Les réseaux pour le calcul haute performance : facteur, livreur ou déménageur ?

Le supercalculateur IBM BlueGene/P Intrepid du laboratoire national d’Argonne est constitué de plus de 160 000 processeurs interconnectés par différents réseaux dont un en tore à 3 dimensions. Argonne National Laboratory / Photo prise le 10 décembre 2007.
Argonne National Laboratory / Photo prise le 10 décembre 2007.
Le calcul haute performance (HPC) est utilisé pour résoudre de très gros problèmes de simulation numérique, par exemple les prévisions météorologiques ou l’étude de l’aérodynamique du fuselage des avions.
Les supercalculateurs sont constitués de nombreux processeurs, reliés par des réseaux de télécommunication où circulent les données à traiter et les résultats des différents calculs intermédiaires. Lorsqu’il s’agit de dizaines ou de centaines de milliers de processeurs, le réseau doit être performant pour éviter de ralentir l’ensemble. Comment les technologies réseau se sont-elles adaptées à ces besoins titanesques ?
Les facteurs du réseau Internet
Avec le développement de l’Internet depuis les années 1970, les réseaux d’interconnexion ont peu à peu maillé toute la planète. Les protocoles qui nous permettent aujourd’hui de communiquer depuis notre salon vers de nombreux services web en ligne ont été conçus dans les années 1980, en particulier IP et TCP. Les messages envoyés sont découpés en morceaux, qu’on appelle des paquets (généralement de quelques milliers d’octets), comme si un gros dossier était découpé et envoyé dans plusieurs petites enveloppes. L’avantage est que n’importe qui peut manipuler ces enveloppes, alors qu’un facteur ne peut pas forcément manipuler un colis de 100 kg tout seul ! Par contre, certaines enveloppes peuvent se perdre en chemin, ou arriver dans le désordre. Le destinataire devra donc passer un peu de temps à réarranger le dossier final.
Sur Internet, les paquets circulent à travers différents intermédiaires qui les dirigent vers le suivant, dans un réseau parfois très compliqué, jusqu’à la destination finale.
Chaque paquet traverse différents équipements réseau intermédiaires, notamment les commutateurs souvent appelés switchs ou routeurs. Ces équipements les envoient un par un à l’intermédiaire suivant sur le chemin à travers le réseau, de la même manière qu’un courrier papier transite par plusieurs centres de tri de la Poste. Ainsi, lorsqu’on accède à une page Interstices depuis chez soi, les paquets sortent de notre ordinateur par une carte réseau, puis ils vont par exemple traverser une box internet, un central téléphonique local, un central du fournisseur d’accès internet, et enfin atteindre un serveur qui héberge le site Interstices.info.
De nombreux travaux ont permis d’améliorer ces communications réseau, par exemple en définissant comment contourner les problèmes sur le long trajet à travers l’Internet (panne, bouchon, etc). Mais s’adapter aux réseaux récents est difficile car le débit a considérablement augmenté (plus de 1000 fois) depuis la conception de ces protocoles, tandis que la taille des paquets a peu évolué. Remplir un gros tuyau avec plein de petits paquets demande de manipuler très vite ces paquets !
Les facteurs des réseaux HPC
Une idée pour améliorer les performances des communications a été d’accélérer le traitement des paquets dans les centres de tri. Le routage par la source consiste par exemple à écrire directement sur l’enveloppe d’un message quel chemin il devra prendre jusqu’à sa destination. Les centres de tri intermédiaires peuvent donc directement le faire suivre sans avoir à chercher quelle est la destination suivante. Sur Internet, cette idée est inapplicable, car chaque machine connectée devrait connaître l’état de l’Internet tout entier pour savoir comment contacter toute autre machine, et savoir si certains routeurs intermédiaires (appartenant à différents pays et entreprises…) sont en panne, etc. Par contre, cette solution fonctionne bien dans un supercalculateur, car le réseau y est très bien maîtrisé (il est entièrement géré par une seule équipe d’administrateurs), on peut donc facilement calculer à l’avance tous les chemins entre tous les processeurs.
La principale plainte du HPC vis-à-vis des réseaux de communication est qu’ils consomment du temps de calcul : il faut un processeur pour découper les messages en paquets côté émetteur et les ré-assembler dans l’ordre côté récepteur, et également pour vérifier qu’ils n’ont pas été corrompus en route. Un programme communiquant sur le réseau va donc passer du temps à réaliser ces communications, au lieu d’utiliser ce temps à calculer. Vu ce que coûte un supercalculateur en électricité, climatisation, aménagement du bâtiment et personnel, ce « gâchis » est peu satisfaisant.
Idéalement, on souhaite qu’un processeur puisse indiquer qu’il veut envoyer ou recevoir quelque chose, puis directement retourner faire ses calculs pendant que le réseau effectuerait le transfert demandé. On parle alors de recouvrement (overlap) des communications par le calcul. Mais si le processeur ne traite pas la communication lui-même, il faut que quelqu’un d’autre s’en occupe. C’est le rôle des cartes réseau améliorées utilisées dans les supercalculateurs, on peut y déporter le traitement intégral des envois et réceptions (on parle d’offload). Si on dit parfois que les supercalculateurs sont un assemblage de matériel standard, ce n’est pas complètement vrai : cet assemblage se base sur un matériel réseau haute performance dédié au HPC.
Du facteur au livreur
Les supercalculateurs bénéficient d’un matériel réseau spécifique, qui permet d’améliorer les performances des communications afin de moins ralentir les calculs. Au niveau logiciel, de nouveaux protocoles ont été spécialement conçus pour mieux répondre aux besoins du HPC. Les applications parallèles n’utilisent pas les protocoles TCP/IP comme sur Internet, mais plutôt l’interface de communication MPI (Message Passing Interface) qui impose moins de contraintes et peut donc mieux s’adapter à la technologie réseau disponible dans chaque machine.
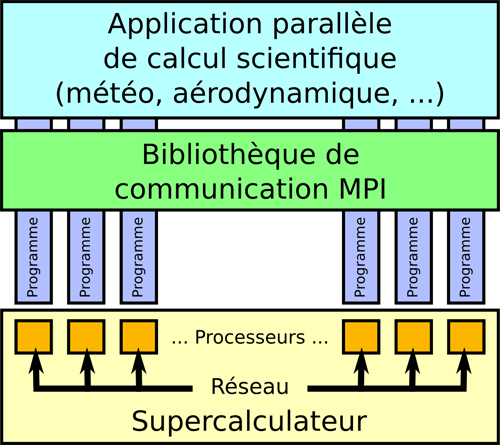
Les applications parallèles utilisent de nombreux processeurs simultanément en faisant collaborer différents programmes via une bibliothèque de communication.
La technique habituelle pour envoyer un message sur un réseau de télécommunication consiste à déclarer une boîte à lettres. Quand un message arrive, la carte réseau le dépose dans la boîte et le programme récepteur peut venir le chercher quand il le souhaite. Premier problème pour le calcul haute performance, le programme récepteur veut parfois récupérer le message le plus rapidement possible, car il en a besoin pour continuer ses calculs. Dans ce cas, il va rester devant la boîte jusqu’à l’arrivée du facteur. Cette technique, appelée Scrutation, est bonne pour la réactivité (le programme sait immédiatement quand le message arrive) mais mauvaise pour le calcul (car le programme ne fait qu’attendre l’arrivée du message au lieu de calculer). C’est donc une stratégie uniquement adaptée quand le programme récepteur sait que le message ne va pas tarder à arriver.
Si, par contre, on ignore quand le message doit arriver, on peut envisager d’alterner de petites phases de calcul et une surveillance de la boîte à lettres. L’autre solution consiste à faire un envoi recommandé, afin que le facteur nous prévienne lorsqu’il apporte le message. En informatique, la carte réseau va déclencher une Interruption, une sorte de signal électrique immédiatement reçu par le processeur, qui pourra donc aussitôt prévenir le programme récepteur. Cette stratégie est efficace, mais demande plus de travail de mise en place, elle n’est donc rentable que si le message n’arrive pas immédiatement.
Enfin, il existe des stratégies adaptées spécifiquement pour les grands messages (plusieurs centaines de kilooctets ou plus). L’idée est qu’un gros colis ne peut pas tenir dans une boîte à lettres. Si le facteur laisse un avis de passage, le destinataire ne pourra pas recevoir le colis avant le lendemain, et le facteur l’aura déplacé pour rien. Sinon, le facteur pourrait le laisser chez le concierge, mais cela impose au destinataire de le déplacer lui-même jusqu’à son domicile. En informatique, on parle de copie mémoire : le message peut être reçu dans une zone mémoire temporaire puis copié dans la zone de destination dans le programme récepteur, mais de telles copies gaspillent du temps processeur. Il vaut donc mieux prendre rendez-vous à l’avance pour que le livreur dépose directement le colis au domicile en présence du destinataire. Ce protocole, également appelé Rendez-vous en informatique, est très utile pour les gros messages, car il évite une copie intermédiaire. Mais il doit être évité pour les petits messages, car la prise de rendez-vous préalable augmente le délai global de livraison.
Du livreur au déménageur
Le modèle du rendez-vous est important en HPC, car les gros messages sont assez courants. Mais les interfaces de communication du HPC comme MPI permettent par ailleurs d’effectuer des communications réseau où un programme va aller directement lire ou écrire dans la mémoire d’un autre, ce qu’on appelle RMA (Remote Memory Access). Dans ce cas, on ne fait plus appel au facteur, ni à un livreur, mais à un déménageur qui va directement prendre les colis dans un domicile et les livrer dans un autre. Les technologies réseau dédiées au HPC, en particulier InfiniBand, implémentent de telles fonctionnalités dans les cartes réseau, permettant au transfert de données d’être effectué pendant que les processeurs continuent de calculer.
Les RMA ont un coût d’organisation important, puisqu’il faut déclarer à l’avance les zones qui vont pouvoir être lues ou modifiées par les autres programmes à distance, comme un déménageur à qui il faut donner les clefs, montrer les cartons à prendre et indiquer où les déposer chez le destinataire. Mais une fois le RMA démarré, le client n’a plus rien à faire, il peut aller travailler normalement. Et quand le déménageur signale qu’il a fini le transfert, les données sont immédiatement disponibles, à l’endroit où on en a besoin. Dans le cas des RMA, on peut même considérer que le déménageur s’est occupé de faire et défaire les cartons pour directement ranger les objets sur la bonne étagère.
Choisir entre les stratégies, un casse-tête pour les chercheurs
Le HPC dispose donc de nombreuses stratégies pour communiquer entre les différents programmes dans les applications parallèles. La difficulté est alors de choisir. Les bibliothèques logicielles qui implémentent MPI (par exemple MPICH ou OpenMPI) peuvent choisir parmi ces stratégies, mais elles ont besoin de beaucoup d’aide pour faire le bon choix.
Les choses sont encore plus compliquées avec les supercalculateurs actuels, qui sont constitués de milliers de serveurs, chacun de ces ordinateurs contenant plusieurs processeurs multicœurs. Ainsi, lors des derniers classements Top500 des plus gros supercalculateurs du monde, en juin et en novembre 2013, le plus puissant était chinois et contenait plus de 3 millions de cœurs. Avec ces processeurs multicœurs, on peut exécuter plusieurs programmes sur chaque ordinateur. Les applications parallèles du HPC ne s’en privent pas, elles utilisent tous les cœurs disponibles, et donc souvent une dizaine par ordinateur, sur des milliers de machines.
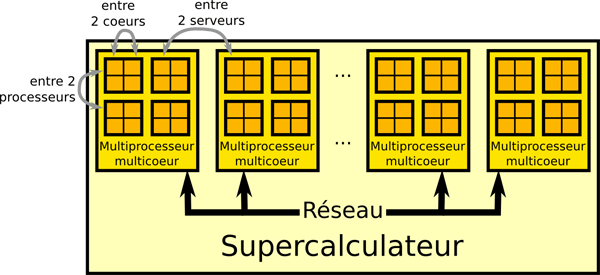
Les supercalculateurs actuels sont constitués de milliers de serveurs reliés par un réseau. Ces serveurs sont des ordinateurs multiprocesseurs, chaque processeur étant multicœur.
Les programmes peuvent donc communiquer avec des voisins situés sur un autre cœur du même processeur, un autre processeur du même serveur, ou un processeur d’un autre ordinateur via le réseau. Évidemment, deux cœurs de la même machine ne vont pas passer par un centre de tri externe pour échanger des messages, des stratégies internes plus rapides ont été conçues. Mais ces communications internes présentent le même problème que pour le réseau de communication entre ordinateurs : plusieurs stratégies coexistent, avec leurs avantages et leurs inconvénients. Comment décider laquelle sera la meilleure pour chacun des échanges ?
La décision dépend tout d’abord de la puissance du matériel. Suivant la puissance relative des processeurs et du réseau, certaines solutions vont devenir plus avantageuses. Mais cette puissance est difficile à évaluer de nos jours, et elle dépend de ce que font les voisins. Ensuite, cela dépend de la distance entre l’émetteur et le destinataire, ainsi que des affinités entre processeurs et cartes réseau. Enfin, il faut regarder ce que l’application souhaite faire par la suite. On peut prendre du temps pour trouver la bonne stratégie, mais il faut que ce temps passé à réfléchir soit inférieur au temps que cette stratégie va nous faire gagner au final. Parfois, ce n’est rentable que si l’application réutilise cette décision plusieurs fois. Mais comment le savoir à l’avance ? La recherche dans le domaine consiste notamment à permettre au programme d’indiquer ce genre d’information aux bibliothèques. Mais il ne faut pas imposer aux développeurs d’applications parallèles (souvent des scientifiques d’autres domaines) de comprendre toutes les subtilités des réseaux. L’autre solution consiste à permettre aux bibliothèques de deviner, voire de prédire le futur, en observant le comportement du programme.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
