

sous licence Creative Commons
Tout ce que les algorithmes de traitement d’images font pour nous
Au long de cet article, nous allons suivre l’évolution d’une image numérique au cours de sa chaîne de traitement, depuis ce que reçoit un capteur photographique jusqu’au fichier final stocké en mémoire.
Du capteur photographique à l’image brute
Tout commence par l’acquisition de l’image. De la même manière que nos yeux parviennent à voir un objet, un appareil photo « voit » grâce à son capteur.
Un capteur photographique est un composant électronique qui constitue la base des appareils photo numériques, l’équivalent de la pellicule en photographie argentique. Il est composé de cellules sensibles à la lumière, appelées des photosites. Ces derniers réagissent à la quantité de lumière qu’ils reçoivent et la convertissent en un nombre entier, qui est ensuite enregistré dans la mémoire de l’appareil photo. À la sortie du capteur, on obtient alors un tableau de valeurs représentant l’intensité lumineuse associée à chaque photosite.
Pour obtenir une image en couleur, la technologie s’inspire de la perception humaine, en associant à chaque valeur une des trois couleurs suivantes : rouge, vert ou bleu.
Pour ce faire, les photosites sont recouverts d’un filtre physique coloré. Il existe différents agencements (par exemple celui de Fujifilm) mais le plus courant est la matrice de Bayer, composée de 50% de vert, 25% de rouge et 25% de bleu. Chaque photosite ne renvoie que l’intensité de la couleur primaire associée. Par synthèse additive, ces trois couleurs permettent de reconstituer toutes les couleurs du spectre visible. La prédominance du vert est due au fait que la vision humaine y est plus sensible.

Image brute du capteur avec matrice de Bayer, visualisation effectuée avec le logiciel vpv.
L’appareil enregistre aussi des informations, appelées métadonnées EXIF, telles que la marque et le modèle de l’appareil et de l’objectif ; la date, l’heure, le lieu de la prise de la photo et les paramètres de prise de vue. Ces informations ajoutées aux données brutes du capteur forment le fichier RAW.
Qu’est-ce qu’une image numérique ?
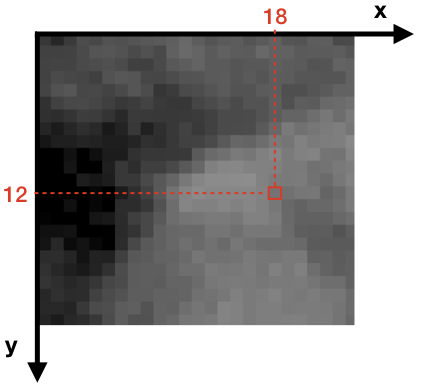
Le pixel de coordonnées (18, 12) est encadré en rouge.
Une image est composée de pixels. La définition de notre image ici est de 7360 × 4912 pixels. Il s’agit d’une matrice (ou un tableau de nombres entiers) à deux dimensions avec 7360 pixels en largeur et 4912 pixels en hauteur. Chaque pixel possède alors une coordonnée horizontale x et une coordonnée verticale y.
Effectuer une opération sur une image revient donc à effectuer une opération sur une matrice.
Qu’en est-il d’une image couleur ?
Chaque pixel d’une image couleur est un triplet (r, v, b) de valeurs allant de 0 à 255 (256 valeurs différentes) : les valeurs sont codées sur 8 bits (28 = 256).
Une image couleur est ainsi composée de trois matrices, appelées canaux, une avec les valeurs qui représentent le rouge, une avec les valeurs du vert et une avec les valeurs du bleu.

Canal rouge

Canal vert

Canal bleu
Le code Python suivant permet d’afficher les valeurs d’un pixel d’une image.
from PIL import Image
img = Image.open("chien.tiff")
(r,v,b) = img.getpixel((18,12))
print("r : ", r, "v : ", v, "b : ", b)Pour le pixel en position (18, 12), on obtient le triplet (96, 93, 62).
Suivant la théorie physique de la synthèse additive, la variation de l’intensité lumineuse associée à chaque canal permet d’obtenir les couleurs, comme vous pouvez le tester ci-dessous. Ainsi, (96, 93, 62) correspond à un vert kaki, (0, 0, 0) à du noir, (255, 255, 255) à du blanc, etc. Testez vous-même les couleurs obtenues en entrant différentes valeurs.
Quelles sont les opérations subies par une image ?
Des algorithmes, issus d’une approche mathématique des images, sont appliqués à l’image obtenue initialement par le capteur, pour produire l’image finale. Plusieurs opérations sont présentes dans la chaîne de traitement d’une image numérique, le but étant d’obtenir l’image « parfaite », celle qui donnera l’illusion de la réalité.
Notre appareil photo, smartphone ou ordinateur, via divers logiciels de traitement d’images, applique ces opérations à l’image afin d’obtenir un résultat final. Pour savoir quels algorithmes appliquer, les données EXIF qui accompagnent l’image peuvent être prises en compte. Des logiciels spécialisés permettent aussi de jouer avec les paramètres de ces algorithmes.
Dans la suite, un exemple commun d’opérations de la chaîne de traitement d’image est illustré. L’ordre diffère d’un logiciel à un autre et certaines opérations sont parfois effectuées en même temps. Certaines tâches sont nécessaires à la formation et au stockage, d’autres permettent une amélioration de la visualisation et ne sont pas appliquées par tous les appareils.
Les étapes de formation d’une image

à la sortie du capteur

après dématriçage

après balance des blancs

après correction de l’exposition

après correction optique

après débruitage et rehaussement de contraste

après changement de luminosité et retouches

après compression JPEG
Utilisez les boutons « Suivante » et « Précédente » pour observer le résultat obtenu à chaque étape.
Le dématriçage est l’opération visant à obtenir une image couleur à partir des données du capteur. Chaque pixel de l’image brute ①, ne possède qu’une composante rouge, verte ou bleue. Après l’opération de dématriçage, les données de chacun des pixels monochromes sont interpolées afin d’estimer les deux composantes manquantes.
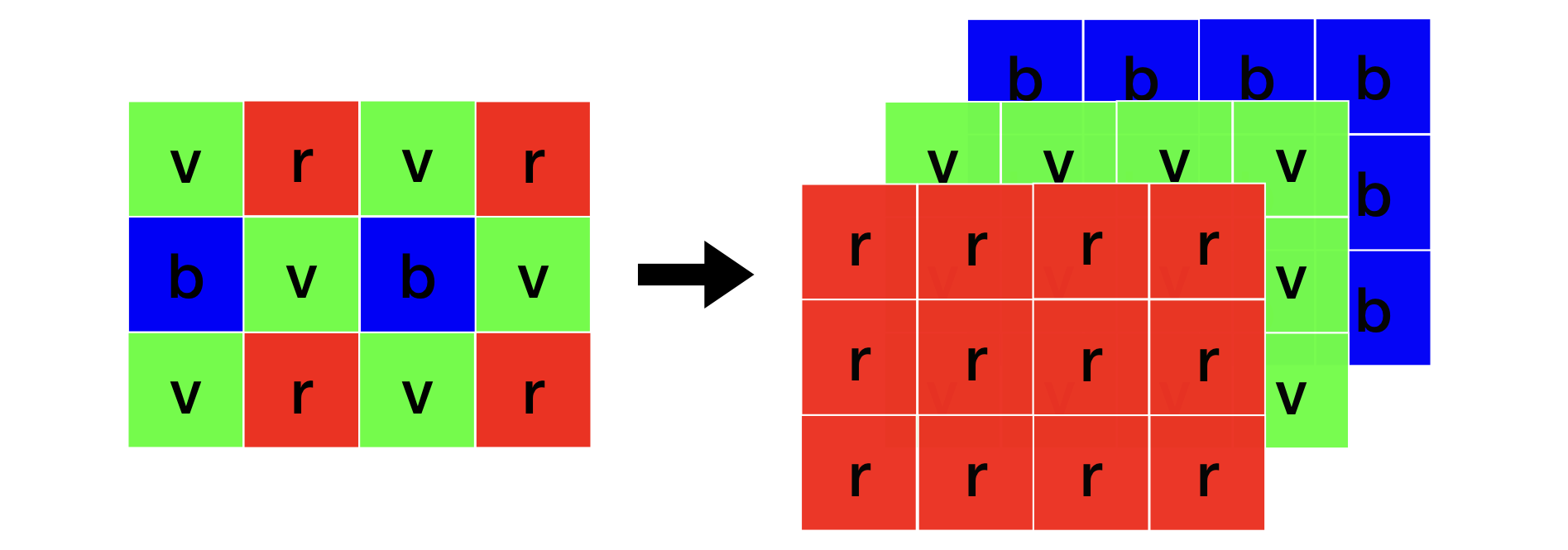
Image brute vers image couleur
On obtient ainsi une image ② avec des pixels composés d’un triplet de valeurs (r, v, b).
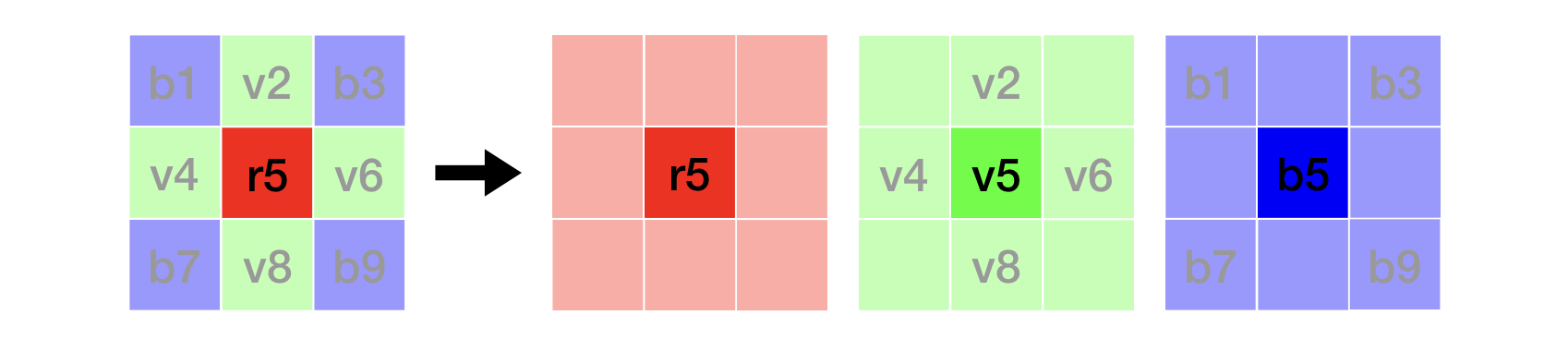
La position 5 ne possède qu’une composante rouge \(r5\). Les composantes \(v5\) et \(b5\) peuvent être calculées par une interpolation simple :
\[v5 = {v2 + v4 + v6 + v8 \over 4}\] \[b5 = {b1 + b3 + b7 + b9\over 4}\]
Bien sûr, il ne s’agit là que d’un exemple pour illustrer l’algorithme de dématriçage. Les méthodes utilisées sont plus complexes et sont souvent combinées avec d’autres traitements tels qu’un débruitage ou une amélioration de la netteté.
Cependant, la visualisation n’est toujours pas acceptable : l’image ② nécessite un calibrage de ses couleurs.
L’image ③ a subi une balance des blancs, qui permet d’obtenir une image aux couleurs fidèles à la scène indépendamment des conditions d’éclairage : pour que le blanc de l’image apparaisse blanc sur nos écrans. Les logiciels permettent de choisir la balance des blancs en fonction d’un type de scène comme par exemple, la lumière naturelle ou la lumière fluorescente.
Pour obtenir une image restituant aussi fidèlement que possible la réalité, d’autres traitements sont classiquement intégrés à la chaîne. Une correction de l’exposition permet d’obtenir l’image ④ . Des corrections pour compenser l’imperfection des objectifs permettent d’obtenir l’image ⑤. Ainsi, la correction des distorsions optiques est une correction de la géométrie de l’image. La correction des aberrations chromatiques permet d’ôter les franges colorées indésirables autour des éléments d’une image. Ces corrections peuvent être effectuées grâce à la connaissance du modèle de l’objectif. Par exemple, le logiciel DxO PhotoLab possède une base de données des objectifs et applique la correction associée.
L’image ⑤ subit encore des corrections de couleurs, comme la correction gamma qui rend la scène plus représentative de la luminosité perçue par la vision humaine et d’autres opérations classiques pour améliorer la netteté, diminuer l’effet « grain » (on parle de débruitage), enlever le flou et rehausser le contraste, jusqu’à obtenir l’image ⑥. Enfin, un changement de luminosité et des opérations locales pour supprimer les petits défauts permettent d’obtenir l’image ⑦.
On peut considérer une image comme étant la somme de deux autres images représentant la même scène mais contenant des caractéristiques différentes. Dans notre exemple, l’image est décomposée en une image « base » et une image « détail ».

Image de départ

Image base

Image détail
Dans la première, on trouve une description grossière de la scène. Dans la seconde, une description plus fine avec la texture et les petites variations de contraste.
Des méthodes de rehaussement de contraste sont basées sur ce type de décomposition. Par exemple, augmenter le contraste de l’image détail permet d’obtenir une image dont le contraste fin est rehaussé. Au contraire, le réduire permet d’obtenir l’effet « peau lisse » qui est utilisé dans le mode portrait de certains téléphones portables.
Comment stocker une image numérique ?
Pour une image couleur, le fichier est composé d’une matrice dont chaque élément est un triplet de valeurs et des données EXIF. Le stockage peut être vu comme le rangement de toutes ces informations dans la mémoire. Il existe différentes manières de les ranger.
Pour ensuite afficher une image, il faut « défaire » ce rangement. Pour y parvenir, le logiciel de visualisation doit savoir comment a été préalablement rangée notre image : il lui est donc nécessaire de connaître son format.
Dans notre exemple, le fichier au format TIFF a une taille de 103 Mo. Il ne s’agit pas de la taille de l’image, qu’on appelle la définition, ni de la profondeur de couleurs représentant le nombre de bits utilisés pour chaque canal, mais de la place qu’occupe le fichier dans la mémoire. Pour avoir un ordre d’idée, 150 fichiers de 103 Mo remplissent un smartphone de 16 Go de mémoire ! On préfère donc compresser nos fichiers, c’est-à-dire les ranger d’une manière à diminuer l’espace occupé sur le support numérique.
Pour les images, il existe un standard de compression appelé JPEG avec des extensions comme JPG, jpg, JPEG ou jpeg. La plupart des appareils utilisent ce format, mais il en existe d’autres comme par exemple HEIF. Depuis 2017, les produits Apple donnent le choix de sauvegarder les photos en JPEG ou en HEIC (qui est le nom donné au format HEIF par la marque).
L’algorithme JPEG dépend d’un paramètre de qualité Q, allant de 1 à 100. Plus celui-ci est petit, plus l’image perd de sa qualité. En effet, la compression est dite avec perte. Elle se fait en retirant certaines informations qui sont des détails peu visibles pour l’œil humain. L’image ⑧ est l’image reconstruite après avoir stocké l’image ⑦ en format JPEG avec Q égal à 85. On remarque que cette perte n’est pas visible et lorsque cette image est stockée, le fichier (image et ses métadonnées) n’occupe plus que 3.8 Mo d’espace en mémoire. Cependant, si on diminue le facteur de qualité Q, l’image se dégrade. Notons que lorsqu’on ne stocke pas toute l’information de l’image, on ne peut bien évidemment pas reconstruire l’image d’origine avec tous ses détails. Toute la subtilité de la méthode est de trouver le bon compromis entre la place qu’occupe le fichier en mémoire et la perte d’information dans l’image.

Q10 : 398Ko

Q30 : 793Ko

Q50 : 1,2Mo

Q70 : 2,0Mo

Q90 : 5,3Mo
Tout d’abord, l’image RVB est convertie en base YCbCr : un canal luminance et deux canaux de couleurs. L’œil humain étant plus sensible à la luminance, les canaux de couleurs sont souvent sous-échantillonnés pour occuper moins d’espace.
Chaque canal est découpé en blocs 8 × 8 pixels, où chaque bloc est alors traité indépendamment. Après passage dans le domaine de Fourier via une transformée en cosinus discrète, une quantification dépendant du paramètre Q est appliquée.
La quantification est l’étape irréversible de l’algorithme au cours de laquelle se produit la majeure partie de la perte d’information. Elle permet ainsi de gagner le plus de place. Elle conduit à l’atténuation des hautes fréquences auxquelles l’œil humain est très peu sensible. Il s’agit des zones qui varient fortement sur quelques pixels, comme les zones très texturées.
Chaque bloc est ensuite codé en suivant des algorithmes de compression de données sans perte.
Quelques étapes de la chaîne de traitement d’une image ont été illustrées ici, mais l’histoire de la vie d’une image ne s’arrête pas là. Les applications telles que Instagram, Facebook ou Snapchat permettent de recadrer l’image, la redresser et lui appliquer différents filtres. Toutes ces actions reposent aussi sur des algorithmes de traitement d’images. Lors de la publication sur les réseaux sociaux, ces derniers appliquent des transformations : ils peuvent redimensionner les images, les compresser à nouveau et la plupart du temps, suppriment les métadonnées EXIF.
De nouvelles méthodes sont constamment développées afin de répondre aux besoins dus à l’arrivée de nouvelles technologies, le désir d’avoir des images de meilleure qualité et les opportunités de partage qu’offre Internet.
Que peut-on faire d’autre avec le traitement d’images ?
Tout d’abord, il existe d’autres types d’images que les photographies : les images médicales, astronomiques, satellitaires, etc. Chaque domaine possède sa batterie d’algorithmes pour former, améliorer, afficher et coder les images.
Il y a aussi l’analyse des images qui permet d’en extraire de l’information. Par exemple, la détection d’objets (voitures, visages, etc.), la détection de mouvements pour la vidéosurveillance, ou l’extraction des contours, comme illustré ci-dessous.


Toutes les méthodes évoquées dans cet article, et bien d’autres, sont des sujets de recherche actuels. Les chercheurs et chercheuses en mathématiques et informatique publient des articles scientifiques, dont certains peuvent être consultés en ligne via le journal de traitement d’images IPOL (Image Processing On Line). Ce journal a la particularité de permettre de télécharger et de lire non seulement la description de la méthode, mais aussi son programme informatique. De plus, il permet de tester chacune des méthodes avec ses propres images directement via le site web.
Niveau de lecture
Aidez-nous à évaluer le niveau de lecture de ce document.
Votre choix a été pris en compte. Merci d'avoir estimé le niveau de ce document !

Tina Nikoukhah
Doctorante en traitement d'images au Centre Borelli (ex-CMLA), ENS Paris-Saclay.