Rose Dieng-Kuntz : savoir, mémoire et partage
De son père, Henri Dieng, elle a appris « le sens du travail et de l’effort ». Naturellement, Rose est une élève brillante. Après un parcours sans faute au lycée Van Vollenhoven, l’un des mieux cotés de Dakar, elle obtient en 1972 le premier prix au Concours général sénégalais en mathématiques, en français, en latin, et le deuxième en grec.

© Inria / Photo Jim Wallace
L’année suivante, elle décroche sans surprise la mention très bien avec félicitations du jury au baccalauréat scientifique. Sur les conseils de ses professeurs, et grâce à une bourse de coopération, elle qui aurait aimé devenir écrivain ou médecin atterrit en « maths sup », en France. En 1976, âgée de vingt ans, elle devient la première femme africaine admise à l’École polytechnique. Suit un diplôme d’ingénieur de l’École nationale supérieure des télécommunications, puis une thèse en informatique à l’université Paris Sud. Études qui la mèneront rapidement à l’Inria, où elle est aujourd’hui directrice de recherche et responsable depuis 1992 du projet ACACIA. Elle vient de gagner en 2005 le Prix Irène Joliot-Curie, décerné par le ministère de la Recherche et la fondation EADS à « la scientifique de l’année ».
Entretien avec Rose Dieng-Kuntz mené par Anne Lefèvre-Balleydier.
Vous avez commencé votre carrière dans le privé. Qu’y faisiez-vous ?
J’ai rejoint Digital Equipment Corporation (DEC) pour travailler sur l’intelligence artificielle. Cela n’avait pas grand rapport avec ma thèse (j’y étudiais la spécification du parallélisme dans les programmes informatiques), mais c’était un domaine qui m’attirait vraiment. Je l’avais découvert en lisant les ouvrages de Marvin Minsky, d’Elaine Rich, d’Edward Feigenbaum, de Bruce Buchanan ou de Jean-Louis Laurière, etc. Qu’une machine puisse raisonner comme un homme – c’était le cas du fameux système expert médical Mycin –, qu’elle soit capable d’apprendre, de comprendre la langue naturelle, cela me fascinait car c’était un véritable défi. L’expertise étant ce qu’il y a de plus difficile pour l’Homme, c’est dans les systèmes experts que le challenge était d’après moi le plus grand.
J’étais alors partagée entre l’envie de rentrer au Sénégal et celle de rester en France. Mais à l’époque, dans mon pays, la recherche en informatique était inexistante et je n’aurais pas pu mettre à profit toutes les connaissances que j’avais acquises. Or chez DEC, je pouvais travailler sur les systèmes experts – pour résoudre par exemple des problèmes de configuration. Et puis j’ai rencontré Pierre Haren. Il souhaitait constituer une équipe de recherche à l’Inria Sophia Antipolis sur les systèmes experts. Son projet me semblait passionnant, et Pierre Haren était très intéressé par mon profil – nous avions d’ailleurs fréquenté le même lycée, le lycée Van Vollenhoven au Sénégal, où chacun de nous avait entendu parler des prix d’excellence continuels de l’autre… En 1985, j’ai donc quitté DEC pour l’Inria.
Quel était le projet de Pierre Haren ?
Il s’agissait de développer des générateurs de systèmes experts. En règle générale, un système expert est constitué d’une base de connaissances – par exemple, en médecine, des connaissances médicales issues des études et de la pratique du médecin – et d’un moteur d’inférences capable d’exploiter cette base de connaissances pour mener des raisonnements et résoudre des problèmes – par exemple, mener un raisonnement pour trouver un diagnostic à partir des symptômes décrits par un patient et des résultats de ses analyses.
Ici, avec le projet SMECI, l’objectif n’était pas de développer une application particulière, mais un outil générique permettant ensuite de construire toute une gamme d’applications : un système expert en conception de digues, ou un système expert en conception de bâtiment. Ce qui était intéressant, c’est qu’éventuellement, on pouvait ensuite travailler sur plusieurs bases de connaissances, en reposant sur les connaissances de plusieurs experts : j’ai toujours été séduite par l’aspect « multi »…
Quelle était votre contribution dans SMECI ?
J’étais chargée des explications : on souhaitait en effet un système expert capable d’expliquer son raisonnement à l’utilisateur. Pour moi, c’était quelque chose de fondamental. Car, plus que la « boîte noire » d’un système expert, ce qui me motivait et me motive toujours, c’est de pouvoir transmettre, partager des connaissances : c’est d’ailleurs avec cette idée que je suis venue en France au départ, en espérant faire profiter tous les Sénégalais de mon expérience.
SMECI avait pour originalité d’offrir un langage de représentation hybride permettant à la fois de décrire des objets et des règles, mais aussi de fonctionner suivant un arbre de raisonnement avec des mécanismes de contrôle pour gérer des solutions alternatives. J’ai alors proposé deux approches. La première était de construire un second système expert (appelé système explicateur) capable, grâce à ses règles explicatives, d’analyser l’arbre de raisonnement du premier système expert. La seconde approche était de générer des formules temporelles pour étiqueter l’arbre de raisonnement et résumer ainsi les principaux points du raisonnement du système expert.
En 1988, Pierre Haren a finalement quitté l’Inria pour lancer ILOG, une startup aux activités basées sur SMECI. Pourquoi ne l’avez-vous pas suivi ?
Je préférais la recherche… Après son départ, le projet a évolué : c’est devenu le projet SECOIA dirigé par Bertrand Neveu. L’idée sur laquelle je travaillais personnellement, c’était de généraliser l’approche du système explicateur de SMECI, en faisant coopérer plusieurs systèmes experts. Il m’est alors apparu que pour obtenir de bonnes explications, mieux valait les préparer dès la phase d’acquisition des connaissances : si cette étape ne tient pas compte des explications ultérieures, on acquiert des connaissances opérationnelles pour raisonner et résoudre un problème, mais on n’acquiert pas forcément les connaissances de fond qui permettront au système d’expliquer pourquoi il a fait tel choix plutôt que tel autre. Je me suis donc intéressée aux systèmes d’aide à l’acquisition des connaissances. Et dans ce cadre, nous avons travaillé sur un outil d’acquisition s’appuyant sur des connaissances qualitatives et permettant de simuler le raisonnement du futur système expert.
C’est de cette évolution vers l’acquisition des connaissances qu’est né en 1992 le projet ACACIA ?
ACACIA doit énormément à Gilles Kahn et à Pierre Bernhard, alors respectivement président du comité des projets et directeur de l’unité de recherche Inria Sophia Antipolis, qui nous ont soutenus à une époque où l’intelligence artificielle n’était pas très en vogue à l’Inria. Ce projet est né de la rencontre avec Alain Giboin, un psychologue ergonome qui travaillait sur les systèmes didactiques. Ensemble, avec Olivier Corby, nous avons eu l’idée d’un projet visant à mettre au point des outils qui aideraient la phase d’acquisition des connaissances lors de la construction d’un système expert. Un projet que je voulais réussir à tout prix, en hommage à mon père qui venait de décéder. Grâce à son souvenir, même dans les moments les plus difficiles, je n’ai jamais perdu confiance.
L’objectif était d’une part d’acquérir des connaissances provenant de plusieurs experts, et de l’autre d’acquérir des connaissances utiles pour préparer les futures explications que devrait fournir le futur système expert.
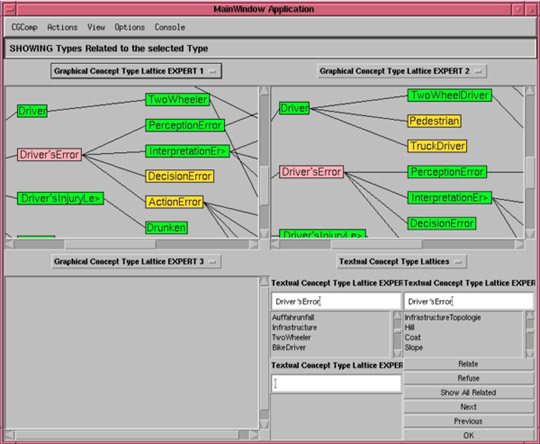
Outil de comparaison multiexpert.
Cet outil permet de comparer automatiquement les connaissances de plusieurs experts, par la comparaison des graphes. Il permet ainsi d’aider à la construction de connaissances communes à plusieurs experts (Image : Projet ACACIA).
Pour la prise en compte de multiples experts, il fallait proposer des protocoles de recueil collectif des connaissances, savoir comment détecter les incohérences et déterminer les connaissances communes et les connaissances spécifiques aux différents experts… Nous avons alors proposé un modèle d’agents cognitifs pour guider l’acquisition de connaissances de plusieurs experts (c’était le travail de thèse de Sofiane Labidi), et pour représenter leurs connaissances, nous avons choisi le formalisme des graphes conceptuels. Les graphes conceptuels permettent de décrire des relations entre des objets, des entités, etc. et peuvent être visualisés sous une forme graphique conviviale pour l’utilisateur. On peut par exemple décrire et visualiser sous forme de graphe conceptuel un accident de la route intervenu entre un camion et un vélo sur une route départementale. En comparant les graphes décrivant les connaissances de plusieurs experts, il est possible de déterminer ce qu’il y a de commun et ce qu’il y a de différent, d’élaborer des stratégies pour résoudre les conflits et intégrer les différentes connaissances : on peut par exemple privilégier les connaissances les plus générales, ou au contraire les connaissances les plus spécialisées.
Ces connaissances pouvaient-elles aussi provenir de documents ?
Nous avons cherché le meilleur moyen d’intégrer documents et bases de connaissances, dans le cadre de la thèse de Philippe Martin, avec l’outil CGKAT (Conceptual Graph Knowledge Acquisition Tool). Dans les entreprises, il existe en effet beaucoup de documents pouvant servir de sources pour construire une base de connaissances. L’idée a été d’associer à ces documents des graphes conceptuels, permettant de décrire leur contenu sémantique. Ces graphes reposent sur l’ontologie du domaine concerné, c’est-à-dire la description des concepts manipulés dans ce domaine et des relations entre ces concepts.
Nous avons alors choisi de développer une extension de WordNet, un dictionnaire développé par des linguistes du laboratoire des sciences cognitives de l’université de Princeton et pouvant être considéré comme une sorte d’ontologie de la langue anglaise. Nous avons pu appliquer CGKAT à l’accidentologie, en collaboration avec l’INRETS. Et cela m’a permis de retourner vers les langues, qui m’ont toujours attirée.
Votre approche reposait-elle nécessairement sur les graphes conceptuels ?
À l’époque, la méthode CommonKADS constituait une sorte de standard dans l’acquisition des connaissances. Nous l’avions d’ailleurs utilisée pour modéliser les connaissances des experts de l’INRETS en accidentologie. D’un autre côté, à l’Inria, l’équipe CROAP avait développé un logiciel, Centaur, capable de générer automatiquement un environnement de programmation dédié au langage dont on lui fournit une spécification.
Nous avons donc choisi le langage de CommonKADS, CML, permettant de décrire de manière formelle des bases de connaissances. Puis nous avons spécifié ce langage dans Centaur de manière à générer un environnement pour CommonKADS, et en particulier un éditeur structuré dédié à CommonKADS. Enfin, nous avons adopté la même démarche qu’avec CGKAT, en partant cette fois des documents accessibles sur le Web auxquels on associe des modèles d’expertise CommonKADS sur la base d’une ontologie décrivant le domaine : c’est le système WebCokace, développé par Olivier Corby et appliqué au développement d’un serveur de connaissances sur le pronostic et la thérapie du cancer du sein. Nada Matta l’a également appliqué à un serveur de connaissances sur la gestion de conflits en ingénierie concourante.
Nous avons donc approfondi notre approche « documents base de connaissances ontologies » à la fois dans le monde des graphes conceptuels et dans le monde de CommonKADS.
Cette époque est aussi celle où vous vous êtes tournée vers la mémoire d’entreprise…
Notre équipe travaillait beaucoup avec des entreprises (Dassault-Aviation, Dassault électronique…) ou avec des centres de recherche tels que l’INRETS. Or nous avons constaté que ce qui les intéressait, ce n’était pas de construire un système expert qui pourrait raisonner et être consulté au même titre qu’un expert humain, mais plutôt de capitaliser les connaissances de l’entreprise et les mettre à disposition des employés. Il s’agissait donc toujours d’acquisition des connaissances, seule la finalité changeait. De ce fait, la mémoire d’entreprise est devenue le fil conducteur de nos recherches.
Désormais, l’équipe ACACIA visait à offrir des méthodes et des outils qui permettraient à une communauté, une entreprise ou une institution de capitaliser et partager des savoirs. La mémoire, c’est d’ailleurs quelque chose d’essentiel dans la vie d’un homme, d’une communauté, d’une nation : ce qui blesse, ce qui détruit, c’est l’absence de mémoire.
Au sein d’une entreprise, le web s’avère un fabuleux outil de partage de connaissances…
C’est effectivement un formidable outil, grâce auquel le savoir peut aussi être transmis aux écoles et aux universités, même des pays les plus pauvres. Nous avions déjà pris en compte l’importance du Web dans WebCokace. Mais en 1999, nos travaux ont pris un tournant important grâce à une notion lancée par Tim Berners-Lee : le Web sémantique. Sur le Web, vous trouvez en effet tout un tas de documents, d’images, autrement dit de ressources. Mais pour le moment, seuls les humains sont capables de comprendre le sens de ces documents : comprendre par exemple qu’un camion est un véhicule, une collision un accident, etc. L’idée du Web sémantique, c’est donc de rendre explicite la sémantique des ressources du Web, pour que des programmes informatiques puissent l’exploiter. Ce qui nous a conduit, en faisant l’analogie entre les ressources du Web et celles d’une entreprise, à proposer ce qu’on appelle le Web sémantique d’entreprise : c’est l’approche du système Samovar, développé dans le cadre de la thèse de Joanna Golebiowska avec Renault.
Cette entreprise voulait capitaliser les connaissances accumulées lors de la conception de véhicules, et en particulier les problèmes qui avaient été rencontrés. Elle avait commencé à le faire sous la forme d’une base de données. Mais l’essentiel des informations de cette base de données se présentait sous forme textuelle, et si cette base représentait une mine d’informations, elle était très difficile à exploiter. L’idée a donc été d’utiliser des outils linguistiques pour analyser tous les champs textuels et construire de manière semi-automatique une ontologie décrivant tous les problèmes pouvant intervenir dans un projet véhicule. On pouvait ensuite utiliser cette ontologie pour indexer automatiquement les descriptions de problèmes figurant dans la base de données. Et l’on peut faire la même chose à partir de documents techniques, d’interviews d’experts, etc.
Une fois l’ontologie construite, il faut encore pouvoir faire des requêtes…
C’est ce que fait Corese, un moteur de recherche développé par mon collègue Olivier Corby, en exploitant l’ontologie et les annotations sémantiques (représentées au niveau interne sous forme de graphes conceptuels) pour retrouver des ressources plus pertinentes qu’avec des moteurs de recherche classiques. Exemple : avec un moteur de recherche classique, si vous cherchez des documents sur des accidents de véhicules, vous ne trouverez que ceux où les mots accident et véhicule apparaissent. Corese, lui, met à profit l’ontologie qui décrit les différents types d’accidents et de véhicules, ce qui lui permet de juger pertinent un document décrivant une collision (un type d’accident) entre un camion et un bus (deux types de véhicules).
Le projet européen CoMMA a permis d’étendre Corese et de l’exploiter dans le cadre d‘une mémoire distribuée dans plusieurs bases d’annotations gérées par plusieurs agents logiciels coopérant : c’était le travail de thèse de Fabien Gandon. L’équipe ACACIA a pu appliquer Corese dans des domaines très variés (médecine, biologie, télécommunications, bâtiment, automobile…), que ce soit pour construire une mémoire de projets, pour la cartographie des compétences ou pour la veille technologique, etc. Et la startup e-Core est en cours de création pour développer des solutions de gestion des compétences basées sur Corese.
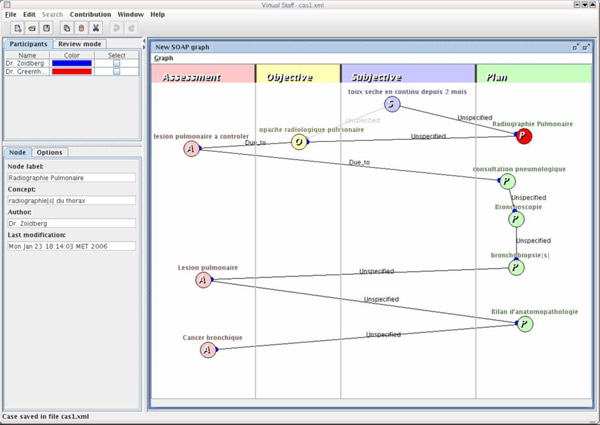
Structurer le dossier patient pour aider la coopération médicale entre acteurs d’un réseau de soins, c’est le but du staff virtuel basé sur Corese et développé dans le cadre du projet Ligne de Vie. Ce staff virtuel repose sur une ontologie pour décrire les symptômes, les analyses, les maladies pouvant être diagnostiquées et les traitements possibles. Il aide les différents médecins à raisonner de manière coopérative pour établir un diagnostic complexe sur le cas du patient et à prendre des décisions entre plusieurs choix thérapeutiques possibles, en argumentant sur ces choix (Image : Projet ACACIA).
Le Web sémantique d’entreprise est-il encore au cœur de vos recherches ?
Nos recherches actuelles sont un peu une extension de ce Web sémantique d’entreprise. Nous exploitons les ontologies pour améliorer des algorithmes de recherche sur le Web, par exemple à des fins de veille technologique. Nous cherchons également à prendre en compte la manière dont évoluent au cours du temps une ontologie et des annotations. Nous essayons d’automatiser, au moins partiellement, la construction et l’enrichissement des ontologies ou des annotations sémantiques, par exemple à partir de sources textuelles ou à partir de bases de données. Nous étudions la gestion de multiples ontologies et de multiples contextes d’annotation. Le e-learning est pour nous un scénario très intéressant de gestion des connaissances. Nous commençons également à étudier l’apport des ontologies pour les services web. Nous essayons d’impliquer les utilisateurs finaux lors de la conception et de l’évaluation de nos systèmes et d’offrir des interfaces ergonomiques.
De manière plus générale, nous visons à améliorer la coopération entre entreprises et communautés via la constitution de « Web de connaissances ». Et c’est en phase avec l’objectif visé par l’Europe d’évoluer d’une « société de l’information » vers une « société de la connaissance ».
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Rose Dieng-Kuntz