De la reconnaissance automatique du locuteur à la signature vocale
Cet article est devenu obsolète, de par son contenu ou sa forme, il est donc archivé.
Nous avons tous des timbres de voix différents. La voix de chaque personne dépend de caractéristiques à la fois anatomiques et comportementales.

Dessin : Joub et Nicoby
La parole est le résultat de l’air faisant vibrer les cordes vocales et passant dans le conduit vocal constitué par la bouche et le nez. Si ces éléments anatomiques influencent la personnalité d’une voix, ils n’en fixent pas pour autant toutes les caractéristiques. Ainsi, une même personne ne parle pas tout le temps de la même façon. La voix change avec l’âge, l’humeur ou encore un rhume. En jargon scientifique, les variations de la voix d’une même personne sont appelées variabilité intra-locuteur. En raison de ces aspects comportementaux, on parle de signature vocale, plutôt que d’empreinte.
Outre la variabilité de la voix d’une même personne, une autre difficulté pour que l’ordinateur puisse reconnaître une voix vient du fait que les conditions et la qualité d’enregistrement d’une même voix peuvent être très différentes.

Dessin : Joub et Nicoby
Une voix passant à travers un microphone, transmise par exemple par radio ou téléphone portable, subit des déformations. C’est le problème de la variabilité du canal. Un environnement calme ou bruité rend aussi plus ou moins facile la détection de la voix. Cette variabilité due au bruit environnant est difficilement prévisible et nécessite des traitements spécifiques pour être neutralisée.
Comment surmonter la variabilité ?
Les humains sont capables d’une certaine souplesse quand ils associent leurs perceptions à un objet : un chat est un chat, qu’il soit noir ou tigré, siamois ou persan, dans un jardin ou sur une photo. Pour l’ordinateur, c’est plus difficile : il ne fonctionne que dans les situations pour lesquelles il a été programmé. Il n’a pas de capacité propre à appréhender le monde qui l’entoure dans toute sa généralité. Il faut donc concevoir des méthodes qui lui permettent de fonctionner dans des contextes très variés.
Pour tolérer une certaine variabilité de la voix, on utilise des modèles statistiques pour créer chaque signature vocale. Le système utilise une technique classique permettant de caractériser la voix d’une personne. Cette technique est basée sur des modèles dits « modèles de mélanges de gaussiennes ».
Détection d’activité de parole
Lorsque l’on dispose d’un enregistrement de parole, la première phase d’analyse consiste à séparer les zones de silence des zones où il y a vraiment de la parole. Pour effectuer cette séparation, on se base sur l’énergie du signal. Ainsi, on ne conserve que les parties où l’énergie du signal est supérieure à un certain seuil. La principale difficulté réside alors dans le choix d’un seuil approprié à chaque signal.
Ce seuil est obtenu en regardant la distribution statistique de l’énergie du signal. On segmente tout d’abord le signal en trames de 20 ms. Ce choix de longueur de trames pour l’analyse du signal de parole repose sur l’hypothèse, formulée à partir d’une étude empirique, que la parole varie peu en 20 ms. En calculant l’énergie de chacune des trames, on peut fixer le seuil voulu.
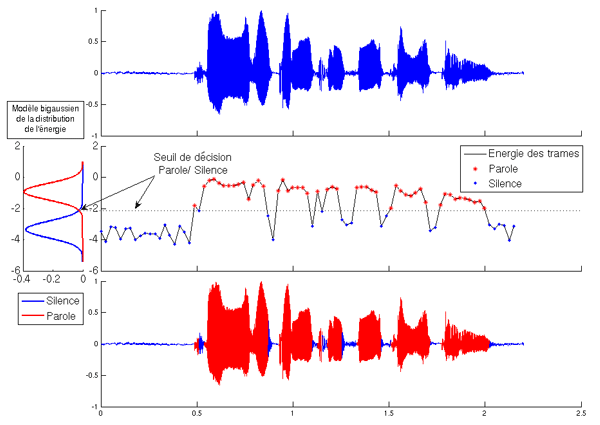
Détermination des zones de parole. L’énergie est mesurée en décibels (dB), c’est-à-dire selon une échelle logarithmique. C’est pourquoi elle peut prendre des valeurs négatives.
Analyse du signal de parole
On ne conserve comme signal de parole que les zones où l’énergie est supérieure au seuil choisi. Par des transformations mathématiques, on extrait ensuite de ce signal segmenté certaines caractéristiques propres à la voix. Seules les fréquences propres à la voix humaine, c’est-à-dire comprises entre 200 Hz et 3400 Hz, sont analysées. Les caractéristiques extraites sont en relation avec le contenu fréquentiel de la parole, la forme du conduit vocal, l’intonation ou encore la prosodie. Elles concernent les fréquences les plus présentes dans la voix, ainsi qu’une information d’intonation ou de transition entre les fréquences à chaque instant. Pour chaque trame de parole, on extrait ainsi un vecteur de 20 à 30 caractéristiques qui sont les coefficients « cepstraux », leurs dérivées et l’énergie du signal.
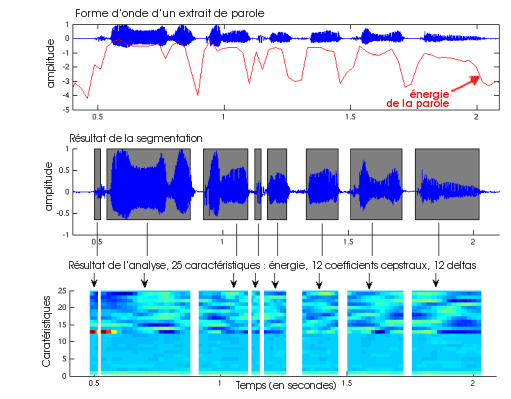
Les différentes étapes de l’analyse du signal. Sur la figure du haut, on observe un exemple de signal de parole (courbe bleue) et la valeur de son énergie à chaque instant (courbe rouge). La figure du milieu montre les parties les plus énergétiques qui sont gardées pour l’analyse (partie grisées). La figure du bas illustre le résultat de la transformation cepstrale. En plus de la valeur de l’énergie, on calcule 12 coefficients cepstraux et 12 dérivées de ces coefficients, ce qui constitue les 25 lignes représentées sur la figure. Les amplitudes de ces coefficients sont représentées par les variations de couleur, et chaque ligne horizontale représente l’évolution des valeurs d’un coefficient dans le temps.
Construction de la signature vocale
En raison de la variabilité des enregistrements et des voix, un seul enregistrement de courte durée ne permet pas de créer un modèle robuste pour reconnaître la voix d’une personne. Pour pallier ce problème, une solution consiste à créer les modèles de voix à partir d’un modèle générique plutôt que de toutes pièces. Ce modèle générique est appelé « modèle du monde » et est entraîné sur une grande variabilité de parole (nombreuses personnes, contenu varié, différents types de microphones, d’ambiances acoustiques…).
Chaque modèle spécifique est ensuite adapté de ce modèle générique pour refléter au mieux les caractéristiques propres à chaque voix. Pour cela, on utilise un petit nombre de caractéristiques extraites de l’enregistrement pour spécialiser le modèle du monde. Pour comprendre plus précisément comment l’adaptation est effectuée, il faut entrer un peu plus dans le détail des modèles probabilistes.
Modèles probabilistes
On crée pour chaque voix un modèle statistique des caractéristiques, c’est-à-dire que l’on modélise la répartition des informations (moyenne, étalement) plutôt que des valeurs précises des coefficients de l’analyse. Cette répartition des informations, que l’on appelle aussi distribution, est représentée par des fonctions mathématiques variées ayant chacune une forme géométrique différente. On choisit alors telle ou telle distribution, suivant la répartition des caractéristiques que l’on souhaite modéliser. Une forme très fréquemment utilisée est la fonction Gaussienne qui est bien adaptée pour représenter des fluctuations d’une grandeur physique autour d’une valeur moyenne (comme par exemple le bruit de fond dans un enregistrement). Le modèle mathématique n’utilise que deux paramètres, ce qui rend plus facile son estimation : la valeur moyenne prise par les caractéristiques et l’écart type de fluctuation autour de cette valeur.
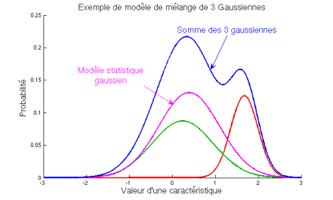
Lorsque l’on veut modéliser des distributions plus complexes, comme c’est le cas pour les caractéristiques de la voix, une technique couramment utilisée consiste à utiliser une somme de fonctions simples, comme les Gaussiennes, plutôt qu’une fonction très compliquée et difficile à estimer. Il existe bien sûr de nombreuses autres techniques, que nous n’abordons pas ici.
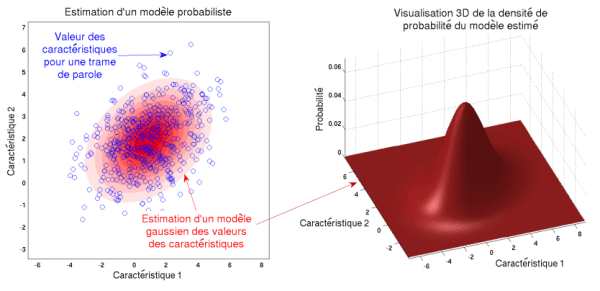
Les modèles probabilistes : exemples d’une distribution Gaussienne à deux dimensions. Sur la figure de gauche, on observe en bleu des valeurs de deux caractéristiques.Chaque rond bleu représente à un instant en abscisse et en ordonnée les valeurs respectives du premier et du second coefficient cepstral. La répartition des valeurs dans le plan peut alors être modélisée sous la forme d’une distribution Gaussienne, représentée en rouge. La figure de droite montre la distribution Gaussienne estimée. La hauteur de la distribution représente la probabilité d’une caractéristique de prendre cette valeur. C’est pourquoi on parle de modèles probabilistes (ou statistiques).
Les modèles que nous utilisons sont donc des « modèles de mélanges de Gaussiennes », appelés aussi GMM. Ces modèles sont constitués d’une somme de fonctions Gaussiennes ayant des poids différents. Pour la voix, les modèles couramment utilisés sont constitués de plusieurs centaines, voire plusieurs milliers de Gaussiennes. Aussi, pour estimer les paramètres de ces modèles – on parle également d’apprentissage des modèles – un court extrait de quelques secondes ne suffit pas. Dans les techniques classiques de reconnaissance du locuteur, le modèle du monde est appris sur plusieurs centaines d’heures de parole, pour couvrir au maximum la variabilité de la voix et de son enregistrement.
 |
 |
|
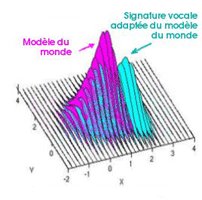
Les modèles probabilistes : exemple d’un modèle Gaussien à 2 dimensions. La figure de gauche montre un exemple de GMM à trois gaussiennes en une dimension. La figure de droite illustre la manière dont peut être adaptée une signature vocale à partir du modèle du monde. |
|
Procédure d’authentification
Une fois le modèle créé, le test d’authentification mesure la ressemblance d’un enregistrement de parole avec toutes les signatures connues par le système. Le résultat du test est un score de vraisemblance proportionnel à la ressemblance entre l’enregistrement et le modèle testé. Si la personne est déjà connue du système, on peut alors lui attribuer l’identité du modèle qui obtient le meilleur score. C’est la vérification du locuteur. Si elle n’est pas connue du système, on mesure alors simplement la ressemblance de sa voix avec les voix du système.
Cette méthode est-elle infaillible ?
Non, dans toutes les techniques d’identification vocale, il existe une marge d’erreur. Et l’on ne peut jamais être certain que deux enregistrements proviennent du même locuteur, même si les signatures vocales se ressemblent.
Et la recherche ?
Les enjeux de la recherche sont donc de proposer des méthodes de modélisation et de test qui soient robustes aux variations de la voix et aux différents types d’enregistrements, tout en restant discriminantes entre locuteurs. Il est aussi important de noter que les techniques utilisées pour la voix sont également utilisées pour caractériser de nombreux autres types de de sons.
Newsletter
Le responsable de ce traitement est Inria. En saisissant votre adresse mail, vous consentez à recevoir chaque mois une sélection d'articles et à ce que vos données soient collectées et stockées comme décrit dans notre politique de confidentialité
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
