

sous licence Creative Commons
Le système d’exploitation, pièce centrale de la sécurité
Quand on achète une machine (téléphone, ordinateur) on s’intéresse à ses caractéristiques matérielles : les Go (pour gigaoctet) de stockage, les Go de RAM (mémoire vive) et GHz (pour gigahertz) de processeurs. Ces ressources matérielles vont être utilisées et partagées par tous les programmes qui s’exécutent sur la machine. Par exemple, les quelques Go de stockage de nos smartphones peuvent être utilisés pour stocker à la fois nos mails professionnels, nos mails personnels et nos photos. Le capteur 5 MP (pour mégapixel) de la caméra peut être utilisé via l’application appareil photo, mais aussi par des applications tierces de réseaux sociaux comme Instagram, ou une application professionnelle pour scanner des notes de frais. Les quelques GHz de processeurs sont eux potentiellement utilisables par toutes les applications.
Le partage des ressources matérielles est nécessaire : s’il n’existait pas, nous devrions nous promener avec un téléphone par application. Cependant, tous ces partages sont autant d’opportunités pour une application malveillante d’espionner ou d’interférer avec l’exécution d’autres applications. Comment faire en sorte que cela n’arrive pas ? Pour répondre à cette question, il faut d’abord répondre à une première question : qui gère les ressources matérielles ?
Par la suite, on utilise le mot processus plutôt qu’application. Une application peut lancer plusieurs processus.
Le système d’exploitation
Le système d’exploitation (SE) est responsable de la gestion des ressources matérielles. Le SE présente à chaque processus un environnement d’exécution, dans lequel il peut tourner sans se soucier des autres processus. Dans le jargon, on dit qu’il « virtualise » les ressources, car chaque processus croît avoir l’ensemble des ressources réelles pour lui alors qu’il n’a accès qu’à une petite partie.
Le SE a une logique très complexe. Imaginons que nous « virtualisions » une cuisine pour que deux chefs cuisinent leur plat avec les ressources de cette cuisine, sans que l’un puisse connaître ni modifier ce que l’autre prépare. La cuisine représente les ressources matérielles, les cuisiniers représentent les processus.
La première chose à faire pour le SE est de planifier qui a accès à la cuisine et quand. C’est l’ordonnancement (scheduling) : on alloue un temps limité à chaque cuisinier après lequel on lui demandera de sortir pour revenir plus tard.
Puis il faut organiser le changement de contexte (context-switch) : lorsque l’on change de cuisinier, on nettoie toute la cuisine et on remet en place les affaires du précédent cuisinier, sans laisser de traces.
Enfin, comme les placards stockent les affaires des deux cuisiniers, il faut empêcher que l’un ouvre et modifie un placard dont l’autre se sert. Pour ce faire, le SE bloque par défaut l’accès aux placards. Lorsqu’un cuisinier essaie d’ouvrir un placard, le SE le fait sortir de la cuisine, et vérifie que le placard n’a pas été alloué à un autre cuisinier avant de le lui attribuer.
Si l’ordonnancement est trop permissif avec les processus, un processus malveillant peut prendre tout le temps et empêcher un autre processus de s’exécuter. S’il y a une erreur dans le changement de contexte, un processus malveillant peut avoir accès à des informations sur un autre processus. Enfin, s’il y a un problème dans la gestion de la mémoire (les placards), le SE pourrait autoriser par erreur l’accès d’un processus à une zone de mémoire qu’il n’était pas censé voir.
Pour plus de détails sur le système d’exploitation, je vous invite à lire ces deux articles de Claude Kaiser : « À quoi sert un système d’exploitation ? », et « Le ballet des processus dans un système d’exploitation ».
La preuve de programme
Comment faire pour vérifier que tout se passe « comme prévu » ? Tout dépend du niveau d’assurance que l’on souhaite.
En général, pour éviter les erreurs dans le design, on l’élabore avec soin et on le documente minutieusement. Pour ensuite vérifier l’implémentation, on effectue des tests fonctionnels. Un test sert à vérifier que pour une certaine donnée d’entrée, le programme termine bien avec la donnée de sortie attendue.
Lorsque le système est simple, les tests permettent de couvrir tous les cas d’exécution possibles. Prenons par exemple un ascenseur sur un étage avec trois boutons : étage 0, étage 1, ouvrir les portes. Cet ascenseur a 5 états possibles : étage 0 ou 1, portes fermées ou non ; entre deux étages, portes fermées. Pour tester tous les cas possibles du système, il suffit d’appuyer sur les 3 boutons dans chacun des 5 états du système.
Lorsque le système est complexe, il est difficile de tout tester. Sur un ordinateur par exemple, en considérant uniquement des paramètres visibles (combien de programmes sont lancés, lequel est en premier plan, combien de mémoire reste-t-il, est-ce qu’il y a une connexion internet, une connexion bluetooth, est-ce qu’il y a une clé USB branchée…) on a bien plus d’états que pour un simple ascenseur. En fait, à ce moment-même, à chaque fois que je tape sur une touche de mon ordinateur, je change son état et le mets dans un état probablement différent de tous les états dans lesquels il a été précédemment, c’est-à-dire dans un état qui n’a pas été testé.
En général, les tests, les bons designs et les bonnes pratiques de programmation permettent de développer des logiciels dans lesquels on peut avoir un niveau de confiance tout à fait satisfaisant. Mais lorsque les logiciels sont « critiques », on peut vouloir élever ce niveau de confiance dans le logiciel.
La preuve formelle de programme permet d’atteindre les niveaux de confiance les plus élevés. Au lieu d’exécuter certains chemins du programme, la preuve formelle utilise la logique pour raisonner sur l’ensemble des chemins possibles du programme. Un adage bien connu dans le domaine dit « le test permet de trouver des erreurs, la preuve prouve qu’il n’y en a pas ». Pour plus de détails sur la preuve formelle, voir l’article « Les méthodes formelles : l’autre arme de la cybersécurité ».
Un système d’exploitation (SE) est complexe, et selon l’utilisation qui en est faite, peut être critique. Par exemple, un SE embarqué dans des objets médicaux, dans l’aviation ou l’automobile, le SE du téléphone d’une personne d’intérêt comme un chef d’État, sont critiques. Voyons comment on peut prouver que « tout se passe comme prévu ».
La propriété d’isolation
Pour prouver que « tout se passe comme prévu » il faut d’abord définir ce que signifie « se passer comme prévu », c’est-à-dire la propriété que l’on cible. Pour un SE, on cherche en général à prouver un certain degré d’isolation entre les processus. Considérons un système S composé d’une machine M faisant tourner deux processus « A » et « B ».
On définit l’état de A comme tout ce que A peut observer. Pour reprendre l’exemple de la cuisine, on a vu que après le passage de B en cuisine, le SE remettait tout en place pour que A ne puisse pas savoir que B a utilisé la même cuisine. A n’observe pas de différences entre avant le passage de B et après, pour autant, la cuisine peut être dans un état différent. Mais tant que A n’ouvre pas les placards, il ne peut pas s’en rendre compte, et comme il ne peut pas les ouvrir, la cuisine lui semble être dans le même état. Ainsi l’état de A peut être le même dans deux systèmes aux états différents.
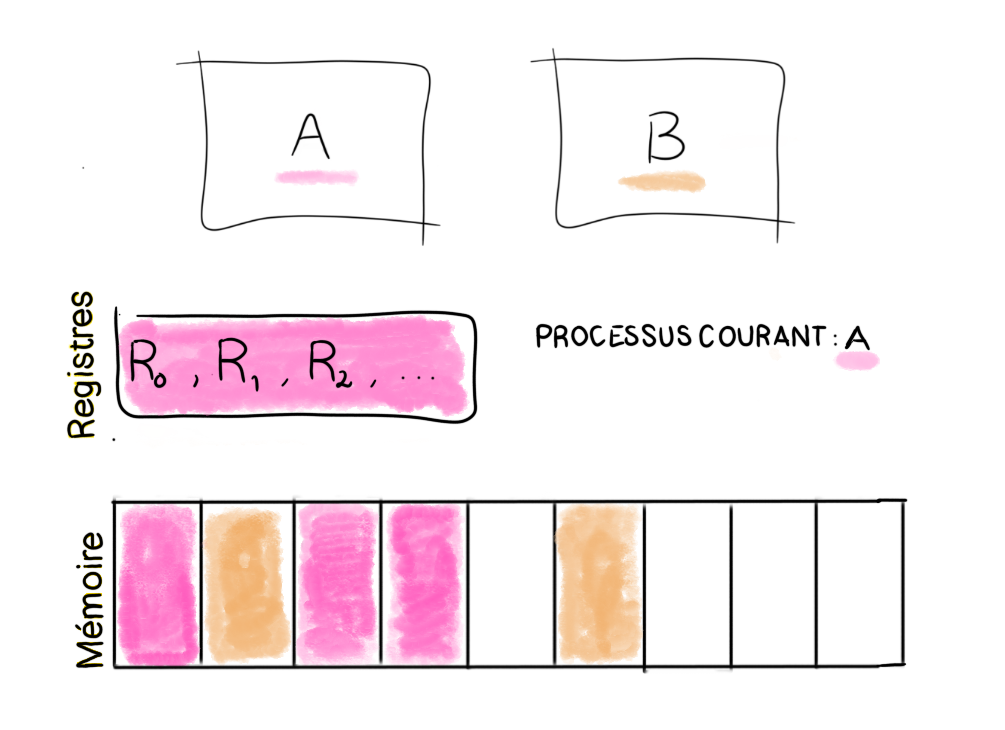
Figure 1 : état du système.
Dans le cas des processus, on peut définir leur état par la mémoire à laquelle ils ont accès et leurs registres. Comme le montre la Figure 1, le processus courant A a accès à ses registres et à sa mémoire. Exprimons l’isolation à partir des états de A et de B. L’isolation peut s’écrire comme la combinaison de l’intégrité et de la confidentialité, que nous allons décrire dans la suite. Par simplicité, nous présentons ici une propriété d’isolation stricte, c’est-à-dire n’autorisant aucune interférence entre les deux processus.
On peut écrire la propriété d’intégrité pour l’application A de la manière suivante : si B s’exécute, alors l’état de A n’est pas modifié. Et la propriété de confidentialité pour l’application A : soit deux états du système S et S’ tels que les états de A et A’ soient différents mais l’état de B soit le même. Si B s’exécute, les états d’arrivée de B sont les mêmes, que l’on parte de S ou de S’. Autrement dit, l’exécution de B ne dépend pas de l’état de A, c’est-à-dire que B n’a pas accès à la mémoire et aux registres de A. La propriété de confidentialité exprimée ici est très stricte, dans certains cas, on peut vouloir que les deux processus communiquent, dans ce cas on peut énoncer une propriété plus faible, dans laquelle les états de départ de A dans S et S’ partagent une similarité.
Pour prouver que A et B sont bien isolés, il faut prouver que la manière dont le SE gère qui a accès à quoi est valide.
La preuve
Afin de comprendre l’intuition derrière la preuve, nous allons prendre une opération du système d’exploitation relative à la virtualisation de la mémoire (l’allocation de mémoire) et nous allons expliquer ce qui pourrait mal se passer et devrait être prouvé.
Lorsque la mémoire est virtualisée, un processus pense avoir un certain espace mémoire alloué, par exemple il pense pouvoir accéder à toutes les adresses de 0 à N. En réalité, le SE a des tables de correspondance entre les adresses « virtuelles » auxquelles le processus croit accéder, et les adresses réelles. Ainsi quand le processus pense accéder à l’adresse « 3 », au lieu d’aller chercher l’adresse 3, le processeur accède aux tables de traduction du SE et renvoie la donnée qui se trouve dans l’adresse physique correspondante, par exemple 42.
En pratique, pour des raisons de performance, le SE ne garde pas de table de traduction adresse par adresse, mais plutôt de morceaux d’adresses contiguës vers des morceaux d’adresses contiguës. Ces morceaux s’appellent les pages, et par conséquent les tables de traductions s’appellent les tables de pages. Si la table de pages ne contient aucune entrée pour l’adresse demandée par le processus, il y a alors ce qu’on appelle un défaut de page : le SE choisit une nouvelle page réelle à attribuer à la page virtuelle, et modifie la table de pages. Pour aller plus loin sur la virtualisation de la mémoire, je vous invite à lire l’article « La mémoire virtuelle, une abstraction féconde ».
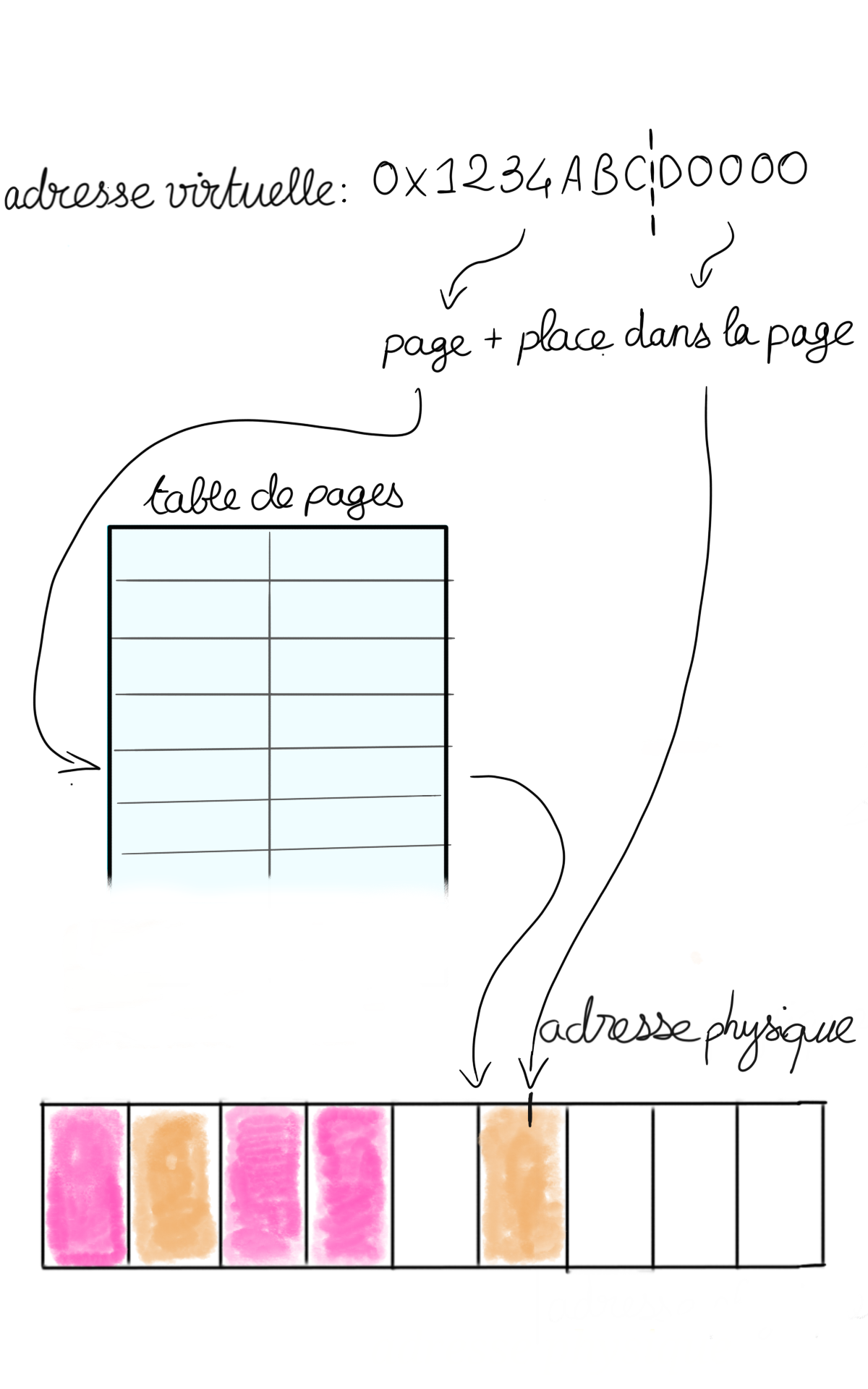
Figure 2 : table de pages.
Les tables de pages sont une pièce centrale de la bonne isolation des processus, car un processus peut uniquement accéder aux adresses qui sont traduites dans sa table de pages. Afin que l’opération d’allocation d’une nouvelle page conserve l’isolation, il faut entre autres prendre garde à ce que la nouvelle page soit vide et qu’elle ne soit pas d’ores et déjà attribuée à un autre processus. C’est ce genre de propriété que l’on prouve formellement. Supposons par exemple que nous ayons un ensemble de pages libres dans lequel on vienne piocher lors d’un défaut de page. Une manière de faire (selon le design) est de prouver qu’à tout moment de l’exécution, les pages de cet ensemble sont vides et ne sont attribuées à aucun processus. Pour ce faire, on vérifie la propriété à l’état initial et on prouve que toutes les opérations qui modifient l’ensemble des pages libres (disons les opérations « ajout d’une page », « suppression d’une page ») conservent cette propriété. Ainsi, lorsque l’on a un défaut de page, on s’appuie sur cette propriété pour prouver que l’attribution de la nouvelle page à un processus A ne brise pas l’intégrité et la confidentialité pour le processus B.
Ce sont en général des algorithmes bas niveau, qui demandent beaucoup de minutie pour être écrits sans erreur. Par exemple, une page pourrait n’être vidée que partiellement, ou on pourrait allouer par mégarde une page de grande taille qui viendrait s’étaler sur une page allouée à un autre processus sans être détectée par le SE.
Le talon d’Achille de la preuve
La preuve est basée sur un modèle, sur des hypothèses que l’on fait sur le matériel. Si ces hypothèses sont fausses, la preuve est caduque. Par exemple, en ce qui concerne la mémoire, on a vu que, lorsque le processus A s’exécute, le SE ordonne au processeur d’utiliser la table de page qu’il a préparée pour A. A ne peut ensuite accéder qu’aux pages traduites dans cette table de page, l’empêchant ainsi d’accéder aux pages allouées à B. On a donc fait deux hypothèses sur le matériel :
- le processeur utilise la table de page choisie par le SE ;
- lorsque le processeur utilise la table de page T, toute adresse qui n’apparaît pas dans T est inaccessible.
La première hypothèse est extrêmement basique : le SE inscrit dans un registre l’adresse de la table de pages à utiliser par le processeur, ce dernier l’utilise pour traduire les pages. Il y a très peu de risques qu’il y ait une erreur sur le circuit matériel à ce niveau là, c’est donc une hypothèse acceptable.
La deuxième hypothèse paraît tout aussi simple, et dans le cas général elle l’est. Cependant, si on utilise le cache, cela devient plus compliqué. Dans les grandes lignes, le cache permet de garder dans une mémoire très rapide d’accès les derniers résultats d’une requête mémoire. En activant le cache, on décide par exemple de faire confiance au matériel pour vider proprement le cache entre chaque exécution de processus, pour ne pas que B accède à des données chargées dans le cache pour A. Les optimisations matérielles peuvent devenir extrêmement complexes, et encore récemment, des failles majeures ont été découvertes (comme Spectre et Meltdown).
En résumé, les méthodes formelles apportent les niveaux de garanties les plus élevés sur les propriétés d’un système. Cela est particulièrement intéressant lorsque les systèmes en question sont critiques et complexes, comme le sont les systèmes d’exploitation des domaines sensibles. Il faut cependant bien garder en tête que l’expression un « système prouvé » seule ne signifie pas grand-chose : il convient de préciser quelles propriétés sont prouvées et sous quelles hypothèses, pour en apprécier la valeur.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !
