Comment donner un sens à l’image numérique ?
Un être humain est capable d’identifier les individus et objets qui se trouvent dans son champ visuel. Réussir à ce qu’un ordinateur puisse faire de même représente un défi immense : il s’agit de parvenir à ce que la machine interprète chaque élément d’une image, fixe ou animée. Dans notre jargon informatique, cela s’appelle l’analyse de scènes. Au-delà de leur aspect fondamental, les recherches en la matière ont des retombées dans divers secteurs, de la robotique aux effets spéciaux, en passant par la recherche de photos dans des bases en contenant plusieurs millions.
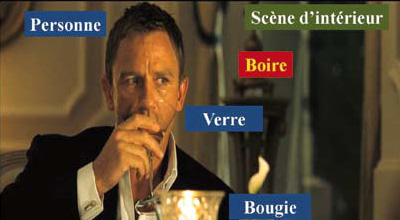
Le repérage des éléments de cette image (personne, verre, bougie, etc.) et des actions qui s’y déroulent (l’homme qui boit), évident pour un être humain, est loin de l’être pour une machine. © I. Laptev.
L’une des difficultés majeures tient à l’énorme variabilité des images d’une même catégorie d’objets : variabilité des points de vue, de l’arrangement des sources lumineuses, des couleurs, des textures, des formes, etc. Par exemple, deux chaises ou tables peuvent avoir des styles ou structures très différents. Dans le cas d’individus, l’apparence varie selon l’expression du visage, la posture, les vêtements, etc., même si l’arrangement géométrique des yeux, du nez et de la bouche ne change guère d’une personne à l’autre, pas plus que le motif d’ombres et de lumières du visage. En outre, un objet peut être partiellement caché par un obstacle. Lorsqu’un solide est opaque, on ne voit que sa partie avant, qui masque la partie arrière. Enfin, chaque objet ou individu est souvent noyé dans un « fouillis » constitué par l’arrière-plan de la scène.
Nous sommes ainsi confrontés à un double problème. Comment représenter une image ? c’est une question de modélisation. Quelles méthodes de classification et d’apprentissage utiliser ? il s’agit là d’un problème de reconnaissance. Pour la reconnaissance de visages, la première idée qui vient à l’esprit s’appuie sur une modélisation et une technique de classification très simples. Une image est représentée par la matrice des niveaux de gris (ou des couleurs) de ses pixels. Quant à la classification, elle consiste à mesurer la distance entre la matrice associée à une image-test et celles associées à des visages de référence stockés en mémoire. L’image-test est alors étiquetée par le nom de l’image de référence la plus proche, selon la distance choisie. Mais si cette démarche donne des résultats acceptables dans des conditions favorables, lorsque le point de vue et l’illumination sont fixes, il n’en va pas de même dans les situations de grande variabilité évoquées plus haut.
Les premiers travaux sur l’interprétation des scènes visuelles ont en fait été menés au début des années 1960, par exemple par l’Américain Lawrence G. Roberts au Massachusetts Institute of Technology (MIT). L’accent a longtemps été mis sur une approche structurelle, appelée syntaxique. Celle-ci est fondée sur une description globale des images en termes de formes primitives, cylindres ou cônes par exemple. Mais il est extrêmement difficile d’extraire ces formes d’images réelles et, surtout, l’analyse de scènes diffère radicalement de celle du langage naturel : même si l’interprétation d’un texte ne se réduit pas à une simple analyse syntaxique, les lettres, mots, etc., n’en forment pas moins un vocabulaire bien établi. Ce n’est pas le cas dans le monde visuel où les primitives, l’équivalent des « mots » d’un texte, sont à découvrir. Un tournant s’est opéré à la fin des années 1990 sous l’impulsion, entre autres, de Cordelia Schmid (Inria, France) et de David Lowe (université de Colombie britannique, Canada). La communauté de vision artificielle se tourne alors vers des primitives locales plus proches de l’image brute et beaucoup plus faciles à extraire. L’idée est de déterminer autour de chaque pixel, ou d’un ensemble parcimonieux de points d’intérêt, une ellipse dont la forme, la taille et l’orientation s’adaptent automatiquement au point de vue d’une caméra. D’où la possibilité de caractériser l’apparence de chaque ellipse par un vecteur (SIFT) dont les composantes mesurent la distribution des niveaux de gris dans la partie de l’image correspondante.
Cette méthodologie permet d’obtenir une description locale des images à la fois discriminative, c’est-à-dire efficace pour l’identification d’objets, et relativement insensible aux variations de point de vue et d’illumination. En outre, des méthodes classiques, dites de discrétisation, permettent ensuite de passer des vecteurs SIFT à un petit nombre de vecteurs représentatifs, assimilables en quelque sorte à des « mots visuels ». Nous sommes par là-même en mesure d’adapter à la vision des méthodes de classification héritées du traitement du langage naturel.
Un document textuel peut en effet lui aussi être décrit par un vecteur, l’histogramme représentant la fréquence des mots qui le composent, hors toute considération d’ordre et de syntaxe : on parle de « sac de mots ». Typiquement, un système tel que Google recherche les documents, les pages web, correspondant à une requête textuelle en combinant des méthodes d’indexation efficaces avec la recherche des plus proches voisins de cette requête dans l’espace des sacs de mots. Transposée dans le visuel, cette méthode permet la recherche d’objets dans une scène.

Identification d’un objet. En haut, la même camionnette apparaît dans deux plans différents d’un film mais avec une localisation et un éclairage différents ainsi que la présence d’une femme sur l’image de droite. Au centre, des primitives visuelles, ici des ellipses, sont extraites de ces images. En bas, on voit le résultat de l’appariement automatique de ces primitives pour la recherche de la camionnette, désignée par le rectangle jaune, dans l’image de droite : l’ordinateur est capable d’identifier la camionnette à droite en dépit des différences précitées. © J. Sivic et A. Zisserman.
La stratégie des sacs de mots offre également le moyen de discriminer dans un échantillon de textes, par exemple des courriels, ceux qui sont acceptables et ceux à rejeter, comme les spams. Les premiers forment un ensemble de prototypes dits « positifs » dans l’espace vectoriel des histogrammes, les seconds un ensemble de prototypes « négatifs ». Tout nouveau document est ainsi classé comme acceptable ou non par comparaison à ces prototypes, sur la base de sa distance aux prototypes en question. Cette technique est appelée méthode des plus proches voisins. En vision artificielle, il s’agit plutôt de décider si une image contient un certain type d’objet ou pas. Il faut pour cela affiner la méthode de classification, ce qu’autorisent certains résultats issus du domaine de l’apprentissage statistique.
Des algorithmes plus puissants que la méthode des plus proches voisins ont en effet été mis au point ces dernières années. Tel est le cas des algorithmes baptisés « machines à vecteurs de support » (MVS), fondés sur des développements théoriques des années 1990 dus à Vladimir Vapnik, aujourd’hui chercheur dans les laboratoires NEC (Princeton). Le principe est de construire une surface séparant les prototypes positifs des négatifs dans l’espace vectoriel des histogrammes, ici l’espace des vecteurs SIFT. Tout nouveau document, dans notre cas toute nouvelle image, reçoit alors l’étiquette associée au côté de la surface où se trouve l’histogramme des « mots » correspondants. Bien qu’elle ignore toute information spatiale, cette technique donne d’excellents résultats en classification d’images.
Mais le Néerlandais Jan J. Kœnderink, l’un des pères de la vision artificielle, va plus loin. À ces représentations qu’il qualifie de désordonnées, il substitue des modèles seulement « localement » désordonnés, de manière à préserver l’arrangement spatial global de chaque image, perdu par la méthode précédente. La version la plus simple de cette approche consiste à remplacer l’histogramme unique des sacs de mots par un ensemble d’histogrammes, obtenus en superposant à l’image une grille qui la découpe en rectangles plus petits et en associant un histogramme à chacun de ces rectangles. Pour améliorer la précision, on procède par étapes, en général trois, en augmentant la résolution de la grille à chaque étape. Tous les histogrammes sont ensuite mis bout à bout pour former un seul vecteur, lequel est donné en entrée d’une machine à vecteurs de support. Cette approche améliore de manière significative les résultats de classification et de détection.
Autre piste : passer du « sac de mots » à une décomposition en « lettres » visuelles, c’est-à-dire, en poursuivant l’analogie avec le texte, des éléments d’un niveau plus élémentaire que les mots, qui se combinent dans l’image un peu comme des lettres dans un mot. Cette piste est explorée notamment chez Inria dans l’équipe WILLOW. L’image est découpée en petits rectangles de quelques dizaines de pixels. Les « lettres » sont symbolisées par les colonnes d’une matrice optimisée pour la tâche de classification. Le nombre de colonnes choisi, de l’ordre de 500, correspond au nombre de « lettres » que comprend l’« alphabet » ou « dictionnaire » associé à l’image. Le vecteur de niveaux de gris correspondant à chaque petit rectangle est alors représenté comme une combinaison linéaire d’un nombre réduit de ces « lettres », de l’ordre de 10 à 20. L’analyse de l’image s’effectue en plusieurs itérations. Au fur et à mesure, l’« alphabet » se met à jour pour mieux s’adapter à l’image. Une fois l’« alphabet » appris, l’ordinateur est en mesure de discriminer les pixels appartenant à une classe d’objets, par exemple des bicyclettes, des pixels appartenant à une seconde classe, par exemple le fond de l’image. Cette méthode est étonnamment performante : elle permet de capturer le concept visuel d’un objet à partir d’informations purement locales.

Classification des pixels. Les deux images de gauche contiennent entre autres une bicyclette. Grâce à la technique de classification mise au point dans l’équipe de recherche WILLOW, l’ordinateur est capable de classer les pixels qu’il suppose appartenir à une bicyclette avec une certaine confiance (du rouge au jaune selon que le degré de confiance est élevé ou faible). © J. Mairal.
Il va de soi que l’interprétation d’images animées comme des vidéos accentue encore les difficultés, très brièvement évoquées ici. À ce jour, il reste un énorme travail avant de pouvoir doter la machine de capacités visuelles comparables à celles de l’être humain : approfondir le problème de la décomposition d’une scène en ses composantes sémantiques, examiner les aspects tridimensionnels de l’analyse de scènes et mieux exploiter les modèles probabilistes issus de l’apprentissage statistique. L’évaluation des méthodes d’analyse de scènes est d’ailleurs devenue une composante importante de la recherche dans ce domaine, en particulier dans le cadre du Réseau d’Excellence européen PASCAL sur la modélisation statistique des interfaces multimodales.
- C. Schmid et R. Mohr, Proc. IEEE Conference on Computer Vision and Pattern Recognition, pp. 872-877, 1996.
- D. Lowe, Proc. International Conference on Computer Vision, pp. 1150-1157, 1999.
- J. Sivic et A. Zisserman, Proc. International Conference on Computer Vision, pp. 1470-1477, 2003.
- J. Zhang, M. Marszalek, S. Lazebnik et C. Schmid, The International Journal of Computer Vision, pp. 213-238, 2007.
- N. Dalal et B. Triggs, Proc. IEEE Conference on Computer Vision and Pattern Recognition, pp. 886-893, 2005.
- S. Lazebnik, C. Schmid et J. Ponce, Proc. IEEE Conference on Computer Vision and Pattern Recognition, pp. 2169- 2178, 2006.
- J. Mairal, F. Bach, J. Ponce, G. Sapiro et A. Zisserman, Proc. IEEE Conference on Computer Vision and Pattern Recognition, pp. 1-8, 2008.
Une première version de cet article est parue dans les Cahiers de l’Inria en partenariat avec la revue La Recherche, n°435, novembre 2009.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Jean Ponce
Professeur à l'École Normale Supérieure, responsable de l'équipe-projet WILLOW (DI ENS, CNRS / ENS Paris / Inria).