Internet, le conglomérat des réseaux
Ce document vise essentiellement à donner une idée des principes de base du fonctionnement de l’Internet. Il aborde notamment la façon dont y sont acheminées les données, comment est identifiée la destination d’un envoi de données (quelle est son adresse ?), les problèmes liés à la croissance de l’Internet, et quelques aspects de son utilisation courante.
1. Circulation de l’information
Comment les données circulent-elles dans l’Internet ?
Ce qui circule : des paquets
Dans un réseau, l’information qui circule est découpée en unités élémentaires appelées paquets. Il s’agit d’une suite d’octets suffisamment courte pour pouvoir être communiquée sous forme numérique et sans erreur sur un câble de communication ou tout autre type de liaison numérique (radio par exemple).
Dans le cas de l’Internet, le format des paquets est spécifié par un protocole, l’Internet Protocol, connu sous l’acronyme IP. On parle donc de paquets IP. Quand on récupère un fichier par exemple, son contenu est découpé en petits morceaux inclus dans une multitude de paquets IP qui transitent sur le réseau. Chaque paquet circule indépendamment des autres. Pour cela, il contient un en-tête indiquant entre autres quelle est la destination du paquet. Le protocole IP spécifie que cette destination est identifiée par une suite de 4 octets : son adresse IP (chaque octet est généralement lu comme un nombre entre 0 et 255).
Voici le format de l’en-tête d’un paquet IP, tel que spécifié au bit près dans le standard RFC 791 défini par l’IETF (pour « Internet Engineering Task Force »), l’organisme de standardisation de l’Internet. La première ligne indique la signification des quatre premiers octets du paquet (soit 32 bits), la deuxième, celle des quatre suivants et ainsi de suite. Le reste du paquet est constitué par les données qui transitent dans le paquet (typiquement de l’ordre de 1000 octets).
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
|Version| IHL |Type of Service| Total Length |
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
| Identification |Flags| Fragment Offset |
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
| Time to Live | Protocol | Header Checksum |
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
| Source Address |
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
| Destination Address |
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
| Options | Padding |
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
On voit qu’outre l’adresse IP de la destination (cinquième ligne), un paquet IP contient aussi celle de la source (quatrième ligne) et bien d’autres champs comme la version du protocole (quatre premiers bits de la première ligne). La version présentée ici (la plus courante à l’heure actuelle) est la version 4 (IPv4). Tout paquet IPv4 commence par les bits 0100, soit 4 en binaire.
- Version indique le type de protocole internet utilisé (4 ou 6 à l’heure actuelle).
- IHL indique la longueur de l’en-tête (20 octets en général, qui peuvent être suivis de champs optionnels).
- Type of Service permet d’indiquer le type de trafic dont le paquet fait partie (voix, vidéo, transfert de fichier…). Il peut être utilisé pour demander différentes priorités de service (comme un temps de transit de paquets court, ou un débit maximum, ou une fiabilité maximale). Ce type de traitement évolué des paquets n’existe pas encore à l’échelle de l’Internet, mais le format des paquets anticipe sur le futur.
- Total Length désigne la longueur totale du paquet.
- Identification est un numéro d’identification du paquet (ce numéro est incrémenté à chaque envoi de paquet). Il permet de plus de réassembler les fragments d’un paquet trop long pour faire transiter un seul morceau sur le réseau. Flags indique si le paquet a été fragmenté et Fragment Offset indique alors la position du fragment transporté par le présent paquet dans le paquet originel.
- Time to Live indique un nombre maximal de retransmissions par les routeurs du réseau. Il s’agit d’une sorte de temps de vie car ce champ est décrémenté à chaque retransmission par un routeur et le paquet disparaît du réseau si ce champ atteint zéro. Ce garde fou permet d’éviter qu’un paquet ne circule à l’infini dans le réseau.
- Protocol indique le protocole de transfert, c’est-à-dire la manière dont le flot de paquets dont ce paquet fait partie est utilisé. Un en-tête pour le protocole suit généralement l’en-tête IP dans le paquet. Le protocole de transfert le plus utilisé est TCP (pour « Transfert Control Protocol ») qui permet de faire transiter de manière fiable un flot de données (comme un fichier, un mail, une page web, une conversion de chat…). Un autre protocole plus rarement utilisé est UDP (pour « User Datagram Protocol ») qui sert à envoyer individuellement des paquets (ou datagrammes) et est utilisé typiquement dans les applications à contraintes temporelles comme la voix sur IP. Mentionnons enfin le protocole ICMP (pour « Internet Control Message Protocol ») qui sert à tester l’état du réseau (il est par exemple utilisé par la commande ping qui teste si les paquets arrivent bien à destination d’une adresse).
- Header Checksum est une somme calculée sur l’en-tête vu comme une suite de nombres de 16 bits, sa valeur est ajustée de sorte que la somme des nombres fasse zéro. Cela permet de tester assez sûrement qu’aucune erreur de transmission ne s’est glissée dans l’en-tête. Un paquet dont l’en-tête ne passe pas ce test est ignoré.
- Options désigne une suite de longueur variable d’octets permettant d’inclure des informations facultatives comme des étiquettes de temps, ou des adresses de routeurs à traverser. Elles sont généralement inutilisées dans les trafics courants.
- Padding indique que des octets doivent être ajoutés pour que la longueur de l’en-tête soit toujours un multiple de 4 octets.
À l’intérieur d’un réseau
Comment les paquets ainsi formés circulent-ils dans un réseau ? Un réseau est constitué de routeurs et de liens de communication. Les liens relient les routeurs entre eux à la manière de routes entre les villes d’un pays. Plus précisément, un routeur est une sorte d’aiguilleur qui possède des liens avec d’autres routeurs. Chaque lien est branché au routeur via une interface. La principale activité d’un routeur consiste à router des paquets.
Voici plus précisément comment fonctionne le routage :
- un paquet arrive sur une interface,
- son en-tête est lu (et éventuellement modifié),
- le paquet est retransmis sur une autre interface.
Le choix de l’interface de sortie dépend de l’en-tête du paquet. Pour faire ce choix, un routeur maintient à jour une table de routage qui contient pour une destination donnée le numéro d’interface où faire suivre le paquet. Un protocole de routage spécifie les informations que s’échangent les routeurs pour pouvoir construire leurs tables de routage. Calculer les tables de routages revient à calculer des chemins dans un graphe. La construction des tables de routage est détaillée plus loin.
Mathématiquement, un réseau se modélise par un graphe dont les nœuds sont les routeurs et les arêtes sont les liens. Trouver comment acheminer un paquet d’un routeur à un autre revient à calculer un chemin dans ce graphe, c’est-à-dire une suite de routeurs telle que chaque routeur est connecté au suivant.
Ainsi, pour une destination donnée, chaque table de routage doit indiquer à qui faire suivre le paquet (en indiquant l’interface attachée au lien vers celui-ci). Pour une destination donnée, cette relation entre un routeur et le routeur suivant peut se représenter par un arc d’un routeur vers le suivant. Idéalement, l’ensemble de ces arcs forme un arbre de plus courts chemins enraciné à la destination.
La bête noire du routage est la boucle, c’est-à-dire une incohérence dans les tables de routage qui fait qu’un paquet peut se mettre à faire une boucle et à circuler indéfiniment par une même suite de routeurs. Si jamais cela arrive, les liens de la boucle peuvent vite être engorgés par ces paquets qui circulent indéfiniment. Pour éviter qu’un tel dysfonctionnement ne devienne dramatique, le protocole IP prévoit un champ TTL (pour « Time To Live ») dans l’en-tête des paquets. Quand un paquet est reçu, le champ TTL est décrémenté de 1. Si le TTL atteint 0, le paquet est interdit de retransmission. Ainsi, un paquet ne peut pas circuler indéfiniment dans le réseau.
Toute machine reliée à un des routeurs du réseau peut ainsi communiquer avec toute autre machine reliée à un routeur du réseau. Les machines qui sont ainsi mises en relation par un réseau sont appelées des hôtes.
À l’opposé, dans les réseaux téléphoniques (qui existent depuis beaucoup plus longtemps que l’internet), tous les paquets d’une communication se suivent avec régularité sur la même route. Toute communication commence par l’établissement d’une connexion qui va configurer les éléments du réseau de sorte qu’une route soit réservée pour la série de paquets qui va suivre. Ces réseaux dédiés à une application donnée, comme le transport de la voix, n’ont pas la malléabilité de l’Internet, dont le principe de base consiste à interconnecter tout ce qui peut transporter un paquet IP. On oppose ainsi les réseaux en mode connecté comme les réseaux téléphoniques aux réseaux à commutation de paquets comme l’Internet.
Comment agréger les réseaux
Comment les paquets circulent-ils d’un réseau à un autre ? Les hôtes, machines des utilisateurs de l’Internet, sont généralement reliés à un réseau local. Pour chaque réseau local, un routeur appelé passerelle relie ce réseau avec l’Internet. La seule décision de routage prise par un hôte est d’envoyer un paquet, soit directement à la destination si elle se trouve dans le réseau local, soit à la passerelle sinon.
Tous les routeurs d’un réseau sont gérés par la même organisation. Ils sont reliés entre eux, et savent acheminer des paquets entre eux. Certains des routeurs du réseau peuvent avoir des liens vers des routeurs d’autres réseaux, appelons-les des routeurs de frontière (pour « border gateway » en anglais). Le monde des destinations, vu d’un routeur de l’Internet, se sépare donc en deux populations, les destinations qui sont accessibles sans sortir de son propre réseau d’une part, et celles qui sont en dehors de ce réseau d’autre part.
Internet est constitué par un empilement hiérarchique de réseaux. Les réseaux du bas de la hiérarchie ne possèdent souvent qu’un seul routeur frontière relié à un réseau de niveau supérieur. Tout paquet pour une destination hors de portée du réseau sera envoyé vers ce lien. On parle de route par défaut, puisque les paquets sont envoyés par là si aucune information concernant la destination n’est trouvée dans la table de routage. Celle-ci ne contient en effet que des entrées concernant les destinations accessibles via le réseau.
À l’inverse, un routeur du réseau supérieur qui connecte ce réseau à l’Internet doit connaître l’ensemble des destinations accessibles via celui-ci, au cas où il recevrait un paquet pour l’une d’elles.
Les réseaux de plus haut niveau n’ont pas de route par défaut, on les appelle systèmes autonomes (en anglais « Autonomous System » ou AS), et ils constituent la nervure centrale (« backbone ») de l’Internet. Ce sont eux qui assurent l’interconnexion globale de l’Internet.
Les réseaux de différentes organisations sont reliés entre eux au gré d’accords bilatéraux (ou même multilatéraux). Les deux organisations s’accordent sur les informations que s’échangent les routeurs et sur les conditions commerciales dans lesquelles ils s’échangent du trafic.
Les réseaux intermédiaires de la hiérarchie, que nous appellerons réseaux d’accès (ou « transit network » en anglais) peuvent aussi conclure à leur niveau de tels accords de « peering » (entre pairs).
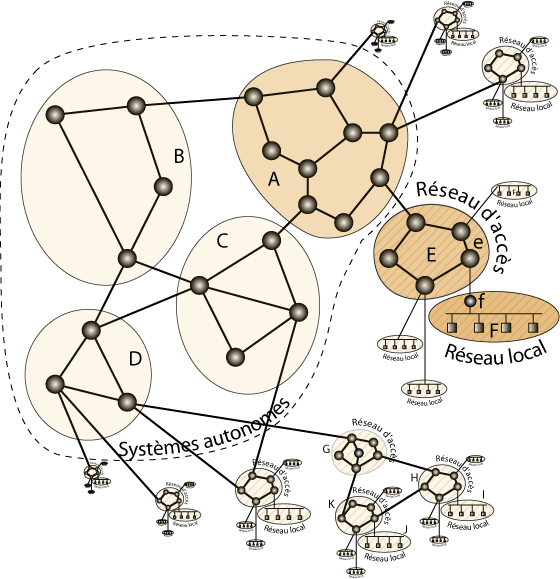
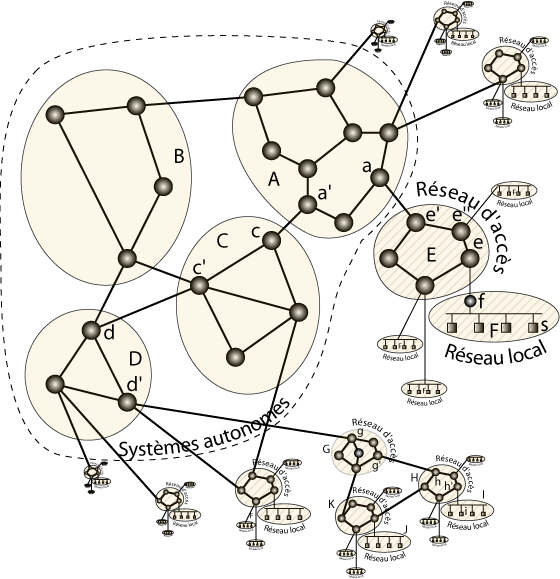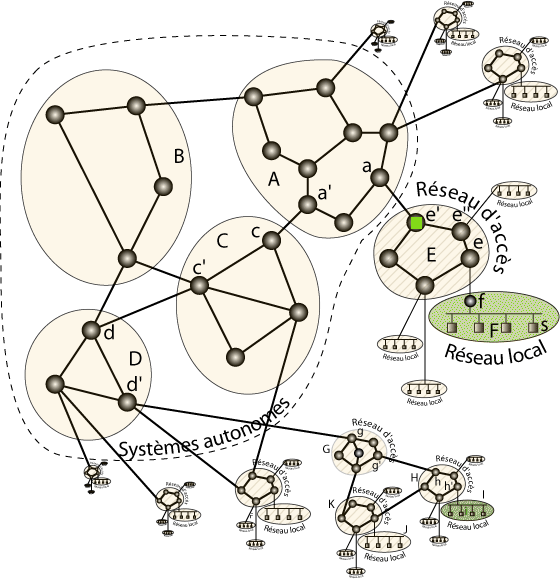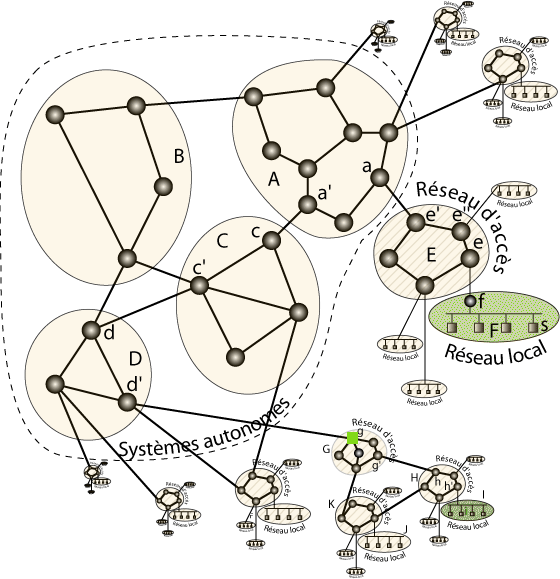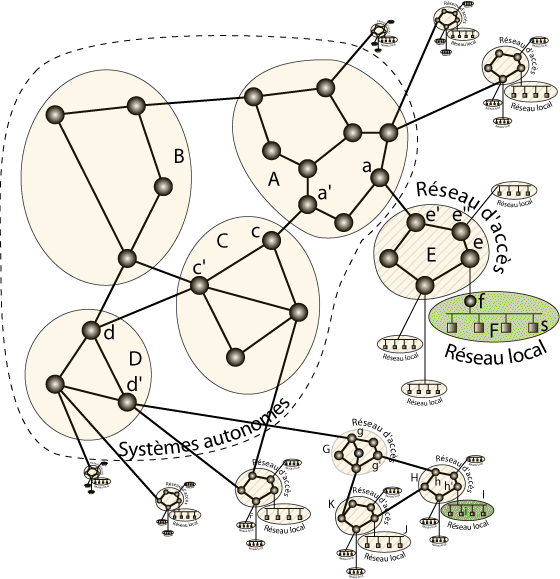
Représentation schématique de la structure de l’Internet.
Le réseau F est par exemple connecté par sa passerelle au réseau E, qui est lui-même un sous-réseau du système autonome A. Le réseau F pourrait par exemple être le réseau Wifi d’un particulier dont le modem ADSL f (qui fait aussi routeur Wifi) est relié à un routeur e (au nom de DSLAM) de son fournisseur d’accès à Internet. Ce routeur e fait partie du réseau national E de son fournisseur qui possède une connexion directe avec un système autonome A internationalement connecté.
Un réseau local peut aussi être directement connecté à un routeur du réseau d’accès. C’est souvent le cas pour les réseaux universitaires ou les réseaux d’entreprise.
Les routeurs des systèmes autonomes possèdent des sortes de métatables de routage qui indiquent pour une adresse IP comment atteindre le système autonome où se trouve la destination possédant cette adresse. Plus précisément, chacun de ces routeurs connaît la suite de systèmes autonomes qu’il va falloir traverser pour atteindre la destination. Pour cela, tout routeur frontière connecté au routeur frontière d’un autre système autonome échange avec lui des informations sur les adresses IP gérées par tel ou tel système autonome et sur les interconnexions entre système autonomes selon le protocole de routage BGP (pour « Border Gateway Protocol »).
L’acheminement d’un paquet IP se fait donc généralement ainsi :
- le paquet remonte la hiérarchie de réseau jusqu’à un routeur du système autonome de la source,
- il transite ensuite de système autonome en système autonome jusqu’à celui de la destination,
- il descend la hiérarchie jusqu’à la passerelle en charge du réseau local de la destination,
- cette passerelle l’envoie à la destination.
Représentation schématique de l’acheminement d’un paquet.
Imaginons par exemple que le nœud s du réseau F envoie un paquet à destination de i (dans le réseau I en bas à droite de la figure). i ne faisant pas partie du réseau F, le routeur Wifi f relaie ce paquet vers sa passerelle par défaut e. e détectant que i n’est pas accessible sous le réseau E le fait parvenir à sa passerelle par défaut e’ (le protocole de routage interne au réseau E indique qu’il faut pour cela passer par e »). e’ passe alors le paquet à a dans le réseau A. Le réseau A ne possède pas de passerelle par défaut (il s’agit d’un système autonome). Ses routeurs savent que i est accessible sous le système autonome D qu’ils peuvent atteindre via C, qui est accessible via le routeur a’ de A. a fait ainsi parvenir le paquet à a’ (par routage interne à A), qui passe à c, qui passe de manière similaire à c’, qui relaie le paquet vers d. d sait que i est dans un sous-réseau de D accessible via d’, à qui il passe donc le paquet. d’ qui interconnecte G sait qu’il doit passer le paquet à ce réseau d’accès intermédiaire pour atteindre i, le paquet circule ainsi ensuite par g, g’, h, h’, pour arriver finalement à i.
Bien sûr, un réseau intermédiaire de la hiérarchie peut s’apercevoir que la destination se trouve dans un autre des sous-réseaux qu’il connecte à l’Internet. Dans ce cas, le paquet redescendra directement vers la destination, sans passer par les routeurs de plus haut niveau des systèmes autonomes. De même, un lien de « peering » avec un réseau intermédiaire en charge du réseau de la destination peut permettre de court-circuiter le passage par les systèmes autonomes.
Par exemple, sur la figure ci-dessus, un paquet envoyé depuis le réseau J à destination de i transitera par K, qui utilisera son lien de « peering » vers H, qui fera suivre directement vers I à destination de i. Notons qu’une commande, traceroute, vous permet de suivre la route suivie par vos paquets.
Il est possible d’afficher la suite de routeurs traversés pour atteindre une destination grâce à la commande traceroute. Cette commande consiste à envoyer des paquets de TTL 1, puis 2, puis 3…, ainsi chaque routeur intermédiaire voit à son tour le TTL atteindre 0 et répond par un paquet ICMP pour signifier que la destination est inaccessible. Ce paquet contient l’adresse IP du routeur qui permet de l’identifier.
Par exemple, depuis une machine de l’INRIA Rocquencourt, la commande traceroute www.gouv.fr donne :
traceroute: Warning: www.gouv.fr has multiple addresses; using 193.51.224.6 traceroute to a331.g.akamai.net (193.51.224.6), 30 hops max, 38 byte packets 1 rocq-gw (128.93.1.100) 1.887 ms 1.459 ms 2.501 ms 2 rocq-royal-gw (192.93.1.106) 3.470 ms 8.980 ms 4.477 ms 3 193.48.202.1 (193.48.202.1) 2.992 ms 2.966 ms 3.489 ms 4 193.48.202.122 (193.48.202.122) 3.992 ms 3.988 ms 3.987 ms 5 193.48.202.132 (193.48.202.132) 2.991 ms 2.989 ms 3.986 ms 6 inria-g3-2-800.cssi.renater.fr (193.51.182.74) 2.996 ms 3.474 ms 3.489 ms 7 nri-a-g13-0-20.cssi.renater.fr (193.51.180.173) 3.987 ms 3.480 ms 3.995 ms 8 nri-a-g1-0-0-101.cssi.renater.fr (193.51.187.17) 5.487 ms 4.460 ms 3.491 ms 9 193.51.224.6 (193.51.224.6) 5.496 ms 4.972 ms 4.989 ms
Les deux premières lignes nous indiquent que www.gouv.fr a plusieurs adresses dont notamment 193.51.224.6 dont un autre nom est a331.g.akamai.net. Il s’agit en fait d’un site géré par la société akamai, qui possède plusieurs miroirs du site. L’adresse cible choisie est accessible via 8 routeurs intermédiaires (notamment des routeurs du réseau renater qui est le réseau académique français).
À l’inverse, un traceroute vers www-rocq.inria.fr donne la route très courte suivante (un simple passage par le routeur du site qui possède deux réseaux) :
traceroute to www-rocq.inria.fr (192.93.2.1), 30 hops max, 38 byte packets 1 rocq-gw (128.93.1.100) 4.202 ms 1.530 ms 2.211 ms 2 www-rocq1 (192.93.2.1) 2.314 ms 4.318 ms 4.701 ms
2. Adresses et embouteillages
Dans un tel conglomérat de réseaux, les routeurs doivent faire face à deux sortes d’abondance : l’abondance de paquets (comment éviter les embouteillages) et la multitude des destinations possibles (comment spécifier l’adresse du destinataire d’un paquet).
Ainsi, la carte du réseau est mouvante, et il n’est pas aisé de définir des adresses de sorte que des destinataires proches aient des adresses similaires. En effet, de même qu’un postier français n’a pas besoin de comprendre l’adresse précise d’un destinataire en Chine pour lui faire suivre une lettre, un routeur de l’Internet doit pouvoir faire suivre un paquet pour un système autonome lointain sans connaître l’organisation de celui-ci. En filigrane, derrière l’Internet Protocol (IP) qui a donné son nom aux adresses de nos ordinateurs, se cache la manière d’agréger les adresses.
De plus, comme dans tout réseau à fort trafic, il faut gérer l’engorgement et prévenir la congestion, c’est le rôle d’un autre protocole, appelé TCP pour « Transfer Control Protocol », de limiter le nombre de paquets qui circulent dans le réseau.
On parle ainsi du couple TCP/IP qui forme les deux piliers du fonctionnement de l’Internet.
Comment agréger les adresses
Un des éléments critiques d’un routeur est la gestion de sa table de routage. Son interrogation doit être extrêmement optimisée. Un routeur avec des liens à plusieurs Gbits/s doit en effet interroger sa table de routage plusieurs millions de fois par seconde, puisque chaque lien peut lui apporter plusieurs millions de paquets par seconde.
Il va de soi que si cette table possédait trop d’entrées, de tels débits ne seraient pas possibles. Les routeurs de plus haut niveau de l’Internet arrivent à fonctionner parce que leurs tables de routage ne contiennent « que » quelques centaines de milliers d’entrées.
Comment arrivent-ils alors à acheminer des paquets vers des centaines de millions d’hôtes ? La clé réside dans l’agrégation des adresses. Une adresse IP est constituée par n’importe quelle suite de 32 bits (soit 4 octets ou encore 4 nombres entre 0 et 255). L’attribution des adresses se fait en regroupant autant que faire se peut les adresses accessibles via une passerelle sous le même préfixe. De même tout réseau de la hiérarchie tentera de représenter l’ensemble des adresses IP qu’il connecte à l’Internet par un petit nombre de préfixes. L’annonce de ces seuls préfixes suffit alors à représenter l’ensemble des adresses accessible via ce réseau. Idéalement, toutes les adresses joignables via un système autonome donné devraient pouvoir être identifiées par un même préfixe commun, des préfixes plus longs servant alors à identifier les adresses accessibles par les réseaux d’accès que ce système autonome connecte.
En pratique, les plages d’adresses sont possédées par différentes organisations qui se connectent via tel ou tel système autonome au gré de la conjoncture économique. Une telle agrégation idéale est donc impossible. Notons cependant que début 2006, les 22 000 systèmes autonomes actuels s’annoncent les uns les autres 180 000 préfixes, ce qui représente une moyenne de 9 préfixes par système autonome, un taux d’agrégation suffisant pour rendre le fonctionnement de l’internet possible et interconnecter près de 400 millions d’hôtes.
Cette agrégation par préfixe se traduit en pratique par l’utilisation d’un masque (comme 255.255.0.0 par exemple) qui est une adresse IP fictive constituée d’une suite de 1 suivie d’une suite de 0 (255 s’écrit en binaire 11111111). En l’associant à une adresse IP (par exemple 128.93.0.0), cela permet d’identifier l’ensemble des adresses de même préfixe qui coïncident sur tous les 1 du masque (dans notre exemple, celles dont les deux premiers octets sont 128.93). Un sous-réseau peut alors être construit en regroupant toutes les adresses possédant un préfixe plus long, par exemple toutes celles identiques à 128.93.17.8 pour le masque 255.255.255.0
À l’origine de l’Internet, ce découpage des adresses en octets servait au découpage hiérarchique. Un sous-réseau pouvait être de classe A, B ou C selon que la longueur de son préfixe était de 1, 2, ou 3 octets (plus le préfixe est court, plus le réseau peut contenir d’adresses). Aujourd’hui, l’agrégation s’effectue par préfixe d’une longueur quelconque de bits. Un préfixe de 17 bits pourra par exemple être indiqué par le masque 255.255.128.0. Cela permet plus de flexibilité et une meilleure utilisation de l’ensemble des adresses.
Comment construire les tables de routage
Que ce soit à l’intérieur d’un réseau ou entre les systèmes autonomes, il existe principalement deux types de protocoles de routage permettant de maintenir à jour les tables de routage :
- le routage par vecteur de distances (« distance vector » en anglais)
- et le routage par état de liens (« link state » en anglais).
Le routage par vecteur de distances consiste à donner à ses routeurs voisins le vecteur des distances estimées avec toutes les destinations. Il repose sur une version asynchrone de l’algorithme de calcul de plus courts chemins connu sous le nom de Bellman-Ford. Le protocole BGP repose sur le même principe, en diffusant plutôt un vecteur de chemins indiquant pour chaque destination la suite de systèmes autonomes qui mène à elle.
Le routage par état de liens consiste pour chaque routeur à diffuser la liste des routeurs avec lesquels il est connecté. Chaque routeur connaît ainsi la topologie complète du réseau et calcule des plus courts chemins selon l’algorithme de Dijkstra.
Gérer la congestion et assembler les paquets
Un autre aspect important des réseaux à commutation de paquets est la nécessité de stocker les paquets temporairement dans chaque routeur. En effet, plusieurs paquets peuvent arriver de différents liens pour être retransmis sur le même lien de sortie. Les derniers arrivés doivent donc être stockés le temps de transmettre les premiers. Des tampons permettent ainsi de résister à un pic d’arrivée de paquets pour chaque lien. Si jamais un paquet supplémentaire arrive alors que le tampon est plein, le routeur n’a d’autre choix que de « jeter » le paquet (il ne sera jamais retransmis, il est perdu).
En cas de trafic trop important pour la capacité des liens, l’engorgement dans les tampons des routeurs est inévitable. L’un des piliers algorithmiques de l’Internet est donc le mécanisme qui permet de limiter le trafic de chaque connexion. C’est le rôle du protocole TCP (pour « Transfer Control Protocol ») de ralentir l’émission de paquets de toute source de trafic dès que celle-ci détecte le moindre signe d’engorgement dans l’acheminement vers ou depuis la destination. De plus, TCP s’occupe de retransmettre les paquets perdus. Pour cela, la destination informe la source des paquets qu’elle a bien reçu par des acquittements. Si un acquittement manque ou tarde à arriver, la source prend deux décisions : réduire son trafic, car il s’agit d’un signe de congestion dans le réseau, et retransmettre le paquet perdu.
Comprendre et analyser la dynamique des débits induite par TCP est un problème de recherche difficile.
Mentionnons aussi un autre rôle fondamental de TCP : remettre les paquets dans l’ordre.
Dans un réseau à commutation de paquets, il se peut en effet qu’un paquet transite plus vite qu’un autre (à la suite d’un changement de décision de routage par l’un des routeurs empruntés par exemple), induisant ainsi une arrivée désordonnée de certains paquets. Pour permettre la transmission fiable de données, TCP permet ainsi de reconstituer la séquence exacte des paquets, et donc de transmettre fidèlement un gros volume de données, comme un fichier.
À l’en-tête IP, TCP rajoute un second en-tête, contenant notamment une somme de contrôle permettant de vérifier l’intégrité des données contenues dans le paquet. Les erreurs de transmission au niveau du routage sont assez rares pour ne pas avoir besoin d’utiliser de code plus évolué, comme un code correcteur.
Dans un paquet TCP, un en-tête TCP suit immédiatement l’en-tête IP. Son format (d’après le RFC 793) est le suivant :
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Source Port | Destination Port |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Sequence Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Acknowledgment Number |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Data | |U|A|P|R|S|F| |
| Offset| Reserved |R|C|S|S|Y|I| Window |
| | |G|K|H|T|N|N| |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Checksum | Urgent Pointer |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| Options | Padding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
Le port source (respectivement destination) permet d’identifier sur la machine source (respectivement destination) le programme en charge de l’envoi des paquets (respectivement de leur réception). TCP est conçu pour un échange symétrique, ainsi chaque envoi de la part de la source sert aussi à acquitter un paquet envoyé en sens inverse par la destination. Sequence Number est un numéro permettant d’identifier le paquet envoyé. Acknowledgment Number indique le numéro du dernier paquet reçu en sens inverse. Les bits SYN et FIN servent à initier et terminer la connexion respectivement.
Checksum est une somme de tout le contenu du paquet, lu comme une suite de nombres entiers positifs codés sur 16 bits. (Les sommes sont effectuées modulo 216 de sorte à toujours manipuler des nombres de 16 bits.) Elle permet de vérifier qu’une erreur ne s’est pas glissée dans la suite des bits contenus dans le paquet : si jamais cela arrive, il y a une chance sur 64 000 d’obtenir la même somme.
TCP permet donc l’établissement de sortes de connexions de transmission de données via l’acheminement de datagrammes dans un réseau à commutation de paquets. Pour identifier ces connexions, TCP utilise des ports qui sont des numéros de 2 octets identifiant la connexion pour la source et la destination. Pour une machine donnée, il y a un seul programme en charge des paquets arrivant sur un port donné (ce programme peut néanmoins gérer plusieurs connexions sur ce port, chaque connexion étant différenciée par l’adresse IP et le port de l’autre participant). Le numéro de port sert ainsi d’aiguilleur pour permettre à une même machine d’accepter plusieurs connexions TCP en parallèle. Les applications les plus courantes de l’internet ont des numéros de port réservés, ainsi le téléchargement de page web auprès d’un serveur web se fait généralement sur le port 80, les serveurs de mail utilisent le port 25… L’en-tête TCP contient notamment les ports source et destination du paquet.
3. Gérer la croissance
Depuis ses débuts, l’Internet s’est développé et continue de croître. Quelles sont les solutions passées et futures permettant de gérer cette croissance ?
Origine de l’Internet
On fait souvent remonter la naissance de l’Internet à celle de son premier réseau, l’ARPANET, en 1969. En fait, les premières interconnexions effectives de réseaux remontent à 1983, avec la séparation de l’ARPANET en deux réseaux et sa liaison avec le réseau académique américain CSNET. L’invention d’IP, qui permet d’interconnecter des réseaux, est généralement attribuée aux américains Vinton Cerf et Robert Kahn à la fin des années 1970.
Cependant, il serait sans doute légitime de leur voir associer le nom du français Louis Pouzin, qu’ils ont visité en 1972 et dont les travaux pour le réseau Cyclades les ont sans doute largement inspirés dans la conception d’IP. Le réseau Cyclades (projet inspiré d’ARPANET et développé à l’IRIA) possédait dès le début des années 1970 une conception centrée sur la commutation de paquets (appelés datagrammes) avec une partie très similaire à IP.
On pourra trouver plus d’informations sur l’histoire de l’internet sur Wikipedia et sur le site de l’Internet Society (l’organisme qui contrôle de nombreux aspects de l’internet comme sa standardisation par le biais de sa branche IETF).
Une croissance exponentielle
De 1985 à 1990, l’Internet devient un réseau académique mondial. Son explosion avec l’arrivée du monde commercial date des années 1990. On décompte ainsi 300 mille hôtes en 1990, 15 millions en 1995, 100 millions en 2000.

Évolution du nombre d’hôtes.
La courbe ci-dessus est de l’Internet Systems Consortium. Certains routeurs offrent aussi de manière automatique des statistiques extraites de leurs tables de routage BGP sous le nom de CIDR Report.
Mais plus qu’au nombre d’ordinateurs connectés par l’Internet (estimé entre 350 et 400 millions début 2006), il convient de s’intéresser au nombre de réseaux connectés (plus de 180 000, dont seulement 22 000 systèmes autonomes assurent l’interconnexion générale début 2006). Le nombre de routeurs de l’Internet quant à lui est estimé aux environ de 200 000, c’est un chiffre très difficile à obtenir techniquement. En effet, la technique du « masquerading » permet de cacher un réseau derrière une seule machine passerelle, mais de tels réseaux apparaissent pour le reste de l’internet comme une seule machine.
Connecter un réseau quand on a une seule adresse IP
Expliquons ici le « masquerading » : une passerelle se fait passer pour toutes les machines du réseau à la fois. La passerelle possède l’adresse IP, les autres machines ont des adresses fictives (typiquement 192.168...). Ce tour de passe-passe est possible grâce aux numéros de port de TCP, qui sont utilisés comme deux octets d’adressage supplémentaires : quand un paquet TCP arrive à la passerelle, celle-ci va transmettre le paquet à l’hôte qui a initié une connexion depuis ce port.
Si plusieurs hôtes utilisent le même port, la passerelle doit jongler avec les numéros de port pour éviter les collisions. Elle peut aussi utiliser l’adresse IP et le port utilisés à l’autre bout de la connexion pour distinguer différentes connexions.
Un routeur Wifi personnel est un exemple typique de passerelle effectuant du « masquerading » pour pouvoir connecter tous les ordinateurs d’une maison à l’Internet, alors que le fournisseur d’accès n’offre généralement qu’une seule adresse IP.
Pour protéger d’éventuelles attaques les machines d’un réseau, une technique classique consiste à les masquer derrière un pare-feu (ou « firewall » en anglais) qui filtre de plus les paquets entrants ou sortants suspects.
À l’inverse, pour rendre accessible un ordinateur ainsi masqué, il faut indiquer à la passerelle qu’elle doit rediriger les tentative de connexion vers le port qu’on veut ouvrir à cet ordinateur.
Pourquoi un tel essor ?
Ce qui caractérise le plus l’Internet est sans doute l’absence d’entité centralisatrice et une architecture ouverte : n’importe qui peut se connecter quelle que soit la technologie utilisée dans son réseau.
Les entités qui dirigent chaque réseau décident de se connecter les unes aux autres au gré d’accord bilatéraux ou multilatéraux. Une série de spécifications publiques indiquent les règles à respecter pour pouvoir se connecter. C’est cet aspect ouvert des spécifications qui rend possible le fonctionnement d’un tel conglomérat de réseaux.
L’évolution d’IP : IPv6
Compte-tenu de la croissance de l’Internet, le nombre d’adresses IP devient une donnée critique. Avec IP version 4 (IPv4), les adresses sont des suites de 32 bits, le nombre d’adresses IP possibles reste donc limité à 232, soit environ 4 milliards. Malgré plusieurs modifications pour augmenter l’utilisation de l’espace d’adressage (comme la technique du « masquerading » mentionnée ci-dessus), la croissance du nombre d’adresse IP utilisées reste exponentielle.
Fatalement viendra un jour où il ne sera plus possible de connecter davantage de réseaux à l’Internet, par manque d’adresses IP. Ce jour-là est déjà anticipé depuis le milieu des années 1990 avec la version 6 de IP (IPv6) qui utilise des adresses de 128 bits, largement de quoi donner une adresse IP à tous les appareils électroniques que la Terre porte ou portera.
Cette version d’IP fonctionne en fait déjà sur de nombreux ordinateurs (comme les systèmes Unix et en particulier Linux et MacOSX) et sur environ un millier des 22 000 systèmes autonomes actuels. Elle est prévue pour cohabiter avec IPv4 de sorte à effectuer une transition progressive.
Problématiques de recherche
Le fonctionnement de l’Internet est le lieu d’une intense activité de recherche, qu’il s’agisse de concevoir les protocoles du futur, d’intégrer de nouvelles formes de réseaux comme les réseaux ad hoc, ou encore de mesurer et de modéliser la forme actuelle du réseau.
En effet, avec son organisation décentralisée, il est impossible d’avoir une carte globale de l’Internet autrement qu’en le mesurant. Il est possible d’utiliser les tables de routage des routeurs, mais elles ne donnent qu’une vision partielle ou agrégée. Voici par exemple le résultat d’une exploration par des traceroute depuis un point de l’Internet vers toutes les destinations possibles obtenu par l’Internet Mapping Project (qui s’est mis ensuite à faire commerce de telles « cartes »).
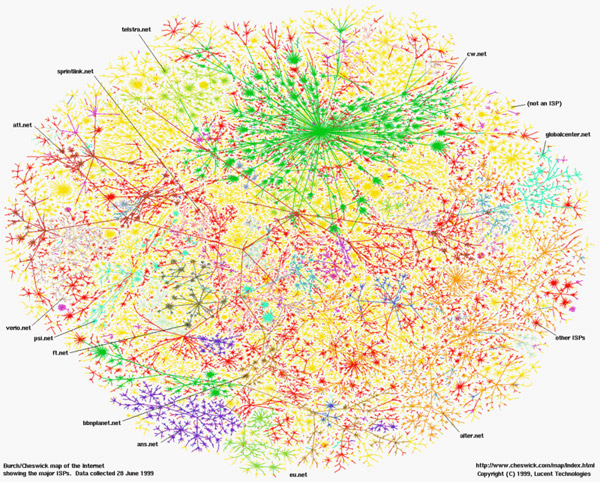
Exemple de « carte » obtenue par exploration de l’internet.
Image : Internet Mapping Project.
Pour plus de détails sur ce qu’on connaît de la topologie de l’Internet, consulter le site de l’association CAIDA (Cooperative Association for Internet Data Analysis).
4. Web et anonymat
Qu’est-ce que le Web (la toile) vis-à-vis de l’Internet, que sont les noms de domaines (comme interstices.info) que nous utilisons si souvent ? Comment sont gérées les questions de publicité et d’anonymat dans l’Internet ?
Le Web, une application sur l’Internet
Il ne faut pas confondre l’Internet avec la toile, qui est le réseau des pages web, même si c’est surtout par la consultation des pages web que le grand public utilise l’Internet, et que cela a contribué à sa croissance. En effet, nous accédons aux pages web grâce à l’Internet qui nous permet de nous connecter aux serveurs web qui proposent ces pages. On peut donc dire qu’on les trouve sur l’Internet.
D’autre part, les pages web possèdent des liens hypertexte qui les relient les unes aux autres. Ces liens, appelés URL ou URI (pour « Uniform Ressource Locator » ou « Uniform Ressource Identifier »), sont des redirections logiques qui contiennent simplement l’adresse IP et le port du serveur (ou simplement son nom) et le chemin du fichier contenant la page sur le serveur. Ces liens logiques n’ont aucun rapport avec les liens physiques de l’Internet.
L’étude du graphe du web (le graphe défini par ces liens) constitue un domaine en soi, qui permet par exemple aux moteurs de recherche d’évaluer l’importance des pages web (sur le principe de base qu’une page pointée par beaucoup de liens doit être plus intéressante qu’une page très peu pointée).
Noms et adresses
On utilise rarement les adresse IP directement lorsqu’on utilise les applications internet comme le web. Il est en effet plus pratique d’utiliser des noms que des numéros.
Pour cela, un système d’annuaire permet de traduire un nom comme interstices.info en l’adresse IP qui lui est associée 128.93.162.59. Ce système est constitué d’une hiérarchie de serveurs de noms ou DNS (pour « Domain Name Serveur »). Une quinzaine de serveurs racines (dont les adresses IP sont connues) indiquent quelles sont les adresses IP des serveurs de nom des domaines les plus haut (comme .com, .fr, .info…). Chaque serveur de nom agit de même pour ses sous-domaines (interstices.info est par exemple un sous-domaine de .info). Ainsi, lorsque vous demandez à votre navigateur la page web d’URL http://interstices.info/internet, ce navigateur commence par effectuer une requête auprès du serveur de nom de votre fournisseur d’accès à internet : quelle est l’adresse IP de interstices.info. Celui-ci va alors demander aux serveurs racines l’adresse IP d’un serveur de nom pour .info, qu’il pourra alors contacter pour obtenir l’adresse IP d’un serveur de nom de interstices.info, qui pourra lui indiquer l’adresse de l’hôte interstices.info. Bien sûr, le serveur de nom retient les réponses qu’il a déjà reçues pour éviter de rechercher trop souvent les mêmes serveurs de nom.
Quand votre navigateur reçoit l’adresse IP de interstices.info, il peut alors ouvrir une connexion TCP vers cette adresse sur le port 80 (le port par défaut pour les serveurs web), et demander le fichier /internet. Quand il reçoit enfin le contenu du fichier, votre navigateur le met en page et commence à l’afficher. (Le contenu peut faire référence à d’autres URL qui sont téléchargées de même pendant l’affichage.)
Questions de confidentialité et de sécurité
L’Internet, en tant qu’espace foisonnant d’informations, suscite bien des questions sur le respect de la vie privée ou au contraire de la publicité qu’il peut apporter. Certains acteurs, comme les sociétés commerciales, aimeraient voir leur nom s’afficher sur un maximum de pages web, alors que d’autres acteurs préféreraient rester le plus anonymes possible. Lançons quelques pistes sur ce débat sans pouvoir le creuser ici plus en détail.
Les moteurs de recherche qui permettent aux internautes de trouver des pages web ont une position clé dans la publicité que peuvent obtenir les acteurs commerciaux (ou politiques) de l’Internet. De nombreux vendeurs de produits, prenons par exemple les baladeurs, se demandent en effet comment faire en sorte que leur site de vente apparaisse en tête du classement lorsqu’un internaute fait une requête avec le mot baladeur dans son moteur de recherche favori. Cette position de porte d’entrée du web permet aux moteurs de recherche de retirer d’importants profits du service gratuit qu’ils fournissent aux internautes.
D’autre part, un internaute peut légitimement se demander quelles traces il laisse lorsqu’il utilise l’Internet. Comme son adresse IP se trouve dans chacun des paquets qu’il envoie, de nombreux acteurs peuvent garder une trace de son passage. L’administrateur d’un site web (qui peut aussi être un site personnel) peut par exemple visualiser quelle page a été visionnée depuis quelle adresse IP. D’autre part, lorsque notre internaute poste un message électronique sur un forum, son message va souvent se retrouver dans une page web générée automatiquement par le site du forum. Son adresse électronique sera alors visible sur la toile et les « spammer » pourront la trouver pour lui envoyer des courriers publicitaires indésirables… Bien sûr, plus un acteur fait de publicité sur l’Internet (par exemple en ayant un nom de domaine pour retrouver plus facilement son serveur web) plus il laissera de traces et sera repérable.
Une certaine paranoïa peut s’emparer de notre internaute apprenant qu’un pirate peut récupérer de telles informations, comme l’adresse IP de son ordinateur, et tenter de s’y connecter pour l’utiliser à son insu. Le pirate tente alors d’utiliser des trous de sécurité du système (le plus souvent connus et corrigés dans les mises à jour du système). Mais les ordinateurs vraiment vulnérables sont ceux qui ont de nombreuses portes d’entrées, comme les serveurs. Une protection simple consiste à installer un « firewall », c’est-à-dire un programme qui va filtrer les paquets IP qui arrivent à l’ordinateur selon des règles permettant d’éviter à coup sûr des comportements indésirables comme l’arrivée d’un paquet d’ouverture de connexion TCP quand l’ordinateur n’est pas serveur.
Cependant, de telles mesures brident l’utilisation que l’on peut faire de l’internet, et empêchent l’utilisation de techniques prometteuses comme le « peer-to-peer » qui consiste à se connecter entre internautes pour échanger des données de manière coopérative. Il faut alors, pour utiliser de tels logiciels qui font de votre ordinateur un serveur, « ouvrir un port », c’est-à-dire autoriser les paquets destinés au port TCP de votre logiciel de passer le « firewall ». (Le même problème se retrouve lorsqu’on est connecté par une passerelle qui fait du « masquerading ».)
Enfin, les acteurs les plus notoires peuvent être victimes d’attaques concertées de plusieurs pirates qui veulent attaquer telle ou telle entreprise qu’ils ont en aversion. L’attaque de « déni de service » consiste ainsi à bombarder de requêtes le serveur de l’entreprise concernée. Un tel assauts de connexions peut alors rendre le serveur inaccessible à tout utilisateur.
Mais ces pirates pourraient aussi bien être des citoyens combattant d’une manière moderne des idées ou des comportements d’une entreprise qu’ils réprouvent légitimement. Comment distinguer ce qui pourrait devenir une forme de manifestation démocratique, consistant à encombrer en masse les routes de l’internet, d’actes de piraterie par des individus isolés ?
L’internet constitue un nouvel espace de vie sociale. Il y a de nombreux problèmes pratiques à gérer techniquement, comme la croissance de sa taille, l’évolution de ses usages, qui intéressent principalement les informaticiens. Mais ce nouveau terrain d’échanges humains soulève aussi de nombreuses questions d’éthique, de droit et surtout de libertés qu’il nous appartient à tous d’apprivoiser et de civiliser.
Newsletter
Le responsable de ce traitement est Inria. En saisissant votre adresse mail, vous consentez à recevoir chaque mois une sélection d'articles et à ce que vos données soient collectées et stockées comme décrit dans notre politique de confidentialité
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Laurent Viennot