dessous montre deux résultats de traduction par Google Translate, qui est l’un des meilleurs systèmes à accès gratuit existants. Les zones jaunes indiquent les segmentations et les traductions correspondantes.
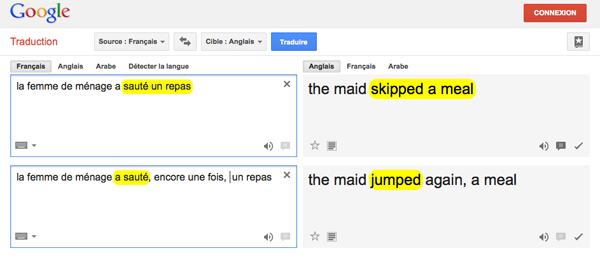
Traduction automatique par Google Translate (Recherches effectuées le 14 octobre 2013.)
On peut noter qu’il a bien traduit la première phrase, mais il se trompe sur le sens du segment a sauté dans la deuxième : le segment a sauté devrait être traduit par skipped dans les deux phrases. Dans la première phrase, sauté un repas est traduit ensemble comme un seul segment, le contexte local est inclus dans le segment. Dans ce cas, l’ambiguïté du mot sauté disparaît. Par contre, dans la deuxième phrase, le mot sauté est séparé de son contexte un repas, qui se retrouve plus loin (et de local devient global). Le segment a sauté est ambigu et le système ne peut que choisir la traduction dont le score du modèle de traduction est le plus grand.
Pour corriger cette erreur, il faut trouver une façon de prendre en compte les informations contextuelles éloignées (le contexte global). Or, dans les systèmes actuels, les scores des modèles sont calculés sur un texte bilingue parallèle fixé une fois pour toutes, qui ne change pas selon le contexte global de chaque nouveau texte à traduire. Les segments peuvent aider à prendre en compte le contexte local lors de la traduction, mais cela ne suffit pas. Un système qui utilise des corpus parallèles du domaine politique pour traduire une recette de cuisine, ce n’est pas approprié !
L’adaptation au domaine
La performance d’un système de traduction automatique statistique dépend considérablement de la qualité du corpus parallèle qu’il utilise. La plupart des corpus parallèles proviennent du domaine politique ou juridique, par exemple les retranscriptions des débats du parlement européen, ou des documents produits par l’Organisation des Nations Unies, qui sont dès l’origine traduits en plusieurs langues. Les journaux multilingues sont aussi une source très riche : de nombreuses publications au Canada fournissent des corpus anglais-français ; de même, à Hong Kong, certains journaux sont des sources de corpus chinois-anglais. Or ces données sont souvent inappropriées pour traduire un texte d’un domaine particulier. C’est pourquoi de nombreuses équipes travaillent à introduire dans le système les connaissances qui se rapportent au domaine du texte à traduire, afin que le système s’adapte à ce domaine.
Une méthode souvent utilisée pour l’adaptation au domaine est d’opérer une sélection des données d’apprentissage. Pour un texte à traduire, au lieu d’estimer les scores des modèles de traduction sur tous les textes du corpus parallèle, le système estime les scores seulement sur un sous-corpus sélectionné. La sélection est fondée sur leur similarité au texte à traduire. Les textes les plus similaires sont sélectionnés et utilisés pour estimer les scores des modèles de traduction. De cette manière, les scores des modèles de traduction vont s’adapter au texte à traduire.
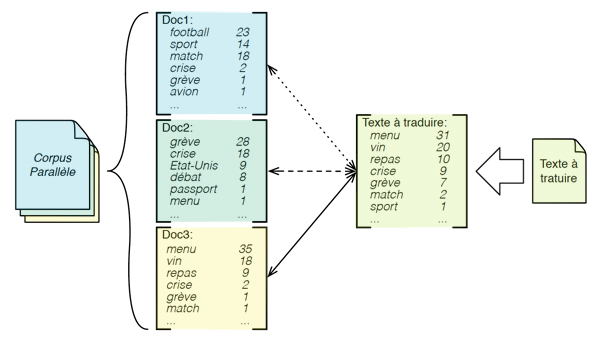
Adaptation au domaine du texte à traduire. Chaque document dans le corpus parallèle est représenté par un « sac de mots ». On remarque très facilement que parmi les 3 documents, le « Doc3 » est le plus similaire au texte à traduire. Les mots vin, menu et repas y figurent de nombreuses fois. Ensuite, c’est le « Doc2 », selon le « sac de mots », qui parle plutôt de sujets politiques : la crise, les grèves, etc. ; le texte à traduire en parle aussi. Enfin, le « Doc1 » parle beaucoup de sport (les matchs de football), alors que le texte à traduire en parle très peu (voire pas du tout).
Par exemple, comment traduire le mot volent dans la phrase Les oiseaux volent dans l’air ? Comme la plupart des corpus parallèles sont du domaine politique ou juridique, voler est souvent utilisé avec le sens dérober et la traduction en anglais est steal. Si les scores des modèles de traduction sont estimés sur tous les corpus parallèles, le système va favoriser cette traduction. Par contre, si l’on peut identifier des textes qui sont similaires à la phrase à traduire, on privilégiera plutôt le domaine animalier ou des voyages, où le mot voler a le sens se déplacer dans l’air, qui est correct ici. On peut sélectionner les textes similaires et construire un sous-corpus, et estimer les scores des modèles de traduction uniquement sur ce sous-corpus. Dans ce cas, le système va probablement favoriser le mot anglais fly comme traduction du mot volent dans cette phrase. Mais si la sélection de données est fondée sur une mesure de similarité, quelle est la mesure utilisée pour évaluer la similarité thématique entre deux documents ?
Mesure de similarité entre documents
On suppose que le contenu d’un document est bien représenté par les mots qu’il contient. Chaque document est représenté par un « sac de mots », où est comptée la fréquence de chaque mot qu’il contient. La fréquence d’un mot représente son importance dans le document. La similarité entre deux documents porte sur la similarité de l’utilisation des mots et la fréquence de ces mots dans les documents.
Plus formellement, chaque document peut être représenté par un vecteur (Vdoc) qui a pour longueur la taille du vocabulaire (s). Chaque composante du vecteur (V i doc où 0≤i≤s) représente un mot dans le vocabulaire, dont la valeur correspond à l’importance de ce mot, par exemple sa fréquence. Les mots qui n’apparaissent pas dans le document ont une importance 0. Alors la similarité entre deux documents est calculée selon la formule suivante :
\[ \text{similarité}=\frac{V_{docA}\cdot V_{docB}}{\|V_{docA}\|\|V_{docB}\|}\label{eq:similarite} \]
où : \({V_{docA}\cdot V_{docB}}\) est le produit scalaire des deux vecteurs ;
\({\|V_{docA}\|\|V_{docB}\|}\) est le produit des longueurs des deux vecteurs.
Avec cette mesure, on peut calculer la similarité entre tous les documents. Si deux documents partagent beaucoup de mots importants en commun, le score de similarité entre eux est plus grand. Néanmoins, chaque document contient toujours beaucoup de mots-outils, par exemple : de, le, la, qui sont moins informatifs que les mots lexicaux, mais toujours plus fréquents. Avec cette méthode, les mots les plus importants pour chaque document sont souvent les mots-outils, ce qui rend le calcul de la similarité moins informatif ! On a donc besoin d’une mesure de l’importance plus intelligente.
La TF-IDF (Fréquence du terme-Fréquence inverse de document ou en anglais Term Frequency-Inverse Document Frequency) est une telle mesure qui permet d’évaluer l’importance d’un terme (un mot ou un segment) contenu dans un document, relativement à un corpus. Le poids augmente proportionnellement au nombre d’occurrences du terme dans le document. Il varie également en fonction de la fréquence du terme dans le corpus.
La fréquence du terme (TF) est le nombre d’occurrences d’un terme dans le document considéré, étant normalisé par la somme des nombres d’occurrences de tous les termes du document. En effet, l’importance d’un terme dans un document peut être justifiée partiellement par son nombre d’occurrences, mais ce n’est pas suffisant. La normalisation effectuée rend valable la comparaison de deux documents de longueurs distinctes.
Soit le document dj et le terme ti, alors la fréquence du terme dans le document est :
\[ tf_{i,j} = \frac{n_{i,j}}{\sum_kn_{k,j}} \label{eq:TF} \]
où \({n_{i,j}}\) est le nombre d’occurrences du terme ti dans le document dj.
Le dénominateur est le nombre d’occurrences de tous les termes dans le document dj.
La fréquence inverse de document (IDF) est une mesure de l’importance du terme dans l’ensemble du corpus. Dans le schéma TF-IDF, elle vise à donner un poids plus perceptible aux termes les moins fréquents, considérés comme plus discriminants. Elle consiste à calculer le logarithme de l’inverse de la proportion de documents du corpus qui contiennent le terme.
\[ \text{IDF} = \log\frac{|D|}{|\{d_j : t_i \in d_j\}|}\label{eq:idf} \]
où \({|D|}\) est le nombre total de documents dans le corpus ;
\({|\{d_j : t_i \in d_j\}|}\) est le nombre de documents où le terme ti apparaît.
Avec cette mesure, l’importance d’un mot dans un document dépend à la fois de sa fréquence dans le document et du nombre de documents du corpus qui le contiennent. La fréquence du terme sert à identifier les mots importants pour le document considéré, mais en même temps, il inclut aussi les mots-outils qu’il faut enlever. La fréquence inverse de document sert à identifier ces mots-outils. En effet, les mots-outils apparaissent dans tous les documents, donc leur score IDF est très faible. En combinant les deux, on peut alors identifier les mots importants pour un document considéré. On peut alors remplacer la fréquence par TF-IDF dans le vecteur du document (Vdoc) et calculer la similarité avec la formule présentée plus haut.
Par cette méthode, en sélectionnant dans le corpus parallèle les documents présentant la meilleure similarité thématique avec le texte à traduire, on augmentera les chances de choisir la traduction la plus appropriée pour chacun des termes importants du texte.
Perspectives de recherche
Si l’on souhaite développer des systèmes capables de traduire n’importe quel document, indépendamment de la langue, plusieurs difficultés apparaissent. Une première relève de la phase de préparation du système : la définition des corpus parallèles entre la langue source et la langue cible. Si pour les langues principales (anglais, chinois, espagnol, français, arabe…) il est possible d’en obtenir au travers des organismes internationaux qui produisent de la documentation multilingue, il devient nécessaire de la produire spécifiquement pour de nombreuses langues minoritaires ou régionales. Un des grands enjeux se situe notamment autour des dialectes arabes qui diffèrent de l’arabe littéral. La production de ces données nécessite une intervention humaine importante et de nombreux pré-traitements. Ces deux aspects la rendent particulièrement coûteuse et expliquent qu’elle ne soit pas être systématique.
Par ailleurs, il ne suffit pas d’avoir un corpus d’entraînement dans les deux langues choisies, il faut également que le domaine soit proche de celui du document à traduire. Et même s’il était possible d’avoir des corpus parallèles pour les langues principales, cette spécialisation du thème du contenu limite les utilisations. Il n’en reste pas moins que cette approche apporte un cœur de système prometteur. On envisage de l’utiliser dans des applications déterminant automatiquement le domaine de connaissances du document, puis d’extraire les données nécessaires depuis le Web afin d’augmenter la qualité de la traduction, ou encore de coupler ce système avec un analyseur et un générateur de parole pour proposer des applications de traduction en temps réel, intervenant directement dans nos conversations sur mobile.
L’une des grandes questions théoriques actuellement ouvertes reste l’hybridation des approches numériques avec les approches symboliques, ce qui permettrait aussi d’améliorer la qualité des résultats proposés. Ces questions théoriques restent à étudier mais on constate déjà que la traduction statistique fournit des résultats largement déployés et utilisés sur le Web.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Li Gong